Arxiv:1908.02322V1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Football Clubs, City Images and Cultural Differentiation: Identifying with Rivalling Vitesse Arnhem and NEC Nijmegen
Urban History, 46, 2 (2019) © The Author(s) 2018. This is an Open Access article, distributed under the terms of the Creative Commons Attribution licence (http://creativecommons.org/ licenses/by/4.0/), which permits unrestricted re-use, distribution, and reproduction in any medium, provided the original work is properly cited. doi:10.1017/S0963926818000354 First published online 29 May 2018 Football clubs, city images and cultural differentiation: identifying with rivalling Vitesse Arnhem and NEC Nijmegen ∗ JON VERRIET Sports History Research Group, History Department, Radboud University Nijmegen, Erasmusplein 1, 6525 HT Nijmegen, The Netherlands abstract: How are deep relationships between city and club identification formed, and are they inevitable? The aim of this article is to provide a historical analysis of the rivalry between two football clubs, Vitesse Arnhem and NEC Nijmegen, explicating their various ‘axes of enmity’. Supporters, club officials and observers of these two clubs created and selectively maintained similarities between respective city image and club image. The process of ‘othering’ influenced both city and club images and helped create oppositional identities. Herein, football identification reflects broader societal needs for a place-based identity, and for a coherent image of both self and other. Introduction The history of sport has proved a fruitful field for research into processes of identification. According to Jeff Hill, the texts and practices of sports represent ‘structured habits of thought and behaviour which contribute to our ways of seeing ourselves and others’.1 Sports rivalries in particular have received attention from sociologists and historians, as they allow investigations into community bonding and the process of ‘othering’. -

Framing of Corporate Crises in Dutch Newspaper Articles
Framing of corporate crises in Dutch newspaper articles A corpus study on crisis response strategies, quotation, and metaphorical frames T.J.A. Haak Radboud University Date of issue: 20 December 2019 Supervisor: Dr. W.G. Reijnierse Second Assessor: Dr. U. Nederstigt Program: MA International Business Communication Framing of corporate crises in Dutch media Abstract Research topic - The purpose of this study was to find answers to how corporate crises are framed in Dutch media. A journalist frames a crisis by making choices about information, quotation, and language. This thesis focusses on these aspects by analysing what crisis response strategies can be found, and how this information is reported by the journalist using quotation and metaphor. Hypotheses and research – It was expected that a company’s cultural background would influence the crisis response strategy that is reported in the newspapers. The hypotheses stated that companies originating from countries with an individualistic culture appear in newspapers more often with a diminish strategy and less often with a no response or rebuild strategy than companies originating from countries with a collectivistic culture. The denial strategy was expected to appear equally frequent. Furthermore, it was studied whether a link exists between these crisis response strategies and the occurrence of quotes and metaphors within Dutch newspaper articles. Method – These topics were studied using a combination of quantitative and qualitative research methods. A corpus of Dutch newspaper articles (N = 606) covering corporate crises was analysed. Findings – No significant relation was found between the reported crisis response strategies and companies’ cultural backgrounds (individualistic or collectivistic). A relationship was found between the reported crisis response strategy and (in)direct quotation of the company in crisis. -

Facebook News Feed Changes in the Netherlands
NEVER MISS A STORY. FACEBOOK NEWS FEED CHANGES IN THE NETHERLANDS WHAT HAPPENED AND WHAT SHOULD YOU DO? Table of CONTENTS UNDERSTANDING FACEBOOK NEWS FEED CHANGES 3 EFFECTS OF THE NEWS FEED CHANGES IN THE NETHERLANDS 4 RECOMMENDATIONS FOR NEWSROOMS 11 METRICS USED IN THIS REPORT 12 ABOUT THIS STUDY 13 CONTACT 13 Information for News Publishers 3 Understanding Facebook News Feed Changes FACEBOOK IS Improving user experience and spread REDEFINING ITS of reliable news. ENGAGEMENT LOGIC As of May 2018, most publishers on Facebook have lost engagement. Publishers most affected: FACEBOOK Large tabloid and viral pages. ENGAGEMENT IS SHRINKING FOR ALMOST EVERYBODY Content type most affected: Video. Local news pages defy the trend and have seen some growth. FACEBOOK’S PUBLIC ANNOUNCEMENTS Facebook made a big announcement OF ALGORITHM in January. CHANGES DO NOT MATCH UP Changes to algorithm are ongoing WITH CHANGES IN and require monitoring. PRACTICE 4 Facebook News Feed changes in the Netherlands EFFECTS OF THE NEWS FEED CHANGES IN THE NETHERLANDS Facebook engagement Viral and tabloid types Link content remains on Dutch news pages of publishers are most steadier than video dropped 36% on affected across Europe average over 6 months Video engagement Who grows: Algorithm changes dropped Smaller television and appear to be ongoing radio pages during Q1 and Q2 2018 Information for News Publishers 5 Dutch news Publishers’ Facebook engagement dropped by 36% on average in 6 months SELECTED MAJOR NEWS PUBLISHERS IN THE NETHERLANDS AVERAGE ENGAGEMENT PER -

Prijzen Digital
Prijzen Digital - Direct Buy Display 2018 Alle prijzen zijn excl. BTW Desktop, laptop & tablet Desktop/laptop Only Mobile Only Multi Device (desktop/laptop/tablet/mobile) Homepage Takeover (desktop/laptop/tablet/mobile) Titel/CPM Leader- Half Page Billboard FloorAd+ Skin + Skin + Billboard Double Half Page* Medium 2AD XL 3AD XL Takeover Titel/fixed per dag HPTO HPTO HPTO board Leader- Billboard + Video Sized Rectangle/ ROS Multi Mobile Desktop/ board Reminder Banner Mobile Tablet V9-150618 Device*** Half Page *** RON (Run of Network) € 6,50 € 13,50 € 15,00 € 20,00 € 20,00 € 25,00 **€ 20,00 € 5,00 € 8,75 € 8,75 € 16,00 €20,00 € 25,00 RON Nationaal + Regionaal € 42.500 € 25.925 € 21.250 Channel Sport € 7,50 € 14,50 € 16,00 € 21,00 € 21,00 € 26,00 € 21,00 € 6,00 € 9,75 € 9,75 € 17,00 € 21,00 € 26,00 RON Nationaal € 40.000 € 24.400 € 20.000 Channel Food € 9,50 € 16,50 € 18,00 € 23,00 € 28,00 € 8,00 € 11,75 € 11,75 € 19,00 RON Regionaal € 10.000 € 6.100 € 5.000 AD RON ADR Nieuwsmedia € 40.000 € 24.400 € 20.000 de Stentor AD € 35.000 € 21.350 € 17.500 Tubantia de Stentor De Gelderlander € 7,50 € 14,50 € 16,00 € 21,00 € 21,00 € 26,00 € 21,00 € 6,00 € 9,75 € 9,75 € 17,00 € 21,00 € 26,00 Tubantia Eindhovens Dagblad De Gelderlander € 2.000 € 1.200 € 1.000 Brabants Dagblad Eindhovens Dagblad BN deStem Brabants Dagblad PZC BN deStem Sportnieuws PZC € 800 € 490 € 400 de Volkskrant de Volkskrant € 10.000 € 6.100 € 5.000 Trouw € 9,50 € 16,50 € 18,00 € 23,00 € 23,00 € 28,00 € 8,00 € 11,75 € 11,75 € 19,00 € 23,00 € 28,00 Trouw € 2.500 € 1.550 € 1.250 -
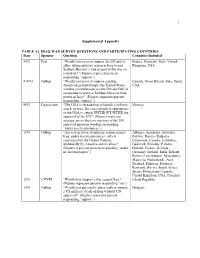
Cotwsupplemental Appendix Fin
1 Supplemental Appendix TABLE A1. IRAQ WAR SURVEY QUESTIONS AND PARTICIPATING COUNTRIES Date Sponsor Question Countries Included 4/02 Pew “Would you favor or oppose the US and its France, Germany, Italy, United allies taking military action in Iraq to end Kingdom, USA Saddam Hussein’s rule as part of the war on terrorism?” (Figures represent percent responding “oppose”) 8-9/02 Gallup “Would you favor or oppose sending Canada, Great Britain, Italy, Spain, American ground troops (the United States USA sending ground troops) to the Persian Gulf in an attempt to remove Saddam Hussein from power in Iraq?” (Figures represent percent responding “oppose”) 9/02 Dagsavisen “The USA is threatening to launch a military Norway attack on Iraq. Do you consider it appropriate of the USA to attack [WITHOUT/WITH] the approval of the UN?” (Figures represent average across the two versions of the UN approval question wording responding “under no circumstances”) 1/03 Gallup “Are you in favor of military action against Albania, Argentina, Australia, Iraq: under no circumstances; only if Bolivia, Bosnia, Bulgaria, sanctioned by the United Nations; Cameroon, Canada, Columbia, unilaterally by America and its allies?” Denmark, Ecuador, Estonia, (Figures represent percent responding “under Finland, France, Georgia, no circumstances”) Germany, Iceland, India, Ireland, Kenya, Luxembourg, Macedonia, Malaysia, Netherlands, New Zealand, Pakistan, Portugal, Romania, Russia, South Africa, Spain, Switzerland, Uganda, United Kingdom, USA, Uruguay 1/03 CVVM “Would you support a war against Iraq?” Czech Republic (Figures represent percent responding “no”) 1/03 Gallup “Would you personally agree with or oppose Hungary a US military attack on Iraq without UN approval?” (Figures represent percent responding “oppose”) 2 1/03 EOS-Gallup “For each of the following propositions tell Austria, Belgium, Bulgaria, me if you agree or not. -

1 Summoned in Preliminary Relief Proceedings In
Kennedy Van der Laan SUMMONED IN PRELIMINARY RELIEF PROCEEDINGS IN EXPEDITED PROCEEDINGS PURSUANT TO A WRITTEN MANDATE OF 19 FEBRUARY 2018 BY THE PRELIMINARY RELIEF JUDGE OF THE AMSTERDAM DISTRICT COURT on the condition that the writ of summons is served on defendants as soon as possible and that the date and time of the court hearing are communicated expediently to defendants, and the draft writ of summons is sent to defendants Today, the ……………………………… two thousand and eighteen, at the request of: 1. the private company with limited liability GS MEDIA B.V., with its official seat in Amsterdam and its principal place of business in (6001 DA) Weert at De Noord 25, hereinafter referred to as “GS Media”; 2. the private company with limited liability DE PERSGROEP NEDERLAND B.V., also trading under the name De Gelderlander, with its official seat in Amsterdam and its principal place of business in (1018 LL) Amsterdam at Jacob Bontiusplaats 9, hereinafter referred to as “De Persgroep”; 3. the private company with limited liability THE POST ONLINE B.V., with its official seat in Amsterdam and its principal place of business in (1017 RR) Amsterdam at Kleine- Gartmanplantsoen 10, hereinafter referred to as “TPO”; 4. Mr CHRISTIAAN EVERHARDUS AALBERTS, residing in all choosing their address for service in this matter at Haarlemmerweg 333 in (1040 HD) Amsterdam, at the offices of Kennedy Van Der Laan N.V., of which firm meester J.P. Van den Brink is appointed as lawyer and will act in that capacity together with meester E.W. Jurjens, HAVE SUMMONED TO APPEAR IN SUMMARY PROCEEDINGS: 1. -

MAPPING DIGITAL MEDIA: NETHERLANDS Mapping Digital Media: Netherlands
COUNTRY REPORT MAPPING DIGITAL MEDIA: NETHERLANDS Mapping Digital Media: Netherlands A REPORT BY THE OPEN SOCIETY FOUNDATIONS WRITTEN BY Martijn de Waal (lead reporter) Andra Leurdijk, Levien Nordeman, Thomas Poell (reporters) EDITED BY Marius Dragomir and Mark Thompson (Open Society Media Program editors) EDITORIAL COMMISSION Yuen-Ying Chan, Christian S. Nissen, Dusˇan Reljic´, Russell Southwood, Michael Starks, Damian Tambini The Editorial Commission is an advisory body. Its members are not responsible for the information or assessments contained in the Mapping Digital Media texts OPEN SOCIETY MEDIA PROGRAM TEAM Meijinder Kaur, program assistant; Morris Lipson, senior legal advisor; and Gordana Jankovic, director OPEN SOCIETY INFORMATION PROGRAM TEAM Vera Franz, senior program manager; Darius Cuplinskas, director 12 October 2011 Contents Mapping Digital Media ..................................................................................................................... 4 Executive Summary ........................................................................................................................... 6 Context ............................................................................................................................................. 10 Social Indicators ................................................................................................................................ 12 Economic Indicators ........................................................................................................................ -

De Telegraaf En De Limburger
Openbare versie Nederlandse mededingingsautoriteit BESLUIT Besluit van de directeur-generaal van de Nederlandse mededingingsautoriteit als bedoeld in artikel 37, eerste lid, van de Mededingingswet. Nummer 1538/24 Betreft zaak: 1538/De Telegraaf – De Limburger I. MELDING 1. Op 22 september 1999 heeft de directeur-generaal van de Nederlandse mededingingsautoriteit (hierna ook: d-g NMa) een melding ontvangen van een voorgenomen concentratie in de zin van artikel 34 van de Mededingingswet (hierna ook: Mw). Hierin is medegedeeld dat N.V. Holdingmaatschappij De Telegraaf (hierna: de Telegraaf-groep) voornemens is zeggenschap te verkrijgen, in de zin van artikel 27, onder b, van de Mededingingswet, over Uitgeversmaatschappij De Limburger B.V. (hierna: DLBV). Van de melding is mededeling gedaan in Staatscourant 186 van 28 september 1999. Naar aanleiding van de mededeling in de Staatscourant is één zienswijze van een derde naar voren gebracht. Ambtshalve zijn vragen gesteld aan verschillende marktpartijen. II. PARTIJEN 2. De Telegraaf-groep is een naamloze vennootschap naar Nederlands recht. Zij heeft een groot aantal dochterondernemingen. 3. De Telegraaf-groep geeft het landelijke dagblad De Telegraaf uit. Zij geeft de volgende regionale dagbladen uit: Limburgs Dagblad, Haarlems Dagblad, IJmuider Courant, Leids Dagblad, Noordhollands Dagblad (waaronder begrepen: Alkmaarse Courant, Schager Courant, Enkhuizer Courant, Dagblad voor West-Friesland, Helderse Courant, Dagblad Kennemerland, Dagblad Zaanstreek, Nieuwe Noord-Hollandse Courant), De Gooi- en Eemlander en Dagblad van Almere. Zij geeft ook een groot aantal huis-aan-huisbladen uit. 1 Openbare versie Openbare versie 4. De Telegraaf-groep is verder actief op het gebied van tijdschriften en elektronische media en de technische vervaardiging van de genoemde media in Nederland, het vervaardigen van grafische producten voor derden, waaronder drukwerk, en het verspreiden van dagbladen, huis- aan-huisbladen en drukwerk door dochteronderneming Spiral B.V. -

Afgesloten / Lopende / Geplande Digitalisering Van Kranten Per Titel Inventarisatie T.D.V
Afgesloten / Lopende / Geplande digitalisering van kranten per titel Inventarisatie t.d.v. Databank Digitale Dagbladen (KB) 1940-1945 Last update: 29 november 2010 TITEL PERIODE INSTELLING CONTACTPERSOON 1 Amersfoortsch Dagblad - De Eemlander A origineel 1913-1942 Archief Eemland [email protected] 2 Axelse courant 1885-1970 Gemeenten Hulst, Terneuzen en Sluis [email protected] 3 BBC Nieuws A origineel 1943-1945 Tresoar 4 Boskoopse Courant A 1889-1981 Historische Vereniging Boskoop 5 Boxtelse courant A origineel 1939-1941 Stadsarchief 's Hertogenbosch [email protected] 6 Brabander A origineel 1944-1946 Stadsarchief 's Hertogenbosch [email protected] 7 Dagblad voor Amersfoort A origineel 1946-1964 Archief Eemland [email protected] 8 Dagblad voor Leiden e.o. L origineel 1944-1945 Regionaal Archief Leiden [email protected] 9 De Bommelerwaard A origineel 1942-1965 Streekarchief Bommelerwaard [email protected] 10 De Burcht L origineel 1945-1946 Regionaal Archief Leiden [email protected] De Eembode, Katholiek Nieuws- en Advertentieblad voor 11 Amersfoort etc. A origineel 1890-1941 Archief Eemland [email protected] 12 De Eendracht A origineel 1945 Stadsarchief 's Hertogenbosch [email protected] 13 De Frisia (CD-ROM) A 1896-1977 Stichting Digitaal Archief Leewarder Courant [email protected] 14 De Gelderlander - editie Nijmegen A/G 1856-2000 Regionaal Archief Nijmegen [email protected] 15 De Graafschapbode G 1879-1945 Bureau Metamorfoze [email protected] 16 De Groene Amsterdammer A 1877-1940 De Groene Amsterdammer [email protected] De Holevoet / De Nieuwe Holevoet. Nieuwsblad voor 17 Scherpenzeel etc. -

The Influence of Newspaper Coverage and a Media Campaign on Smokers’ Support for Smoke-Free Bars and Restaurants and on Second-Hand Smoke Harm Awareness
The influence of newspaper coverage and a media campaign on smokers’ support for smoke-free bars and restaurants and on second-hand smoke harm awareness. Findings from the International Tobacco Control (ITC) Netherlands Survey. Gera E Nagelhout, Bas van den Putte, Hein de Vries, Mathilde R. Crone, Geoffrey T Fong, Marc C Willemsen To cite this version: Gera E Nagelhout, Bas van den Putte, Hein de Vries, Mathilde R. Crone, Geoffrey T Fong, et al.. The influence of newspaper coverage and a media campaign on smokers’ support for smoke-free bars and restaurants and on second-hand smoke harm awareness. Findings from the International Tobacco Control (ITC) Netherlands Survey.. Tobacco Control, BMJ Publishing Group, 2011, 21 (1), pp.24. 10.1136/tc.2010.040477. hal-00677617 HAL Id: hal-00677617 https://hal.archives-ouvertes.fr/hal-00677617 Submitted on 9 Mar 2012 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. The influence of newspaper coverage and a media campaign on smokers’ support for smoke-free bars and restaurants and on second-hand smoke harm awareness. Findings from the International Tobacco Control (ITC) Netherlands Survey Gera E. -

Vogelkoppenknipsels Verzameld Door Wim Smeets
Vogelkoppenknipsels verzameld door Wim Smeets Hieronder treft u een onvolledigoverzicht aan van Noodgrepen betekenen alleen uitstel allerlei vogelkoppen met een verkorte inhoud die broeden gierzwaluwen in verscheidene Nederlandse dagbladen zijn ver- De Nieuwsbode, 9 mei 2000 (een huis-aan-huis- schenen. blad voor Zeist). Het dak van het voormalige klooster Mariaoord aan de Rozenstraat in Zeist ondergaat een ver- bouwing waardoor de broedplaats van de Gier- oeverzwaluw Flatgebouw deels zwaluwen onder handen wordt genomen. Volgens ingestort de veldpolitie is er helemaal niets aan de hand. De 3 mei 2000. Gelderlander, 1 We hebben de bouwwerkzaamheden vier weken Een deel van het flatgebouw van de Oeverzwa- naar voren geschoven en speciale dakpannen luwen bleek Volgens het Polderdistrict ingeslort. aangebracht, we wisten van het bestaan van de Betuwe is een de natuurlijke zandverschuiving kolonie niets af/aldus de woningbouwvereniging. oorzaak de De van instorting. aannemer, bezig met de dijkverzwaring, is vooraf gevraagd door Eidereend verhongert het Polderdistrict rekening te houden met de Trouw, 10 mei 2000 Oeverzwaluwen. Vogelbescherming en de Waddenverenigingheb- Het werk aan de dijk wordt door de Oeverzwalu- ben staatssecretaris G. Faber (Natuurbeheer) ge- niet wen in gevaar gebracht. Aannemer kan tot vraagd de schelpdiervisserij in de Waddenzee tij- eind juli-beginaugustus wachten en dan zijn de delijkstop te zetten vanwege de grotesterfte on- Oeverzwaluwen vertrokken naar Afrika. der de Eidereenden. Dit jaar zijn al 17.000 dode redactie: in Bunschoten de Oeverzwaluwen (noot blijven Eidereenden zesmaal zoveel als gevonden; ge- in de tweede helft de jaarlijks tot van september aan middeld. oeverzwaluwenwand). Over hetzelfde onderwerp een vloed van berich- ten: Vogelclub eist verbod vissen schelpdieren (LeeuwarderCourant, 9 mei 2000), Sterfte eider- Gedoe over het doden van duiven eenden door voedselgebrek nog nooit zo groot Trouw, 4 mei 2000. -

Ifra XMA Cross Media Awards 2007
Ifra XMA Cross Media Awards 2007 Village Squares The news never was this close By Royal Wegener NV 1 About Royal Wegener NV: In November 1903, Johan (J. F.) Wegener started a newspaper and advertiser in Apeldoorn, the Netherlands: the forerunner to the Apeldoornse Courant. This small, local publisher would grow into the leading media group that it is today. Royal Wegener NV is located in Apeldoorn and is registered at Euronext. Every day, Wegener delivers 0.9 million newspapers to its readers in a sizeable area of the Netherlands. Each week, Wegener turns out more than 7 million newspapers and free door-to-door papers. In addition, Wegener also develops and operates Internet products and services. Furthermore, Wegener provides graphics products and services. Wegener’s regional newspapers cover the vast majority of the Netherlands. They are published in various regions, from the North Sea coast all the way to the German border. Total circulation is around 869.254 copies that are read by 2,6 million consumers. The Wegener newspapers have a long tradition in the regions. Some titles have even been around for more than a century. They are characterised by strong reader loyalty and a large readership. Wegener’s regional newspapers and their daily circulation: • Brabants Dagblad 137 746 • BN/DeStem 125 532 • De Gelderlander 165 547 • De Stentor 142 405 • De Twentsche Courant Tubantia 124 621 • Eindhovens Dagblad 114 213 • Provinciale Zeeuwse Courant 58 190 Group office visiting address: Koninklijke Wegener NV Laan van Westenenk 4 7336 AZ Apeldoorn The Netherlands Group office postal address: P.O.