Lexical-Functional Grammar∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Language Group Specific Informational Reports
Rhode Island College M.Ed. In TESL Program Language Group Specific Informational Reports Produced by Graduate Students in the M.Ed. In TESL Program In the Feinstein School of Education and Human Development Language Group: Romanian Author: Jean Civil Program Contact Person: Nancy Cloud ([email protected]) RHODE ISLAND COLLEGE TESL 539-01: ROMANIAN LANGUAGE Student: Jean Ocelin Civil Prof: Nancy Cloud Spring 2010 Introduction Thousands of languages, dialects, creoles and pidgins are spoken worldwide. Some people, endowed by either an integrative or extrinsic motivation, want to be bilingual, trilingual or multilingual. So, the interlanguage interference becomes unavoidable. Those bilingual individuals are omnipresent in the State of Rhode Island. As prospective ESL teachers, our job requirement is to help them to achieve English proficiency. Knowing the interference problems attributable to their native language is the sine qua none pre- condition to helping them. However, you may have trouble understanding Romanian native speakers due to communication barriers here in the State of Rhode Island. The nature of our research is to use a Contrastive Analysis Approach to the Romanian language, so we can inquire about their predicted errors. In the following PowerPoint presentation, we will put emphasis specifically on phonology, grammar, communication style, and semantic problems. Romanian History 1. Before 106 AD, the Dacians lived in Romanian territory. They spoke Thracian tongue. 2. 106 AD, the defeat of the Dacians, (an indo-European people), led to a period of intense Romanization. A vulgar Latin became the language of commerce and administration. Thracian and Latin combined gave birth to Romanian Language. 3. -

Language Structure: Phrases “Productivity” a Property of Language • Definition – Language Is an Open System
Language Structure: Phrases “Productivity” a property of Language • Definition – Language is an open system. We can produce potentially an infinite number of different messages by combining elements differently. • Example – Words into phrases. An Example of Productivity • Human language is a communication system that bears some similarities to other animal communication systems, but is also characterized by certain unique features. (24 words) • I think that human language is a communication system that bears some similarities to other animal communication systems, but is also characterized by certain unique features, which are fascinating in and of themselves. (33 words) • I have always thought, and I have spent many years verifying, that human language is a communication system that bears some similarities to other animal communication systems, but is also characterized by certain unique features, which are fascinating in and of themselves. (42 words) • Although mainstream some people might not agree with me, I have always thought… Creating Infinite Messages • Discrete elements – Words, Phrases • Selection – Ease, Meaning, Identity • Combination – Rules of organization Models of Word reCombination 1. Word chains (Markov model) Phrase-level meaning is derived from understanding each word as it is presented in the context of immediately adjacent words. 2. Hierarchical model There are long-distant dependencies between words in a phrase, and these inform the meaning of the entire phrase. Markov Model Rule: Select and concatenate (according to meaning and what types of words should occur next to each other). bites bites bites Man over over over jumps jumps jumps house house house Markov Model • Assumption −Only adjacent words are meaningfully (and lawfully) related. -

Chapter 30 HPSG and Lexical Functional Grammar Stephen Wechsler the University of Texas Ash Asudeh University of Rochester & Carleton University
Chapter 30 HPSG and Lexical Functional Grammar Stephen Wechsler The University of Texas Ash Asudeh University of Rochester & Carleton University This chapter compares two closely related grammatical frameworks, Head-Driven Phrase Structure Grammar (HPSG) and Lexical Functional Grammar (LFG). Among the similarities: both frameworks draw a lexicalist distinction between morphology and syntax, both associate certain words with lexical argument structures, both employ semantic theories based on underspecification, and both are fully explicit and computationally implemented. The two frameworks make available many of the same representational resources. Typical differences between the analyses proffered under the two frameworks can often be traced to concomitant differ- ences of emphasis in the design orientations of their founding formulations: while HPSG’s origins emphasized the formal representation of syntactic locality condi- tions, those of LFG emphasized the formal representation of functional equivalence classes across grammatical structures. Our comparison of the two theories includes a point by point syntactic comparison, after which we turn to an exposition ofGlue Semantics, a theory of semantic composition closely associated with LFG. 1 Introduction Head-Driven Phrase Structure Grammar is similar in many respects to its sister framework, Lexical Functional Grammar or LFG (Bresnan et al. 2016; Dalrymple et al. 2019). Both HPSG and LFG are lexicalist frameworks in the sense that they distinguish between the morphological system that creates words and the syn- tax proper that combines those fully inflected words into phrases and sentences. Stephen Wechsler & Ash Asudeh. 2021. HPSG and Lexical Functional Gram- mar. In Stefan Müller, Anne Abeillé, Robert D. Borsley & Jean- Pierre Koenig (eds.), Head-Driven Phrase Structure Grammar: The handbook. -

Romanian Timebank: an Annotated Parallel Corpus for Temporal Information
Romanian TimeBank: An Annotated Parallel Corpus for Temporal Information Corina Forăscu1,2, Dan Tufiş1 1 Research Institute in Artificial Intelligence, Romanian Academy, Bucharest 1,2 Faculty of Computer Science, Alexandru Ioan Cuza University of Iași, Romania 16, General Berthelot, Iasi 700483, Romania E-mail: [email protected], [email protected] Abstract The paper describes the main steps for the construction, annotation and validation of the Romanian version of the TimeBank corpus. Starting from the English TimeBank corpus – the reference annotated corpus in the temporal domain, we have translated all the 183 English news texts into Romanian and mapped the English annotations onto Romanian, with a success rate of 96.53%. Based on ISO-Time - the emerging standard for representing temporal information, which includes many of the previous annotations schemes -, we have evaluated the automatic transfer onto Romanian and, and, when necessary, corrected the Romanian annotations so that in the end we obtained a 99.18% transfer rate for the TimeML annotations. In very few cases, due to language peculiarities, some original annotations could not be transferred. For the portability of the temporal annotation standard to Romanian, we suggested some additions for the ISO-Time standard, concerning especially the EVENT tag, based on linguistic evidence, the Romanian grammar, and also on the localisations of TimeML to other Romance languages. Future improvements to the Ro-TimeBank will take into consideration all temporal expressions, signals and events in texts, even those with a not very clear temporal anchoring. Keywords: temporal information, annotation standards, Romanian language expressions – references to a calendar or clock system, 1. -

A Pedagogical Perspective on the Definite and the Indefinite Article in the Romanian Language
Ovidiu Ivancu Institute of Romanian Language, Bucharest, Caransebeș 1, Bucharest Vilnius University, University 5, Vilnius [email protected] Research interests: cultural studies, literature, linguistics, theory of literature A Pedagogical Perspective on the Definite and the Indefinite Article in the Romanian Language. Challenges for Foreign Learners Abstract All Romance languages have developed the definite and the indefinite article via the Vulgar Latin (Classical Latin did not use articles), the language of the Roman colonists. According to Joseph H. Greenberg (1978), the definite article predated the indefinite one by approximately two centuries, being developed from demonstratives through a complex process of grammaticalization. Many areas of nowadays` Romania were incorporated into the Roman Empire for about 170 years. After two military campaign, the Roman emperor Trajan conquered Dacia, east of Danube. The Romans imposed their own administration and inforced Latin as lingua franca. The language of the colonists, mixed with the native language and, later on, with various languages spoken by the many migrant populations that followed the Roman retreat resulted in a new language (Romanian), of Latin origins. The Romanian language, attested in the 16th Century, in documents written by foreign travellers, uses four different types of articles. Being a highly inflected language, Romanian changes the form of the articles according to the gender, the number and the case of the noun As compared to the other Romance languages, Romanian uses the definite article enclitically. Thus, the definite article and the noun constitute a single word. The present paper aims at discussing, analysing and providing an overview of the use of definite and indefinite articles. -

Lexical-Functional Grammar and Order-Free Semantic Composition
COLING 82, J. Horeck~(eel) North-HoOandPubllshi~ Company O A~deml~ 1982 Lexical-Functional Grammar and Order-Free Semantic Composition Per-Kristian Halvorsen Norwegian Research Council's Computing Center for the Humanities and Center for Cognitive Science, MIT This paper summarizes the extension of the theory of lexical-functional grammar to include a formal, model-theoretic, semantics. The algorithmic specification of the semantic interpretation procedures is order-free which distinguishes the system from other theories providing model-theoretic interpretation for natural language. Attention is focused on the computational advantages of a semantic interpretation system that takes as its input functional structures as opposed to syntactic surface-structures. A pressing problem for computational linguistics is the development of linguistic theories which are supported by strong independent linguistic argumentation, and which can, simultaneously, serve as a basis for efficient implementations in language processing systems. Linguistic theories with these properties make it possible for computational implementations to build directly on the work of linguists both in the area of grammar-writing, and in the area of theory development (cf. universal conditions on anaphoric binding, filler-gap dependencies etc.). Lexical-functional grammar (LFG) is a linguistic theory which has been developed with equal attention being paid to theoretical linguistic and computational processing considerations (Kaplan & Bresnan 1981). The linguistic theory has ample and broad motivation (vide the papers in Bresnan 1982), and it is transparently implementable as a syntactic parsing system (Kaplan & Halvorsen forthcoming). LFG takes grammatical relations to be of primary importance (as opposed to the transformational theory where grammatical functions play a subsidiary role). -

Romanian; an Essential Grammar
Romanian Now in its second edition, Romanian: An Essential Grammar is a concise, user- friendly guide to modern Romanian. It takes the student through the essentials of the language, explaining each concept clearly and providing many examples of contemporary Romanian usage. This fully revised second edition contains: • a chapter of each of the most common grammatical areas with Romanian and English examples • extensive examples of the more difficult areas of the grammar • a section with exercises to consolidate the learning and the answer key • a list of useful verbs • an appendix listing useful websites for further information • a glossary of grammatical terms used in the book • a useful bibliographical list Suitable for both classroom use and independent study, this book is ideal for beginner to intermediate students. Ramona Gönczöl is a lecturer in Romanian language at the School of Slavonic and East European Studies, University College London. She is co-author, with Dennis Deletant, of Colloquial Romanian, 4th edition, Routledge, 2012. Ramona’s research interests include language acquisition, learner experience, online learning, sociolinguistics, psycholinguistics, cultural identities and language contact. Routledge Essential Grammars Essential Grammars describe clearly and succinctly the core rules of each language and are up-to-date and practical reference guides to the most important aspects of languages used by contemporary native speakers. They are designed for elementary to intermediate learners and present an accessible description of the language, focusing on the real patterns of use today. Essential Grammars are a reference source for the learner and user of the language, irrespective of level, setting out the complexities of the language in short, readable sections that are clear and free from jargon. -

(Romanian) on L2/L3 Learning (Catalan/Spanish) Simona Popa
Nom/Logotip de la Universitat on s’ha llegit la tesi Language transfer in second language acquisition. Some effects of L1 instruction (Romanian) on L2/L3 learning (Catalan/Spanish) Simona Popa http://hdl.handle.net/10803/380548 ADVERTIMENT. L'accés als continguts d'aquesta tesi doctoral i la seva utilització ha de respectar els drets de la persona autora. Pot ser utilitzada per a consulta o estudi personal, així com en activitats o materials d'investigació i docència en els termes establerts a l'art. 32 del Text Refós de la Llei de Propietat Intel·lectual (RDL 1/1996). Per altres utilitzacions es requereix l'autorització prèvia i expressa de la persona autora. En qualsevol cas, en la utilització dels seus continguts caldrà indicar de forma clara el nom i cognoms de la persona autora i el títol de la tesi doctoral. No s'autoritza la seva reproducció o altres formes d'explotació efectuades amb finalitats de lucre ni la seva comunicació pública des d'un lloc aliè al servei TDX. Tampoc s'autoritza la presentació del seu contingut en una finestra o marc aliè a TDX (framing). Aquesta reserva de drets afecta tant als continguts de la tesi com als seus resums i índexs. ADVERTENCIA. El acceso a los contenidos de esta tesis doctoral y su utilización debe respetar los derechos de la persona autora. Puede ser utilizada para consulta o estudio personal, así como en actividades o materiales de investigación y docencia en los términos establecidos en el art. 32 del Texto Refundido de la Ley de Propiedad Intelectual (RDL 1/1996). -

Romanian Grammar
1 Cojocaru Romanian Grammar 0. INTRODUCTION 0.1. Romania and the Romanians 0.2. The Romanian language 1. ALPHABET AND PHONETICS 1.1. The Romanian alphabet 1.2. Potential difficulties related to pronunciation and reading 1.2.1. Pronunciation 1.2.1.1. Vowels [ ǝ ] and [y] 1.2.1.2. Consonants [r], [t] and [d] 1.2.2. Reading 1.2.2.1. Unique letters 1.2.2.2. The letter i in final position 1.2.2.3. The letter e in the initial position 1.2.2.4. The ce, ci, ge, gi, che, chi, ghe, ghi groups 1.2.2.5. Diphthongs and triphthongs 1.2.2.6. Vowels in hiatus 1.2.2.7. Stress 1.2.2.8. Liaison 2. MORPHOPHONEMICS 2.1. Inflection 2.1.1. Declension of nominals 2.1.2. Conjugation of verbs 2.1.3. Invariable parts of speech 2.2. Common morphophonemic alternations 2.2.1. Vowel mutations 2.2.1.1. the o/oa mutation 2.2.1.2. the e/ea mutation 2.2.1.3. the ă/e mutation 2.2.1.4. the a/e mutation 2.2.1.5. the a/ă mutation 2.2.1.6. the ea/e mutation 2.2.1.7. the oa/o mutation 2.2.1.8. the ie/ia mutation 2.2.1.9. the â/i mutation 2.2.1.10. the a/ă mutation 2.2.1.11. the u/o mutation 2.2.2. Consonant mutations 2.2.2.1. the c/ce or ci mutation 2.2.2.2. -
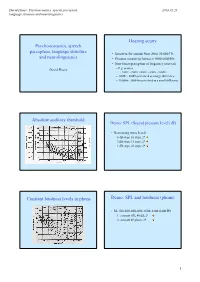
Psychoacoustics, Speech Perception, Language Structure and Neurolinguistics Hearing Acuity Absolute Auditory Threshold Constant
David House: Psychoacoustics, speech perception, 2018.01.25 language structure and neurolinguistics Hearing acuity Psychoacoustics, speech perception, language structure • Sensitive for sounds from 20 to 20 000 Hz and neurolinguistics • Greatest sensitivity between 1000-6000 Hz • Non-linear perception of frequency intervals David House – E.g. octaves • 100Hz - 200Hz - 400Hz - 800Hz - 1600Hz – 100Hz - 800Hz perceived as a large difference – 3100Hz - 3800 Hz perceived as a small difference Absolute auditory threshold Demo: SPL (Sound pressure level) dB • Decreasing noise levels – 6 dB steps, 10 steps, 2* – 3 dB steps, 15 steps, 2* – 1 dB steps, 20 steps, 2* Constant loudness levels in phons Demo: SPL and loudness (phons) • 50-100-200-400-800-1600-3200-6400 Hz – 1: constant SPL 40 dB, 2* – 2: constant 40 phons, 2* 1 David House: Psychoacoustics, speech perception, 2018.01.25 language structure and neurolinguistics Critical bands • Bandwidth increases with frequency – 200 Hz (critical bandwidth 50 Hz) – 800 Hz (critical bandwidth 80 Hz) – 3200 Hz (critical bandwidth 200 Hz) Critical bands demo Effects of masking • Fm=200 Hz (critical bandwidth 50 Hz) – B= 300,204,141,99,70,49,35,25,17,12 Hz • Fm=800 Hz (critical bandwidth 80 Hz) – B=816,566,396,279,197,139,98,69,49,35 Hz • Fm=3200 Hz (critical bandwidth 200 Hz) – B=2263,1585,1115,786,555,392,277,196,139,98 Hz Effects of masking Holistic vs. analytic listening • Low frequencies more effectively mask • Demo 1: audible harmonics (1-5) high frequencies • Demo 2: melody with harmonics • Demo: how -

Phrase Structure Rules, Tree Rewriting, and Other Sources of Recursion Structure Within the NP
Introduction to Transformational Grammar, LINGUIST 601 September 14, 2006 Phrase Structure Rules, Tree Rewriting, and other sources of Recursion Structure within the NP 1 Trees (1) a tree for ‘the brown fox sings’ A ¨¨HH ¨¨ HH B C ¨H ¨¨ HH sings D E the ¨¨HH F G brown fox • Linguistic trees have nodes. The nodes in (1) are A, B, C, D, E, F, and G. • There are two kinds of nodes: internal nodes and terminal nodes. The internal nodes in (1) are A, B, and E. The terminal nodes are C, D, F, and G. Terminal nodes are so called because they are not expanded into anything further. The tree ends there. Terminal nodes are also called leaf nodes. The leaves of (1) are really the words that constitute the sentence ‘the brown fox sings’ i.e. ‘the’, ‘brown’, ‘fox’, and ‘sings’. (2) a. A set of nodes form a constituent iff they are exhaustively dominated by a common node. b. X is a constituent of Y iff X is dominated by Y. c. X is an immediate constituent of Y iff X is immediately dominated by Y. Notions such as subject, object, prepositional object etc. can be defined structurally. So a subject is the NP immediately dominated by S and an object is an NP immediately dominated by VP etc. (3) a. If a node X immediately dominates a node Y, then X is the mother of Y, and Y is the daughter of X. b. A set of nodes are sisters if they are all immediately dominated by the same (mother) node. -

'Until' and 'Before' Clauses: Zooming in on Linguistic Diversity
BALTIC LINGUISTICS ISSN 2081- 9 (2018), 141–2 ‘As long as’, ‘until’ and ‘before’ clauses: Zooming in on linguistic diversity Be W Stockholm University This paper investigates ‘before’, ‘until’ and ‘as long as’ clauses in the Baltic languages in their wider areal and genealogical context in a sample of 2 modern and ancient doculects of European and Indo-European languages. In a bottom-up construction of the semantic map of ‘before’, ‘until’ and ‘as long as’ connectors from parallel text data, a fourth cluster intermediate between ‘before’ and ‘until’ with negative main clauses is identified. The typology resulting from the different overlaps of clusters locates Baltic languages in an intermediate zone between Western, Eastern, and Northern European languages. This goes hand-in-hand with a high diversity of Baltic languages in their typology of ‘before’, ‘until’ and ‘as long as’ clauses. The temporal connectors found in Baltic varieties can be classified according to whether they originate from strategies expressing temporal identity (simultaneity) or non-identity (non-simultaneity). Many connectors in Baltic derive from correlative constructions and originally express iden- tity, but can then shift from simultaneity towards posteriority as they gradually lose their association with correlative constructions. Since temporal clauses are never at- emporal and are hence incompatible with permanent states and since negation often expresses permanent states, negation—a marker of non-identity—is prone to develop non-polarity functions in ‘before’ and ‘until’ clauses. The Baltic and Slavic languages are rich in various kinds of expanded negation (translation equivalents in other languages lack negation) and expletive negation (negation does not have the function of expressing negative polarity) in ‘before’ and ‘until’ clauses.