Mapping at 30 M Resolution of Soil Attributes at Multiple Depths in Midwest Brazil
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
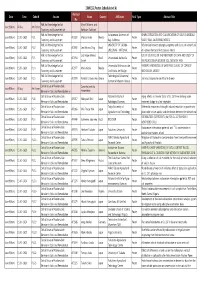
Poster Presentation Schedule
20WCSS_Poster Schedule(vol.6) Abstract Date Time Code-N Session Name Country Affiliation Final Type Abstract Title No Folk Soil Knowledge for Soil Myriel Milicevic and June 9(Mon) All day Art Poster Taxonomy and Assessment-art Ruttikorn Vuttikorn Folk Soil Knowledge for Soil Autonomous University of CHARACTERIZATION AND CLASSIFICATION OF SOILS IN MEXICALI June 9(Mon) 15:30~16:20 P1-1 AF2388 Monica Aviles Mexico Poster Taxonomy and Assessment Baja California VALLEY, BAJA CALIFORNIA, MEXICO Folk Soil Knowledge for Soil UNIVERSITY OF CUIABA - Relationship between phytophysiognomy and classes of wetland soil June 9(Mon) 15:30~16:20 P1-2 AF2892 Leo Adriano Chig Brazil Poster Taxonomy and Assessment UNIC/INAU - NATIONAL of northern Pantanal Mato Grosso - Brazil Folk Soil Knowledge for Soil Luiz Felipe Moreira USE OF SIG TOOLS IN THE TREATMENT OF DATA AND STUDY OF June 9(Mon) 15:30~16:20 P1-3 AF2934 Brazil Universidade de Brasilia Poster Taxonomy and Assessment Cassol THE RELATIONSHIP BETWEEN SOIL, GEOLOGY AND Folk Soil Knowledge for Soil Universidad Michoacana de FARMER'S KNOWLEDGE OF LAND AND CLASSES OF CORN OF June 9(Mon) 15:30~16:20 P1-4 AF2977 Maria Alcala Mexico Poster Taxonomy and Assessment San Nicolas de Hidalgo MICHOACAN, MEXICO Folk Soil Knowledge for Soil Technological Educational June 9(Mon) 15:30~16:20 P1-5 AF2979 Pantelis E. Barouchas Greece Poster Soil mass balance for an Alfisol in Greece Taxonomy and Assessment Institute of Western Greece Critical Issues of Radionuclide Center for Land Use June 9(Mon) All day Art Poster Behavior -

Pedometric Mapping of Key Topsoil and Subsoil Attributes Using Proximal and Remote Sensing in Midwest Brazil
UNIVERSIDADE DE BRASÍLIA FACULDADE DE AGRONOMIA E MEDICINA VETERINÁRIA PROGRAMA DE PÓS-GRADUAÇÃO EM AGRONOMIA PEDOMETRIC MAPPING OF KEY TOPSOIL AND SUBSOIL ATTRIBUTES USING PROXIMAL AND REMOTE SENSING IN MIDWEST BRAZIL RAÚL ROBERTO POPPIEL TESE DE DOUTORADO EM AGRONOMIA BRASÍLIA/DF MARÇO/2020 UNIVERSIDADE DE BRASÍLIA FACULDADE DE AGRONOMIA E MEDICINA VETERINÁRIA PROGRAMA DE PÓS-GRADUAÇÃO EM AGRONOMIA PEDOMETRIC MAPPING OF KEY TOPSOIL AND SUBSOIL ATTRIBUTES USING PROXIMAL AND REMOTE SENSING IN MIDWEST BRAZIL RAÚL ROBERTO POPPIEL ORIENTADOR: Profa. Dra. MARILUSA PINTO COELHO LACERDA CO-ORIENTADOR: Prof. Titular JOSÉ ALEXANDRE MELO DEMATTÊ TESE DE DOUTORADO EM AGRONOMIA BRASÍLIA/DF MARÇO/2020 ii iii REFERÊNCIA BIBLIOGRÁFICA POPPIEL, R. R. Pedometric mapping of key topsoil and subsoil attributes using proximal and remote sensing in Midwest Brazil. Faculdade de Agronomia e Medicina Veterinária, Universidade de Brasília- Brasília, 2019; 105p. (Tese de Doutorado em Agronomia). CESSÃO DE DIREITOS NOME DO AUTOR: Raúl Roberto Poppiel TÍTULO DA TESE DE DOUTORADO: Pedometric mapping of key topsoil and subsoil attributes using proximal and remote sensing in Midwest Brazil. GRAU: Doutor ANO: 2020 É concedida à Universidade de Brasília permissão para reproduzir cópias desta tese de doutorado e para emprestar e vender tais cópias somente para propósitos acadêmicos e científicos. O autor reserva outros direitos de publicação e nenhuma parte desta tese de doutorado pode ser reproduzida sem autorização do autor. ________________________________________________ Raúl Roberto Poppiel CPF: 703.559.901-05 Email: [email protected] Poppiel, Raúl Roberto Pedometric mapping of key topsoil and subsoil attributes using proximal and remote sensing in Midwest Brazil/ Raúl Roberto Poppiel. -- Brasília, 2020. -

Impact of Heathland Restoration and Re-Creation Techniques on Soil Characteristics and the Historical Environment
Natural England Research Report NERR010 Impact of heathland restoration and re-creation techniques on soil characteristics and the historical environment www.naturalengland.org.uk Natural England Research Report NERR010 Impact of heathland restoration and re-creation techniques on soil characteristics and the historical environment Hawley, G.1, Anderson, P. 1, Gash, M. 1, Smith, P. 1, Higham, N. 2, Alonso, I. 3, Ede, J.3 & Holloway, J.3 1 Independent consultant, 2 University of Manchester and 3 Natural England Published on 28 March 2008 The views in this report are those of the authors and do not necessarily represent those of Natural England. You may reproduce as many individual copies of this report as you like, provided such copies stipulate that copyright remains with Natural England, 1 East Parade, Sheffield, S1 2ET ISSN 1754-1956 © Copyright Natural England 2008 Project details This report results from research commissioned by Natural England in order to provide information on the impact of heathland restoration and re-creation activities on the soils and archaeology. The work was undertaken under Natural England contract FST20-84-010 by the following team: Penny Anderson (Managing Director Penny Anderson Associates Ltd (PAA); Gerard Hawley (Senior Soil Scientist, PAA); Mark Gash (Ecologist, PAA); Phil Smith (Senior Ecologist, PAA) and Nick Higham (Professor of Early Medieval and Landscape History, University of Manchester). Isabel Alonso (Heathland Ecologist, Natural England), Joy Ede (Historic Environment Advisor, Natural England) and Julie Holloway (Senior Soil Specialist, Natural England) provided contacts, information, references and edited the report. A summary of the findings covered by this report, as well as Natural England's views on this research, can be found within Natural England Research Information Note RIN010: Impact of heathland restoration and re-creation techniques on soil characteristics and the historical environment. -

Economic Valuation of Soil Functions: Phase 1
Economic Valuation of Soil Functions Phase 1: Literature Review and Method Development Prepared for: Defra Prepared by: David Harris, ADAS Boxworth, Battlegate Road, Boxworth, Cambridge, CB3 8NN Dr. Bob Crabtree, CJC Consulting, Oxford John King, ADAS Boxworth Paul Newell-Price, ADAS Gleadthorpe Date: July 2006 Copyright The proposed approach and methodology is protected by copyright and no part of this document may be copied or disclosed to any third party, either before or after the contract is awarded, without the written consent of ADAS. 0936648 Economic Valuation of Soil Functions Phase 1: Literature Review and Method Development Glossary of Terms ALC Agricultural Land Classification AONB Area of Outstanding Natural Beauty BMP Best Management Practice generally defined by being within the Codes of Good Agricultural Practice for Air, Water and Soil, COGAP (Defra) Brickfield series An imperfectly drained soil with a fine loamy texture CAP Common Agricultural Policy Clifton series An imperfectly drained, medium to coarse-textured soil with a perched water table Cu Copper CV Contingent valuation DE Direct energy used in fuel for field operations Defra Department for Environment, Food and Rural Affairs DoE Department of the Environment (now part of Defra and distinct from the Environment Agency) Dunkeswick series A poorly drained soil with a fine loamy topsoil, and a clay subsoil beginning at between 40 and 80 cm depth ELS Entry Level Scheme of Environmental Stewardship Scheme ESA Environmentally Sensitive Area FIOs Faecal indicator organisms -

Introduction to Soils and Pedology
Introduction to Soils and Pedology • Coined in mid 19th Century by French scientist • DidDerived from Gree k: pedon=ground, log ia = discour se • “The study, in situ, of the biogeochemical processes that form and dbdistribute soil”ls” • An observational, vs. an experimental, science - nature is the laboratory • Origins attributed to two centers: Russia (Dokuchaev) and Berkeley (Hilgard) Definition of Soils • Many definitions •Soil is part of a continuum of materials at earth’ surface –Soil vs. non-soil at bottom and top –Different soils laterally •Need to divide continuum into systems, or discrete seggyments, for study •Hans Jenny (1930’s) conceptualized soils as physical systems amenable and susceptible to physical variables (STATE FACTORS) ElEcological functions of soil • Supports plant growth • Recycles nutrients and waste • Controls the flow and purity of water • Provid es habit a t for soil organisms • Functions as a building material/base Role of Pedology in Scientific and Societal Problems •Carbon and nitrogen cycles •Are soils part of an unidentified sink for CO2? •What is the effect of agricultural on soil C (and atm CO2)? •Will soils store excess N from human activity? •Chemi st ry of natural waters •How do soils release elements with time and space? •Earth history •‘Paleosols’ and evolution of land plants, atmospheric CO2 records, human evolution •Soils and archaeology •Biodiversity •Is soil diversity analogous to, and complementary to, biodiversity •Microorganisms in soil represent unknown biodiversity resources Soils as a -

Soils As Pacemakers and Limiters of Global Silicate Weathering
Originally published as: Dixon, J. L., von Blanckenburg, F. (2012): Soils as pacemakers and limiters of global silicate weathering. ‐ Comptes Rendus Geoscience, 344, 11 ‐ 12, 597‐609 DOI: 10.1016/j.crte.2012.10.012 Soils as pacemakers and limiters of global silicate weathering Jean L. Dixon1,2 and Friedhelm von Blanckenburg1 1 Helmholtz Centre Potsdam, GFZ German Centre for Geosciences, Telegraphenberg, 14473 Potsdam, Germany 2 Department of Geography, University of California, Santa Barbara, CA 93106, USA Keywords: chemical weathering, soil production, speed limits, erosion, regolith, river fluxes Comptes rendus – Geosciences 344, 597-609, 2012 Abstract The weathering and erosion processes that produce and destroy regolith are widely recognized to be positively correlated across diverse landscapes. However, conceptual and numerical models predict some limits to this relationship that remain largely untested. Using new global data compilations of soil production and weathering rates from cosmogenic nuclides and silicate weathering fluxes from global rivers, we show that the weathering- erosion relationship is capped by certain ‘speed limits’. We estimate a soil production speed limit of between 320 to 450 t km-2 y-1 and the associated weathering rate speed limit of roughly 150 t km-2 y-1. These limits appear to be valid for a range of lithologies, and also extend to mountain belts, where soil cover is not continuous and erosion rates outpace soil production. We argue that the presence of soil and regolith is a requirement for high weathering fluxes from a landscape, and that rapidly eroding, active mountain belts are not the most efficient sites for weathering. -

Table of Contents
Table of Contents ............................................................................................................................................................ 1 1. 1.2. Geographic interpretation of the concept of the environment ........................................ 7 1.1. 1.3. The system-based approach of the geographical environment .......................... 9 1.2. 1.4. The assessment of landscape and environment ................................................ 11 1.3. 2.1. Ecosystem models ........................................................................................... 13 1.4. 2.2. Dividing the landscape into subsystems .......................................................... 15 1.5. 2.3. The landscape ecosystem and its sub-systems ................................................. 20 1.5.1. 4.1.1. Biological ecology ........................................................................... 26 1.5.2. 4.1.2. Geoecology and landscape ecology ................................................. 32 1.6. 4.2. Ecosystem research in biology ........................................................................ 33 1.7. 5.1. Lithological conditions .................................................................................... 36 1.8. 5.2. Relief as a landscape forming factor ................................................................ 42 1.9. 5.3 Soil as a landscape forming factor .................................................................... 54 1.10. 5.4. Water as a landscape factor .......................................................................... -

Dissertation
Spatial Patterns of Soil Characteristics and Soil Formation in the transitional landscape zone, central part of Bogowonto Catchment, Java, Indonesia DISSERTATION zur Erlangung des Akademischen Grades einer Doktorin der Naturwissenschaften am Institut für Geographie der Fakultät für Geo-und Atmosphärenwissenschaften der Leopold Franzens-Universität, Innsbruck eingereicht von Nur Ainun Harlin Pulungan Betreuung: Univ. Prof. Johann Stötter (Institut für Geographie, Innsbruck) Assoz. Prof. Clemens Geitner (Institut für Geographie, Innsbruck) Prof. Junun Sartohadi (Fakultät für Geographie, UGM, Yogyakarta) Innsbruck, 2016 Leopold-Franzens-Universität Innsbruck Eidesstattliche Erklärung Ich erkläre hiermit an Eides statt durch meine eigenhändige Unterschrift, dass ich die vorliegende Arbeit selbständig verfasst und keine anderen als die angegebenen Quellen und Hilfsmittel verwendet habe. Alle Stellen, die wörtlich oder inhaltlich den angegebenen Quellen entnommen wurden, sind als solche kenntlich gemacht. Die vorliegende Arbeit wurde bisher in gleicher oder ähnlicher Form noch nicht als Magister- /Master-/Diplomarbeit/Dissertation eingereicht. 28.10.2016 Datum Unterschrift ACKNOWLEDGEMENTS I would like to thank to all those who supported the study and made this dissertation possible. Without their excellent guidance, encouragement, caring, patience, and effort, this study could have been never accomplished. To all persons who are mentioned or cannot be mentioned by name in this page, I am greatly indebted. First of all, I express my sincere gratitude to my first supervisor, Professor Johann Stötter for his valuable guidance, taught, and ideas to my scientific work, also for providing me with very kind atmosphere for doing research from the beginning until the end of this study. I also would like to thank to Assoc.Professor Clemens Geitner for his valuable comments, enormous advises that improve the quality of this work a lot, and particularly for supporting me doing laboratory research. -

INTRODUCTION the 4-H Soil Activity Guide Has Been Designed with Two
INTRODUCTION The 4-H Soil Activity Guide has been designed with two age groups in mind: Junior: 8 to 10 years of age Intermediate: 11 to 14 years of age Each activity has been designed for both age groups. These activities are meant for members to have an opportunity to learn, evaluate, make decisions, communicate and develop confidence. Each activity has the following format: Title Topic Learning Outcomes Time Materials/Resources Instructions Suggestions Discussion/Comments Processing Prompts Each activity in the 4-H Soil Activity Project has learning outcomes identified at the beginning of the activity, and processing prompts at the end. To gain a better understanding of why these were added to every activity, we have included the following section about experiential learning. Experiential Learning Experiential learning is a model that, simply put, consists of action and reflection. Research show that learning is often best achieved when it is fun, active, interesting and easy to understand. Participating in fun activities creates a sense of togetherness within a group, helping members relate to one another as well as allowing the group to relax, feel safe and at ease. Through guided reflection and discussion, activities with meaning often help individuals understand concepts and skills more than if the same meaning was presented in a lecture format. A leader can help 4-H members and groups learn by leading activities with meaning. These activities can then be processed to help the group find the meaning. These lessons can then be applied to other areas of the members’ lives – helping them to transfer the meaning from the activity to the real world and every day life. -

“Soil Wallet”? Do We Think of the Soil on Our Farm As a Valuable Asset?
What’s in your “Soil Wallet”? Do we think of the soil on our farm as a valuable asset? The amount of “green” in our “soil wallet” can be variable! Identifying soil factors begins the process of determining its potential value. Soil formation is based on the following soil factors: parent material, climate, topography, biological affects and length of development. Differences in soil formation dictates differences in potential soil account values. Management decisions determine a high or low performing soil account. Monitoring the value in our “soil account” is vital to the success of our farm now and in the future. To better understand the true value of our soil, let’s compare a soil account to an investment account. Start by identifying the balance of one of your investment accounts. The goal is to gain interest or “value” through the invested money. Decisions we make affect whether the account will gain, maintain or lose value. Losing value in the account is really painful and maintaining value is rather pointless, so we position our account to gain value! What about your farm’s soil account? Are you gaining, maintaining or losing value in it? Changes in available technology and the collection of research based outcomes, gives us new tools to better manage our soil. Can you afford to only maintain the value of your soil account? What about lose value in your soil account? To become resilient and able to withstand a wide range of weather extremes, pest pressure and economic stressors, soil accounts must consistently gain value! Avoiding direct loss to a soil account has been the work of soil conservation practices for years. -

Valuing Soil's Economic Worth
Valuing Soil’s Economic Worth Matthew Oliver Ralp Loria Dimal VALUING SOIL’S ECONOMIC WORTH DISSERTATION to obtain the degree of doctor at the University of Twente, on the authority of the rector magnificus, prof.dr. T.T.M. Palstra, on account of the decision of the Doctorate Board, to be publicly defended on Wednesday 6 February 2019 at 12.45 hrs by Matthew Oliver Ralp Loria Dimal born on 9 April 1984 in Manila, Philippines This thesis has been approved by Prof.dr. V.G. Jetten, supervisor ITC dissertation number 342 ITC, P.O. Box 217, 7500 AE Enschede, The Netherlands ISBN 978-90-365-4723-9 DOI 10.3990/1.9789036547239 Cover designed by Job Duim Printed by ITC Printing Department Copyright © 2019 by M.O.R.L. Dimal Graduation committee: Chairman/Secretary Prof.dr.ir. A. Veldkamp Supervisor Prof.dr. V.G. Jetten University of Twente Member(s) Prof.dr. P.Y. Georgiadou University of Twente Prof.dr. T. Filatova University of Twente Prof.dr. C.J. Ritsema Wageningen University Dr.ir. L. Fleskens Wageningen University “The soil is the great connector of lives, the source and destination of all. It is the healer and restorer and resurrector, by which disease passes into health, age into youth, death into life. Without proper care for it we can have no community, because without proper care for it we can have no life.” Wendell Berry (1977) Acknowledgements I would like to express my deepest gratitude to my promoter and supervisor, Prof. Victor Jetten, for the guidance, the support and the willingness of helping me find clarity on my work. -

How Valuable Is the Soil Resource? How Can We Measure It? How Can We Communicate Its Value to the Public? ISRIC Spring School 2019
How valuable is the soil resource? How can we measure it? How can we communicate its value to the public? ISRIC Spring School 2019 David G Rossiter Guest Researcher, ISRIC { World Soil Information (NL) Adjunct Associate Professor, Section of Soil & Crop Sciences, Cornell University (USA) Visiting Professor, Nanjing Normal University (PRC) 24{May{2019 Concepts of Value Valuation Land evaluation Ecosystem Approach Communicating value Outline 1 Concepts of Value 2 Valuation 3 Land evaluation 4 Ecosystem Approach 5 Communicating value Concepts of Value Valuation Land evaluation Ecosystem Approach Communicating value Reference Rossiter, D. G., Hewitt, A. E., & Dominati, E. J. (2018). Pedometric Valuation of the Soil Resource. In Pedometrics (pp. 521{546). Springer https://doi.org/10.1007/978-3-319-63439-5_17 Alan Hewitt: Manaaki Whenua { Landcare Research, New Zealand Estelle Dominati: AgResearch Grasslands, Palmerston North, New Zealand Progress in Soil Science Alex. B. McBratney Budiman Minasny Uta Stockmann Editors Pedometrics Concepts of Value Valuation Land evaluation Ecosystem Approach Communicating value Outline 1 Concepts of Value 2 Valuation 3 Land evaluation 4 Ecosystem Approach 5 Communicating value Concepts of Value Valuation Land evaluation Ecosystem Approach Communicating value Concepts of \Value" \Nowadays people know the price of everything and the value of nothing" Oscar Wilde { The Picture of Dorian Gray, 1890 Concepts of Value Valuation Land evaluation Ecosystem Approach Communicating value Soils in the Sustainable Development