Assessing and Mitigating Mobile Sensing Heterogeneities for Activity Recognition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Texting on a Smartwatch Versus a Smartphone: a Comparison of Their Effects on Driving Performance
TEXTING ON A SMARTWATCH VERSUS A SMARTPHONE: A COMPARISON OF THEIR EFFECTS ON DRIVING PERFORMANCE A Dissertation by Joel Persinger Master of Arts, Wichita State University, 2014 Bachelor of Science, Eastern Kentucky University, 2005 Submitted to the Department of Psychology and the faculty of the Graduate School of Wichita State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy December 2017 ©Copyright 2017 by Joel A. Persinger All Rights Reserved TEXTING ON A SMARTWATCH VERSUS A SMARTPHONE: A COMPARISON OF THEIR EFFECTS ON DRIVING PERFORMANCE The following faculty members have examined the final copy of this dissertation for form and content, and recommend that it be accepted in partial fulfillment of the requirement for the degree of Doctor of Philosophy, with a major in Psychology. _____________________________________________ Rui Ni, Committee Chair _____________________________________________ Alex Chaparro, Committee Member _____________________________________________ Barbara Chaparro, Committee Member _____________________________________________ Jibo He, Committee Member _____________________________________________ Jeremy Patterson, Committee Member Accepted for the College of Liberal Arts and Sciences _______________________________________________ Ron Matson, Dean Accepted for the Graduate School _______________________________________________ Dennis Livesay, Dean iii DEDICATION To my beautiful wife, who has pushed me to go further than I ever thought I could. She has truly carried me though graduate school with love and encouragement. iv ABSTRACT The National Safety Council reports that 6 percent or more car crashes involved text messaging from a smartphone. In addition, many studies have found that cell phone while driving increases crash risk by 2.8–5 times (Klauer et al. 2006; Redelmeier and Tibshirani 1997; Violanti 1998; Violanti and Marshall 1996). -

Securing and Managing Wearables in the Enterprise
White Paper: Securing and Managing Wearables in the Enterprise Streamline deployment and protect smartwatch data with Samsung Knox Configure White Paper: Securing and Managing Wearables in the Enterprise 2 Introduction: Smartwatches in the Enterprise As the wearable device market heats up, wrist-worn devices Industries as varied as healthcare, such as smartwatches are leading the pack. According to CCS Insight, forecasts for global sales of smart wearable devices finance, energy, transportation, will grow strongly over the next five years, with the global public safety, retail and hospitality market reaching nearly $30 billion by 2023.1 are deploying smartwatches for While smartwatches for fitness and activity tracking are popular, consumer demand is only part of the equation. added business value. Enterprises are also seeing business value in wearable devices. In a report by Robert Half Technology, 81 percent of CIOs surveyed expect wearable devices like smartwatches to Samsung has been working to address these concerns and become common tools in the workplace.2 has developed the tools to make its Galaxy and Galaxy Active smartwatches customizable, easily manageable and highly secure for enterprise users. This white paper will look at how these tools address key wearable security and manageability challenges, as well as considerations for smartwatch 81% deployments. of CIOs surveyed expect wearable devices like smartwatches to become common tools in the workplace. Industries as varied as healthcare, finance, energy, transportation, public safety, retail and hospitality are deploying smartwatches for added business value, such as hands-free communication for maintenance workers, task management, as well as physical monitoring of field workers in dangerous or remote locations. -

Apple and Nokia: the Transformation from Products to Services
9 Apple and Nokia: The Transformation from Products to Services In the mid- to late 2000s, Nokia flourished as the world’s dominant mobile phone – and mobile phone operating software – producer. Founded in 1871 originally as a rubber boots manufacturer, by 2007 Nokia produced more than half of all mobile phones sold on the planet, and its Symbian mobile operating system commanded a 65.6 percent global market share. 1 But within half a decade, Nokia would falter and be surpassed in the smartphone market not only by Apple’s revolu- tionary iPhone but also by competitors including Google and Samsung. And in September 2013, Nokia would sell its mobile phone business to Microsoft for $7 billion. 2 Apple literally came out of nowhere – it sold exactly zero mobile phones before the year 2007 (the year Nokia held more than half of the global market share) – but by the first quarter of 2013, Apple had captured almost 40 percent of the US smartphone market and over 50 percent of the operating profit in the global handset industry.3 In fiscal year 2013, Apple would sell five times more smart- phones than Nokia: 150 million iPhones compared to Nokia’s sales of 30 million Lumia Windows phones. 4 In contrast to Nokia, Apple real- ized it wasn’t just about the mobile device itself, it was about leveraging software to create a platform for developing compelling mobile experi- ences – including not just telephony but also music, movies, applica- tions, and computing – and then building a business model that allows partners to make money alongside the company (e.g., Apple’s iTunes and AppStore) and, in so doing, perpetuate a virtuous cycle of making the iPhone attractive to customers over multiple life cycles through ever-ex- panding feature sets. -

UI Design for Wearable Devices
FACULTY OF ENGINEERING UNIVERSITY OF PORTO UI Design for Wearable Devices Vitor Mota Master in Informatics and Computing Engineering Supervised by: Miguel Pimenta Monteiro (Assistant professor) Pedro Rocha (GlinttHS) January 2015 2 Abstract Smartwatches have been around for some time now (Ranger 2015), but 2015 is the year this wearable technology will finally get its boom in terms of popularity and growth. Technology giants like Apple, Google and Samsung are betting on their own-line of products such as the Apple Watch, Android Wear and Gear respectively (Apple Inc 2015a; Google Inc 2015b; SAMSUNG 2015). All of these devices are computation capable electronics with very small touch capacitive screens, limited number of hardware buttons with varying screen sizes and even shapes. Our research focused mainly on these constraints and how to successfully develop user friendly GUI’s for such small screens. The goal was to develop a model with guidelines to help developers provide easy to use and user friendly applications at a visual and interaction level to end users. To successfully achieve this, we first took a deep look at the available technology within these devices, including the framework each of the major platforms provide and the underlying hardware capabilities such as sensors like GPS, gyroscope, the use of the touch screen or microphone for user input and whether the shape of the device (round or squared) can have different effects on the design and usability. We also analyzed the impact of placement and arrangement of interface components having in mind that this technology, since it is a wearable watch, can be worn on both wrists and therefore will be used with only one hand that may obscure a different portion of the interface depending on which wrist the user uses it (Chandra and Raghunath 2000). -

Characterizing Smartwatch Usage in the Wild
Characterizing Smartwatch Usage In The Wild Xing Liu1 Tianyu Chen1 Feng Qian1 Zhixiu Guo23 Felix Xiaozhu Lin4 Xiaofeng Wang1 Kai Chen25 1Indiana University Bloomington 2SKLOIS, Institute of Information Engineering, Chinese Academy of Sciences 3Beijing Jiaotong University 4Purdue ECE 5School of Cyber Security, University of Chinese Academy of Sciences ABSTRACT participants, we conduct an in-depth characterization of three key Smartwatch has become one of the most popular wearable aspects of smartwatch usage “in the wild”: usage patterns, energy computers on the market. We conduct an IRB-approved consumption, and network traffic characteristics. This is to our measurement study involving 27 Android smartwatch users. Using knowledge the most comprehensive and in-depth crowd-sourced a 106-day dataset collected from our participants, we perform in- study of smartwatches. Our key measurement results consist of depth characterization of three key aspects of smartwatch usage “in the following. the wild”: usage patterns, energy consumption, and network traffic. • We characterize the smartwatch usage patterns. An Android Based on our findings, we identify key aspects of the smartwatch watch can stay in one of the four states with diverse power ecosystem that can be further improved, propose recommendations, characteristics: fully awake, dozing (with dimmed watch face and point out future research directions. display and restricted system activity), sleeping (screen further turned off), and charging. We find that smartwatch’s wake-up CCS Concepts period accounts for only 2% of the overall usage period among • → the four states. The wake-up sessions are not only short, but Human-centered computing Ubiquitous and mobile also frequent (72 times per day on average). -

Digital Forensic Analysis of Smart Watches
TALLINN UNIVERSITY OF TECHNOLOGY School of Information Technologies Kehinde Omotola Adebayo (174449IVSB) DIGITAL FORENSIC ANALYSIS OF SMART WATCHES Bachelor’s Thesis Supervisor: Hayretdin Bahsi Research Professor Tallinn 2020 TALLINNA TEHNIKAÜLIKOOL Infotehnoloogia teaduskond Kehinde Omotola Adebayo (174449IVSB) NUTIKELLADE DIGITAALKRIMINALISTIKA Bachelor’s Thesis Juhendaja: Hayretdin Bahsi Research Professor Tallinn 2020 Author’s declaration of originality I hereby certify that I am the sole author of this thesis. All the used materials, references to the literature and the work of others have been referred to. This thesis has not been presented for examination anywhere else. Author: Kehinde Omotola Adebayo 30.04.2020 3 Abstract As wearable technology is becoming increasingly popular amongst consumers and projected to continue to increase in popularity they become probable significant source of digital evidence. One category of wearable technology is smart watches and they provide capabilities to receive instant messaging, SMS, email notifications, answering of calls, internet browsing, fitness tracking etc. which can be a great source of digital artefacts. The aim of this thesis is to analyze Samsung Gear S3 Frontier and Fitbit Versa Smartwatches, after which we present findings alongside the limitations encountered. Our result shows that we can recover significant artefacts from the Samsung Gear S3 Frontier, also more data can be recovered from Samsung Gear S3 Frontier than the accompanying mobile phone. We recovered significant data that can serve as digital evidence, we also provided a mapping that would enable investigators and forensic examiners work faster as they are shown where to look for information in the course of an investigation. We also presented the result of investigating Fitbit Versa significant artefacts like Heart rate, sleep, exercise and personal data like age, weight and height of the user of the device, this shows this device contains artefacts that might prove useful for forensic investigators and examiners. -
API Diagrams
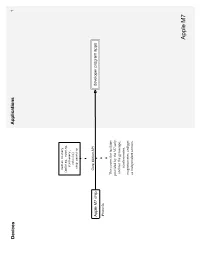
Devices Applications 1 motion history (walking, running, stationary, vehicle) step counting Core Motion API Apple M7 chip developer program apps iPhone 5s This covers the facilities provided by the M7 only, and not the gyroscope, accelerometer, magnetometer, and gps as independent sensors. Apple M7 Devices Applications Services 2 Runkeeper Argus Fitbit bluetooth 4.0 Withings LifeTrak Move C300 iOS Argus uses each New Balance LifeTRNr Watches services’ Pebble SmartWatch Sleep Time respective API. Mio Alpha Data is only viewable in the Wahoo Blue HR Heart Rate Strap iOS/Android Argus app, not in the website Stress Check iOS/Android Instant Heart Rate CSV Azumio cloud CSV premium feature or text iOS/Android/Windows table Phone/Windows 8 Cardio Buddy Data is not available for for Argus (steps only), iOS viewing from website, but Instant Heart Rate, Stress can sync to multiple Check and Sleep Time devices. Instant Fitness iOS CSV or text Fitness Buddy table iOS/Android text Glucose Buddy CSV table Glucose Buddy iOS/Android Azumio Devices Applications Services 3 Viera is Panasonic’s Smart TV platform that runs 3rd- party apps App requires Link Armband armband and API is active to subscription current developers but closed off to activity Bluetooth 2.0 new development heart rate food sleep BodyMedia FIT nutrients steps iOS/Android/Viera BodyMedia FIT API partner Armband Advantage Activity Manager program USB web dashboard BodyMedia SYNC Jawbone UP API apps Windows/Mac The desktop software only location CORE Armband transfers data to the registered image “Activity Manager” developers cardiac service. It does not allow oauth 2.0 food users to view data json goals mood activity sleep RF workout Since the armbands do not have displays, the Display Device is a Display way to show the data. -

Factors Influencing the Adoption of Smart Wearable Devices
Scholars' Mine Masters Theses Student Theses and Dissertations Spring 2016 Factors influencing the adoption of smart wearable devices Apurva Adapa Follow this and additional works at: https://scholarsmine.mst.edu/masters_theses Part of the Technology and Innovation Commons Department: Recommended Citation Adapa, Apurva, "Factors influencing the adoption of smart wearable devices" (2016). Masters Theses. 7492. https://scholarsmine.mst.edu/masters_theses/7492 This thesis is brought to you by Scholars' Mine, a service of the Missouri S&T Library and Learning Resources. This work is protected by U. S. Copyright Law. Unauthorized use including reproduction for redistribution requires the permission of the copyright holder. For more information, please contact [email protected]. FACTORS INFLUENCING THE ADOPTION OF SMART WEARABLE DEVICES by APURVA ADAPA A THESIS Presented to the faculty of the Graduate School of the MISSOURI UNIVERSITY OF SCIENCE AND TECHNOLOGY In Partial Fulfillment of the Requirements for the Degree MASTER OF SCIENCE IN INFORMATION SCIENCE AND TECHNOLOGY 2016 Approved by Dr. Fiona Fui Hoon Nah, Advisor Dr. Keng L. Siau Dr. Richard Hall Copyright 2016 Apurva Adapa All Rights Reserved iii ABSTRACT This study aims to examine the factors and issues in adoption of smart wearable devices. Wearable devices have many functions to offer which make them very useful in our daily lives. However, factors influencing the adoption of these devices are not well understood. This research explores the inhibiting and contributing factors influencing the adoption of wearable devices by employing the laddering approach. Qualitative data were collected through in-depth interviews using the laddering technique in order to understand these factors. -

Fossil's Gen 5 LTE Touchscreen Smartwatch
FOSSIL LAUNCHES ITS FIRST LTE-EQUIPPED SMARTWATCH – GEN 5 LTE The new smartwatch boasts new cellular call and text abilities for Verizon users with Android™ phones on Fossil’s heralded fifth-generation smartwatch Richardson, Texas – January 11, 2021 – It is with great excitement that Fossil brand announces the newest addition to our wearables assortment: the Gen 5 LTE Touchscreen Smartwatch. Enabled with 4G cellular connectivity powered by Verizon, Qualcomm’s Snapdragon Wear 3100 platform and Wear OS by Google™, Android phone users can stay more connected with texting and calling abilities without needing their phone. As the newest iteration of Fossil’s latest touchscreen smartwatch, users will also enjoy software updates from Wear OS by Google and Fossil Group, speaker functionality, smart battery modes, 8GB of storage, and the performance and capabilities of the Qualcomm® Snapdragon Wear™ 3100 platform. The new smartwatch is launching first in the US and specifically designed for Android phone users with eligible Verizon service. Gen 5 LTE is Fossil’s first introduction into the cellular wearables space, designed with the Wear OS by Google team and Qualcomm. Fossil's smartwatch LTE capability is exclusively available for Android phone consumers through Verizon utilizing their Number Share feature. With an additional data plan, Number Share allows users' phones and watches to be synced to the same number so when away from your phone or WiFi, you will continue to receive calls and texts on your watch — only an LTE signal is needed. To connect the cellular functionality, Gen 5 LTE comes with the integrated 4G LTE modem in the Snapdragon Wear platform with an eSIM chip, making Fossil the first mass-market fashion brand on Wear OS by Google to offer eSIM. -

The Relative Impact of Smartwatch and Smartphone Use While Driving on Workload, Attention, and Driving Performance T
Applied Ergonomics 75 (2019) 8–16 Contents lists available at ScienceDirect Applied Ergonomics journal homepage: www.elsevier.com/locate/apergo The relative impact of smartwatch and smartphone use while driving on workload, attention, and driving performance T ∗ David Perlmana, Aubrey Samosta, August G. Domelb, Bruce Mehlerc, , Jonathan Dobresc, Bryan Reimerc a MIT Engineering Systems Division, United States b Harvard University – School of Engineering and Applied Sciences, United States c MIT AgeLab and New England University Transportation Center, United States ARTICLE INFO ABSTRACT Keywords: The impact of using a smartwatch to initiate phone calls on driver workload, attention, and performance was Attention compared to smartphone visual-manual (VM) and auditory-vocal (AV) interfaces. In a driving simulator, 36 Workload participants placed calls using each method. While task time and number of glances were greater for AV calling Detection response task (DRT) on the smartwatch vs. smartphone, remote detection task (R-DRT) responsiveness, mean single glance duration, Distraction percentage of long duration off-road glances, total off-road glance time, and percent time looking off-road were Age similar; the later metrics were all significantly higher for the VM interface vs. AV methods. Heart rate and skin conductance were higher during phone calling tasks than “just driving”, but did not consistently differentiate calling method. Participants exhibited more erratic driving behavior (lane position and major steering wheel reversals) for smartphone VM calling compared to both AV methods. Workload ratings were lower for AV calling on both devices vs. VM calling. 1. Introduction recognition function compared to voice entry on a smartphone; con- versely, task completion time was shorter with Glass. -

Technology, Media & Telecommunications Predictions 2014
Technology, Media & Telecommunications Predictions 2014 Contents Foreword 3 Technology 5 The $750 billion converged living room: a plateau approaches 6 Wearables: the eyes have it 10 One became many: the tablet market stratifies 13 Massive Open Online Courses (MOOCs): not disruptive yet, but the future looks bright 16 eVisits: the 21st century housecall 20 Media 23 Doubling up on pay‑TV 24 Television measurement: for better and worse 26 Broadcast sports rights: premium plus 28 Performance rights lift recorded music revenues 30 ‘Cordless’ video‑on‑demand leaps in Sub‑Saharan Africa 32 Telecommunications 35 Short messaging services versus instant messaging: value versus volume 36 Phablets are not a phad 39 The smartphone generation gap: over‑55? There’s no app for that 42 ‘Ruggedized’ data devices at $250: reinventing the business case for mobile field force 45 Recent Deloitte thought leadership 47 Contacts at Deloitte Touche Tohmatsu Limited (DTTL) and its member firms 48 Endnotes 49 Technology, Media & Telecommunications Predictions 2014 1 Igal Brightman, 1945‑2013 This edition of TMT Predictions is dedicated to the memory of Igal Brightman who passed away in August 2013. Igal was the Global Managing Partner and Chairman of the TMT Industry Group for nine years, and his tireless energy and enthusiasm helped define much of our practice, including thought leadership. Igal was a pioneering, unflinching supporter of Deloitte’s research into the TMT sector. He was a steadfast advocate of the need for professional services firms to blend functional skills with leading industry knowledge. He was passionate about investing in research, and through Igal’s support from its launch in 2001, TMT Predictions has become one of the flagship research titles used by Deloitte members firms in over 80 countries around the world. -

Can Smartwatches Replace Smartphones for Posture Tracking?
Sensors 2015, 15, 26783-26800; doi:10.3390/s151026783 sensorsOPEN ACCESS ISSN 1424-8220 www.mdpi.com/journal/sensors Article Can Smartwatches Replace Smartphones for Posture Tracking? Bobak Mortazavi 1;y;*, Ebrahim Nemati 2;y, Kristina VanderWall 3, Hector G. Flores-Rodriguez 4, Jun Yu Jacinta Cai 5, Jessica Lucier 3, Arash Naeim 3 and Majid Sarrafzadeh 1;2 1 Computer Science Department, University of California, Los Angeles, Los Angeles, CA 90095, USA; E-Mail: [email protected] 2 Department of Electrical Engineering, University of California, Los Angeles, Los Angeles, CA 90095, USA; E-Mail:[email protected] 3 School of Medicine, University of California, Los Angeles, Los Angeles, CA 90095, USA; E-Mails: [email protected] (K.V.W.); [email protected] (J.L.); [email protected] (A.N.) 4 Computer Science Department, El Camino College, Torrance, CA 90506, USA; E-Mail: hct.fl[email protected] 5 Computer Science Department, University of Alabama Birmingham, Birmingham, AL 35233, USA; E-Mail: [email protected] y These authors contributed equally to this work. * Author to whom correspondence should be addressed; E-Mail: [email protected]. Academic Editors: Steffen Leonhardt and Daniel Teichmann Received: 14 July 2015 / Accepted: 16 October 2015 / Published: 22 October 2015 Abstract: This paper introduces a human posture tracking platform to identify the human postures of sitting, standing or lying down, based on a smartwatch. This work develops such a system as a proof-of-concept study to investigate a smartwatch’s ability to be used in future remote health monitoring systems and applications.