A Sentiment Analysis of Gujarati Text Using Gujarati Senti Word Net
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Efficient Database Design for Indowordnet Development Using
An Efficient Database Design for IndoWordNet Development Using Hybrid Approach Venkatesh Prabhu2 Shilpa Desai1 Hanumant Redkar1 N eha Prabhugaonkar1 Apurva N agvenkar1 Ramdas Karmali1 (1) GOA UNIVERSITY, Taleigao - Goa (2) THYWAY CREATIONS, Mapusa - Goa [email protected], [email protected], [email protected], [email protected], [email protected], [email protected] ABSTRACT WordNet is a crucial resource that aids in Natural Language Processing (NLP) tasks such as Machine Translation, Information Retrieval, Word Sense Disambiguation, Multi-lingual Dictionary creation, etc. The IndoWordNet is a multilingual WordNet which links WordNets of different Indian languages on a common identification number given to each concept. WordNet is designed to capture the vocabulary of a language and can be considered as a dictionary cum thesaurus and much more. WordNets for some Indian Languages are being developed using expansion approach. In this paper we have discussed the details and our experiences during the evolution of this database design while working on the Indradhanush WordNet Project. The Indradhanush WordNet Project is working on the development of WordNets for seven Indian languages. Our database design gives an efficient plan for storage of WordNet data for all languages. In addition it extends the design to hold specific concepts for a language. KEYWORDS: WordNet, IndoWordNet, synset, database design, expansion approach, semantic relation, lexical relation. Proceedings of the 3rd Workshop on South and Southeast Asian Natural Language Processing (SANLP), pages 229–236, COLING 2012, Mumbai, December 2012. 229 1 Introduction 1.1 WordNet and its storage methods WordNet (Miller, 1993) maintains the concepts in a language, relations between concepts and their ontological details. -
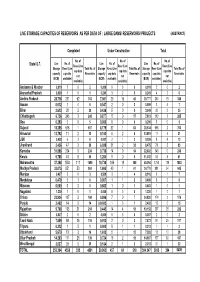
Live Storage Capacities of Reservoirs As Per Data of : Large Dams/ Reservoirs/ Projects (Abstract)
LIVE STORAGE CAPACITIES OF RESERVOIRS AS PER DATA OF : LARGE DAMS/ RESERVOIRS/ PROJECTS (ABSTRACT) Completed Under Construction Total No. of No. of No. of Live No. of Live No. of Live No. of State/ U.T. Resv (Live Resv (Live Resv (Live Storage Resv (Live Total No. of Storage Resv (Live Total No. of Storage Resv (Live Total No. of cap data cap data cap data capacity cap data Reservoirs capacity cap data Reservoirs capacity cap data Reservoirs not not not (BCM) available) (BCM) available) (BCM) available) available) available) available) Andaman & Nicobar 0.019 20 2 0.000 00 0 0.019 20 2 Arunachal Pradesh 0.000 10 1 0.241 32 5 0.241 42 6 Andhra Pradesh 28.716 251 62 313 7.061 29 16 45 35.777 280 78 358 Assam 0.012 14 5 0.547 20 2 0.559 34 7 Bihar 2.613 28 2 30 0.436 50 5 3.049 33 2 35 Chhattisgarh 6.736 245 3 248 0.877 17 0 17 7.613 262 3 265 Goa 0.290 50 5 0.000 00 0 0.290 50 5 Gujarat 18.355 616 1 617 8.179 82 1 83 26.534 698 2 700 Himachal 13.792 11 2 13 0.100 62 8 13.891 17 4 21 J&K 0.028 63 9 0.001 21 3 0.029 84 12 Jharkhand 2.436 47 3 50 6.039 31 2 33 8.475 78 5 83 Karnatka 31.896 234 0 234 0.736 14 0 14 32.632 248 0 248 Kerala 9.768 48 8 56 1.264 50 5 11.032 53 8 61 Maharashtra 37.358 1584 111 1695 10.736 169 19 188 48.094 1753 130 1883 Madhya Pradesh 33.075 851 53 904 1.695 40 1 41 34.770 891 54 945 Manipur 0.407 30 3 8.509 31 4 8.916 61 7 Meghalaya 0.479 51 6 0.007 11 2 0.486 62 8 Mizoram 0.000 00 0 0.663 10 1 0.663 10 1 Nagaland 1.220 10 1 0.000 00 0 1.220 10 1 Orissa 23.934 167 2 169 0.896 70 7 24.830 174 2 176 Punjab 2.402 14 -

Junagadh Agricultural University Junagadh-362 001
Junagadh Agricultural University Junagadh-362 001 Information Regarding Registered Students in the Junagadh Agricultural University, Junagadh Registered Sr. Name of the Major Minor Remarks Faculty Subject for the Approved Research Title No. students Advisor Advisor (If any) Degree 1 Agriculture Agronomy M.A. Shekh Ph.D. Dr. M.M. Dr. J. D. Response of castor var. GCH 4 to irrigation 2004 Modhwadia Gundaliya scheduling based on IW/CPE ratio under varying levels of biofertilizers, N and P 2 Agriculture Agronomy R.K. Mathukia Ph.D. Dr. V.D. Dr. P. J. Response of castor to moisture conservation 2005 Khanpara Marsonia practices and zinc fertilization under rainfed condition 3 Agriculture Agronomy P.M. Vaghasia Ph.D. Dr. V.D. Dr. B. A. Response of groundnut to moisture conservation 2005 Khanpara Golakia practices and sulphur nutrition under rainfed condition 4 Agriculture Agronomy N.M. Dadhania Ph.D. Dr. B.B. Dr. P. J. Response of multicut forage sorghum [Sorghum 2006 Kaneria Marsonia bicolour (L.) Moench] to varying levels of organic manure, nitrogen and bio-fertilizers 5 Agriculture Agronomy V.B. Ramani Ph.D. Dr. K.V. Dr. N.M. Efficiency of herbicides in wheat (Triticum 2006 Jadav Zalawadia aestivum L.) and assessment of their persistence through bio assay technique 6 Agriculture Agronomy G.S. Vala Ph.D. Dr. V.D. Dr. B. A. Efficiency of various herbicides and 2006 Khanpara Golakia determination of their persistence through bioassay technique for summer groundnut (Arachis hypogaea L.) 7 Agriculture Agronomy B.M. Patolia Ph.D. Dr. V.D. Dr. B. A. Response of pigeon pea (Cajanus cajan L.) to 2006 Khanpara Golakia moisture conservation practices and zinc fertilization 8 Agriculture Agronomy N.U. -

POTTERY ANALYSIS of Kuntasl CHAPTEH IV
CHAPTER IV POTTERY ANALYSIS OF KUNTASl CHAPTEH IV POTTBKY ANALYSIS OF KUNTASI IV-A. KUNTASI, A HARAPPAN SITE IN WESTKRN SAUKASHTKA IV-A-1. Gujarat and its regions The ancient site of Kuntasi (22" 53’ OO” N - 70“ :J2 ’ OO" H '; Taluka Maliya, Dislricl l^ajkot) lies about two kilomelres soulh- easl of the present village, on the right (north) bank of the meandering, ephemeral nala of Zinzoda. The village of Kuntasi lies just on the border of three districts, viz., Rajkot, Jamnagar and Kutch (Fig. 1). Geographically, Kuntasi is located at the north western corner of Saurashtra bordering Kutch, almost at the mouth of the Little Rann. Thus, the location of the site itself is very interesting and unique. Three regions of Gujarat^ : Gujarat is roughly divided into three divisions, namely Anarta (northern Gujarat), Lata (southern Gujarat from Mahi to Tapi rivers) and Saurashtra (Sankalia 1941: 4- 6; Shah 1968: 56-62). The recent anthropological field survey has also revealed major “ eco-cultural” zones or the folk regions perceived by the local people in Gujarat (North, South and Saurashtra) identical with the traditional divisions, adding Kutch as the fourth region (Singh 1992: 34 and Map 1). These divisions also agree well more or less with the physiographical divisions, which are also broadly divided into three distinct units, viz. the mainland or the plains of (North and South combined) Gujarat, the Saurashtra peninsular and Kutch (Deshpande 1992: 119)'. -72- The mainland or the plains of Gujarat is characleri zed by a flat tract of alluvium formed by the rivers such as Banas and Kupen X draining out into the Little Rann of Kutch, and Sabarmati, Mahi, Narmada, Tapi, etc.(all these rivers are almost perennial) into the Gulf of Khambhat. -

Exploring Resources in Word Sense Disambiguation for Marathi Language Amit Patil1, Chhaya Patil2, Dr
www.rspsciencehub.com Volume 02 Issue 10S October 2020 Special Issue of First International Conference on Advancements in Management, Engineering and Technology (ICAMET 2020) Exploring Resources in Word Sense Disambiguation for Marathi Language Amit Patil1, Chhaya Patil2, Dr. Rakesh Ramteke3, Dr. R. P. Bhavsar4, Dr. Hemant Darbari5 1,2 Assistant Professor, Department of Computer Application, RCPET’s IMRD, Maharashtra, India 3,4Professor, School of Computer Sciences, KBC North Maharashtra University, Maharashtra, India 5Director General, Centre for Development of Advanced Computing (C-DAC), Maharashtra, India Abstract Word Sense Disambiguation (WSD) is one of the most challenging problems in the research area of natural language processing. To find the correct sense of the word in a particular context is called Word Sense Disambiguation. As a human, we can get a correct sense of the word given in the sentence because of word knowledge of that particular natural language, but it is not an easy task for the machine to disambiguate the word. Developing any WSD system, it required sense repository and sense dictionary. It is very costly and time-consuming to build these resources. Many foreign languages have available these resources, that is why most of the foreign languages like English, German, Spanish etc lot of work is done in these Natural languages. When we look for Indian languages like Hindi, Marathi, Bengali etc. very less work is done. The reason behind this is resource-scarcity. In this paper, we majorly focus on Marathi Language Word Sense Disambiguation because of very less work is done in the Marathi Language as compared to Hindi and other Indian Languages. -

Reg. No Name in Full Residential Address Gender Contact No. Email Id Remarks 9421864344 022 25401313 / 9869262391 Bhaveshwarikar
Reg. No Name in Full Residential Address Gender Contact No. Email id Remarks 10001 SALPHALE VITTHAL AT POST UMARI (MOTHI) TAL.DIST- Male DEFAULTER SHANKARRAO AKOLA NAME REMOVED 444302 AKOLA MAHARASHTRA 10002 JAGGI RAMANJIT KAUR J.S.JAGGI, GOVIND NAGAR, Male DEFAULTER JASWANT SINGH RAJAPETH, NAME REMOVED AMRAVATI MAHARASHTRA 10003 BAVISKAR DILIP VITHALRAO PLOT NO.2-B, SHIVNAGAR, Male DEFAULTER NR.SHARDA CHOWK, BVS STOP, NAME REMOVED SANGAM TALKIES, NAGPUR MAHARASHTRA 10004 SOMANI VINODKUMAR MAIN ROAD, MANWATH Male 9421864344 RENEWAL UP TO 2018 GOPIKISHAN 431505 PARBHANI Maharashtra 10005 KARMALKAR BHAVESHVARI 11, BHARAT SADAN, 2 ND FLOOR, Female 022 25401313 / bhaveshwarikarmalka@gma NOT RENEW RAVINDRA S.V.ROAD, NAUPADA, THANE 9869262391 il.com (WEST) 400602 THANE Maharashtra 10006 NIRMALKAR DEVENDRA AT- MAREGAON, PO / TA- Male 9423652964 RENEWAL UP TO 2018 VIRUPAKSH MAREGAON, 445303 YAVATMAL Maharashtra 10007 PATIL PREMCHANDRA PATIPURA, WARD NO.18, Male DEFAULTER BHALCHANDRA NAME REMOVED 445001 YAVATMAL MAHARASHTRA 10008 KHAN ALIMKHAN SUJATKHAN AT-PO- LADKHED TA- DARWHA Male 9763175228 NOT RENEW 445208 YAVATMAL Maharashtra 10009 DHANGAWHAL PLINTH HOUSE, 4/A, DHARTI Male 9422288171 RENEWAL UP TO 05/06/2018 SUBHASHKUMAR KHANDU COLONY, NR.G.T.P.STOP, DEOPUR AGRA RD. 424005 DHULE Maharashtra 10010 PATIL SURENDRANATH A/P - PALE KHO. TAL - KALWAN Male 02592 248013 / NOT RENEW DHARMARAJ 9423481207 NASIK Maharashtra 10011 DHANGE PARVEZ ABBAS GREEN ACE RESIDENCY, FLT NO Male 9890207717 RENEWAL UP TO 05/06/2018 402, PLOT NO 73/3, 74/3 SEC- 27, SEAWOODS, -

Ahmedabad Sector
Office of the Chief Commissioner of Central Excise, Ahmedabad Zone, 7th Floor, Central Excise Bhavan, Near Polytechn_c, Ambavadi, Ahmedabad — 380 015 Email : ccuahmedabad gmail.com Fax: (079) 26303607 Tel.: (079) 26303612 Establishment Order No. 27 / 2014 Dated 13th June, 2014 Sub : Annual General Transfer — J014 in the grade of Inspector — Regarding The following Inspectors of Customs Gujarat Zone are hereby transferred and posted to Central Excise, Ahmedabad Ione with immediate effect and until further orders. Sr. Name of the Officer FroM To No. S/Shri 01 Shri Neeraj Singh Customs, Ahmedabad Ahmedabad Sector 02 Shri Manish Kumar Customs, Ahmedabad Ahmedabad Sector Singh 03 Shri Rupesh Kumar Customs, Ahm:xlabad Ahmedabad Sector Suman 04 Shri Rajendra Singh Customs, Ahmedabad Ahmedabad Sector 05 Shri Saurabh Prakash Customs, Ahmedabad Ahmedabad Sector 06 Shri Narendra Kumar Customs, Ah dabad Ahmedabad Sector Rai 07 Shri Nirmal Kumar Customs, Ahmedabad Ahmedabad Sector Jha 08 Shri Suraj Prakash Customs, Ahmedabad Ahmedabad Sector 09 Shri Sarvesh Kumar Customs, Ahmedabad Ahmedabad Sector Singh 10 Shri Jay Kumar Customs, Ahrr edabad Ahmedabad Sector Bishwas 11 Shri Narendra Kumar Customs, A edabad Ahmedabad Sector Meena 12 Shri Rakesh Devathia Customs, Ahniedabad Ahmedabad Sector 13 Shri Premraj Meena Customs, Ahrnedabad Ahmedabad Sector 14 Shri Navin Kumar Customs, Ahmedabad Ahmedabad Sector 15 Shri K.J. Acharya Customs, Kandla Ahmedabad Sector 16 Shri M.J. Shulda Customs, Kandla Ahmedabad Sector 17 Shri P.C. Dave Customs, Kandla Ahmedabad Sector 18 Shri L.C. Bodat Customs, Kandla Ahmedabad Sector 19 Shri B.S. Bhagora Customs, Karklla Ahmedabad Sector 20 Shri F.S. Shaikh Customs, Ka4dla Ahmedabad Sector ' Sr. -

DENA BANK.Pdf
STATE DISTRICT BRANCH ADDRESS CENTRE IFSC CONTACT1 CONTACT2 CONTACT3 MICR_CODE South ANDAMAN Andaman,Village &P.O AND -BambooFlat(Near bambooflat NICOBAR Rehmania Masjid) BAMBOO @denaban ISLAND ANDAMAN Bambooflat ,Andaman-744103 FLAT BKDN0911514 k.co.in 03192-2521512 non-MICR Port Blair,Village &P.O- ANDAMAN Garacharma(Near AND Susan garacharm NICOBAR Roses,Opp.PHC)Port GARACHAR a@denaba ISLAND ANDAMAN Garacharma Blair-744103 AMA BKDN0911513 nk.co.in (03192)252050 non-MICR Boddapalem, Boddapalem Village, Anandapuram Mandal, ANDHRA Vishakapatnam ANANTAPU 888642344 PRADESH ANANTAPUR BODDAPALEM District.PIN 531163 R BKDN0631686 7 D.NO. 9/246, DMM GATE ANDHRA ROAD,GUNTAKAL – 08552- guntak@denaba PRADESH ANANTAPUR GUNTAKAL 515801 GUNTAKAL BKDN0611479 220552 nk.co.in 515018302 Door No. 18 slash 991 and 992, Prakasam ANDHRA High Road,Chittoor 888642344 PRADESH CHITTOOR Chittoor 517001, Chittoor Dist CHITTOOR BKDN0631683 2 ANDHRA 66, G.CAR STREET, 0877- TIRUPA@DENA PRADESH CHITTOOR TIRUPATHI TIRUPATHI - 517 501 TIRUPATI BKDN0610604 2220146 BANK.CO.IN 25-6-35, OPP LALITA PHARMA,GANJAMVA ANDHRA EAST RI STREET,ANDHRA 939474722 KAKINA@DENA PRADESH GODAVARI KAKINADA PRADESH-533001, KAKINADA BKDN0611302 2 BANK.CO.IN 1ST FLOOR, DOOR- 46-12-21-B, TTD ROAD, DANVAIPET, RAJAHMUNDR ANDHRA EAST RAJAMUNDRY- RAJAHMUN 0883- Y@DENABANK. PRADESH GODAVARI RAJAHMUNDRY 533103 DRY BKDN0611174 2433866 CO.IN D.NO. 4-322, GAIGOLUPADU CENTER,SARPAVAR AM ROAD,RAMANAYYA ANDHRA EAST RAMANAYYAPE PETA,KAKINADA- 0884- ramanai@denab PRADESH GODAVARI TA 533005 KAKINADA BKDN0611480 2355455 ank.co.in 533018003 D.NO.7-18, CHOWTRA CENTRE,GABBITAVA RI STREET, HERO HONDA SHOWROOM LINE, ANDHRA CHILAKALURIPE CHILAKALURIPET – CHILAKALU 08647- chilak@denaban PRADESH GUNTUR TA 522616, RIPET BKDN0611460 258444 k.co.in 522018402 23/5/34 SHIVAJI BLDG., PATNAM 0836- ANDHRA BAZAR, P.B. -

WWDS Apis: Application Programming Interfaces for Efficient Manipulation of World Wordnet Database Structure
Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16) WWDS APIs: Application Programming Interfaces for Efficient Manipulation of World WordNet Database Structure Hanumant Redkar1, Sudha Bhingardive1, Kevin Patel1, Pushpak Bhattacharyya1 Neha Prabhugaonkar2, Apurva Nagvenkar2, Ramdas Karmali2 1Indian Institute of Technology Bombay, Mumbai, India 2Goa University, Goa, India {hanumantredkar, bhingardivesudha, kevin.svnit, pushpakbh}@gmail.com {nehapgaonkar.1920, apurv.nagvenkar, ramdas.karmali}@gmail.com Abstract example, developers can potentially extract information WordNets are useful resources for natural language from other WordNets through WWDS and its APIs that is processing. Various WordNets for different languages have missing in their source WordNet. The WWDS and WWDS been developed by different groups. Recently, World APIs are explained in the following sections. WordNet Database Structure (WWDS) was proposed by Redkar et. al (2015) as a common platformm to store these different WordNets. However, it is underutilized due to lack World WordNet Database Structure of programming interface. In this paper, we present WWDS APIs, which are designed to address this shortcoming. These WWDS is an efficient storage mechanism which uses WWDS APIs, in conjunction with WWDS, act as a wrapper that enables developers to utilize WordNets without multiple databases to accommodate different WordNets. Its worrying about the underlying storage structure. The APIs design is based on IndoWordNet database structure are developed in PHP, Java, and Python, as they are the (Prabhu et al., 2012). The language independent preferred programming languages of most developers and information such as semantic relations, ontology details, researchers working in language technologies. These APIs etc. is stored in a single master database named can help in various applications like machine translation, word sense disambiguation, multilingual information wordnet_master. -

'A Study of Tourism in Gujarat: a Geographical Perspective'
‘A Study of Tourism in Gujarat: A Geographical Perspective” CHAPTER-2 GEOGRAPHICAL PROFILE OF THE STUDY AREA ‘A Study of Tourism in Gujarat: A Geographical Perspective’ 2.1 GUJARAT : AN INTRODUCTION Gujarat has a long historical and cultural tradition dating back to the days of the Harappan civilization established by relics found at Lothal(Figure-1).It is also called as the “Jewel of the West”, is the westernmost state of India(Figure-2). The name “Gujarat” itself suggests that it is the land of Gurjars, which derives its name from ‘Gujaratta’ or ‘Gujaratra’ that is the land protected by or ruled by Gurjars. Gurjars were a migrant tribe who came to India in the wake of the invading Huna’s in the 5th century. The History of Gujarat dates back to 2000 BC. Some derive it from ‘Gurjar-Rashtra’ that is the country inhabited by Gurjars. Al-Beruni has referred to this region as ‘Gujratt’. According to N.B. Divetia the original name of the state was Gujarat & the above- mentioned name are the Prakrit& Sanskrit forms respectively. The name GUJARAT, which is formed by adding suffix ‘AT’ to the word ‘Gurjar’ as in the case of Vakilat etc. There are many opinions regarding the arrivals of Gurjars, two of them are, according to an old clan, they inhabited the area during the Mahabharat period and another opined that they belonged to Central Asia and came to India during the first century. The Gurjars passed through the Punjab and settled in some parts of Western India, which came to be known as Gujarat.Gujarat was also inhabited by the citizens of the Indus Valley and Harappan civilizations. -

Comparative Study on Currently Available Wordnets
International Journal of Applied Engineering Research ISSN 0973-4562 Volume 13, Number 10 (2018) pp. 8140-8145 © Research India Publications. http://www.ripublication.com Comparative Study on Currently Available WordNets Sreedhi Deleep Kumar Reshma E U PG Scholar PG Scholar Department of Computer Science and Engineering Department of Computer Science and Engineering Vidya Academy of Science and Technology Vidya Academy of Science and Technology Thrissur, India. Thrissur, India. Sunitha C Amal Ganesh Associate Professor Assistant Professor Department of Computer Science and Engineering Department of Computer Science and Engineering Vidya Academy of Science and Technology Vidya Academy of Science and Technology Thrissur, India. Thrissur, India. Abstract SinoTibetan, Tibeto-Burman and Austro-Asiatic. The major ones are the Indo-Aryan, spoken by the northern to western WordNet is an information base which is arranged part of India and Dravidian, spoken by southern part of India. hierarchically in any language. Usually, WordNet is The Eighth Schedule of the Indian Constitution lists 22 implemented using indexed file system. Good WordNets languages, which have been referred to as scheduled available in many languages. However, Malayalam is not languages and given recognition, status and official having an efficient WordNet. WordNet differs from the encouragement. dictionaries in their organization. WordNet does not give pronunciation, derivation morphology, etymology, usage notes, A Dictionary can be called as are source dealing with the or pictorial illustrations. WordNet depicts the semantic relation individual words of a language along with its orthography, between word senses more transparently and elegantly. In this pronunciation, usage, synonyms, derivation, history, work, a general comparison of currently browsable WordNets etymology, etc. -

Rasa and Garba in the Arts of Gujarat 1
Rasa and Garba in the Arts of Gujarat 1 Jyotindra Jain Rasa and garba are two interrelated and exceedingly popular forms of dance in Gujarat. The purpose of this article is not so much to trace the general chronology of rasa and garba from literary evidence as to examine the local Gujarati varieties of these dance forms in relation to their plastic and pictorial depictions. Literary sources, however graphic in description, do not always provide an accurate picture of the visual aspects of dance. Therefore rasa and garba as depicted in the visual arts of Gujarat might serve as a guide to an understanding of some features of these dances otherwise not easy to construe. Dr. Kapila Vatsyayan2 has given a sufficiently exhaustive and analytical account of rasa as described in the Harivamsha, Vishnu Purana, Shrimad Bhagavata and Brahma Vaivarta Purana as well as the commentaries of Nilakantha on the Puranas. Vasant Yamadagni3 and Ramanarayana Agrawal4 have published full-fledged monographs on the rasaleela of Vraja and other related subjects. The aspects covered by them will not be dealt with in this article. The descriptions of rasa in the Puranas make it clear that it is a circle-dance in which the participants move with hands interlocked. It appears that rasa included several types of circle-dances: ( 1) Those where several gopi-s formed a circle with Krishna in the centre; 5 (2) Those where Radha and Krishna danced as a pair together with other gopi-s or other pairs of gopa-s and gopi-s;6 (3) Those where Krishna multiplied himself and actually danced between two gopi-s thus forming a ring with one gopi and one Krishna.