Formula One Race Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Listing Des Circuits D'autocross Et De Rallycross Et
CIRCUITS ET PARCOURS INTERNATIONAUX INTERNATIONAL CIRCUITS AND COURSES Adresse, localisation, tracé et information concernant les circuits; Listing des circuits d’Autocross et de Rallycross et des parcours de course de côte Tous les dessins de cette section sont strictement le copyright de la FIA et ne peuvent être reproduits sans autorisation écrite préalable. Abréviations L Longueur du circuit S Sens de la course P Pôle W Largeur de référence Prendre note Un circuit ou un parcours est inclus dans cette section sur la base de son activité générale en matière de compétition internationale mais ne signifie pas l’attribution d’un statut particulier ou une quelconque reconnaissance de la part de la FIA. Les détails de la situation géographique des circuits sont fournis sous la forme d’une carte simplifiée (nord en haut, sud en bas). Ces cartes, qui ne sont pas toutes dessinées à la même échelle, n’ont pour but qu’une indication de base, et devraient être lues de concert avec une carte détaillée de la région en question. Circuits: addresses, locations, layouts and information; List of Autocross and Rallycross circuits and Hill-Climb courses All the drawings in this section are strictly the copyright of the FIA and may not be reproduced without prior permission in writing. Abbreviations L Circuit length S Direction of racing P Pole position W Reference width Please note A circuit or course is included in this section on the basis of its general international competition activity, but does not infer any particular status or recognition on the part of the FIA. -

Armiku I Klimës Në Modë Nga Gjergj Nika Qershor 2020
Armiku i klimës në modë Nga Gjergj Nika Qershor 2020 Nuk e di sa është i vërtetë lajmi i mediave online, që Australia do të vrasë 10.000 deve me arsyen se qenkan një rrezik për mjedisin, sepse pijnë shumë ujë. Po e marrim si të vërtetë. Përpara se të vrasin këto kafshë të gjora nën pretekstin për të zgjidhur problemet klimatike, le të ndalojnë ose të pakësojnë garat motorrike si Formula 1, të cilat në një garë të një dite të vetme, emetojnë më shumë gaz karbonik sesa emetojnë devetë gjatë gjithë vitit. Le të analizojmë problemet e shumta për mjedisin dhe klimën që sjellin garat motorrike, duke marrë si shembull Formula 1, që është më ndotësi nga garat motorrike dhe të shohim se sa e dëmton natyrën. Një nga problemet e shumta për mjedisin dhe klimën, që vjen si pasojë e garave të Formula 1 është çlirimi i dioksidit të karbonit nga djegia e karburantit për një garë, e cila nuk sjell asnjë të mirë materiale për njerëzit. Kjo djegie karburanti nuk është e domosdoshme si ajo e traktorit, që punon tokën për ta mbjellur, apo e autobusit, që transporton pasagjerë nevojtarë nga një vend në një tjetër. Sipas Uikipedias një makinë e zakonshme e garës Formula 1 djeg 75 litra karburant për 100 km të përshkuara. Pra 0.75 litra karburant të djegur, lëshojnë rreth 1737 gram dioksid karboni për një kilometër, sasi kjo që është pothuajse nëntë herë më shumë se sasia e dioksidit të karbonit që lëshojnë makinat normale. 1 Dhe gjatë një sezoni garash, ku përdoren afërsisht 100,000 litra karburant, i takon të prodhohet 231 ton dioksid karboni për çdo makinë. -

Video Name Track Track Location Date Year DVD # Classics #4001
Video Name Track Track Location Date Year DVD # Classics #4001 Watkins Glen Watkins Glen, NY D-0001 Victory Circle #4012, WG 1951 Watkins Glen Watkins Glen, NY D-0002 1959 Sports Car Grand Prix Weekend 1959 D-0003 A Gullwing at Twilight 1959 D-0004 At the IMRRC The Legacy of Briggs Cunningham Jr. 1959 D-0005 Legendary Bill Milliken talks about "Butterball" Nov 6,2004 1959 D-0006 50 Years of Formula 1 On-Board 1959 D-0007 WG: The Street Years Watkins Glen Watkins Glen, NY 1948 D-0008 25 Years at Speed: The Watkins Glen Story Watkins Glen Watkins Glen, NY 1972 D-0009 Saratoga Automobile Museum An Evening with Carroll Shelby D-0010 WG 50th Anniversary, Allard Reunion Watkins Glen, NY D-0011 Saturday Afternoon at IMRRC w/ Denise McCluggage Watkins Glen Watkins Glen October 1, 2005 2005 D-0012 Watkins Glen Grand Prix Festival Watkins Glen 2005 D-0013 1952 Watkins Glen Grand Prix Weekend Watkins Glen 1952 D-0014 1951-54 Watkins Glen Grand Prix Weekend Watkins Glen Watkins Glen 1951-54 D-0015 Watkins Glen Grand Prix Weekend 1952 Watkins Glen Watkins Glen 1952 D-0016 Ralph E. Miller Collection Watkins Glen Grand Prix 1949 Watkins Glen 1949 D-0017 Saturday Aternoon at the IMRRC, Lost Race Circuits Watkins Glen Watkins Glen 2006 D-0018 2005 The Legends Speeak Formula One past present & future 2005 D-0019 2005 Concours d'Elegance 2005 D-0020 2005 Watkins Glen Grand Prix Festival, Smalleys Garage 2005 D-0021 2005 US Vintange Grand Prix of Watkins Glen Q&A w/ Vic Elford 2005 D-0022 IMRRC proudly recognizes James Scaptura Watkins Glen 2005 D-0023 Saturday -
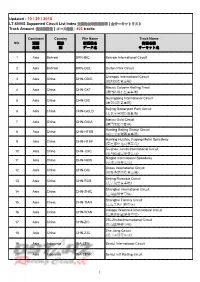
Updated : 10 / 29 / 2018 LT-6000S Supported Circuit List Index 支援的全球賽道清單│全サーキットリスト Track Amount 賽道總數量│コース総数 : 623 Tracks
Updated : 10 / 29 / 2018 LT-6000S Supported Circuit List Index 支援的全球賽道清單│全サーキットリスト Track Amount 賽道總數量│コース総数 : 623 tracks Continent Country File Name Track Name NO. 洲別 國家 賽道檔名 賽道名稱 地域 国 データ名 サーキット名 1 Asia Bahrain BRN-BIC Bahrain International Circuit 2 Asia Bahrain BRN-OUL Oulton Park Circuit Chengdu International Circuit 3 Asia China CHN-CDIC (成都國際賽車場) Macau Coloane Karting Track 4 Asia China CHN-CKT (澳門路環小型賽車場) Guangdong International Circuit 5 Asia China CHN-GIC (廣東國際賽車場) Beijing Goldenport Park Circuit 6 Asia China CHN-GOLD (北京金港國際賽車場) Macau Guia Circuit 7 Asia China CHN-GUIA (澳門東望洋賽道) Hunting Beijing Shunyi Circuit 8 Asia China CHN-HTBS (豪庭北京順義賽車場) Hunting Huizhou Fugang Motor Speedway 9 Asia China CHN-HTHF (豪霆惠州福岗赛车场) Guizhou Junchi International Circuit 10 Asia China CHN-JCIC (贵州骏驰国际赛车场) Ningbo International Speedway 11 Asia China CHN-NBIS (宁波国际赛车场) Ordos International Circuit 12 Asia China CHN-OIC (鄂爾多斯國際賽車場) Beijing Ruisiclub Circuit 13 Asia China CHN-RUS (北京銳思賽車場) Shanghai International Circuit 14 Asia China CHN-SHIC (上海國際賽車場) Shanghai Tianma Circuit 15 Asia China CHN-TIAN (上海天馬山賽車場) Jiangsu Wantrack International Circuit 16 Asia China CHN-WAN (江蘇萬馳國際賽車場) ZIC-Zhuhai International Circuit 17 Asia China CHN-ZIC (珠海國際賽車場) Zhe Jiang Circuit 18 Asia China CHN-ZJC (浙江国际赛车场) 19 Asia Indonesia INA-SEN Sentul International Circuit 20 Asia Indonesia INA-SENK Sentul Int'l Karting circuit 1 Continent Country File Name Track Name NO. 洲別 國家 賽道檔名 賽道名稱 地域 国 データ名 サーキット名 21 Asia India IND-BUD Buddh International Circuit 22 Asia India IND-KMS Kari -

Video 14 – Turkey Preview
Video 14 – Turkey Preview [Cut to Christine. ] Chris: Welcome to Sidepodcast TV , today we are previewing the Turkish Grand Prix. [Intro shots of Turkey. Cut to Christine. ] Chris: It’s not long since Toro Rosso announced their split with driver Scott Speed in favour of German Sebastian Vettel. Now the team have announced their second Sebastian signing, this time in the form of Bourdais, double Champ Car champion. He will replace Tonio Liuzzi for the 2008 season, in a move that Liuzzi describes as unsurprising. Relationships within the team have been strained for a while, so the decision to shake thing s up a bit for 2008 can only be a good thing. I wonder if McLaren will have to do something similar. [Cut to shots of Bourdais. Cut to Christine. ] Chris: Onto Turkey, then, it’s Formula 1’s third outing at the Istanbul Park Circuit, arguably one of the best from designer Herman Tilke. The track features the incredible Turn 8, that just seems to go on and on… but… I don’t want to spoil it for you. Here’s the lap in more detail. [Cut to Allianz animation.] Chris - Voiceover Although it’s still a relatively new track, the Istanbul Park Circuit has already become a firm favourite of both teams and fans alike. It still bears all the hallmarks of the Tilke design but there are some extra special bits thrown in to make it interesting, like the fact that the course runs anti -clockwise. This is the first of only two anti -clockwise tracks this year, which makes it a tough challenge for drivers. -

5 DAYS ISTANBUL PARK FORMULA 1 TOUR Tour
5 DAYS ISTANBUL PARK FORMULA 1 TOUR Tour Start Date : Available on 30.09.2021 TOUR ROUTE : Istanbul TOUR HIGHLIGHTS : Istanbul – Turkish Grand Prix Transfer – Blue Mosque – Haghia Sophia Mosque - Hipodrome – Shopping 5 DAYS ISTANBUL PARK FORMULA 1 TOUR SUMMARY: If you are looking for something special and extraordinary then look no further. Enjoy first class service and guided transportation through the historical and picturesque sites of Istanbul and the excitement and drama of a Grand Prix to combine for the experience of a lifetime. Istanbul is the only city where is dividing to Asia and Europe from each other. Old City, Historical Museums & Palaces, Shoppings and Tasting of Traditional Turkish Culinary so you make your time unforgettable. 5 DAYS ISTANBUL PARK FORMULA 1 TOUR ITINERARY: Day 1 - Istanbul - Arrival Day – 30.09.2021 Meet at the Istanbul International Airport and transfer to your hotel. You will be given your room key and the rest of the day is yours to explore Istanbul. Overnight in Istanbul. Day 2 - Transfer to Formula 1 Track Or Option to Istanbul City Tour – 01.10.2021 (Breakfast included) Pick up from your hotel and Transfer to the race track after breakfast. The schedule of the day includes F1 qualifying rounds. Return to the hotel in the evening. Overnight in Istanbul. If you want you can go to our Daily Istanbul City Tour ; Pick up from your hotel and depart to beginning point of the tour. First stop will be Blue Mosque. The Blue Mosque (Called Sultanahmet Camii in Turkish) is an historical mosque in Istanbul. -

Racing Towards a Sustainable Future a Review of the Sustainability Performance of International Racing Circuits
RACING TOWARDS A SUSTAINABLE FUTURE A REVIEW OF THE SUSTAINABILITY PERFORMANCE OF INTERNATIONAL RACING CIRCUITS Edition June 2021 Racing towards a sustainable future FOREWORD I have been involved with the safety and sustainability of racing tracks for many years now, as a driver, GPDA Chairman and a circuit designer. And while I would argue that big improvements have been made in terms of safety, I also know that there is a long way to go in terms of fully embracing sustainability for racing tracks around the globe. Though circuits have started to change the way in which they approach sustainability, more guidance on what sustainability means and how a circuit can be sustainable are needed. This is why I welcome this new research and the data-driven proposal of the Sustainable Circuits Index™, highlighting indicators from the wider sustainability and sport ecosystem, encouraging best practice and calling attention to the importance of transparent reporting and independent validation. Motorsport has historically been defined by its commitment to innovation and excellence through competition. It’s now critically important for our sport to demonstrate its commitment to sustainability through collaboration. This paper highlights the new metrics for success in this global effort and provides circuits with the tools they need to help win the race for our planet, a race which we can only win together. Alexander Wurz Former F1 Driver, GPDA Chairman, and Consultant on Road Safety and Circuit Design Sustainability is one of the key issues of today’s society as confirmed by the increasing attention of governments, media, academics, and industry. -

News Release 20.09.15 Petter's Best in Barcelona Norwegian Superstar
News release 20.09.15 Petter’s best in Barcelona Norwegian superstar Petter Solberg celebrated victory at the maiden World RX of Barcelona at the Circuit de Barcelona-Catalunya today (Sunday). Petter’s no stranger to winning, but it’s been a pretty lean summer in terms of time on the top step for the two-time FIA World Champion. Which is why he was so pleased to land a first victory since World RX of Great Britain at Lydden Hill in May. That and the fact he didn’t let his son Oliver down… Solberg, who is 35 points clear at the top of the World RX table with three rounds remaining this season, said: “We have fought hard for this win the whole weekend. We’ve run a lot of different set-ups on the car – we had to really work at it to catch Peugeot. All the time, the 208 was taking tenths of seconds, but eventually the brilliant PSRX engineers worked it out. “My son won a crosskart race in Sweden today; I got the message by telephone and he was joking and being quite confident and cocky in telling me I couldn’t let the family down – I actually really felt the pressure from that! “In the end, I could call him back and be quite cocky back with him. I liked that! “Everything was going quite well from the start, but in the third heat, I touched the wall on the left side – there was loads of dust in the car and I really couldn’t see so well. -

Racing Factbook Circuits
Racing Circuits Factbook Rob Semmeling Racing Circuits Factbook Page 2 CONTENTS Introduction 4 First 5 Oldest 15 Newest 16 Ovals & Bankings 22 Fastest 35 Longest 44 Shortest 48 Width 50 Corners 50 Elevation Change 53 Most 55 Location 55 Eight-Shaped Circuits 55 Street Circuits 56 Airfield Circuits 65 Dedicated Circuits 67 Longest Straightaways 72 Racing Circuits Factbook Page 3 Formula 1 Circuits 74 Formula 1 Circuits Fast Facts 77 MotoGP Circuits 78 IndyCar Series Circuits 81 IMSA SportsCar Championship Circuits 82 World Circuits Survey 83 Copyright © Rob Semmeling 2010-2016 / all rights reserved www.wegcircuits.nl Cover Photography © Raphaël Belly Racing Circuits Factbook Page 4 Introduction The Racing Circuits Factbook is a collection of various facts and figures about motor racing circuits worldwide. I believe it is the most comprehensive and accurate you will find anywhere. However, although I have tried to make sure the information presented here is as correct and accurate as possible, some reservation is always necessary. Research is continuously progressing and may lead to new findings. Website In addition to the Racing Circuits Factbook file you are viewing, my website www.wegcircuits.nl offers several further downloadable pdf-files: theRennen! Races! Vitesse! pdf details over 700 racing circuits in the Netherlands, Belgium, Germany and Austria, and also contains notes on Luxembourg and Switzerland. The American Road Courses pdf-documents lists nearly 160 road courses of past and present in the United States and Canada. These files are the most comprehensive and accurate sources for racing circuits in said countries. My website also lists nearly 5000 dates of motorcycle road races in the Netherlands, Belgium, Germany, Austria, Luxembourg and Switzerland, allowing you to see exactly when many of the motorcycle circuits listed in the Rennen! Races! Vitesse! document were used. -

2018 Motogp™ NUMBER of SPECTATORS
2018 MotoGP™ NUMBER OF SPECTATORS DATE GRAND PRIX CIRCUIT DAY 1 DAY 2 DAY 3 TOTAL March 18th (night race) Grand Prix of Qatar* LOSAIL INTERNATIONAL CIRCUIT 7.411 10.241 13.966 31.618 April 8th Gran Premio Motul de la República Argentina TERMAS DE RÍO HONDO 47.735 60.564 * 63.305 * 171.604 April 22nd Red Bull Grand Prix of The Americas CIRCUIT OF THE AMERICAS 36.196 38.471 50.460 125.127 May 6th Gran Premio Red Bull de España CIRCUITO DE JEREZ 21.602 51.291 71.878 144.771 May 20th HJC Helmets Grand Prix de France LE MANS 26.812 74.602 105.203 206.617 June 3rd Gran Premio d’Italia Oakley AUTODROMO DEL MUGELLO 18.061 41.758 90.310 150.129 June 17th Gran Premi Monster Energy de Catalunya CIRCUIT DE BARCELONA- CATALUNYA 18.824 46.040 90.537 155.401 July 1st Motul TT Assen TT CIRCUIT ASSEN 22.150 40.020 105.000 167.170 July 15th Pramac Motorrad Grand Prix Deutschland SACHSENRING 32.657 71.456 89.242 193.355 August 5th Monster Energy Grand Prix České republiky AUTOMOTODROM BRNO 31.345 71.325 84.678 187.348 August 12th eyetime Motorrad Grand Prix von Österreich RED BULL RING - SPIELBERG 39.955 73.836 * 92.955 206.746 August 26th GoPro British Grand Prix SILVERSTONE CIRCUIT 34.431 * 36.400 * 54.603 * 125.434 September 9th Gran Premio Octo di San Marino e della Riviera di Rimini MISANO WORLD CIRCUIT MARCO SIMONCELLI 20.576 41.786 96.758 159.120 September 23rd Gran Premio Movistar de Aragón MOTORLAND ARAGÓN 16.185 34.902 62.970 114.057 October 7th PTT Thailand Grand Prix CHANG INTERNATIONAL CIRCUIT 41.235 81.055 100.245 222.535 October 21st Motul -

Get a Better Understanding to What Factors Caused the on a Race-To-Race Basis, Focusing Solely on the Impact Season-To-Season Changes in Overtaking Frequencies
Journal of Sports Analytics 7 (2021) 119–137 119 DOI 10.3233/JSA-200466 IOS Press Overtaking in Formula 1 during the Pirelli era: A driver-level analysis Jesper de Groote∗ Amersfoortsestraatweg 92 A4, Naarden, North Holland, Netherlands Abstract. The introduction of DRS and rapidly-degrading tires in 2011 boosted on-track overtaking levels in Formula 1 to unprecedented highs. Since then, overtaking has steadily decreased again, culminating in a 60-percent reduction in 2017. In this paper, using a Poisson model on individual-level overtaking data from 2011 to 2018, it was found that about half the decrease can be attributed to the cars, 20 to 30 percent to the reduction in field size and about 20 percent to more uniform race strategies. Keywords: Formula 1, overtaking, quantitative analysis 1. Introduction Bridgestone pulled out of the sport and was replaced by Pirelli. The 2011 season would become the start of Overtaking is an essential ingredient in motor rac- the high-tire-degradation era, as Pirelli was required ing. However, in Formula 1, overtaking has been to artificially increase tire degradation. Along with somewhat difficult since at least the 1980s due the change of tire suppliers, DRS (Drag Reduction to the strong reliance on aerodynamic downforce, System, a driver-adjustable rear wing to increase top which creates wake turbulence (Mafi, 2007; Newbon, speed) was introduced to boost overtaking. Sims-Williams, and Dominy, 2016), in combination The 2011 rule changes proved to be highly suc- with the twisty nature of the tracks, which prevents cessful, as (dry-race) overtaking tripled from 2010 large-scale slipstreaming. -

Benchmarking Formula One Auto Racing Circuits: a Two Stage DEA Approach
Benchmarking Formula One auto racing circuits: A two stage DEA approach Ester Gutiérrez*and Sebastián Lozano Dpto. Organización Industrial y Gestión de Empresas I Escuela Superior de Ingenieros, University of Seville Camino de los Descubrimientos, s/n, 41092 Seville, Spain ARTÍCULO PUBLICADO EN LA REVISTA Operational Research (2019) doi: https://doi.org/10.1007/s12351-018-0416-z Abstract Formula One (F1) World Championship has become one of the most successful sport tournaments over the last decade. Races take place in modern-day closed racing circuits, whose design plays a key role in racing results. This paper proposes a framework for the design efficiency assessment of the more representative racing circuits that hosted Grands Prix during the recent F1 seasons. The proposed approach considers two basic circuit features (namely, circuit length and number of turns) and combines car performance and race safety data. The methodology used is based on Data Envelopment Analysis (DEA). The number of inefficient circuits is small, five in the case of variable returns to scale and nine (out of 21) when constant returns to scale are assumed. Potential improvements in terms of speed, fuel consumption and safety targets are computed. For each inefficient circuit its reference set is identified. Also, a second-stage DEA fractional regression analysis is carried out to study the influence of the circuit type (race or street circuit), the track orientation (clockwise or anticlockwise) and the number of red- flagged races due to rainfall on the circuits’ efficiency. The results indicate that all three variables are significant. The implications of the results for track designers and F1 organizers are also discussed.