Tools for Creating Audio Stories
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ABC's of Ios: a Voiceover Manual for Toddlers and Beyond!
. ABC’s of iOS: A VoiceOver Manual for Toddlers and Beyond! A collaboration between Diane Brauner Educational Assistive Technology Consultant COMS and CNIB Foundation. Copyright © 2018 CNIB. All rights reserved, including the right to reproduce this manual or portions thereof in any form whatsoever without permission. For information, contact [email protected]. Diane Brauner Diane is an educational accessibility consultant collaborating with various educational groups and app developers. She splits her time between managing the Perkins eLearning website, Paths to Technology, presenting workshops on a national level and working on accessibility-related projects. Diane’s personal mission is to support developers and educators in creating and teaching accessible educational tools which enable students with visual impairments to flourish in the 21st century classroom. Diane has 25+ years as a Certified Orientation and Mobility Specialist (COMS), working primarily with preschool and school-age students. She also holds a Bachelor of Science in Rehabilitation and Elementary Education with certificates in Deaf and Severely Hard of Hearing and Visual Impairments. CNIB Celebrating 100 years in 2018, the CNIB Foundation is a non-profit organization driven to change what it is to be blind today. We work with the sight loss community in a number of ways, providing programs and powerful advocacy that empower people impacted by blindness to live their dreams and tear down barriers to inclusion. Through community consultations and in our day to -

Turning Voiceover on with Siri 1
Texas School for the Blind and Visually Impaired Outreach Programs www.tsbvi.edu | 512.454.8631 | 1100 W. 45th St. | Austin, TX 78756 Coffee Hour - August 27, 2020 VoiceOver Basics on iOS Presented by Carrie Farraje Introduction: Question: What is VoiceOver? Answer: VoiceOver is a screen reader software that is built into iOS devices such as iPads or iPhones that gives audio description of the screen that people with vision navigate with their eyes. Note: There are multiple ways and gestures to access an iOS device with VoiceOver Important Terms • iOS device: iPad, iPhone, Apple Watch • home button: newer devices do not have a Home button • settings: location of iOS setup and customization • orientation: landscape or portrait • app: application • app icons: small picture that represents an app • page: apps are in rows and columns on a page • gestures: touches that create actions • focus: what has the attention of VoiceOver • page adjuster: to navigate to different pages • dock: area on bottom of screen customized with commonly used apps • status bar: where features such as time, date, battery are located • control center: direct access to customizable settings 1 Turning VoiceOver on in Settings 1. Go to the Settings icon 2. Go to General 3. Go to Accessibility 4. Go to VoiceOver and, tap it on 5. Press Home button to go back to the home screen Turning VoiceOver on with Accessibility Shortcut 1. Go to the Settings icon 2. Go to Accessibility 3. Go to Accessibility Shortcut (at the bottom of the screen) 4. Tap VoiceOver on 5. Turn VoiceOver on by pressing the Home button or the top side button(on newer devices) three times. -

Masterarbeit
Masterarbeit Erstellung einer Sprachdatenbank sowie eines Programms zu deren Analyse im Kontext einer Sprachsynthese mit spektralen Modellen zur Erlangung des akademischen Grades Master of Science vorgelegt dem Fachbereich Mathematik, Naturwissenschaften und Informatik der Technischen Hochschule Mittelhessen Tobias Platen im August 2014 Referent: Prof. Dr. Erdmuthe Meyer zu Bexten Korreferent: Prof. Dr. Keywan Sohrabi Eidesstattliche Erklärung Hiermit versichere ich, die vorliegende Arbeit selbstständig und unter ausschließlicher Verwendung der angegebenen Literatur und Hilfsmittel erstellt zu haben. Die Arbeit wurde bisher in gleicher oder ähnlicher Form keiner anderen Prüfungsbehörde vorgelegt und auch nicht veröffentlicht. 2 Inhaltsverzeichnis 1 Einführung7 1.1 Motivation...................................7 1.2 Ziele......................................8 1.3 Historische Sprachsynthesen.........................9 1.3.1 Die Sprechmaschine.......................... 10 1.3.2 Der Vocoder und der Voder..................... 10 1.3.3 Linear Predictive Coding....................... 10 1.4 Moderne Algorithmen zur Sprachsynthese................. 11 1.4.1 Formantsynthese........................... 11 1.4.2 Konkatenative Synthese....................... 12 2 Spektrale Modelle zur Sprachsynthese 13 2.1 Faltung, Fouriertransformation und Vocoder................ 13 2.2 Phase Vocoder................................ 14 2.3 Spectral Model Synthesis........................... 19 2.3.1 Harmonic Trajectories........................ 19 2.3.2 Shape Invariance.......................... -

MACBOOK Keyboard Shortcuts
MACBOOK Keyboard Shortcuts Learn about common OS X keyboard shortcuts. A keyboard shortcut is a way to invoke a function in OS X by pressing a combination of keys on your keyboard. To use a keyboard shortcut, or key combination, you press a modifier key with a character key. For example, pressing the Command key (the key that has a symbol) and the "c" key at the same time copies whatever is currently selected (text, graphics, and so forth) into the Clipboard. This is also known as the Command-C key combination (or keyboard shortcut). A modifier key is a part of many key combinations. A modifier key alters the way other keystrokes or mouse/trackpad clicks are interpreted by OS X. Modifier keys include: Command, Shift, Option, Control, Caps Lock, and the Fn key. If your keyboard has an Fn key, you may need to use it in some of the key combinations listed below. For example, if the keyboard shortcut is Control-F2, press Fn-Control-F2. Here are the modifier key symbols you may see in OS X menus: ⌘ Command key ⌃ Control key ⌥ Option key ⇧ Shift Key ⇪ Caps Lock Fn Function Key Startup shortcuts Press the key or key combination until the expected function occurs/appears (for example, hold Option during startup until Startup Manager appears, or Shift until "Safe Boot" appears). Tip: If a startup function doesn't work and you use a third-party keyboard, try again with an Apple keyboard. Key or key combination What it does Display all bootable volumes (Startup Option Manager) Shift Perform a Safe Boot (start up in Safe Mode) Left Shift Prevent -

Mac OS X Server V10.5 Vpat
The following Voluntary Product Accessibility information refers to the Mac OS X Server version 10.5 “Leopard Server” (Mac OS X Server) operating system. For more information on accessibility features in Mac OS X Server and to find out about available applications and peripheral devices visit Apple’s accessibility web site at http://www.apple.com/accessibility Summary Table Voluntary Product Accessibility Template Criteria Supporting Features Remarks and explanations Section 1194.21 Software Please refer to the attached VPAT Applications and Operating Systems Section 1194.22 Web-based Not Applicable internet information and applications Section 1194.23 Not Applicable Telecommunications Products Section 1194.24 Video and Not Applicable Multi-media Products Section 1194.25 Self- Not Applicable Contained, Closed Products Section 1194.26 Desktop Not Applicable and Portable Computers Section 1194.31 Functional Please refer to the attached VPAT Performance Criteria Section 1194.41 Information, Please refer to the attached VPAT Documentation, and Support Section 1194.21 Software Applications and Operating Systems - Detail Voluntary Product Accessibility Template Criteria Supporting Features Remarks and explanations (a) When software is Supported with exceptions: Exceptions: designed to run on a Mac OS X Server provides keyboard access to operating system system that has a interface elements using a feature called “full keyboard access” These applications and keyboard, product which controls the keyboard cursor and VoiceOver (an integrated features included with Mac functions shall be screen reader) that provides an additional cursor. One can Full OS X Server may only be executable from a keyboard access to navigate the system including menus, partially keyboard keyboard where the windows, palettes, controls, text boxes, lists, window drawers, and accessible. -

OS X Mountain Lion Includes Ebook & Learn Os X Mountain Lion— Video Access the Quick and Easy Way!
Final spine = 1.2656” VISUAL QUICKSTA RT GUIDEIn full color VISUAL QUICKSTART GUIDE VISUAL QUICKSTART GUIDE OS X Mountain Lion X Mountain OS INCLUDES eBOOK & Learn OS X Mountain Lion— VIDEO ACCESS the quick and easy way! • Three ways to learn! Now you can curl up with the book, learn on the mobile device of your choice, or watch an expert guide you through the core features of Mountain Lion. This book includes an eBook version and the OS X Mountain Lion: Video QuickStart for the same price! OS X Mountain Lion • Concise steps and explanations let you get up and running in no time. • Essential reference guide keeps you coming back again and again. • Whether you’re new to OS X or you’ve been using it for years, this book has something for you—from Mountain Lion’s great new productivity tools such as Reminders and Notes and Notification Center to full iCloud integration—and much, much more! VISUAL • Visit the companion website at www.mariasguides.com for additional resources. QUICK Maria Langer is a freelance writer who has been writing about Mac OS since 1990. She is the author of more than 75 books and hundreds of articles about using computers. When Maria is not writing, she’s offering S T tours, day trips, and multiday excursions by helicopter for Flying M Air, A LLC. Her blog, An Eclectic Mind, can be found at www.marialanger.com. RT GUIDE Peachpit Press COVERS: OS X 10.8 US $29.99 CAN $30.99 UK £21.99 www.peachpit.com CATEGORY: Operating Systems / OS X ISBN-13: 978-0-321-85788-0 ISBN-10: 0-321-85788-7 BOOK LEVEL: Beginning / Intermediate LAN MARIA LANGER 52999 AUTHOR PHOTO: Jeff Kida G COVER IMAGE: © Geoffrey Kuchera / shutterstock.com ER 9 780321 857880 THREE WAYS To learn—prINT, eBOOK & VIDEO! VISUAL QUICKSTART GUIDE OS X Mountain Lion MARIA LANGER Peachpit Press Visual QuickStart Guide OS X Mountain Lion Maria Langer Peachpit Press www.peachpit.com To report errors, please send a note to [email protected]. -

Configurations, Troubleshooting, and Advanced Secure Browser Installation Guide for Macos and Ipados
Configurations, Troubleshooting, and Advanced Secure Browser Installation Guide for macOS and iPadOS 2021–2022 Updated 9/2/2021 1 Table of Contents Configurations, Troubleshooting, and Secure Browser Installation for macOS and iPadOS ............. 3 How to Configure macOS Workstations for Online Testing .......................................................................... 3 Installing the Secure Profile for macOS ......................................................................................................... 4 Installing Secure Browser for macOS ............................................................................................................ 5 Installing the SecureTestBrowser App for iPadOS ........................................................................................ 5 Additional Instructions for Installing the Secure Browser for macOS ............................................................ 6 Cloning the Secure Browser Installation to Other macOS Machines ................................................... 6 Uninstalling the Secure Browser on macOS ......................................................................................... 6 Additional Configurations for macOS ............................................................................................................ 6 Disabling Updates to Third-Party Apps ................................................................................................. 7 Disabling Fast User Switching ............................................................................................................. -

Apple Accessibility Conformance Report
Apple Accessibility Conformance Report Based on Voluntary Product Accessibility Template® (VPAT®) Name of Product: iOS 14 and iPadOS 14 Product Description: The operating system for iPhone, iPad and iPod touch. Date: October 12, 2020 Contact information: [email protected] Terms The terms used in the Conformance Level information are defined as follows: • Supports: The functionality of the product has at least one method that meets the criteria without known defects or meets with equivalent facilitation. • Supports with Exceptions: Some functionality of the product does not meet the criteria. • Does Not Support: Majority of functionality of the product does not meet the criteria. • Not Applicable: The criteria are not relevant to the product. • Not Evaluated: The product has not been evaluated against the criteria. This can be used only with WCAG 2.0 Level AAA. WCAG 2.0 Report - Table 1: Conformance Criteria, Level A - Criteria Conformance Level Remarks and Explanations 1.1.1 Non-text Content: All non-text content that is Supports with exceptions VoiceOver, the screen reader built into iOS, provides presented to the user has a text alternative that audio descriptions for non-text content and images serves the equivalent purpose, except in situations presented to the user. However, some user-generated listed in WCAG 2.0 1.1.1. content images may or may not have text alternatives provided. 1.2.1 Audio-only and Video-only (Prerecorded): For Supports with exceptions iOS supports the pass-through of closed-captioned prerecorded audio-only and prerecorded video-only video and video descriptions in industry-standard media, the following are true, except when the audio formats. -

A Unit Selection Text-To-Speech-And-Singing Synthesis Framework from Neutral Speech: Proof of Concept 39 II.1 Introduction
Adding expressiveness to unit selection speech synthesis and to numerical voice production 90) - 02 - Marc Freixes Guerreiro http://hdl.handle.net/10803/672066 Generalitat 472 (28 de Catalunya núm. Rgtre. Fund. ADVERTIMENT. L'accés als continguts d'aquesta tesi doctoral i la seva utilització ha de respectar els drets de ió la persona autora. Pot ser utilitzada per a consulta o estudi personal, així com en activitats o materials d'investigació i docència en els termes establerts a l'art. 32 del Text Refós de la Llei de Propietat Intel·lectual undac F (RDL 1/1996). Per altres utilitzacions es requereix l'autorització prèvia i expressa de la persona autora. En qualsevol cas, en la utilització dels seus continguts caldrà indicar de forma clara el nom i cognoms de la persona autora i el títol de la tesi doctoral. No s'autoritza la seva reproducció o altres formes d'explotació efectuades amb finalitats de lucre ni la seva comunicació pública des d'un lloc aliè al servei TDX. Tampoc s'autoritza la presentació del seu contingut en una finestra o marc aliè a TDX (framing). Aquesta reserva de drets afecta tant als continguts de la tesi com als seus resums i índexs. Universitat Ramon Llull Universitat Ramon ADVERTENCIA. El acceso a los contenidos de esta tesis doctoral y su utilización debe respetar los derechos de la persona autora. Puede ser utilizada para consulta o estudio personal, así como en actividades o materiales de investigación y docencia en los términos establecidos en el art. 32 del Texto Refundido de la Ley de Propiedad Intelectual (RDL 1/1996). -
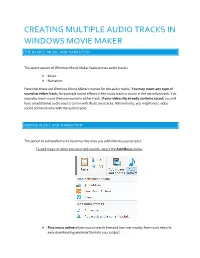
Creating Multiple Audio Tracks in Windows Movie Maker
CREATING MULTIPLE AUDIO TRACKS IN WINDOWS MOVIE MAKER THE BASICS: MUSIC AND NARRATION The latest version of Windows Movie Maker features two audio tracks: Music Narration Note that these are Windows Movie Maker’s names for the audio tracks. You may insert any type of sound on either track, for example sound effects in the music track or music in the narration track. You may also insert more than one sound in either track. If your video clip already contains sound, you will have an additional audio source to mix with these two tracks. Alternatively, you might mute video sound and work only with the audio tracks. ADDING MUSIC AND NARRATION The option to add audio tracks becomes live once you add video to your project. To add music or other pre-recorded sounds, select the Add Music menu: Find music online allows you to search free and low-cost royalty-free music sites for easy downloading and insertion into your project. Add music from PC allows you to Add music to the entire project or Add music at the current point in your video. The first time you add a music file, choose Add music. When you add additional sounds to the music track, choose Add music at the current point. To add narration or a pre-recorded sound, select the Record Narration drop-down menu: Record narration allows you to record voiceover. Windows Movie Maker saves your recording as an audio file you can then insert into your project. Add sound allows you to insert sound files from your hard drive. -

VPAT™ for Apple Itunes 12 for OS X
VPAT™ for Apple iTunes 12 for OS X The following Voluntary Product Accessibility information refers to the Apple iTunes 12 for OS X. For more information on the accessibility features of this product and to learn more about this product’s features, visit www.apple.com/itunes and www.apple.com/accessibility VPAT™ Voluntary Product Accessibility Template Summary Table Criteria Supporting Features Remarks and Explanations Section 1194.21 Software Applications and Please refer to the attached VPAT Please refer to the attached VPAT Operating Systems Section 1194.22 Web-based Internet Information Please refer to the attached VPAT Please refer to the attached VPAT and Applications Section 1194.23 Telecommunications Products Not Applicable Not Applicable Section 1194.24 Video and Multi-media Products Not Applicable Not Applicable Section 1194.25 Self-Contained, Closed Products Not Applicable Not Applicable Section 1194.26 Desktop and Portable Computers Not Applicable Not Applicable Section 1194.31 Functional Performance Criteria Please refer to the attached VPAT Please refer to the attached VPAT Section 1194.41 Information, Documentation and Please refer to the attached VPAT Please refer to the attached VPAT Support VPAT™ for Apple iTunes 12 for OS X Page !1 of !7 Section 1194.21 Software Applications and Operating Systems – Detail Criteria Supporting Features Remarks and Explanations (a) When software is designed to run on a system Supported iTunes is accessible to keyboard-only users. that has a keyboard, product functions shall be executable from a keyboard where the function iTunes features are accessible to the blind and itself or the result of performing a function can be visually impaired using VoiceOver, including discerned textually. -

Deque Quick Reference Guide: Voiceover for Macos Keyboard
Quick Reference Guide: VoiceOver for macOS Keyboard Commands Recommended browser: Safari Getting Started Reading Text Command + F5 starts the VoiceOver program. VoiceOver uses the Task Command Control and Option keys before each command. The combination is Start reading VO + A referred to as VO in the tables. The VO keys can be locked so that Stop reading Control they do not need to be pressed to perform VoiceOver commands by Read next item VO + Right Arrow pressing VO + ;. Read previous item VO + Left Arrow Read paragraph VO + P Keyboard accessibility is NOT enabled by default on a Mac. Your Read sentence VO + S accessibility and screen reader test results will be inaccurate if you Read word (press W multiple times to spell VO + W do not enable keyboard accessibility in the following two places: words alphabetically and phonetically) Read from top to current location VO + B 1. System Settings: Keyboard > Shortcuts > Full Keyboard Jump to top of page (using desktop keyboards) VO + Home Access > All controls Jump to top of page (using laptop keyboards) VO + Fn + Left Arrow 2. Safari Settings: Advanced > Accessibility > Press Tab to Jump to bottom of page (using desktop VO + End highlight each item on a webpage. keyboards) Jump to bottom of page (using laptop VO + Fn + Right Arrow The Basics keyboards) Select speech setting option (speaking rate, VO + Command + Right Task Command voice, pitch, etc.) Arrow or Left Arrow Start (or stop) VoiceOver Command + F5 Modify the selected speech setting VO + Command + Up VoiceOver activation keys (or