Reply to Reviewer 1 We Would Like to Appreciate the Valuable Comments Which Help for Improving the Manuscript
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 7. Building a Safe and Comfortable Society
Section 1 Realizing a Universal Society Building a Safe and Comfortable Chapter 7 Society Section 1 Realizing a Universal Society 1 Realizing Accessibility through a Universal Design Concept The “Act on Promotion of Smooth Transportation, etc. of Elderly Persons, Disabled Persons, etc.” embodies the universal design concept of “freedom and convenience for anywhere and anyone”, making it mandatory to comply with “Accessibility Standards” when newly establishing various facilities (passenger facilities, various vehicles, roads, off- street parking facilities, city parks, buildings, etc.), mandatory best effort for existing facilities as well as defining a development target for the end of FY2020 under the “Basic Policy on Accessibility” to promote accessibility. Also, in accordance with the local accessibility plan created by municipalities, focused and integrated promotion of accessibility is carried out in priority development district; to increase “caring for accessibility”, by deepening the national public’s understanding and seek cooperation for the promotion of accessibility, “accessibility workshops” are hosted in which you learn to assist as well as virtually experience being elderly, disabled, etc.; these efforts serve to accelerate II accessibility measures (sustained development in stages). Chapter 7 (1) Accessibility of Public Transportation In accordance with the “Act on Figure II-7-1-1 Current Accessibility of Public Transportation Promotion of Smooth Transportation, etc. (as of March 31, 2014) of Elderly Persons, Disabled -

October 2013 Global Catastrophe Recap 2 2
October 2013 Global Catastrophe Recap Table of Contents Executive0B Summary 3 United2B States 4 Remainder of North America (Canada, Mexico, Caribbean, Bermuda) 4 South4B America 4 Europe 4 6BAfrica 5 Asia 5 Oceania8B (Australia, New Zealand and the South Pacific Islands) 6 8BAAppendix 7 Contact Information 14 Impact Forecasting | October 2013 Global Catastrophe Recap 2 2 Executive0B Summary . Windstorm Christian affects western and northern Europe; insured losses expected to top USD1.35 billion . Cyclone Phailin and Typhoon Fitow highlight busy month of tropical cyclone activity in Asia . Deadly bushfires destroy hundreds of homes in Australia’s New South Wales Windstorm Christian moved across western and northern Europe, bringing hurricane-force wind gusts and torrential rains to several countries. At least 18 people were killed and dozens more were injured. The heaviest damage was sustained in the United Kingdom, France, Belgium, the Netherlands and Scandinavia, where a peak wind gust of 195 kph (120 mph) was recorded in Denmark. More than 1.2 million power outages were recorded and travel was severely disrupted throughout the continent. Reports from European insurers suggest that payouts are likely to breach EUR1.0 billion (USD1.35 billion). Total economic losses will be even higher. Christian becomes the costliest European windstorm since WS Xynthia in 2010. Cyclone Phailin became the strongest system to make landfall in India since 1999, coming ashore in the eastern state of Odisha. At least 46 people were killed. Tremendous rains, an estimated 3.5-meter (11.0-foot) storm surge, and powerful winds led to catastrophic damage to more than 430,000 homes and 668,000 hectares (1.65 million) acres of cropland. -

Met Office Unified Model Tropical Cyclone Performance Following Major Changes to the Initialization Scheme and a Model Upgrade
OCTOBER 2016 H E M I N G 1433 Met Office Unified Model Tropical Cyclone Performance Following Major Changes to the Initialization Scheme and a Model Upgrade JULIAN T. HEMING Met Office, Exeter, Devon, United Kingdom (Manuscript received 1 March 2016, in final form 27 June 2016) ABSTRACT The Met Office has used various schemes to initialize tropical cyclones (TCs) in its numerical weather pre- diction models since the 1980s. The scheme introduced in 1994 was particularly successful in reducing track forecast errors in the model. Following modifications in 2007 the scheme was still beneficial, although to a lesser degree than before. In 2012 a new trial was conducted that showed that the scheme now had a detrimental impact on TC track forecasts. As a consequence of this, the scheme was switched off. The Met Office Unified Model (MetUM) underwent a major upgrade in 2014 including a new dynamical core, changes to the model physics, an increase in horizontal resolution, and changes to satellite data usage. An evaluation of the impact of this change on TC forecasts found a positive impact both on track and particularly intensity forecasts. Following implementation of the new model formulation in 2014, a new scheme for initialization of TCs in the MetUM was developed that involved the assimilation of central pressure estimates from TC warning centers. A trial showed that this had a positive impact on both track and intensity predictions from the model. Operational results from the MetUM in 2014 and 2015 showed that the combined impact of the model upgrade and new TC initialization scheme was a dramatic cut in both TC track forecast errors and intensity forecast bias. -
Pdf | 431.12 Kb
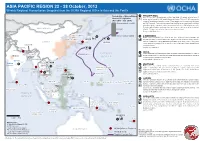
ASIA PACIFIC REGION 22 - 28 October, 2013 Weekly Regional Humanitarian Snapshot from the OCHA Regional Office in Asia and the Pacific 1 PHILIPPINES Probability of Above/Below As of 21 Oct, the 7.2M earthquake in Bohol had killed 186 people, affected some 3 Normal Precipitation r" million, and left nearly 381,000 people displaced of whom 70% or 271,000 were staying (Nov 2013 - Jan 2014) outside of established evacuation centers. These people were in urgent need of shelter Above normal rainfall and WASH support. Psycho-social support was identified as an urgent need for children traumatized by the earthquake, which has produced well over 2,000 aftershocks so far. Recently repaired bridges and roads have opened greater access to affected locations M O N G O L I A normal in Bohol. The Government has welcomed international assistance. Source: OCHA Sitrep No. 4 DPR KOREA Below normal rainfall 2 CAMBODIA 5 Floods across Cambodia have claimed 168 lives, displaced almost 145,000 and 5 RO KOREA JAPAN r" p" u" affected more than 1.7 million. Waters have begun to recede across the country with the worst affected provinces being Battambang and Banteay Meanchey, where many parts C H I N A LEKIMA KOBE remain flooded. Communities are in urgent need of clean water, basic sanitation and BHUTAN emergency shelter. NEPAL p" 5 Source: HRF Sitrep No. 4 KATHMANDU 3 INDIA PA C I F I C Heavy rainfall has been affecting the states of Andhra Pradesh and Odisha, SE India, in BANGLADESH FRANCISCO I N D I A u" the last few days. -

Downloaded 10/05/21 02:09 PM UTC 1426 WEATHER and FORECASTING VOLUME 29
DECEMBER 2014 W E I 1425 Surface Wind Nowcasting in the Penghu Islands Based on Classified Typhoon Tracks and the Effects of the Central Mountain Range of Taiwan CHIH-CHIANG WEI Department of Digital Content Designs and Management, Toko University, Pu-Tzu City, Chia-Yi County, Taiwan (Manuscript received 5 March 2014, in final form 21 September 2014) ABSTRACT The purposes of this study were to forecast the hourly typhoon wind velocity over the Penghu Islands, and to discuss the effects of the terrain of the Central Mountain Range (CMR) of Taiwan over the Penghu Islands based on typhoon tracks. On average, a destructive typhoon hits the Penghu Islands every 15–20 yr. As a typhoon approaches the Penghu Islands, its track and intensity are influenced by the CMR topography. Therefore, CMR complicates the wind forecast of the Penghu Islands. Six main typhoon tracks (classes I–VI) are classified based on typhoon directions, as follows: (I) the direction of direct westward movement across the CMR of Taiwan, (II) the direction of northward movement along the eastern coast of Taiwan, (III) the direction of northward movement traveling through Taiwan Strait, (IV) the direction of westward movement traveling through Luzon Strait, (V) the direction of westward movement traveling through the southern East China Sea (near northern Taiwan), and (VI) the irregular track direction. The adaptive network-based fuzzy inference system (ANFIS) and multilayer perceptron neural network (MLPNN) were used as the forecasting technique for predicting the wind velocity. A total of 49 typhoons from 2000 to 2012 were analyzed. Results showed that the ANFIS models provided high-reliability predictions for wind velocity, and the ANFIS achieved more favorable performance than did the MLPNN. -

Resilience of Human Mobility Under the Influence of Typhoons
Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 118 ( 2015 ) 942 – 949 International Conference on Sustainable Design, Engineering and Construction Resilience of human mobility under the influence of typhoons Qi Wanga, John E. Taylor b,* a Charles E. Via, Jr. Department of Civil and Environmental Engineering, 121 Patton Hall, Blacksburg, VA 24060, U.S.A b Charles E. Via, Jr. Department of Civil and Environmental Engineering, 113 Patton Hall, Blacksburg, VA 24060, U.S.A Abstract Climate change has intensified tropical cyclones, resulting in several recent catastrophic hurricanes and typhoons. Such disasters impose threats on populous coastal urban areas, and therefore, understanding and predicting human movements plays a critical role in evaluating vulnerability and resilience of human society and developing plans for disaster evacuation, response and relief. Despite its critical role, limited research has focused on tropical cyclones and their influence on human mobility. Here, we studied how severe tropical storms could influence human mobility patterns in coastal urban populations using individuals’ movement data collected from Twitter. We selected 5 significant tropical storms and examined their influences on 8 urban areas. We analyzed the human movement data before, during, and after each event, comparing the perturbed movement data to movement data from steady states. We also used different statistical analysis approaches to quantify the strength and duration of human mobility perturbation. The results suggest that tropical cyclones can significantly perturb human movements, and human mobility experienced different magnitudes in different cases. We also found that power-law still governed human movements in spite of the perturbations. The findings from this study will deepen our understanding about the interaction between urban dwellers and civil infrastructure, improve our ability to predict human movements during natural disasters, and help policymakers to improve disaster evacuation, response and relief plans. -

Natural Catastrophes and Man-Made Disasters in 2013
No 1/2014 Natural catastrophes and 01 Executive summary 02 Catastrophes in 2013 – man-made disasters in 2013: global overview large losses from floods and 07 Regional overview 15 Fostering climate hail; Haiyan hits the Philippines change resilience 25 Tables for reporting year 2013 45 Terms and selection criteria Executive summary Almost 26 000 people died in disasters In 2013, there were 308 disaster events, of which 150 were natural catastrophes in 2013. and 158 man-made. Almost 26 000 people lost their lives or went missing in the disasters. Typhoon Haiyan was the biggest Typhoon Haiyan struck the Philippines in November 2013, one of the strongest humanitarian catastrophe of the year. typhoons ever recorded worldwide. It killed around 7 500 people and left more than 4 million homeless. Haiyan was the largest humanitarian catastrophe of 2013. Next most extreme in terms of human cost was the June flooding in the Himalayan state of Uttarakhand in India, in which around 6 000 died. Economic losses from catastrophes The total economic losses from natural catastrophes and man-made disasters were worldwide were USD 140 billion in around USD 140 billion last year. That was down from USD 196 billion in 2012 2013. Asia had the highest losses. and well below the inflation-adjusted 10-year average of USD 190 billion. Asia was hardest hit, with the cyclones in the Pacific generating most economic losses. Weather events in North America and Europe caused most of the remainder. Insured losses amounted to USD 45 Insured losses were roughly USD 45 billion, down from USD 81 billion in 2012 and billion, driven by flooding and other below the inflation-adjusted average of USD 61 billion for the previous 10 years, weather-related events. -

Quantifying, Comparing Human Mobility Perturbation During Hurricane Sandy, Typhoon Wipha, Typhoon Haiyan
Available online at www.sciencedirect.com ScienceDirect Procedia Economics and Finance 18 ( 2014 ) 33 – 38 4th International Conference on Building Resilience, Building Resilience 2014, 8-10 September 2014, Salford Quays, United kingdom Quantifying and Comparing Human Mobility Perturbation during Hurricane Sandy, Typhoon Wipha and Typhoon Haiyan Qi Wanga, John E. Taylora,* a Charles E. Via, Jr. Department of Civil and Environmental Engineering, 120 Patton Hall, Blacksburg, VA 24060, U.S.A Abstract Climate change has intensified tropical cyclones, resulting in several recent catastrophic hurricanes and typhoons. Such disasters impose threats on populous coastal urban areas, and therefore, understanding and predicting human movements plays a critical role in disaster evacuation, response and relief. Despite its critical roles, limited research has focused on tropical cyclones and their influence on human mobility. Here, we studied how severe tropical storms could influence human mobility patterns in coastal urban populations using individuals’ movement data collected from Twitter. We selected three significant tropical storms, including Hurricane Sandy, Typhoon Wipha, and Typhoon Haiyan. We analyzed the human movement data before, during, and after each event, comparing the perturbed movement data to movement data from steady states. We also used different statistical analysis approaches to quantify the strength and duration of human mobility perturbation. The results suggest that tropical cyclones can significantly perturb human movements by changing travel frequencies and displacement probability distributions; however, the nature-derived Lévy Walk model still predominantly governs human mobility. Also, human mobility exhibits a surprisingly mild and brief perturbation for Hurricane Sandy and Typhoon Wipha, while the duration of disturbance was much longer for Typhoon Haiyan. -

Global 7-Km Mesh Nonhydrostatic Model Intercomparison
Geosci. Model Dev. Discuss., doi:10.5194/gmd-2016-184, 2016 Manuscript under review for journal Geosci. Model Dev. Published: 2 August 2016 c Author(s) 2016. CC-BY 3.0 License. Global 7-km mesh nonhydrostatic Model Intercomparison Project for improving TYphoon forecast (TYMIP-G7): Experimental design and preliminary results Masuo Nakano1, Akiyoshi Wada2, Masahiro Sawada2, Hiromasa Yoshimura2, Ryo Onishi1, Shintaro 5 Kawahara1, Wataru Sasaki1, Tomoe Nasuno1, Munehiko Yamaguchi2, Takeshi Iriguchi2, Masato Sugi2, and Yoshiaki Takeuchi2 1Japan Agency for Marine-Earth Science and Technology, 3173-25 Showa-machi, Kanazawa-ku, Yokohama, Kanagawa 236-0001, Japan 2Meteorological Research Institute, Japan Meteorological Agency, 1-1 Nagamine, Tsukuba, Ibaraki 305-0052, Japan 10 Correspondence to: Masuo Nakano ([email protected]) Abstract. Recent advances in high-performance computers facilitate operational numerical weather prediction by global hydrostatic atmospheric models with horizontal resolution ~10 km. Given further advances in such computers and the fact that the hydrostatic balance approximation becomes invalid for spatial scales < 10 km, development of global nonhydrostatic models with high accuracy is urgently needed. 15 The Global 7-km mesh nonhydrostatic Model Intercomparison Project for improving TYphoon forecast (TYMIP-G7) is designed to understand and statistically quantify the advantage of high-resolution nonhydrostatic global atmospheric models for improvement of tropical cyclone (TC) prediction. The 137 sets of 5-day simulations using three next-generation nonhydrostatic global models with horizontal resolution 7 km, and conventional hydrostatic global model with horizontal resolution 20 km are run on the Earth Simulator. The three 7-km mesh nonhydrostatic models are the nonhydrostatic global 20 spectral atmospheric Model using Double Fourier Series (DFSM), Multi-Scale Simulator for the Geoenvironment (MSSG), and Nonhydrostatic ICosahedral Atmospheric Model (NICAM). -

7.2 AWG Membersreportssummary 2019.Pdf
ESCAP/WMO Typhoon Committee FOR PARTICIPANTS ONLY 2nd Video Conference INF/TC.52/3.2 Fifty-Second Session 05 June 2020 10 June 2020 ENGLISH ONLY Guangzhou, China SUMMARY OF MEMBERS’ REPORTS 2019 (submitted by AWG Chair) Summary and Purpose of Document: This document presents an overall view of the progress and issues in meteorology, hydrology and DRR aspects among TC Members with respect to tropical cyclones and related hazards in 2019 Action Proposed The Committee is invited to: (a) take note of the major progress and issues in meteorology, hydrology and DRR activities in support of the 21 Priorities detailed in the Typhoon Committee Strategic Plan 2017-2021; and (b) Review the Summary of Members’ Reports 2019 in APPENDIX B with the aim of adopting a “Executive Summary” for distribution to Members’ governments and other collaborating or potential sponsoring agencies for information and reference. APPENDICES: 1) Appendix A – DRAFT TEXT FOR INCLUSION IN THE SESSION REPORT 2) Appendix B – SUMMARY OF MEMBERS’ REPORTS 2019 APPENDIX A: DRAFT TEXT FOR INCLUSION IN THE SESSION REPORT 3.2 SUMMARY OF MEMBERS’ REPORTS 1. The Committee took note of the Summary of Members’ Reports 2019 highlighting the key tropical cyclone impacts on Members in 2019 and the major activities undertaken by Members under the TC Priorities and components during the year. 2. The Committee expressed its sincere appreciation to AWG Chair for preparing the Summary of Members’ Reports and the observations made with respect to the progress of Members’ activities in support of the 21 Priorities identified in the TC Strategic Plan 2017-2021. -

MWL Aug 2014 Draft 1A BOX
MarinersMariners WEATHER LOGWEATHER LOG Volume 58, Number 2 August 2014 From the Editor Greetings! Welcome to another edition of the Mariners Weather Log. We are smack dab in the middle of hurricane season and our first named storm of the season, Arthur, occurred on July 1st. Tropical Storm Arthur reached hurricane strength on July 3rd off the coast of Mariners Weather Log South Carolina making for a very soggy 4th of July Independence ISSN 0025-3367 Day celebration. Hurricane Arthur has become the first hurricane to make landfall in the continental U.S. since hurricane Isaac struck U.S. Department of Commerce Louisiana on August 28/29th in 2012. With this, I want to remind you Dr. Kathryn D. Sullivan that your marine weather observations really do matter. The data we Under Secretary of Commerce for Oceans and Atmosphere & Acting NOAA Administrator receive from you gets ingested directly into the models, thus you give Acting Administrator the National Weather Service a much better confidence in forecasts National Weather Service and analysis…thank you in advance and we count on your participa- Dr. Louis Uccellini tion. For a full complement of hurricane information you can always NOAA Assistant Administrator for Weather Services go to the National Hurricane Center. For a full explanation on how Editorial Supervisor the Climate Prediction Center in collaboration with the hurricane Paula M. Rychtar experts from the National Hurricane Center and the Hurricane Research Division produce their seasonal outlook you can go to: Layout and Design Stuart Hayes http://www.cpc.ncep.noaa.gov/products/outlooks/hurricane.shtml. -

MEMBER REPORT Japan
MEMBER REPORT ESCAP/WMO Typhoon Committee 8th Integrated Workshop/2nd TRCG Forum Japan Macao, China 2 ‐ 6 December 2013 CONTENTS I. Overview of tropical cyclones which have affected/impacted Member’s area since the last Typhoon Committee Session II. Summary of progress in Key Result Areas 2 I. Overview of tropical cyclones which have affected/impacted Member’s area in 2013 (Free format) 1. Meteorological Assessment (highlighting forecasting issues/impacts) In 2013, 14 tropical cyclones (TCs) of tropical storm (TS) intensity or higher had come within 300 km of the Japanese islands as of the end of October. Japan was affected by 13 of these, with 2 making landfall. These 13 TCs are described below, and their tracks are shown in Figure 1. (1) TS Leepi (1304) Leepi was upgraded to TS intensity east of the Philippines at 00 UTC on 18 June. Moving northward, it reached its peak intensity with maximum sustained winds of 40 kt and a central pressure of 994 hPa 18 hours later. Leepi passed near Miyakojima Island the next day and transformed into an extratropical cyclone over the East China Sea at 00 UTC on 21 June, and a 24‐hour precipitation total of 222.0 mm was recorded at Ishigakijima (47918). Damage to houses and cancellations of flights and ship departures were reported in Okinawa Prefecture. (2) TY Soulik (1307) Soulik was upgraded to TS intensity around the Mariana Islands at 00 UTC on 8 July, and was further upgraded to TY intensity west of the islands at 00 UTC the next day. Turning west‐northwestward, it developed rapidly and reached its peak intensity with maximum sustained winds of 100 kt and a central pressure of 925 hPa north of Okinotorishima Island at 00 UTC on 10 July.