View Preprint
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lanosterol 14Α-Demethylase (CYP51)
463 Lanosterol 14-demethylase (CYP51), NADPH–cytochrome P450 reductase and squalene synthase in spermatogenesis: late spermatids of the rat express proteins needed to synthesize follicular fluid meiosis activating sterol G Majdicˇ, M Parvinen1, A Bellamine2, H J Harwood Jr3, WWKu3, M R Waterman2 and D Rozman4 Veterinary Faculty, Clinic of Reproduction, Cesta v Mestni log 47a, 1000 Ljubljana, Slovenia 1Institute of Biomedicine, Department of Anatomy, University of Turku, Kiinamyllynkatu 10, FIN-20520 Turku, Finland 2Department of Biochemistry, Vanderbilt University School of Medicine, Nashville, Tennessee 37232–0146, USA 3Pfizer Central Research, Department of Metabolic Diseases, Box No. 0438, Eastern Point Road, Groton, Connecticut 06340, USA 4Institute of Biochemistry, Medical Center for Molecular Biology, Medical Faculty University of Ljubljana, Vrazov trg 2, SI-1000 Ljubljana, Slovenia (Requests for offprints should be addressed to D Rozman; Email: [email protected]) (G Majdicˇ is now at Department of Internal Medicine, UT Southwestern Medical Center, Dallas, Texas 75235–8857, USA) Abstract Lanosterol 14-demethylase (CYP51) is a cytochrome detected in step 3–19 spermatids, with large amounts in P450 enzyme involved primarily in cholesterol biosynthe- the cytoplasm/residual bodies of step 19 spermatids, where sis. CYP51 in the presence of NADPH–cytochrome P450 P450 reductase was also observed. Squalene synthase was reductase converts lanosterol to follicular fluid meiosis immunodetected in step 2–15 spermatids of the rat, activating sterol (FF-MAS), an intermediate of cholesterol indicating that squalene synthase and CYP51 proteins are biosynthesis which accumulates in gonads and has an not equally expressed in same stages of spermatogenesis. additional function as oocyte meiosis-activating substance. -

Mrna Vaccine: a Potential Therapeutic Strategy Yang Wang† , Ziqi Zhang† , Jingwen Luo† , Xuejiao Han† , Yuquan Wei and Xiawei Wei*
Wang et al. Molecular Cancer (2021) 20:33 https://doi.org/10.1186/s12943-021-01311-z REVIEW Open Access mRNA vaccine: a potential therapeutic strategy Yang Wang† , Ziqi Zhang† , Jingwen Luo† , Xuejiao Han† , Yuquan Wei and Xiawei Wei* Abstract mRNA vaccines have tremendous potential to fight against cancer and viral diseases due to superiorities in safety, efficacy and industrial production. In recent decades, we have witnessed the development of different kinds of mRNAs by sequence optimization to overcome the disadvantage of excessive mRNA immunogenicity, instability and inefficiency. Based on the immunological study, mRNA vaccines are coupled with immunologic adjuvant and various delivery strategies. Except for sequence optimization, the assistance of mRNA-delivering strategies is another method to stabilize mRNAs and improve their efficacy. The understanding of increasing the antigen reactiveness gains insight into mRNA-induced innate immunity and adaptive immunity without antibody-dependent enhancement activity. Therefore, to address the problem, scientists further exploited carrier-based mRNA vaccines (lipid-based delivery, polymer-based delivery, peptide-based delivery, virus-like replicon particle and cationic nanoemulsion), naked mRNA vaccines and dendritic cells-based mRNA vaccines. The article will discuss the molecular biology of mRNA vaccines and underlying anti-virus and anti-tumor mechanisms, with an introduction of their immunological phenomena, delivery strategies, their importance on Corona Virus Disease 2019 (COVID-19) and related clinical trials against cancer and viral diseases. Finally, we will discuss the challenge of mRNA vaccines against bacterial and parasitic diseases. Keywords: mRNA vaccine, Self-amplifying RNA, Non-replicating mRNA, Modification, Immunogenicity, Delivery strategy, COVID-19 mRNA vaccine, Clinical trials, Antibody-dependent enhancement, Dendritic cell targeting Introduction scientists are seeking to develop effective cancer vac- A vaccine stimulates the immune response of the body’s cines. -

Characterization of Methylene Diphenyl Diisocyanate Protein Conjugates
Portland State University PDXScholar Dissertations and Theses Dissertations and Theses Spring 6-5-2014 Characterization of Methylene Diphenyl Diisocyanate Protein Conjugates Morgen Mhike Portland State University Follow this and additional works at: https://pdxscholar.library.pdx.edu/open_access_etds Part of the Allergy and Immunology Commons, and the Chemistry Commons Let us know how access to this document benefits ou.y Recommended Citation Mhike, Morgen, "Characterization of Methylene Diphenyl Diisocyanate Protein Conjugates" (2014). Dissertations and Theses. Paper 1844. https://doi.org/10.15760/etd.1843 This Dissertation is brought to you for free and open access. It has been accepted for inclusion in Dissertations and Theses by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. Characterization of Methylene Diphenyl Diisocyanate Protein Conjugates by Morgen Mhike A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Chemistry Dissertation Committee: Reuben H. Simoyi, Chair Paul D. Siegel Itai Chipinda Niles Lehman Shankar B. Rananavare Robert Strongin E. Kofi Agorsah Portland State University 2014 © 2014 Morgen Mhike ABSTRACT Diisocyanates (dNCO) such as methylene diphenyl diisocyanate (MDI) are used primarily as cross-linking agents in the production of polyurethane products such as paints, elastomers, coatings and adhesives, and are the most frequently reported cause of chemically induced immunologic sensitization and occupational asthma (OA). Immune mediated hypersensitivity reactions to dNCOs include allergic rhinitis, asthma, hypersensitivity pneumonitis and allergic contact dermatitis. There is currently no simple diagnosis for the identification of dNCO asthma due to the variability of symptoms and uncertainty regarding the underlying mechanisms. -

Cytochrome Oxidase (A3) Heme and Copper Observed by Low- Temperature Fourier Transform Infrared Spectroscopy Ofthe CO Complex (Photolysis/Mitoehondria/Beef Heart) J
Proc. Natl Acad. Sci. USA Vol. 78, No. 1, pp. 234-237, January 1981 Biochemistry Cytochrome oxidase (a3) heme and copper observed by low- temperature Fourier transform infrared spectroscopy ofthe CO complex (photolysis/mitoehondria/beef heart) J. 0. ALBEN, P. P. MOH, F. G. FIAMINGO, AND R. A. ALTSCHULD Department ofPhysiological Chemistry, The Ohio State University, Columbus, Ohio 43210 Communicated by Hans Frauenfelder, October 10, 1980 ABSTRACT Carbon monoxide bound to iron or copper in sub- chondria is bound reversibly to the a3 copper would appear to strate-reduced mitochondrial cytochrome c oxidase (ferrocyto- explain these results. Here, we extend the observations to lower chrome c:oxygen oxidoreductase, EC 1.9.3.1) from beefheart has beenused toexplore the structural interaction ofthea3 heme-copper temperatures, illustrate the structural differences between pocket at.15 K and 80 K in the dark and in the presence ofvisible heme and copper CO complexes in cytochrome a3, and show light. The vibrational absorptions of CO measured by a Fourier how this may be related to the functional contributions ofthese transform infrared interferometer occur in the dark at 1963 cm-' metal centers. with small absorptions near 1952 cm-', and aredue toa3 heme-CO complexes. These disappear in strong visible light and are re- placed by a major absorption at 2062 cm' and a minor one at 2043 MATERIALS AND METHODS cm' due to CU-CO. Relaxation in the dark is rapid and quantita- tive at 210 K, but becomes negligible below 140 K. The multiple Mitochondria, prepared from fresh beef heart by use of Nagarse absorptions indicate structural heterogeneity of.cytochrome oxi- (8), were kindly donated by G. -

Table S1. Identified Proteins with Exclusive Expression in Cerebellum of Rats of Control, 10Mg F/L and 50Mg F/L Groups
Table S1. Identified proteins with exclusive expression in cerebellum of rats of control, 10mg F/L and 50mg F/L groups. Accession PLGS Protein Name Group IDa Score Q3TXS7 26S proteasome non-ATPase regulatory subunit 1 435 Control Q9CQX8 28S ribosomal protein S36_ mitochondrial 197 Control P52760 2-iminobutanoate/2-iminopropanoate deaminase 315 Control Q60597 2-oxoglutarate dehydrogenase_ mitochondrial 67 Control P24815 3 beta-hydroxysteroid dehydrogenase/Delta 5-->4-isomerase type 1 84 Control Q99L13 3-hydroxyisobutyrate dehydrogenase_ mitochondrial 114 Control P61922 4-aminobutyrate aminotransferase_ mitochondrial 470 Control P10852 4F2 cell-surface antigen heavy chain 220 Control Q8K010 5-oxoprolinase 197 Control P47955 60S acidic ribosomal protein P1 190 Control P70266 6-phosphofructo-2-kinase/fructose-2_6-bisphosphatase 1 113 Control Q8QZT1 Acetyl-CoA acetyltransferase_ mitochondrial 402 Control Q9R0Y5 Adenylate kinase isoenzyme 1 623 Control Q80TS3 Adhesion G protein-coupled receptor L3 59 Control B7ZCC9 Adhesion G-protein coupled receptor G4 139 Control Q6P5E6 ADP-ribosylation factor-binding protein GGA2 45 Control E9Q394 A-kinase anchor protein 13 60 Control Q80Y20 Alkylated DNA repair protein alkB homolog 8 111 Control P07758 Alpha-1-antitrypsin 1-1 78 Control P22599 Alpha-1-antitrypsin 1-2 78 Control Q00896 Alpha-1-antitrypsin 1-3 78 Control Q00897 Alpha-1-antitrypsin 1-4 78 Control P57780 Alpha-actinin-4 58 Control Q9QYC0 Alpha-adducin 270 Control Q9DB05 Alpha-soluble NSF attachment protein 156 Control Q6PAM1 Alpha-taxilin 161 -

17F8-Estradiol Hydroxylation Catalyzed by Human Cytochrome P450 Lbl (Catechol Estrogen/Indole Carbinol/Dioxin/Breast Cancer/Uterine Cancer) CARRIE L
Proc. Natl. Acad. Sci. USA Vol. 93, pp. 9776-9781, September 1996 Medical Sciences 17f8-Estradiol hydroxylation catalyzed by human cytochrome P450 lBl (catechol estrogen/indole carbinol/dioxin/breast cancer/uterine cancer) CARRIE L. HAYES*, DAVID C. SPINKt, BARBARA C. SPINKt, JOAN Q. CAOt, NIGEL J. WALKER*, AND THOMAS R. SUTTER*t *Department of Environmental Health Sciences, Johns Hopkins University, School of Hygiene and Public Health, Baltimore, MD 21205-2179; and tWadsworth Center, New York State Department of Health, Albany, NY 12201-0509 Communicated by Paul Talalay, Johns Hopkins University, Baltimore, MD, June 11, 1996 (received for review April 24, 1996) ABSTRACT The 4-hydroxy metabolite of 178-estradiol of 4-hydroxyestradiol (4-OHE2), and lack of activity of 2-hy- (E2) has been implicated in the carcinogenicity of this hor- droxyestradiol (2-OHE2), (17-19), implicate the 4-hydroxy- mone. Previous studies showed that aryl hydrocarbon- lated metabolites in estrogen-induced carcinogenesis. Perti- receptor agonists induced a cytochrome P450 that catalyzed nent to elucidating the contribution of 4-OHE2 to the devel- the 4-hydroxylation of E2. This activity was associated with opment of human cancer is the identification of the enzyme(s) human P450 lBi. To determine the relationship of the human that produce this metabolite. P450 lBl gene product and E2 4-hydroxylation, the protein Previous studies demonstrated that treatment of MCF-7 was expressed in Saccharomyces cerevisiae. Microsomes from breast cancer cells with 2,3,7,8-tetrachlorodibenzo-p-dioxin the transformed yeast catalyzed the 4- and 2-hydroxylation of (TCDD), an environmental pollutant and potent agonist of the E2 with Km values of 0.71 and 0.78 ,uM and turnover numbers aryl hydrocarbon (Ah)-receptor, resulted in greater than 10- of 1.39 and 0.27 nmol product min'l nmol P450-1, respec- fold increases in the rates of E2 4- and 2-hydroxylation (20). -

Current Trends in Cancer Immunotherapy
biomedicines Review Current Trends in Cancer Immunotherapy Ivan Y. Filin 1 , Valeriya V. Solovyeva 1 , Kristina V. Kitaeva 1, Catrin S. Rutland 2 and Albert A. Rizvanov 1,3,* 1 Institute of Fundamental Medicine and Biology, Kazan Federal University, 420008 Kazan, Russia; [email protected] (I.Y.F.); [email protected] (V.V.S.); [email protected] (K.V.K.) 2 Faculty of Medicine and Health Science, University of Nottingham, Nottingham NG7 2QL, UK; [email protected] 3 Republic Clinical Hospital, 420064 Kazan, Russia * Correspondence: [email protected]; Tel.: +7-905-316-7599 Received: 9 November 2020; Accepted: 16 December 2020; Published: 17 December 2020 Abstract: The search for an effective drug to treat oncological diseases, which have become the main scourge of mankind, has generated a lot of methods for studying this affliction. It has also become a serious challenge for scientists and clinicians who have needed to invent new ways of overcoming the problems encountered during treatments, and have also made important discoveries pertaining to fundamental issues relating to the emergence and development of malignant neoplasms. Understanding the basics of the human immune system interactions with tumor cells has enabled new cancer immunotherapy strategies. The initial successes observed in immunotherapy led to new methods of treating cancer and attracted the attention of the scientific and clinical communities due to the prospects of these methods. Nevertheless, there are still many problems that prevent immunotherapy from calling itself an effective drug in the fight against malignant neoplasms. This review examines the current state of affairs for each immunotherapy method, the effectiveness of the strategies under study, as well as possible ways to overcome the problems that have arisen and increase their therapeutic potentials. -

Molecular Profiling of Innate Immune Response Mechanisms in Ventilator-Associated 2 Pneumonia
bioRxiv preprint doi: https://doi.org/10.1101/2020.01.08.899294; this version posted January 9, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Title: Molecular profiling of innate immune response mechanisms in ventilator-associated 2 pneumonia 3 Authors: Khyatiben V. Pathak1*, Marissa I. McGilvrey1*, Charles K. Hu3, Krystine Garcia- 4 Mansfield1, Karen Lewandoski2, Zahra Eftekhari4, Yate-Ching Yuan5, Frederic Zenhausern2,3,6, 5 Emmanuel Menashi3, Patrick Pirrotte1 6 *These authors contributed equally to this work 7 Affiliations: 8 1. Collaborative Center for Translational Mass Spectrometry, Translational Genomics Research 9 Institute, Phoenix, Arizona 85004 10 2. Translational Genomics Research Institute, Phoenix, Arizona 85004 11 3. HonorHealth Clinical Research Institute, Scottsdale, Arizona 85258 12 4. Applied AI and Data Science, City of Hope Medical Center, Duarte, California 91010 13 5. Center for Informatics, City of Hope Medical Center, Duarte, California 91010 14 6. Center for Applied NanoBioscience and Medicine, University of Arizona, Phoenix, Arizona 15 85004 16 Corresponding author: 17 Dr. Patrick Pirrotte 18 Collaborative Center for Translational Mass Spectrometry 19 Translational Genomics Research Institute 20 445 North 5th Street, Phoenix, AZ, 85004 21 Tel: 602-343-8454; 22 [[email protected]] 23 Running Title: Innate immune response in ventilator-associated pneumonia 24 Key words: ventilator-associated pneumonia; endotracheal aspirate; proteome, metabolome; 25 neutrophil degranulation 26 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.01.08.899294; this version posted January 9, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. -

Identifying Genetic Variants and Pathways Associated with Extreme Levels of Fetal Hemoglobin in Sickle Cell Disease in Tanzania
Nkya et al. BMC Medical Genetics (2020) 21:125 https://doi.org/10.1186/s12881-020-01059-1 RESEARCH ARTICLE Open Access Identifying genetic variants and pathways associated with extreme levels of fetal hemoglobin in sickle cell disease in Tanzania Siana Nkya1,2*, Liberata Mwita2, Josephine Mgaya2, Happiness Kumburu3, Marco van Zwetselaar3, Stephan Menzel4, Gaston Kuzamunu Mazandu5,6,7* , Raphael Sangeda2,8, Emile Chimusa5 and Julie Makani2 Abstract Background: Sickle cell disease (SCD) is a blood disorder caused by a point mutation on the beta globin gene resulting in the synthesis of abnormal hemoglobin. Fetal hemoglobin (HbF) reduces disease severity, but the levels vary from one individual to another. Most research has focused on common genetic variants which differ across populations and hence do not fully account for HbF variation. Methods: We investigated rare and common genetic variants that influence HbF levels in 14 SCD patients to elucidate variants and pathways in SCD patients with extreme HbF levels (≥7.7% for high HbF) and (≤2.5% for low HbF) in Tanzania. We performed targeted next generation sequencing (Illumina_Miseq) covering exonic and other significant fetal hemoglobin-associated loci, including BCL11A, MYB, HOXA9, HBB, HBG1, HBG2, CHD4, KLF1, MBD3, ZBTB7A and PGLYRP1. Results: Results revealed a range of genetic variants, including bi-allelic and multi-allelic SNPs, frameshift insertions and deletions, some of which have functional importance. Notably, there were significantly more deletions in individuals with high HbF levels (11% vs 0.9%). We identified frameshift deletions in individuals with high HbF levels and frameshift insertions in individuals with low HbF. CHD4 and MBD3 genes, interacting in the same sub-network, were identified to have a significant number of pathogenic or non-synonymous mutations in individuals with low HbF levels, suggesting an important role of epigenetic pathways in the regulation of HbF synthesis. -
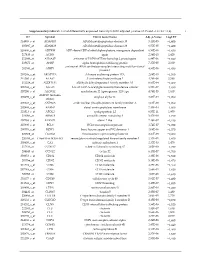
Supplementary Table S1. List of Differentially Expressed
Supplementary table S1. List of differentially expressed transcripts (FDR adjusted p‐value < 0.05 and −1.4 ≤ FC ≥1.4). 1 ID Symbol Entrez Gene Name Adj. p‐Value Log2 FC 214895_s_at ADAM10 ADAM metallopeptidase domain 10 3,11E‐05 −1,400 205997_at ADAM28 ADAM metallopeptidase domain 28 6,57E‐05 −1,400 220606_s_at ADPRM ADP‐ribose/CDP‐alcohol diphosphatase, manganese dependent 6,50E‐06 −1,430 217410_at AGRN agrin 2,34E‐10 1,420 212980_at AHSA2P activator of HSP90 ATPase homolog 2, pseudogene 6,44E‐06 −1,920 219672_at AHSP alpha hemoglobin stabilizing protein 7,27E‐05 2,330 aminoacyl tRNA synthetase complex interacting multifunctional 202541_at AIMP1 4,91E‐06 −1,830 protein 1 210269_s_at AKAP17A A‐kinase anchoring protein 17A 2,64E‐10 −1,560 211560_s_at ALAS2 5ʹ‐aminolevulinate synthase 2 4,28E‐06 3,560 212224_at ALDH1A1 aldehyde dehydrogenase 1 family member A1 8,93E‐04 −1,400 205583_s_at ALG13 ALG13 UDP‐N‐acetylglucosaminyltransferase subunit 9,50E‐07 −1,430 207206_s_at ALOX12 arachidonate 12‐lipoxygenase, 12S type 4,76E‐05 1,630 AMY1C (includes 208498_s_at amylase alpha 1C 3,83E‐05 −1,700 others) 201043_s_at ANP32A acidic nuclear phosphoprotein 32 family member A 5,61E‐09 −1,760 202888_s_at ANPEP alanyl aminopeptidase, membrane 7,40E‐04 −1,600 221013_s_at APOL2 apolipoprotein L2 6,57E‐11 1,600 219094_at ARMC8 armadillo repeat containing 8 3,47E‐08 −1,710 207798_s_at ATXN2L ataxin 2 like 2,16E‐07 −1,410 215990_s_at BCL6 BCL6 transcription repressor 1,74E‐07 −1,700 200776_s_at BZW1 basic leucine zipper and W2 domains 1 1,09E‐06 −1,570 222309_at -

SARS-Cov-2 and Mirna-Like Inhibition Power
SARS-CoV-2 and miRNA-like inhibition power Jacques Demongeot1*, Hervé Seligmann1,2 1 Laboratory AGEIS EA 7407, Team Tools for e-Gnosis Medical & Labcom CNRS/UGA/OrangeLabs Telecom4HealtH, Faculty of Medicine, University Grenoble Alpes (UGA), 38700 La TroncHe, France; [email protected] 2 THe National Natural History Collections, THe Hebrew University of Jerusalem, 91404 Jerusalem, Israel; [email protected] * Correspondence: [email protected] Abstract: (1) Background: RNA viruses and especially coronaviruses could act inside Host cells not only by building tHeir own proteins, but also by perturbing tHe cell metabolism. We sHow tHe possibility of miRNA-like inHibitions by the SARS-CoV-2 concerning for example tHe Hemoglobin and type I interferons syntHeses, Hence HigHly perturbing oxygen distribution in vital organs and immune response as described by clinicians; (2) MetHods: We compare RNA subsequences of SARS- CoV-2 protein S and RNA-dependent RNA polymerase genes to mRNA sequences of beta-globin and type I interferons; (3) Results: RNA subsequences longer tHan eigHt nucleotides from SARS- CoV-2 genome could Hybridize subsequences of tHe mRNA of beta-globin and of type I interferons; (4) Conclusions: Beyond viral protein production, Covid-19 migHt affect vital processes like host oxygen transport and immune response. Keywords: SARS-CoV-2; microRNA-like inHibition; oxygen metabolism; beta-globin translation inHibition; type I interferons translation inHibition. 1. Introduction Viruses act in Host cells by reproducing tHeir own proteins for reconstituting tHeir capsid, duplicating their genome [1] and leaving non-coding RNA or DNA remnants in Host genomes [2]. Moreover, RNA viruses can also form complexes witH existing mRNAs and/or proteins of Host cells. -

Research Article Association Between HBA Locus Copy Number Gains And
INTERNATIONAL JOURNAL OF MEDICAL BIOCHEMISTRY DOI: 10.14744/ijmb.2021.65477 Int J Med Biochem 2021;4(2):91-6 Research Article Association between HBA locus copy number gains and pathogenic HBB gene variants Guven Toksoy1, Nergis Akay2, Agharza Aghayev1, Volkan Karaman1, Sahin Avci1, Tugba Kalayci1, Umut Altunoglu1, Zeynep Karakas2, Zehra Oya Uyguner1 1Department of Medical Genetics, Istanbul University Istanbul Faculty of Medicine, Istanbul, Turkey 2Department of Pediatric Hematology-Oncology, Istanbul University Istanbul Faculty of Medicine, Istanbul, Turkey Abstract Objectives: Alpha (α) and beta (β) thalassemia are the most prevalent genetic hematological disorders. The co-occur- rence of silent β-thalassemia with excess α-globin gene copies is associated with the thalassemia intermedia pheno- type. This study was an investigation of the α-globulin gene dosage and sequence variations in thalassemia patients. Methods: Multiplex ligation-dependent probe amplification and Sanger sequencing were used to identify the hemo- globin subunit alpha 1 (HBA1) and HBA2 gene alterations in 32 patients. Deletion, duplication, and other findings were analyzed in the index cases and family members. Results: Four of the 32 cases (12.5%) were found to have gross duplications. Two cases demonstrated α-globin triplica- tion, and 2 had a quadruplicated HBA1/2 genes. Affected family members revealed genotype-phenotype correlation. In 1 patient, it was observed that quadruplicated HBA genes co-occurrence with hemoglobin subunit beta (HBB) mu- tation was inherited from his mother. Notably, the mother did not demonstrate any thalassemia phenotype. Further investigation showed that the mother was carrying a single copy HBA gene deletion in the trans allele that explained her clinical condition.