The Ultimate Guide to Using Azure Data Box with Hubstor
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

IBM Cloud Unit 2016 IBM Cloud Unit Leadership Organization
IBM Cloud Technical Academy IBM Cloud Unit 2016 IBM Cloud Unit Leadership Organization SVP IBM Cloud Robert LeBlanc GM Cloud Platform GM Cloud GM Cloud Managed GM Cloud GM Cloud Object Integration Services Video Storage Offering Bill Karpovich Mike Valente Braxton Jarratt Line Execs Line Execs Marie Wieck John Morris GM Strategy, GM Client Technical VP Development VP Service Delivery Business Dev Engagement Don Rippert Steve Robinson Harish Grama Janice Fischer J. Comfort (GM & CTO) J. Considine (Innovation Lab) Function Function Leadership Leadership VP Marketing GM WW Sales & VP Finance VP Human Quincy Allen Channels Resources Steve Cowley Steve Lasher Sam Ladah S. Carter (GM EcoD) GM Design VP Enterprise Mobile GM Digital Phil Gilbert Phil Buckellew Kevin Eagan Missions Missions Enterprise IBM Confidential IBM Hybrid Cloud Guiding Principles Choice with! Hybrid ! DevOps! Cognitive Powerful, Consistency! Integration! Productivity! Solutions! Accessible Data and Analytics! The right Unlock existing Automation, tooling Applications and Connect and extract workload in the IT investments and composable systems that insight from all types right place and Intellectual services to increase have the ability to of data Property speed learn Three entry points 1. Create! 2. Connect! 3. Optimize! new cloud apps! existing apps and data! any app! 2016 IBM Cloud Offerings aligned to the Enterprise’s hybrid cloud needs IBM Cloud Platform IBM Cloud Integration IBM Cloud Managed Offerings Offerings Services Offerings Mission: Build true cloud platform -
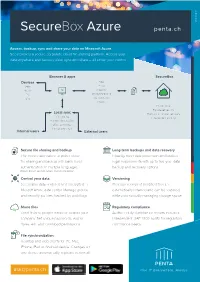
Securebox Azure
General Electronics E-Commerce General Web General General General Electronics General Location Electronics E-Commerce Electronics Electronics Arrows General Web Electronics E-Commerce E-Commerce E-Commerce Web Location GeneraE-Col mmerce Weather Web Arrows WeWeb b Electronics Location Weather Miscellaneous Location Arrows Location Location Arrows Arrows Miscellaneous Electronics E-Commerce Arrows Weather Weather Weather Miscellaneous Web 28/03/2019 Weather SecureBox Azure penta.ch General Miscellaneous Access, backup, sync and share your data on Microsoft Azure SecureBox is a secure corporate cloud file sharing platform. Access your data anywhere and backup, view, sync and share – all under your control. Miscellaneous E-Commerce Browser & apps General SecureBox Devices Files Tablet Email Mobile Calendar PC Word processing Mac Spreadsheets Miscellaneous Photos Private cloud Bank-level security Local sync Backups & disaster recovery File sharing Independent auditing Password protection Editing permissions Link expiry dates Internal users External users SecureLo filecati sharingon and backup Long-term backups and data recovery The secure alternative to public cloud Instantly meet data protection and backup file sharing and backup with bank-level legal requirements with up to five-year data authentication. In multiple languages. backup and recovery options. English, French, German, Italian, Spanish and Arabic Web Control your data Versioning SecureBox data is stored and encrypted in Previous version of modified files are Microsft Azure data center. Manage groups automatically retained and can be restored, and security policies, backed by audit logs. while automatically managing storage space. Share files Regulatory compliance Send Arrolinks to wspeople inside or outside your Auditor-ready compliance reports included. company. Set unique passwords, expiry IndependentElec ISAEtr onic3402 auditss for regulatory dates, edit and download permissions. -

Mimioclassroom User Guide for Windows
MimioClassroom User Guide For Windows mimio.com © 2012 Sanford, L.P. All rights reserved. Revised 12/4/2012. No part of this document or the software may be reproduced or transmitted in any form or by any means or translated into another language without the prior written consent of Sanford, L.P. Mimio, MimioClassroom, MimioTeach, MimioCapture, MimioVote, MimioView, MimioHub, MimioPad, and MimioStudio are registered marks in the United States and other countries. All other trademarks are the property of their respective holders. Contents About MimioClassroom 1 MimioStudio 1 MimioTeach 1 Mimio Interactive 1 MimioCapture 2 Mimio Capture Kit 2 MimioVote 2 MimioView 2 MimioPad 2 Minimum System Requirements 2 Using this Guide 3 MimioStudio 7 About MimioStudio 7 About MimioStudio Notebook 7 About MimioStudio Tools 7 About MimioStudio Gallery 9 Getting Started with MimioStudio 9 Accessing MimioStudio Notebook 9 Accessing MimioStudio Tools 10 Accessing MimioStudio Gallery 10 Using MimioStudio Notebook 10 Working with Pages 11 Creating an Activity 14 Creating an Activity - Step 1: Define 14 Creating an Activity - Step 2: Select 14 Creating an Activity - Step 3: Refine 15 Creating an Activity - Step 4: Review 16 Working with an Activity 17 Writing an Objective 17 Attaching Files 18 Using MimioStudio Tools 18 Creating Objects 18 Manipulating Objects 21 Adding Actions to Objects 25 Using MimioStudio Gallery 26 iii Importing Gallery Items into a Notebook 27 Customizing the Content of the Gallery 27 Exporting a Gallery Folder to a Gallery File 29 Working -

Wandisco Fusion® Microsoft Azure Data Box
WANDISCO FUSION® MICROSOFT AZURE DATA BOX Use WANdisco Fusion with Data Box for bulk transfer of changing data WANdisco Fusion is the only solution that enables Microsoft customers to use the bulk transfer capabilities of the Azure Data Box to transfer static and changing Guaranteed data consistency information from Big Data applications to Azure Cloud with guaranteed data consistency. Users can continue to Take advantage of the storage on Azure Data Box for write to their local cluster while the Azure Data Box is in bulk data transfer while continuing to write to a local transit so when the Azure Data Box is subsequently being cluster and replicate those changes while the Azure uploaded, any changes are replicated to the Azure Cloud Data Box is uploaded to the Azure Cloud. with guaranteed consistency. Easy and intuitive step-by-step operation • Applications write to Azure Data Box using the same API that they use to interact with the Azure Cloud. No downtime and • WANdisco Fusion for Azure Data Box requires no change to applications which can continue to use the no business disruption API as they would normally. Write data to a local HDFS-compatible endpoint • Replication is continuous and recovers from on-premises and replicate to a storage location in intermittent network or system failures automatically. Microsoft Azure with no modification or disruption to applications on-premises. AZURE 2 STORAGE Cost saving MICROSOFT 1 3 AZURE DATA BOX Avoid the high network costs common to large scale data transfers and benefit from a range of FUSION applications available in Azure Cloud. -

Lock-Free Collaboration Support for Cloud Storage Services With
Lock-Free Collaboration Support for Cloud Storage Services with Operation Inference and Transformation Jian Chen, Minghao Zhao, and Zhenhua Li, Tsinghua University; Ennan Zhai, Alibaba Group Inc.; Feng Qian, University of Minnesota - Twin Cities; Hongyi Chen, Tsinghua University; Yunhao Liu, Michigan State University & Tsinghua University; Tianyin Xu, University of Illinois Urbana-Champaign https://www.usenix.org/conference/fast20/presentation/chen This paper is included in the Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST ’20) February 25–27, 2020 • Santa Clara, CA, USA 978-1-939133-12-0 Open access to the Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST ’20) is sponsored by Lock-Free Collaboration Support for Cloud Storage Services with Operation Inference and Transformation ⇤ 1 1 1 2 Jian Chen ⇤, Minghao Zhao ⇤, Zhenhua Li , Ennan Zhai Feng Qian3, Hongyi Chen1, Yunhao Liu1,4, Tianyin Xu5 1Tsinghua University, 2Alibaba Group, 3University of Minnesota, 4Michigan State University, 5UIUC Abstract Pattern 1: Losing updates Alice is editing a file. Suddenly, her file is overwritten All studied This paper studies how today’s cloud storage services support by a new version from her collaborator, Bob. Sometimes, cloud storage collaborative file editing. As a tradeoff for transparency/user- Alice can even lose her edits on the older version. services friendliness, they do not ask collaborators to use version con- Pattern 2: Conflicts despite coordination trol systems but instead implement their own heuristics for Alice coordinates her edits with Bob through emails to All studied handling conflicts, which however often lead to unexpected avoid conflicts by enforcing a sequential order. -
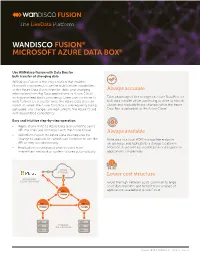
Wandisco Fusion® Microsoft Azure Data Box®
FUSION WANDISCO FUSION® MICROSOFT AZURE DATA BOX® Use WANdisco Fusion with Data Box for bulk transfer of changing data WANdisco Fusion is the only solution that enables Microsoft customers to use the bulk transfer capabilities of the Azure Data Box to transfer static and changing Always accurate information from Big Data applications to Azure Cloud with guaranteed data consistency. Users can continue to Take advantage of the storage on Azure Data Box for write to their local cluster while the Azure Data Box is in bulk data transfer while continuing to write to a local transit so when the Azure Data Box is subsequently being cluster and replicate those changes while the Azure uploaded, any changes are replicated to the Azure Cloud Data Box is uploaded to the Azure Cloud. with guaranteed consistency. Easy and intuitive step-by-step operation • Applications write to Azure Data Box using the same API that they use to interact with the Azure Cloud. Always available • WANdisco Fusion for Azure Data Box requires no change to applications which can continue to use the Write data to a local HDFS-compatible endpoint API as they would normally. on-premises and replicate to a storage location in • Replication is continuous and recovers from Microsoft Azure with no modification or disruption to intermittent network or system failures automatically. applications on-premises. AZURE 2 STORAGE Lower cost structure MICROSOFT 1 3 AZURE DATA BOX Avoid the high network costs common to large scale data transfers and benefit from a range of applications available in Azure Cloud. FUSION FUSION FUSION HADOOP ON-PREMISES Copyright © 2018 WANdisco, Inc. -

Igneous Backup with Microsoft Azure Data Box Executive Overview the Benefits of Cloud Backup, Including Scalability, Accessibility, and Agility, Are Immense
SOLUTION GUIDE Igneous Backup with Microsoft Azure Data Box Executive Overview The benefits of cloud backup, including scalability, accessibility, and agility, are immense. However, significant challenges lie in effectively deploying cloud backups for enterprise. To help enterprises harness the value of cloud backup while overcoming the challenges of massive scale, Igneous Unstructured Data Management as-a-Service and Microsoft Azure Data Box combine to offer an integrated solution that accelerates data migration from network attached storage (NAS) to Microsoft Azure Storage, and manages ongoing replication and tiering to cloud. With backup environments, the challenge of using public cloud is often seeding the initial backup before doing incrementals. Azure Data Box provides an economical way to transport those initial backups (often called “level- 0’s”) into Azure Storage without worrying about network bandwidth between your on-premises environment and Azure Storage. Igneous Unstructured Data Management as-a-Service solution, built for managing file-based backups, provides native integration with Azure Storage, including the Azure Data Box. Together, Igneous and Azure allow you to backup unstructured data stored on your primary network attached storage (NAS) file systems, efficiently move large amounts of data to Azure Storage, and protect and manage your data with tiering and replication to cloud. Microsoft Azure Data Box provides a secure, tamper-resistant method for quick and simple transfer of your data to Azure. Use Azure Data Box service when you want to transfer large amounts of data to Azure but are limited by time, network availability, or costs. Azure Data Box is supported by Igneous as a method to support transfers or initial sync to Azure Storage. -

Getting Started with Google Cloud Platform
Harvard AP275 Computational Design of Materials Spring 2018 Boris Kozinsky Getting started with Google Cloud Platform A virtual machine image containing Python3 and compiled LAMMPS and Quantum Espresso codes are available for our course on the Google Cloud Platform (GCP). Below are instructions on how to get access and start using these resources. Request a coupon code: Google has generously granted a number of free credits for using GCP Compute Engines. Here is the URL you will need to access in order to request a Google Cloud Platform coupon. You will be asked to provide your school email address and name. An email will be sent to you to confirm these details before a coupon code is sent to you. Student Coupon Retrieval Link • You will be asked for a name and email address, which needs to match the domain (@harvard.edu or @mit.edu). A confirmation email will be sent to you with a coupon code. • You can only request ONE code per unique email address. If you run out of computational resources, Google will grant more coupons! If you don’t have a Gmail account, please get one. Harvard is a subscriber to G Suite, so access should work with your @g.harvard.edu email and these were added already to the GCP project. If you prefer to use your personal Gmail login, send it to me. Once you have your google account, you can log in and go to the website below to redeem the coupon. This will allow you to set up your GCP billing account. -

The Effect of Film Sharing on P2P Networks on Box Office Sales
The effect of film sharing on P2P networks on box office sales Kęstutis Černiauskas Faculty of Computing Blekinge Institute of Technology SE-371 79 Karlskrona Sweden i This thesis is submitted to the Faculty of Computing at Blekinge Institute of Technology in partial fulfillment of the requirements for the degree of Master in Informatics (120 credits). Contact Information: Author(s): Kęstutis Černiauskas E-mail: [email protected] University advisor: Sara Eriksén Department Faculty of Computing Internet : www.bth.se Blekinge Institute of Technology Phone : +46 455 38 50 00 SE-371 79 Karlskrona, Sweden Fax : +46 455 38 50 57 ii ABSTRACT Context. Online piracy is widespread, controversial and poorly understood social phenomena that affects content creators, owners, and consumers. Online piracy, born from recent, rapid ITC changes, raises legal, ethical, and business challenges. Content owners, authors and content consumers should benefit from better understanding of online piracy. Improved, better adapted to marketplace and ITC changes content distribution models should benefit content owners and audiences. Objectives. Investigate online piracy effect on pirated product sales. Improve understanding of online piracy behaviors and process scale. Methods. This observational study investigated movie-sharing effect on U.S. box office. Movie sharing was observed over BitTorrent network, the most popular peer-to-peer file-sharing network. Relationship between piracy and sales was analyzed using linear regression model. Results. File sharing was found to have a slightly positive correlation with U.S. box office sales during first few weeks after film release, and no effect afterwards. Most of newly released movies are shared over BitTorrent network. -

IBM Storage Suite for IBM Cloud Paks Data Sheet
IBM Storage Suite for IBM Cloud Paks Data Sheet IBM Storage Suite for IBM Cloud Paks IBM Storage Suite for Cloud Paks offers Highlights a faster, more reliable way to modernize and move to the cloud • Flexible sofware-defined data resources for easy Today, 85% of enterprises around the world are already container deployments operating in a hybrid cloud environment.1 At the same time, • Reduce risk and complexity more than three-quarters of all business-critical workloads when moving mission- have yet to make the transition to the cloud.2 These metrics critical apps to the cloud suggest that for all the benefits conveyed by cloud • Market-leading Red Hat and computing, many organizations still face plenty of challenges award-winning IBM ahead to fully incorporate cloud-native solutions into their Spectrum Storage software core business environments. Containerization is a key enabling technology for flexibly delivering workloads to private and public clouds and DevOps. Among their many benefits, containers allow legacy applications to run in almost any host environment without being rewritten – an enormous advantage for enterprises with numerous applications, each composed of thousands of lines of code. To facilitate deployment of containerized workloads and development of new cloud-native applications, companies large and small are modernizing around platforms such as Red Hat OpenShift. IBM has developed a series of middleware tools called IBM Cloud Pak solutions designed to enhance and extend the functionality and capabilities of Red Hat OpenShift. The solutions include Cloud Pak for Data, Business Automation, Watson AIOps, Integration, Network Application, and Security, and give enterprises the fully modular and easy-to- consume capabilities they need to bring the next 80% of their workloads into modern, cloud-based environments. -

Salesforce Shield
Salesforce Shield Enhance protection, monitoring, and retention of critical Salesforce data Overview The State of Cloud Security Companies of all sizes and industries are using Salesforce across departments to run their businesses faster. As adoption of Salesforce for critical business capabilities grows, monitoring Security and user behavior, tracking changes to data, and preventing data privacy concerns loss is more important than ever. With more sensitive data in are the top the cloud, security and compliance requirements also become inhibitors IT organizations face increasingly complex. Salesforce Shield helps address these when trying to integrate requirements while allowing you to proactively monitor user data for a shared single activity and enforce security policies. view of customers.* Salesforce Shield provides enhanced protection, monitoring, and retention of your critical data stored in Salesforce. Improving security policies and practices is the top • Native Encryption: Natively encrypt your most sensitive data priority for IT teams while retaining critical app functionality including search, over the next 12 to 18 workflow, and validation rules. months.* • Detailed Data & Monitoring: Gain access to detailed performance, security, and usage data for your Salesforce 65% apps in order to monitor critical business data, understand of IT leaders plan on user adoption across your apps, and troubleshoot and increasing data stored in optimize custom application performance. the cloud over the next 12 - 18 months.* • Security Policies: Build flexible, customizable security policies that give IT the power to identify and prevent malicious activity in real time. Retain data history for forensic * Salesforce State of IT level compliance as well as greater operational insights into Report, 2017 your business. -

Private Cloud in the Hybrid Cloud Era
IBM Global Technology Services Thought Leadership White Paper Private cloud in the hybrid cloud era The critical choices driving business value and agility 2 Private cloud in the hybrid cloud era Contents Private clouds help lay the essential foundation for hybrid computing by putting in place much of the workload and 2 Executive summary management automation that will be needed. While an 3 Private cloud today increasing number of private cloud products are providing turnkey functionality right out of the box, optimal business 4 The road to hybrid computing agility depends on making the right service and technology 5 Private cloud: the core differentiators for your business choices. Capitalizing on the transformative potential of private cloud requires leveraging the differentiators that will drive 6 Speed exponential value down the road—differentiators like: 7 Dynamic scalability and flexibility • Standardized private cloud builds with the automation to 8 Optimization and efficiency deliver fully functional private clouds in days or weeks • Platform as a service (PaaS) models that dramatically speed 10 Security and resiliency application development and time to market 11 IBM expertise in the cloud • Self-service catalogs that provide the modular flexibility, easy scalability and customization to address rapidly 12 Conclusion changing needs 12 For more information • Open cloud architectures that enable hybrid cloud interoperability and provide a path to collaborative innovation Executive summary • Automated private cloud management that provides infrastructure-wide visibility across cloud and non-cloud Private clouds have become a major catalyst for business environments growth and differentiation while supporting organizations’ • Fully integrated security and resiliency management, with need to manage highly sensitive information.