District Concordance Note the CEDA Portal Contains Data Across a Number of Time Periods Ranging from 1999 Upto 2017-18 at District Level
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supply Chain Analysis of Onion and Cauliflower in Punjab
Agricultural Economics Research Review Vol. 23 (Conference Number) 2010 pp 445-453 Supply Chain Analysis of Onion and Cauliflower in Punjab R.S. Sidhu*, Sanjay Kumar, Kamal Vatta and Parminder Singh Department of Economics and Sociology, Punjab Agricultural University, Ludhiana – 141 004, Punjab Abstract The present study was conducted in Rajpura block of Patiala district in Punjab with a sample of 50 vegetables growers. The total cost of cultivation was estimated at Rs 49563/ha for onion and Rs 34840/ha for cauliflower. The net returns were found higher for onion (Rs 74597/ha) as compared to that from cauliflower (Rs 38072/ha). Majority of these vegetables were being disposed off through commission agent/wholesaler (more than 90 per cent) followed by retailer and directly to the consumer. The efficiency of the these market channels can be enhanced through competition by organized retail chains and modernizing the vegetable market system in the state. The wholesale markets of Pune, Ludhiana and Patiala for onion and that of Shimla, Ludhiana and Patiala for cauliflower have been found integrated with price of onion and cauliflower transmitting quickly from the independent to the dependent markets. The highest elasticity of price transmission in onion has been observed between Ludhiana and Patiala markets with almost 90 per cent of the price change in Ludhiana getting transmitted to the Patiala market. Such transmission has been 100 per cent for cauliflower between Shimla and Patiala markets. The price transmission has been observed faster in cauliflower than onion. Though a long-term equilibrium relationship exists between all the studied markets in terms of weekly price of the two vegetables crops, there also exists a short-run disequilibrium between some of the market pairs with almost 15 to 25 per cent of the fluctuations usually getting corrected within a week. -

List of Registered Projects in RERA Punjab
List of Registered Real Estate Projects with RERA, Punjab as on 01st October, 2021 S. District Promoter RERA Type of Contact Details of Project Name Project Location Promoter Address No. Name Name Registration No. Project Promoter Amritsar AIPL Housing G T Road, Village Contact No: 95600- SCO (The 232-B, Okhla Industrial and Urban PBRERA-ASR02- Manawala, 84531 1. Amritsar Celebration Commercial Estate, Phase-III, South Infrastructure PC0089 Amritsar-2, Email.ID: Galleria) Delhi, New Delhi-110020 Limited Amritsar [email protected] AIPL Housing Village Manawala, Contact No: 95600- # 232-B, Okhla Industrial and Urban Dream City, PBRERA-ASR03- NH1, GT Road, 84531 2. Amritsar Residential Estate, Phase-III, South Infrastructure Amritsar - Phase 1 PR0498 Amritsar-2, Email.ID: Delhi, New Delhi-110020 Limited Punjab- 143109 [email protected] Golf View Corporate Contact No: 9915197877 Alpha Corp Village Vallah, Towers, Sector 42, Golf Model Industrial PBRERA-ASR03- Email.ID: Info@alpha- 3. Amritsar Development Mixed Mehta Link Road, Course Road, Gurugram- Park PM0143 corp.com Private Limited Amritsar, Punjab 122002 M/s. Ansal Buildwell Ltd., Village Jandiala Regd. Off: 118, Upper Contact No. 98113- Guru Ansal Buildwell Ansal City- PBRERA-ASR02- First Floor, 62681 4. Amritsar Residential (Meharbanpura) Ltd Amritsar PR0239 Prakash Deep Building, Email- Tehsil and District 7, Tolstoy Marg, New [email protected] Amritsar Delhi-110001 Contact No. 97184- 07818 606, 6th Floor, Indra Ansal Housing PBRERA-ASR02- Verka and Vallah Email Id: 5. Amritsar Ansal Town Residential Prakash, 21, Barakhamba Limited PR0104 Village, Amritsar. ashok.sharma2@ansals. Road, New Delhi-110001 com Page 1 of 220 List of Registered Real Estate Projects with RERA, Punjab as on 01st October, 2021 S. -

State Profiles of Punjab
State Profile Ground Water Scenario of Punjab Area (Sq.km) 50,362 Rainfall (mm) 780 Total Districts / Blocks 22 Districts Hydrogeology The Punjab State is mainly underlain by Quaternary alluvium of considerable thickness, which abuts against the rocks of Siwalik system towards North-East. The alluvial deposits in general act as a single ground water body except locally as buried channels. Sufficient thickness of saturated permeable granular horizons occurs in the flood plains of rivers which are capable of sustaining heavy duty tubewells. Dynamic Ground Water Resources (2011) Annual Replenishable Ground water Resource 22.53 BCM Net Annual Ground Water Availability 20.32 BCM Annual Ground Water Draft 34.88 BCM Stage of Ground Water Development 172 % Ground Water Development & Management Over Exploited 110 Blocks Critical 4 Blocks Semi- critical 2 Blocks Artificial Recharge to Ground Water (AR) . Area identified for AR: 43340 sq km . Volume of water to be harnessed: 1201 MCM . Volume of water to be harnessed through RTRWH:187 MCM . Feasible AR structures: Recharge shaft – 79839 Check Dams - 85 RTRWH (H) – 300000 RTRWH (G& I) - 75000 Ground Water Quality Problems Contaminants Districts affected (in part) Salinity (EC > 3000µS/cm at 250C) Bhatinda, Ferozepur, Faridkot, Muktsar, Mansa Fluoride (>1.5mg/l) Bathinda, Faridkot, Ferozepur, Mansa, Muktsar and Ropar Arsenic (above 0.05mg/l) Amritsar, Tarantaran, Kapurthala, Ropar, Mansa Iron (>1.0mg/l) Amritsar, Bhatinda, Gurdaspur, Hoshiarpur, Jallandhar, Kapurthala, Ludhiana, Mansa, Nawanshahr, -

Revised Master Plan Derabassi 2031
Revised Draft Master Plan of LPA Derabassi 2031 REPORT REVISED MASTER PLAN DERABASSI 2031 CLIENT DEPARTMENT OF TOWN AND COUNTRY PLANNING, PUNJAB, CONSUTANT N—14, LG FLOOR, MALVIYA NAGAR, NEW DELHI-110017, TEL: +911126673095, +911126682201 Email:[email protected] NFInfratech Service Pvt. Ltd, New Delhi Page i Revised Draft Master Plan of LPA Derabassi 2031 PREFACE In today’s world where urban centres are growing at an astonishing pace, large amount of resources are being spent on the development of various urban settlements but the condition of these towns continues to deteriorate because of piecemeal nature of expenditure and lack of definitive development schemes. In view of this, Department of Town Planning, Punjab has undertaken the preparation of the Revised GIS based Master Plans for Dera-Bassi Town for which the Department has outsourced the work to M/S NF Infra tech Service Private Limited, New Delhi. The studies involved in the preparation of Master Plan for Dera-Bassi (2015-2031) concerns with the areas crucial to planning and development of the sub- region. It has been a great privilege for M/S NF Infra tech Service Private Limited, New Delhi to undertake the assignment of formulating the Revised Master Plan of Dera-Bassi (2015- 31). In this Master Plan, the development proposals have been framed after a detailed study and analysis of the crucial issues related to economic development, infrastructure, transportation, housing, environment and urban sustainability. (Harnek Singh Dhillion) Chief Town Planner Town Planning Organisation, Punjab NFInfratech Service Pvt. Ltd, New Delhi Page ii Revised Draft Master Plan of LPA Derabassi 2031 TEAM COMPOSITION Mr. -

STATE SOCIAL IMPACT ASSESSMENT AUTHORITY Punjabi University, Patiala
STATE SOCIAL IMPACT ASSESSMENT AUTHORITY Punjabi University, Patiala Draft Social Impact Assessment Report & Draft Social Impact Management Plan of Land Acquisition for completion of 100 feet wide road in mega project in area of New Chandigarh at Village Mastgarh S.A.S. Nagar. Submitted to: Department of Housing and Urban Development, Government of Punjab, Chandigarh November 2019 STATE SOCIAL IMPACT ASSESSMENT AUTHORITY, PUNJABI UNIVERSITY PATIALA Contents Topic Page No. Introduction 1-15 Team Composition, Approach, Methodology and Schedule 16-21 of SIA Land Assessment 22-28 Socio-Economic and Cultural Profile of Affected Area 29-31 Social Impacts 32-37 Analysis of Costs and Benefits 38-40 Social Impact Management Plan 41-44 Annexure I 46 Questionnaire 52 STATE SOCIAL IMPACT ASSESSMENT AUTHORITY, PUNJABI UNIVERSITY PATIALA INTRODUCTION I. Context and the Background The present study “Social Impact Assessment study of Land Acquisition for completion of 100 feet wide road in mega project in area of New Chandigarh at Village Mastgarh S.A.S. Nagar. Urbanisation ‘Urban’ area means the area with limited geographical area, inhabited by a largely and closely settled population, having many common interests and institutions, under a local government authorised by the State. Urbanization is a shift from rural to urban areas, the gradual increase in the proportion of people living in urban areas and the ways in which each society adapts to the change. The growth of urban centers is a result of multiple factors such as industrialization, economic causes, education and many more pull & push factors. Table 2.1: Data on Urbanization Increase in Decadal Population Urban Population Growth (2001 to 2011) Punjab S.A.S Nagar S.A.S India Punjab Rural Urban Nagar 32.08 31.16 37.49 55.17 7.58 25.72 Source: Census 2011 1 STATE SOCIAL IMPACT ASSESSMENT AUTHORITY, PUNJABI UNIVERSITY PATIALA Figure 2.1: Density of Population in India Source: Urbanization in India: Population and Urban Classification Grids for 2011 by Deborah Balk, Mark R. -
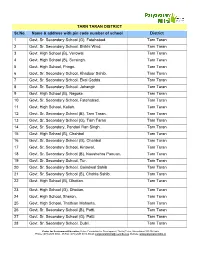
TARN TARAN DISTRICT Sr.No. Name & Address With
TARN TARAN DISTRICT Sr.No. Name & address with pin code number of school District 1 Govt. Sr. Secondary School (G), Fatehabad. Tarn Taran 2 Govt. Sr. Secondary School, Bhikhi Wind. Tarn Taran 3 Govt. High School (B), Verowal. Tarn Taran 4 Govt. High School (B), Sursingh. Tarn Taran 5 Govt. High School, Pringri. Tarn Taran 6 Govt. Sr. Secondary School, Khadoor Sahib. Tarn Taran 7 Govt. Sr. Secondary School, Ekal Gadda. Tarn Taran 8 Govt. Sr. Secondary School, Jahangir Tarn Taran 9 Govt. High School (B), Nagoke. Tarn Taran 10 Govt. Sr. Secondary School, Fatehabad. Tarn Taran 11 Govt. High School, Kallah. Tarn Taran 12 Govt. Sr. Secondary School (B), Tarn Taran. Tarn Taran 13 Govt. Sr. Secondary School (G), Tarn Taran Tarn Taran 14 Govt. Sr. Secondary, Pandori Ran Singh. Tarn Taran 15 Govt. High School (B), Chahbal Tarn Taran 16 Govt. Sr. Secondary School (G), Chahbal Tarn Taran 17 Govt. Sr. Secondary School, Kirtowal. Tarn Taran 18 Govt. Sr. Secondary School (B), Naushehra Panuan. Tarn Taran 19 Govt. Sr. Secondary School, Tur. Tarn Taran 20 Govt. Sr. Secondary School, Goindwal Sahib Tarn Taran 21 Govt. Sr. Secondary School (B), Chohla Sahib. Tarn Taran 22 Govt. High School (B), Dhotian. Tarn Taran 23 Govt. High School (G), Dhotian. Tarn Taran 24 Govt. High School, Sheron. Tarn Taran 25 Govt. High School, Thathian Mahanta. Tarn Taran 26 Govt. Sr. Secondary School (B), Patti. Tarn Taran 27 Govt. Sr. Secondary School (G), Patti. Tarn Taran 28 Govt. Sr. Secondary School, Dubli. Tarn Taran Centre for Environment Education, Nehru Foundation for Development, Thaltej Tekra, Ahmedabad 380 054 India Phone: (079) 2685 8002 - 05 Fax: (079) 2685 8010, Email: [email protected], Website: www.paryavaranmitra.in 29 Govt. -

Information Manual for Rti Act, 2005 District & Sessions Court, Rupnagar
INFORMATION MANUAL FOR RTI ACT, 2005 DISTRICT & SESSIONS COURT, RUPNAGAR PUBLIC INFORMATION OFFICER CONTACT DETAILS Sr. No. PIO's Name / Designation Phone / Fax No. DISTRICT & SESSIONS JUDGE,RUPNAGAR 1 Appellate Authority Ms. Harpreet Kaur Jeewan, District & Sessions 01881-223001 Judge 0164-223102(fax) 2 Public Information Officer Sh. Jarnail Singh, Superintendent / CAO 01881-223001 0164-223102(fax) CIVIL JUDGE SENIOR DIVISION, RUPNAGAR 1 Appellate Authority Sh. Madan Lal, Civil Judge (Senior Division) 01881-223005 2 Public Information Officer Clerk of Court ( COC ) CHIEF JUDICIAL MEGISTRATE,RUPNAGAR 1 Appellate Authority Ms. Pooja Andotra, Chief Judicial Magistrate 01881- 223003 2 Public Information Officer Clerk of Court ( COC ) CONTENTS OF MANUALS: MANUAL- I Particulars of Organization MANUAL-II The Power and Duties of its Officers and Employees MANUAL- III The Procedure Followed In the Decision Making MANUAL-IV The Norms Set By It for the Discharge of Its Functions MANUAL- V The Rules, Regulations, Instructions, Manual and records, held by it 1 | P a ge MANUAL- VI Statement Of The categories of Documents held by it etc. MANUAL- VII The particular of formulation of it policy or implementation MANUAL- VIII A Statement of the Boards, Councils, Committees etc. MANUAL- IX Directory of Its Officers and Employees MANUAL- X Monthly Remuneration Received MANUAL- XI The Budget Allocation MANUAL- XII The manner of execution of subsidy programs etc. MANUALXIII Particulars of concessions, permits or authorizations etc. MANUAL – XIV Details in respect of the information, available to or held by it, reduced in an electronic form MANUAL- XV The particulars of facilities available to citizen etc. -

Census of India 2011
Census of India 2011 PUNJAB SERIES-04 PART XII-B DISTRICT CENSUS HANDBOOK TARN TARAN VILLAGE AND TOWN WISE PRIMARY CENSUS ABSTRACT (PCA) DIRECTORATE OF CENSUS OPERATIONS PUNJAB CENSUS OF INDIA 2011 PUNJAB SERIES-04 PART XII - B DISTRICT CENSUS HANDBOOK TARN TARAN VILLAGE AND TOWN WISE PRIMARY CENSUS ABSTRACT (PCA) Directorate of Census Operations PUNJAB MOTIF GURU ANGAD DEV GURUDWARA Khadur Sahib is the sacred village where the second Guru Angad Dev Ji lived for 13 years, spreading the universal message of Guru Nanak. Here he introduced Gurumukhi Lipi, wrote the first Gurumukhi Primer, established the first Sikh school and prepared the first Gutka of Guru Nanak Sahib’s Bani. It is the place where the first Mal Akhara, for wrestling, was established and where regular campaigns against intoxicants and social evils were started by Guru Angad. The Stately Gurudwara here is known as The Guru Angad Dev Gurudwara. Contents Pages 1 Foreword 1 2 Preface 3 3 Acknowledgement 4 4 History and Scope of the District Census Handbook 5 5 Brief History of the District 7 6 Administrative Setup 8 7 District Highlights - 2011 Census 11 8 Important Statistics 12 9 Section - I Primary Census Abstract (PCA) (i) Brief note on Primary Census Abstract 16 (ii) District Primary Census Abstract 21 Appendix to District Primary Census Abstract Total, Scheduled Castes and (iii) 29 Scheduled Tribes Population - Urban Block wise (iv) Primary Census Abstract for Scheduled Castes (SC) 37 (v) Primary Census Abstract for Scheduled Tribes (ST) 45 (vi) Rural PCA-C.D. blocks wise Village Primary Census Abstract 47 (vii) Urban PCA-Town wise Primary Census Abstract 133 Tables based on Households Amenities and Assets (Rural 10 Section –II /Urban) at District and Sub-District level. -

Government of Punjab Department of Housing and Urban Development (Housing-I, Branch)
Government of Punjab Department of Housing and Urban Development (Housing-I, Branch) NOTIFICATION OF THE SOCIAL IMPACT ASSESSMENT No:06/O2/2021-6HG1/3 .S Dated:)Jo/j Greater Mohali Area Development Authority, (GMADA), an Urban Development Authority constituted by the Government of Punjab has been entrusted to planned development in Sahibzada Ajit Singh Nagar (Mohali). In this connection GMADA has proposed to acquire the land for Setting up of ESDM Industrial Park in Sector 101 as per approved Sahibzada Ajit Singh Nagar Master Plan in the area of Tehsil Mohali, District Sahibzada Ajit Singh Nagar. The proposed land falls in various villages of Tehsil Mohali, District Sahibzada Ajit Singh Nagar. It is hereby notified that the Social Impact Assessment shall be carried out in consultation with the concerned Gram Pachayat in the affected area, The proposed acquisition of aforesaid scheme would entail about (496.4417 acres) of land. These lands shall be acquired from Villages Dhurali, Chau Majra, Saini Majra, Raipur Khurd and Manauli, Tehsil Mohali, District Sahibzada Ajit Singh Nagar. Thus the affected area shall be Villages Dhurali, Chau Majra, Saini Majra, Raipur Khurd and Manauli, Tehsil Mohali, District Sahibzada Ajit Singh Nagar. The main objectives of Social Impact Assessment (SIA) are to:- (1) Assess whether the proposed acquisition serves public purpose. (ii) Estimate number of affected families and number of families among them likely to be displaced (iii) Understand extent of land public and private, houses, settlement and other common properties likely to be affected by the proposed acquisition (iv) Understand extent of land acquired is bare minimum needed for the project (v) Analyse alternate place (if any) (vi) Study of the Social impacts, nature and cost of addressing them and impact of these cost on the overall cost of the project vis-à-vis the benefit of the project. -

Village & Townwise Primary Census Abstract, Ludhiana, Part XIII-A & B
PARTS XIII A &, B SERIES-11 PUNJAB VILLAGE & TOWN DIRECtORY VILLAGE & TOWNWISB PRIMARY CENSUS ABSTRACT DIS1'RICT CENSUS IANDBOOK LUDHIANA DISTRICT D. N. :OlUR t:>F 'tHE INDIAN ADMiNISTRATIVE SBIWlcB blrector 01 census Operations PUNJAB '"0z it ;: 0 2! ~l ! ::I: :;. ~~(~'J-'"\.'-I E ~ .> % R~U P N ~ .. J I , 0 ,. -4 , ~ ~ ~ < . 8 '" f ...... '* ( J-,~ . ",2 r \- ~ ~ ) .. fj D ..s.. '" i ,.."\.... -' .')... " ~ U , ~~ s::: 0 : .> ii: \ ti~· !~ ... \ . .. .. ! !!!. I 0 I, ., .s.. ; , :~ ,<t i i ~5 I ,- z ) Ir:) .... @ %.. .... 0 L,~,~,_,-·" ...... ~. .i 1- I U\ .... ::> .s.. ...J I). W ., z > 0 0 ..'" 0 0 '" II! 0 '"gf .,; Z '"<t ;- ~ ~ ~;> 0 Q. 0 0 Z Q. ~ .. :r Q. 0 '"0 c 0 c 3: "I !:: Q. 0 g 0 0 g 3: ~. C\ c 0 0 ~ ~ i In"' eo"' "' '" zll> w'" 1:1 El i!: ::- > u~ '" ZU :\'" {J 0:~~ _. ~'" _e ••• · ~I ~I __ ~ __________ ~======.. ~ __ = ___~J~ CENSUS OF INDIA, 1981 A-CENTRAL GOVERNMENT PUBLICATIONS Part-I-A Administration Report-Enumeration (for offidal use only) (Printed) Part-I-B Administration Report-Tabulation (for offic~al use only) Part-II-A General Population Tables 1 ~ Combined Volum~ (Printed) Part-II-B Primary Census Abstract J Part-III General Economic Tables Part-IV Social and Cultural Tables Part-V Migration Tables, Part-VI Fertility Tables Part-VII Tables on Houses and Disabled Population (Printed) Part-VJII Household Tables Part-IX Special Tables on Scheduled Castes and Scheduled Tribes Part-X-A Town Directory (Printed) Part-X-B Survey Reports on Selected Towns Part-X-C Survey Reports on Selected Villages Part-XI Ethnographic notes and special studies on Scheduled Castes and Scheduled Tribes Part-XII Census Atlas . -

A Case Study of Rupnagar District, Punjab, India
The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Volume XL-8, 2014 ISPRS Technical Commission VIII Symposium, 09 – 12 December 2014, Hyderabad, India Geospatial modelling for groundwater quality mapping: a case study of Rupnagar district, Punjab, India. S. Sahoo a, *, A. Kaur a, P. Litoria b, B. Pateriya a a Punjab Remote Sensing Centre, Ludhiana, Punjab, India (www.prsc.gov.in) KEY WORDS: Groundwater Quality, Shallow Aquifer, Water Quality Parameters, IDW, Rupnagar, Punjab. ABSTRACT: Over period of time, the water usage and management is under stress for various reasons including pollution in both surface and subsurface. The groundwater quality decreases due to the solid waste from urban and industrial nodes, rapid use of insecticides and pesticides in agricultural practices. In this study, ground water quality maps for Rupnagar district of Punjab has been prepared using geospatial interpolation technique through Inverse Distance Weighted (IDW) approach. IDW technique has been used for major ground water quality parameters observed from the field samples like Arsenic, Hardness, pH, Iron, Fluoride, TDS, and Sulphate. To assess the ground water quality of the Rupnagar district, total 280 numbers of samples from various sources of tubewells for both pre and post monsoon have collected. Out of which, 80 to 113 samples found Iron with non potable limits ranging 0.3-1.1mg/l and 0.3- 1.02mg/l according to BIS standard for both the seasons respectively. Chamkaur Sahib, Rupnagar, Morinda blocks have been found non potable limit of iron in both pre & post-monsoon. 11 to 52 samples in this region have sulphate with permissible limits in both the season ranging 200-400mg/l and 201-400mg/l. -

2 Bedroom Apartment / Flat for Sale in Kharar, Mohali (P65319137
https://www.propertywala.com/P65319137 Home » Mohali Properties » Residential properties for sale in Mohali » Apartments / Flats for sale in Kharar, Mohali » Property P65319137 2 Bedroom Apartment / Flat for sale in Kharar, Mohali 27.9 lakhs Guru Homes Independent Builder Floor In Advertiser Details Kharar Guru Homes, Kharar, Mohali - 140301 (Chandigarh) Area: 990 SqFeet ▾ Bedrooms: Two Bathrooms: Two Floor: Ground Total Floors: Three Facing: East Furnished: Semi Furnished Transaction: New Property Price: 2,790,000 Rate: 2,818 per SqFeet +5% Age Of Construction: 1 Years Scan QR code to get the contact info on your mobile Possession: Immediate/Ready to move View all properties by Alexan Real Estate Description Pictures 2 bhk Independent Builder Floor at Kharar, in prime location, jogging track , indoor games area , landscaped parks, kids play area , gymnasium, convenience stores 24/ 7 security . For more information contact us .Additional details The society has dedicated security guards for every tower. The time you'll spend here will become the greatest moment of your life that will also help you to relieve, relax & evoke a great sense of happiness. Bedroom Dinning Room Please mention that you saw this ad on PropertyWala.com when you contact. Features General Security Power Back-up High Speed Internet Wi-Fi Security Guards Electronic Security Intercom Facility Fire Alarm Bedroom Other Lot Interior Balcony Corner Location Woodwork Modular Kitchen Marble Flooring Granite Flooring Wooden Flooring Fly Proofing Feng Shui / Vaastu Compliant