The Fundamental Theorem of Linear Algebra
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fifth International Congress of Chinese Mathematicians Part 1
AMS/IP Studies in Advanced Mathematics S.-T. Yau, Series Editor Fifth International Congress of Chinese Mathematicians Part 1 Lizhen Ji Yat Sun Poon Lo Yang Shing-Tung Yau Editors American Mathematical Society • International Press Fifth International Congress of Chinese Mathematicians https://doi.org/10.1090/amsip/051.1 AMS/IP Studies in Advanced Mathematics Volume 51, Part 1 Fifth International Congress of Chinese Mathematicians Lizhen Ji Yat Sun Poon Lo Yang Shing-Tung Yau Editors American Mathematical Society • International Press Shing-Tung Yau, General Editor 2000 Mathematics Subject Classification. Primary 05–XX, 08–XX, 11–XX, 14–XX, 22–XX, 35–XX, 37–XX, 53–XX, 58–XX, 62–XX, 65–XX, 20–XX, 30–XX, 80–XX, 83–XX, 90–XX. All photographs courtesy of International Press. Library of Congress Cataloging-in-Publication Data International Congress of Chinese Mathematicians (5th : 2010 : Beijing, China) p. cm. (AMS/IP studies in advanced mathematics ; v. 51) Includes bibliographical references. ISBN 978-0-8218-7555-1 (set : alk. paper)—ISBN 978-0-8218-7586-5 (pt. 1 : alk. paper)— ISBN 978-0-8218-7587-2 (pt. 2 : alk. paper) 1. Mathematics—Congresses. I. Ji, Lizhen, 1964– II. Title. III. Title: 5th International Congress of Chinese Mathematicians. QA1.I746 2010 510—dc23 2011048032 Copying and reprinting. Material in this book may be reproduced by any means for edu- cational and scientific purposes without fee or permission with the exception of reproduction by services that collect fees for delivery of documents and provided that the customary acknowledg- ment of the source is given. This consent does not extend to other kinds of copying for general distribution, for advertising or promotional purposes, or for resale. -

Department of Mathematics
Department of Mathematics The Department of Mathematics seeks to sustain its top ranking in research and education by hiring the best faculty, with special attention to the recruitment of women and members of underrepresented minority groups, and by continuing to serve the varied needs of the department’s graduate students, mathematics majors, and the broader MIT community. Faculty Awards and Honors A number of major distinctions were given to the department’s faculty this year. Professor George Lusztig received the 2014 Shaw Prize in Mathematical Sciences “for his fundamental contributions to algebra, algebraic geometry, and representation theory, and for weaving these subjects together to solve old problems and reveal beautiful new connections.” This award provides $1 million for research support. Professors Paul Seidel and Gigliola Staffilani were elected fellows of the American Academy of Arts and Sciences. Professor Larry Guth received the Salem Prize for outstanding contributions in analysis. He was also named a Simons Investigator by the Simons Foundation. Assistant professor Jacob Fox received the 2013 Packard Fellowship in Science and Engineering, the first mathematics faculty member to receive the fellowship while at MIT. He also received the National Science Foundation’s Faculty Early Career Development Program (CAREER) award, as did Gonçalo Tabuada. Professors Roman Bezrukavnikov, George Lusztig, and Scott Sheffield were each awarded a Simons Fellowship. Professor Tom Leighton was elected to the Massachusetts Academy of Sciences. Assistant professors Charles Smart and Jared Speck each received a Sloan Foundation Research Fellowship. MIT Honors Professor Tobias Colding was selected by the provost for the Cecil and Ida Green distinguished professorship. -

AMS Officers and Committee Members
Of®cers and Committee Members Numbers to the left of headings are used as points of reference 1.1. Liaison Committee in an index to AMS committees which follows this listing. Primary All members of this committee serve ex of®cio. and secondary headings are: Chair Felix E. Browder 1. Of®cers Michael G. Crandall 1.1. Liaison Committee Robert J. Daverman 2. Council John M. Franks 2.1. Executive Committee of the Council 3. Board of Trustees 4. Committees 4.1. Committees of the Council 2. Council 4.2. Editorial Committees 4.3. Committees of the Board of Trustees 2.0.1. Of®cers of the AMS 4.4. Committees of the Executive Committee and Board of President Felix E. Browder 2000 Trustees Immediate Past President 4.5. Internal Organization of the AMS Arthur M. Jaffe 1999 4.6. Program and Meetings Vice Presidents James G. Arthur 2001 4.7. Status of the Profession Jennifer Tour Chayes 2000 4.8. Prizes and Awards H. Blaine Lawson, Jr. 1999 Secretary Robert J. Daverman 2000 4.9. Institutes and Symposia Former Secretary Robert M. Fossum 2000 4.10. Joint Committees Associate Secretaries* John L. Bryant 2000 5. Representatives Susan J. Friedlander 1999 6. Index Bernard Russo 2001 Terms of members expire on January 31 following the year given Lesley M. Sibner 2000 unless otherwise speci®ed. Treasurer John M. Franks 2000 Associate Treasurer B. A. Taylor 2000 2.0.2. Representatives of Committees Bulletin Donald G. Saari 2001 1. Of®cers Colloquium Susan J. Friedlander 2001 Executive Committee John B. Conway 2000 President Felix E. -

January 2007 Prizes and Awards
January 2007 Prizes and Awards 4:25 P.M., Saturday, January 6, 2007 MATHEMATICAL ASSOCIATION OF AMERICA DEBORAH AND FRANKLIN TEPPER HAIMO AWARDS FOR DISTINGUISHED COLLEGE OR UNIVERSITY TEACHING OF MATHEMATICS In 1991, the Mathematical Association of America instituted the Deborah and Franklin Tepper Haimo Awards for Distinguished College or University Teaching of Mathematics in order to honor college or university teachers who have been widely recognized as extraordinarily successful and whose teaching effectiveness has been shown to have had influence beyond their own institutions. Deborah Tepper Haimo was president of the Association, 1991–1992. Citation Jennifer Quinn Jennifer Quinn has a contagious enthusiasm that draws students to mathematics. The joy she takes in all things mathematical is reflected in her classes, her presentations, her publications, her videos and her on-line materials. Her class assignments often include nonstandard activities, such as creating time line entries for historic math events, or acting out scenes from the book Proofs and Refutations. One student created a children’s story about prime numbers and another produced a video documentary about students’ perceptions of math. A student who had her for six classes says, “I hope to become a teacher after finishing my master’s degree and I would be thrilled if I were able to come anywhere close to being as great a teacher as she is.” Jenny developed a variety of courses at Occidental College. Working with members of the physics department and funded by an NSF grant, she helped develop a combined yearlong course in calculus and mechanics. She also developed a course on “Mathematics as a Liberal Art” which included computer discussions, writing assignments, and other means to draw technophobes into the course. -

Peter D. Lax: a Life in Mathematics
Peter D. Lax: A Life in Mathematics There is apparently little to say about the mathematical contributions of Peter Lax and his effect on the work of so many others that has not already been said in several other places, including the Wikipedia, the web site of the Norwegian Academy’s Abel Prize, and in quite a few other tributes. These lines are being written on the occasion of Peter’s 90th birthday — which will be mathematically celebrated at the 11th AIMS Conference on Dynamical Systems, Differential Equations and Applications, to be held in July 2016 in Orlando, FL — and their author merely intends to summarize some salient and relevant points of Peter’s life and work for this celebration. The Life. Peter was born on May 1st, 1926 into an upper-middle class, highly educated Jewish family in Budapest, Hungary. Fortunately for him, his family realized early on the danger to Jewish life and limb posed by the proto-fascist government of Miklós Horthy, a former admiral in the Austro-Hungarian Navy, who ruled the country from March 1920 to October 1944 with the title of Regent of the Kingdom of Hungary. The Laxes took the last boat from Lisbon to New York in November 1941. In New York, Peter completed his high-school studies at the highly competitive Stuyvesant High School and managed three semesters of mathematics at New York University (NYU) before being drafted into the U.S. Army. His mathematical talents were already recognized by several leading Jewish and Hungarian mathematicians who had fled the fascist cloud gathering over Western and Central Europe, including Richard Courant at NYU and John von Neumann at Princeton. -

GILBERT STRANG Education Positions Held Awards and Duties
CURRICULUM VITAE : GILBERT STRANG Work: Department of Mathematics, M.I.T. Cambridge MA 02139 Phone: 617{253{4383 Fax: 617{253{4358 e-mail: [email protected] URL: http://math.mit.edu/ gs Home: 7 Southgate Road Wellesley MA 02482 Phone: 781{235{9537 Education 1. 1952{1955 William Barton Rogers Scholar, M.I.T. (S.B. 1955) 2. 1955{1957 Rhodes Scholar, Oxford University (B.A., M.A. 1957) 3. 1957{1959 NSF Fellow, UCLA (Ph.D. 1959) Positions Held 1. 1959{1961 C.L.E. Moore Instructor, M.I.T. 2. 1961{1962 NATO Postdoctoral Fellow, Oxford University 3. 1962{1964 Assistant Professor of Mathematics, M.I.T. 4. 1964{1970 Associate Professor of Mathematics, M.I.T. 5. 1970{ Professor of Mathematics, M.I.T. Awards and Duties 1. Alfred P. Sloan Fellow (1966{1967) 2. Chairman, M.I.T. Committee on Pure Mathematics (1975{1979) 3. Chauvenet Prize, Mathematical Association of America (1976) 4. Council, Society for Industrial and Applied Mathematics (1977{1982) 5. NSF Advisory Panel on Mathematics (1977{1980) (Chairman 1979{1980) 6. CUPM Subcommittee on Calculus (1979{1981) 7. Fairchild Scholar, California Institute of Technology (1980{1981) 8. Honorary Professor, Xian Jiaotong University, China (1980) 9. American Academy of Arts and Sciences (1985) 10. Taft Lecturer, University of Cincinnati (1977) 11. Gergen Lecturer, Duke University (1983) 12. Lonseth Lecturer, Oregon State University (1987) 13. Magnus Lecturer, Colorado State University (2000) 14. Blumberg Lecturer, University of Texas (2001) 15. AMS-SIAM Committee on Applied Mathematics (1990{1992) 16. Vice President for Education, SIAM (1991{1996) 17. -

Officers and Committee Members, Volume 48, Number 9
Officers and Committee Members Numbers to the left of headings are used as points of reference 2. Council in an index to AMS committees which follows this listing. Primary and secondary headings are: 2.0.1. Officers of the AMS 1. Officers President Hyman Bass 2002 1.1. Liaison Committee Immediate Past President 2. Council Felix E. Browder 2001 2.1. Executive Committee of the Council Vice Presidents James G. Arthur 2001 3. Board of Trustees Ingrid Daubechies 2003 4. Committees David Eisenbud 2002 4.1. Committees of the Council Secretary Robert J. Daverman 2002 4.2. Editorial Committees Associate Secretaries* John L. Bryant 2002 4.3. Committees of the Board of Trustees 4.4. Committees of the Executive Committee and Board of Susan J. Friedlander 2001 Trustees Bernard Russo 2001 4.5. Internal Organization of the AMS Lesley M. Sibner 2002 4.6. Program and Meetings Treasurer John M. Franks 2002 4.7. Status of the Profession Associate Treasurer B. A. Taylor 2002 4.8. Prizes and Awards 4.9. Institutes and Symposia 4.10. Joint Committees 2.0.2. Representatives of Committees 5. Representatives Bulletin Donald G. Saari 2001 6. Index Colloquium Susan J. Friedlander 2001 Terms of members expire on January 31following the year given Executive Committee Robert L. Bryant 2003 unless otherwise specified. Executive Committee Joel H. Spencer 2001 Executive Committee Karen Vogtmann 2002 Journal of the AMS Carlos E. Kenig 2003 1. Mathematical Reviews Hugh L. Montgomery 2001 Officers Mathematical Surveys President Hyman Bass 2002 and Monographs Michael P. Loss 2002 Immediate Past President Mathematics of Felix E. -

Gilbert Strang: the Changing Face of Applied Mathematics >>>
ISSUE 2 Newsletter of Institute for Mathematical Sciences, NUS 2003 Mathematical Conversations Gilbert Strang: The Changing Face of Applied Mathematics >>> An interview of Gilbert Strang by Y.K. Leong Gilbert Strang is a prominent scholar in applied mathematics and an active promoter of mathematics and mathematical education in the United States. He has made numerous contributions to numerical analysis, wavelets and signal processing. He is also well-known for his textbooks on linear algebra and applied mathematics at the undergraduate and advanced levels. He is editor of many well-known journals and has given invited lectures throughout the world. He has received numerous honors and awards and is a Fellow of the American Academy of Arts and Sciences. He has served on many committees, in particular, as President of the Society of Industrial and Applied Mathematics (SIAM) in 1999 and 2000. He is currently Chair of the US National Committee on Mathematics for 2003-2004. He has been Professor of Mathematics at MIT since 1970. He has been closely associated with NUS, having served as a member of the University’s International Advisory Panel from 1998 to 2001 during a period of reorganization. The Editor of Imprints interviewed him on 18 July 2003 at the Institute for Mathematical Sciences when he visited NUS as a guest of the Institute and the Singapore MIT Alliance from 15 to 19 July 2003. The following is an edited transcript of the interview in which he spoke about e-learning and teaching, applied mathematics in the service of society and the changing landscape of applied mathematics. -

2009 Integral
Autumn 2009 Volume 4 Massachusetts Institute of Technology 1ntegraL NEWS FROM THE MATHEMATICS DEPARTMENT AT MIT renewal. About a third of our tenured faculty are nearing retirement. Several have already Inside initiated the process. This spring we celebrated Hartley Rogers’ 54 years on the MIT faculty • Recounting our history 2 at a retirement luncheon for him (see story on page 8). Next year more faculty are planning • Faculty news 3 to retire, including Mike Artin, David Benney, • Student awards 4 Dan Kleitman, Arthur Mattuck, Dan Stroock and Alar Toomre. The Sputnik-era generation • New doctorates 4 has been the core of our department for a long • Donor profile 5 time. Reconstituting ourselves with a new generation is necessary and healthy, of course, • Women in math 6 but still it is hard to imagine our department without these extraordinary people. Fortu- • Math Project Lab 7 nately, many plan to continue teaching and • Celebrating Singer 8 other activities post-retirement. Dear Friends, Our departmental history book, Recountings: Conversations with MIT Mathematicians, has TIME FLIES . Five years ago I was entrusted Fundraising activities continue unabated. with the job of “running” our department. enjoyed tremendous success since its publica- Breakfast talks were held here and in Cali- That being the usual term for department tion last winter. It tells personal stories about fornia to showcase the department’s research. heads, by now I should have gratefully science, politics and administration from the More talks are planned for this year. One handed over the reins of leadership to one 1950s and 1960s. We were most fortunate of our goals is to endow the RSI and SPUR of my colleagues to carry on with his or her to have interviewed former department head summer programs that provide research expe- vision for the future. -

Zoomnotes for Linear Algebra
ZOOMNOTES FOR LINEAR ALGEBRA GILBERT STRANG Massachusetts Institute of Technology WELLESLEY - CAMBRIDGE PRESS Box 812060 Wellesley MA 02482 ZoomNotes for Linear Algebra Copyright ©2021 by Gilbert Strang ISBN 978-1-7331466-4-7 LATEX typesetting by Ashley C. Fernandes Printed in the United States of America 9 8 7 6 5 4 3 2 1 Texts from Wellesley - Cambridge Press Linear Algebra for Everyone, 2020, Gilbert Strang ISBN 978-1-7331466-3-0 Linear Algebra and Learning from Data, 2019, Gilbert Strang ISBN 978-0-6921963-8-0 Introduction to Linear Algebra, 5th Ed., 2016, Gilbert Strang ISBN 978-0-9802327-7-6 Computational Science and Engineering, Gilbert Strang ISBN 978-0-9614088-1-7 Differential Equations and Linear Algebra, Gilbert Strang ISBN 978-0-9802327-9-0 Wavelets and Filter Banks, Gilbert Strang and Truong Nguyen ISBN 978-0-9614088-7-9 Introduction to Applied Mathematics, Gilbert Strang ISBN 978-0-9614088-0-0 Calculus Third Edition, Gilbert Strang ISBN 978-0-9802327-5-2 Algorithms for Global Positioning, Kai Borre & Gilbert Strang ISBN 978-0-9802327-3-8 Essays in Linear Algebra, Gilbert Strang ISBN 978-0-9802327-6-9 An Analysis of the Finite Element Method, 2008 edition, Gilbert Strang and George Fix ISBN 978-0-9802327-0-7 Wellesley - Cambridge Press Gilbert Strang’s page : math.mit.edu/ gs ∼ Box 812060, Wellesley MA 02482 USA For orders : math.mit.edu/weborder.php www.wellesleycambridge.com Outside US/Canada : www.cambridge.org Select books, India : www.wellesleypublishers.com The textbook websites are math.mit.edu/linearalgebra and math.mit.edu/everyone. -

Recountings Tells of the Influential US Mathematics Department at the Massachusetts Institute of Technology (MIT) Through Interviews with a Dozen Faculty Members
“Recountings tells of the influential US mathematics department at the Massachusetts Institute of Technology (MIT) through interviews with a dozen faculty members . The interest in teaching among these senior faculty members is broad and deep. The professors share their strategies for achieving research success, from working on prize problems to developing an intuitive feel for proofs. They explain how new research directions have come from interactions with students and colleagues or from writing a review article. The insights in [this book] will inspire mathematicians and scientists to come.” —Eric Altschuler, NATURE “Students currently contemplating or pursuing a mathematics-related career should find MIT’s oral history illuminating and thought provoking. It is a remarkable institutional story, recalled and superbly narrated by those much concerned.” —Mathematics Teacher “Recountings provides a history of the MIT Mathematics Department, as told through interviews conducted with 12 of its current and former faculty members, plus Zipporah (Fagi) Levinson, widow of Norman Levinson (and one-time ‘den mother’ of the department). What emerges is a piecemeal yet compelling portrait of the department’s rapid post-WW II transformation from a program largely focused on offering mathematical instruction to engineering students, to a world-class research enterprise. Highly recommended.” —CHOICE “Though never in the eye of popular culture, these men kept society advancing with their minds. Recountings is a collection of interviews and anecdotes from the geniuses of MIT who have pursued mathematics as their life’s careers and obsessions. These men have been responsible for major scientific advances throughout history . Recountings is an intriguing look at mathematics and the men behind it.” —Library Bookwatch “It’s full of really good stuff. -
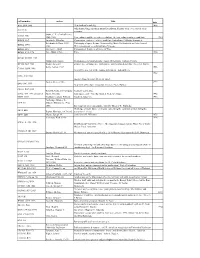
Call Number Author Title Date AG5 .B64 2006 New Book of Knowledge
call number author Title date AG5 .B64 2006 New book of knowledge. 2006 John Simon Guggenheim memorial foundation. Reports of the secretary & of the AS911.J6 treasurer. Snow, C. P. (Charles Percy), AZ361 .S56 1905-1980 Two cultures and the scientific revolution, the two cultures and a second look 1963 BD632 .F67 Formánek, Miloslav. Časoprostor v politice : některé problémy fyzikalismu / Miloslav Formánek. Reichenbach, Hans, 1891- Philosophy of space & time. Translated by Maria Reichenbach and John Freund. BD632 .R413 1953. With introductory remarks by Rudolf Carnap. BD632.G92 Gurnbaum, Adolf Philosophical Problems of Space of Time BD638 .P73 1996 Price, Huw, 1953- Price. 1996 BH301.N3 H55 1985 Hildebrandt, Stefan. Mathematics and optimal form / Stefan Hildebrandt, Anthony Tromba. BT130 .B69 1983 Brams, Steven J. omniscience, omnipotence, immortality, and incomprehensibility / Steven J. Brams. Berry, Adrian, 1937- 1996 CB161 .B459 1996 Next 500 years : life in the coming millennium / Adrian Berry. 1982 E158 .A48 1982 America from the road / Reader's digest. Forbes, Steve, 1947- 1999 E885 .F67 1999 New birth of freedom : vision for America / Steve Forbes. G1019 .R47 1955 Rand McNally and Company. Standard world atlas. G70.4 .S77 1992 oversized Strain, Priscilla. Looking at earth / Priscilla Strain & Frederick Engle. 1992 GB55 .G313 Gaddum, Leonard William, Harold L. Knowles. 1953 Fairbridge, Rhodes W. GC9 .F3 (Rhodes Whitmore), 1914- 2006. Encyclopedia of oceanography, edited by Rhodes W. Fairbridge. Challenge of man's future; an inquiry concerning the condition of man during the GF31 .B68 Brown, Harrison, 1917-1986. years that lie ahead. GF47 .M63 Moran, Joseph M. [and] James H. Wiersma. 1973 Anderson, Walt, 1933- 1996 GN281.4 .A53 1996 Evolution isn't what it used to be : the augmented animal and the whole wired world / Walter Truett Anderson.