Benchmarking JPEG XL Image Compression
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Exploring the .BMP File Format
Exploring the .BMP File Format Don Lancaster Synergetics, Box 809, Thatcher, AZ 85552 copyright c2003 as GuruGram #14 http://www.tinaja.com [email protected] (928) 428-4073 The .BMP image standard is used by Windows and elsewhere to represent graphics images in any of several different display and compression options. The .BMP advantages are that each pixel is usually independently available for any alteration or modification. And that repeated use does not normally degrade the image. Because lossy compression is not used. Its main disadvantage is that file sizes are usually horrendous compared to JPEG, fractal, GIF, or other lossy compression schemes. A comparison of popular image standards can be found here. I’ve long been using the .BMP format for my eBay and my other phototography, scanning, and post processing. I firmly believe that… All photography, scanning, and all image post-processing should always be done using .BMP or a similar non-lossy format. Only after all post-processing is complete should JPEG or another compressed distribution format be chosen. Some current examples of my .BMP work now do include the IMAGIMAG.PDF post-processing tutorial, the Bitmap Typewriterthat generates fully anti-aliased small fonts, the Aerial Photo Combiner, and similar utilities and tutorials found on our Fonts & Images, PostScript, and on our Acrobat library pages. A few projects of current interest involving .BMP files include true view camera swings and tilts for a digital camera, distortion correction, dodging & burning, preventing white punchthrough on knockouts, and emphasis vignetting. Mainly applied to uncompressed RGBX 24-bit color .BMP files. -

Data Compression: Dictionary-Based Coding 2 / 37 Dictionary-Based Coding Dictionary-Based Coding
Dictionary-based Coding already coded not yet coded search buffer look-ahead buffer cursor (N symbols) (L symbols) We know the past but cannot control it. We control the future but... Last Lecture Last Lecture: Predictive Lossless Coding Predictive Lossless Coding Simple and effective way to exploit dependencies between neighboring symbols / samples Optimal predictor: Conditional mean (requires storage of large tables) Affine and Linear Prediction Simple structure, low-complex implementation possible Optimal prediction parameters are given by solution of Yule-Walker equations Works very well for real signals (e.g., audio, images, ...) Efficient Lossless Coding for Real-World Signals Affine/linear prediction (often: block-adaptive choice of prediction parameters) Entropy coding of prediction errors (e.g., arithmetic coding) Using marginal pmf often already yields good results Can be improved by using conditional pmfs (with simple conditions) Heiko Schwarz (Freie Universität Berlin) — Data Compression: Dictionary-based Coding 2 / 37 Dictionary-based Coding Dictionary-Based Coding Coding of Text Files Very high amount of dependencies Affine prediction does not work (requires linear dependencies) Higher-order conditional coding should work well, but is way to complex (memory) Alternative: Do not code single characters, but words or phrases Example: English Texts Oxford English Dictionary lists less than 230 000 words (including obsolete words) On average, a word contains about 6 characters Average codeword length per character would be limited by 1 -

An Effective Self-Adaptive Policy for Optimal Video Quality Over Heterogeneous Mobile Devices and Network Discovery Services
Appl. Math. Inf. Sci. 13, No. 3, 489-505 (2019) 489 Applied Mathematics & Information Sciences An International Journal http://dx.doi.org/10.18576/amis/130322 An Effective Self-Adaptive Policy for Optimal Video Quality over Heterogeneous Mobile Devices and Network Discovery Services Saleh Ali Alomari∗1 , Mowafaq Salem Alzboon1, Belal Zaqaibeh1 and Mohammad Subhi Al-Batah1 1Faculty of Science and Information Technology, Jadara University, 21110 Irbid, Jordan Received: 12 Dec. 2018, Revised: 1 Feb. 2019, Accepted: 20 Feb. 2019 Published online: 1 May 2019 Abstract: The Video on Demand (VOD) system is considered a communicating multimedia system that can allow clients be interested whilst watching a video of their selection anywhere and anytime upon their convenient. The design of the VOD system is based on the process and location of its three basic contents, which are: the server, network configuration and clients. The clients are varied from numerous approaches, battery capacities, involving screen resolutions, capabilities and decoder features (frame rates, spatial dimensions and coding standards). The up-to-date systems deliver VOD services through to several devices by utilising the content of a single coded video without taking into account various features and platforms of a device, such as WMV9, 3GPP2 codec, H.264, FLV, MPEG-1 and XVID. This limitation only provides existing services to particular devices that are only able to play with a few certain videos. Multiple video codecs are stored by VOD systems store for a similar video into the storage server. The problems caused by the bandwidth overhead arise once the layers of a video are produced. -

Free Lossless Image Format
FREE LOSSLESS IMAGE FORMAT Jon Sneyers and Pieter Wuille [email protected] [email protected] Cloudinary Blockstream ICIP 2016, September 26th DON’T WE HAVE ENOUGH IMAGE FORMATS ALREADY? • JPEG, PNG, GIF, WebP, JPEG 2000, JPEG XR, JPEG-LS, JBIG(2), APNG, MNG, BPG, TIFF, BMP, TGA, PCX, PBM/PGM/PPM, PAM, … • Obligatory XKCD comic: YES, BUT… • There are many kinds of images: photographs, medical images, diagrams, plots, maps, line art, paintings, comics, logos, game graphics, textures, rendered scenes, scanned documents, screenshots, … EVERYTHING SUCKS AT SOMETHING • None of the existing formats works well on all kinds of images. • JPEG / JP2 / JXR is great for photographs, but… • PNG / GIF is great for line art, but… • WebP: basically two totally different formats • Lossy WebP: somewhat better than (moz)JPEG • Lossless WebP: somewhat better than PNG • They are both .webp, but you still have to pick the format GOAL: ONE FORMAT THAT COMPRESSES ALL IMAGES WELL EXPERIMENTAL RESULTS Corpus Lossless formats JPEG* (bit depth) FLIF FLIF* WebP BPG PNG PNG* JP2* JXR JLS 100% 90% interlaced PNGs, we used OptiPNG [21]. For BPG we used [4] 8 1.002 1.000 1.234 1.318 1.480 2.108 1.253 1.676 1.242 1.054 0.302 the options -m 9 -e jctvc; for WebP we used -m 6 -q [4] 16 1.017 1.000 / / 1.414 1.502 1.012 2.011 1.111 / / 100. For the other formats we used default lossless options. [5] 8 1.032 1.000 1.099 1.163 1.429 1.664 1.097 1.248 1.500 1.017 0.302� [6] 8 1.003 1.000 1.040 1.081 1.282 1.441 1.074 1.168 1.225 0.980 0.263 Figure 4 shows the results; see [22] for more details. -
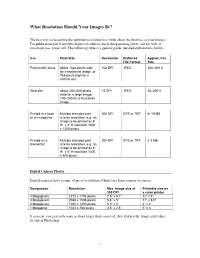
What Resolution Should Your Images Be?
What Resolution Should Your Images Be? The best way to determine the optimum resolution is to think about the final use of your images. For publication you’ll need the highest resolution, for desktop printing lower, and for web or classroom use, lower still. The following table is a general guide; detailed explanations follow. Use Pixel Size Resolution Preferred Approx. File File Format Size Projected in class About 1024 pixels wide 102 DPI JPEG 300–600 K for a horizontal image; or 768 pixels high for a vertical one Web site About 400–600 pixels 72 DPI JPEG 20–200 K wide for a large image; 100–200 for a thumbnail image Printed in a book Multiply intended print 300 DPI EPS or TIFF 6–10 MB or art magazine size by resolution; e.g. an image to be printed as 6” W x 4” H would be 1800 x 1200 pixels. Printed on a Multiply intended print 200 DPI EPS or TIFF 2-3 MB laserwriter size by resolution; e.g. an image to be printed as 6” W x 4” H would be 1200 x 800 pixels. Digital Camera Photos Digital cameras have a range of preset resolutions which vary from camera to camera. Designation Resolution Max. Image size at Printable size on 300 DPI a color printer 4 Megapixels 2272 x 1704 pixels 7.5” x 5.7” 12” x 9” 3 Megapixels 2048 x 1536 pixels 6.8” x 5” 11” x 8.5” 2 Megapixels 1600 x 1200 pixels 5.3” x 4” 6” x 4” 1 Megapixel 1024 x 768 pixels 3.5” x 2.5” 5” x 3 If you can, you generally want to shoot larger than you need, then sharpen the image and reduce its size in Photoshop. -

How to Exploit the Transferability of Learned Image Compression to Conventional Codecs
How to Exploit the Transferability of Learned Image Compression to Conventional Codecs Jan P. Klopp Keng-Chi Liu National Taiwan University Taiwan AI Labs [email protected] [email protected] Liang-Gee Chen Shao-Yi Chien National Taiwan University [email protected] [email protected] Abstract Lossy compression optimises the objective Lossy image compression is often limited by the sim- L = R + λD (1) plicity of the chosen loss measure. Recent research sug- gests that generative adversarial networks have the ability where R and D stand for rate and distortion, respectively, to overcome this limitation and serve as a multi-modal loss, and λ controls their weight relative to each other. In prac- especially for textures. Together with learned image com- tice, computational efficiency is another constraint as at pression, these two techniques can be used to great effect least the decoder needs to process high resolutions in real- when relaxing the commonly employed tight measures of time under a limited power envelope, typically necessitating distortion. However, convolutional neural network-based dedicated hardware implementations. Requirements for the algorithms have a large computational footprint. Ideally, encoder are more relaxed, often allowing even offline en- an existing conventional codec should stay in place, ensur- coding without demanding real-time capability. ing faster adoption and adherence to a balanced computa- Recent research has developed along two lines: evolu- tional envelope. tion of exiting coding technologies, such as H264 [41] or As a possible avenue to this goal, we propose and investi- H265 [35], culminating in the most recent AV1 codec, on gate how learned image coding can be used as a surrogate the one hand. -

Download Media Player Codec Pack Version 4.1 Media Player Codec Pack
download media player codec pack version 4.1 Media Player Codec Pack. Description: In Microsoft Windows 10 it is not possible to set all file associations using an installer. Microsoft chose to block changes of file associations with the introduction of their Zune players. Third party codecs are also blocked in some instances, preventing some files from playing in the Zune players. A simple workaround for this problem is to switch playback of video and music files to Windows Media Player manually. In start menu click on the "Settings". In the "Windows Settings" window click on "System". On the "System" pane click on "Default apps". On the "Choose default applications" pane click on "Films & TV" under "Video Player". On the "Choose an application" pop up menu click on "Windows Media Player" to set Windows Media Player as the default player for video files. Footnote: The same method can be used to apply file associations for music, by simply clicking on "Groove Music" under "Media Player" instead of changing Video Player in step 4. Media Player Codec Pack Plus. Codec's Explained: A codec is a piece of software on either a device or computer capable of encoding and/or decoding video and/or audio data from files, streams and broadcasts. The word Codec is a portmanteau of ' co mpressor- dec ompressor' Compression types that you will be able to play include: x264 | x265 | h.265 | HEVC | 10bit x265 | 10bit x264 | AVCHD | AVC DivX | XviD | MP4 | MPEG4 | MPEG2 and many more. File types you will be able to play include: .bdmv | .evo | .hevc | .mkv | .avi | .flv | .webm | .mp4 | .m4v | .m4a | .ts | .ogm .ac3 | .dts | .alac | .flac | .ape | .aac | .ogg | .ofr | .mpc | .3gp and many more. -

Video Codec Requirements and Evaluation Methodology
Video Codec Requirements 47pt 30pt and Evaluation Methodology Color::white : LT Medium Font to be used by customers and : Arial www.huawei.com draft-filippov-netvc-requirements-01 Alexey Filippov, Huawei Technologies 35pt Contents Font to be used by customers and partners : • An overview of applications • Requirements 18pt • Evaluation methodology Font to be used by customers • Conclusions and partners : Slide 2 Page 2 35pt Applications Font to be used by customers and partners : • Internet Protocol Television (IPTV) • Video conferencing 18pt • Video sharing Font to be used by customers • Screencasting and partners : • Game streaming • Video monitoring / surveillance Slide 3 35pt Internet Protocol Television (IPTV) Font to be used by customers and partners : • Basic requirements: . Random access to pictures 18pt Random Access Period (RAP) should be kept small enough (approximately, 1-15 seconds); Font to be used by customers . Temporal (frame-rate) scalability; and partners : . Error robustness • Optional requirements: . resolution and quality (SNR) scalability Slide 4 35pt Internet Protocol Television (IPTV) Font to be used by customers and partners : Resolution Frame-rate, fps Picture access mode 2160p (4K),3840x2160 60 RA 18pt 1080p, 1920x1080 24, 50, 60 RA 1080i, 1920x1080 30 (60 fields per second) RA Font to be used by customers and partners : 720p, 1280x720 50, 60 RA 576p (EDTV), 720x576 25, 50 RA 576i (SDTV), 720x576 25, 30 RA 480p (EDTV), 720x480 50, 60 RA 480i (SDTV), 720x480 25, 30 RA Slide 5 35pt Video conferencing Font to be used by customers and partners : • Basic requirements: . Delay should be kept as low as possible 18pt The preferable and maximum delay values should be less than 100 ms and 350 ms, respectively Font to be used by customers . -

Panstamps Documentation Release V0.5.3
panstamps Documentation Release v0.5.3 Dave Young 2020 Getting Started 1 Installation 3 1.1 Troubleshooting on Mac OSX......................................3 1.2 Development...............................................3 1.2.1 Sublime Snippets........................................4 1.3 Issues...................................................4 2 Command-Line Usage 5 3 Documentation 7 4 Command-Line Tutorial 9 4.1 Command-Line..............................................9 4.1.1 JPEGS.............................................. 12 4.1.2 Temporal Constraints (Useful for Moving Objects)...................... 17 4.2 Importing to Your Own Python Script.................................. 18 5 Installation 19 5.1 Troubleshooting on Mac OSX...................................... 19 5.2 Development............................................... 19 5.2.1 Sublime Snippets........................................ 20 5.3 Issues................................................... 20 6 Command-Line Usage 21 7 Documentation 23 8 Command-Line Tutorial 25 8.1 Command-Line.............................................. 25 8.1.1 JPEGS.............................................. 28 8.1.2 Temporal Constraints (Useful for Moving Objects)...................... 33 8.2 Importing to Your Own Python Script.................................. 34 8.2.1 Subpackages.......................................... 35 8.2.1.1 panstamps.commonutils (subpackage)........................ 35 8.2.1.2 panstamps.image (subpackage)............................ 35 8.2.2 Classes............................................ -

Discrete Cosine Transform for 8X8 Blocks with CUDA
Discrete Cosine Transform for 8x8 Blocks with CUDA Anton Obukhov [email protected] Alexander Kharlamov [email protected] October 2008 Document Change History Version Date Responsible Reason for Change 0.8 24.03.2008 Alexander Kharlamov Initial release 0.9 25.03.2008 Anton Obukhov Added algorithm-specific parts, fixed some issues 1.0 17.10.2008 Anton Obukhov Revised document structure October 2008 2 Abstract In this whitepaper the Discrete Cosine Transform (DCT) is discussed. The two-dimensional variation of the transform that operates on 8x8 blocks (DCT8x8) is widely used in image and video coding because it exhibits high signal decorrelation rates and can be easily implemented on the majority of contemporary computing architectures. The key feature of the DCT8x8 is that any pair of 8x8 blocks can be processed independently. This makes possible fully parallel implementation of DCT8x8 by definition. Most of CPU-based implementations of DCT8x8 are firmly adjusted for operating using fixed point arithmetic but still appear to be rather costly as soon as blocks are processed in the sequential order by the single ALU. Performing DCT8x8 computation on GPU using NVIDIA CUDA technology gives significant performance boost even compared to a modern CPU. The proposed approach is accompanied with the sample code “DCT8x8” in the NVIDIA CUDA SDK. October 2008 3 1. Introduction The Discrete Cosine Transform (DCT) is a Fourier-like transform, which was first proposed by Ahmed et al . (1974). While the Fourier Transform represents a signal as the mixture of sines and cosines, the Cosine Transform performs only the cosine-series expansion. -

Chapter 9 Image Compression Standards
Fundamentals of Multimedia, Chapter 9 Chapter 9 Image Compression Standards 9.1 The JPEG Standard 9.2 The JPEG2000 Standard 9.3 The JPEG-LS Standard 9.4 Bi-level Image Compression Standards 9.5 Further Exploration 1 Li & Drew c Prentice Hall 2003 ! Fundamentals of Multimedia, Chapter 9 9.1 The JPEG Standard JPEG is an image compression standard that was developed • by the “Joint Photographic Experts Group”. JPEG was for- mally accepted as an international standard in 1992. JPEG is a lossy image compression method. It employs a • transform coding method using the DCT (Discrete Cosine Transform). An image is a function of i and j (or conventionally x and y) • in the spatial domain. The 2D DCT is used as one step in JPEG in order to yield a frequency response which is a function F (u, v) in the spatial frequency domain, indexed by two integers u and v. 2 Li & Drew c Prentice Hall 2003 ! Fundamentals of Multimedia, Chapter 9 Observations for JPEG Image Compression The effectiveness of the DCT transform coding method in • JPEG relies on 3 major observations: Observation 1: Useful image contents change relatively slowly across the image, i.e., it is unusual for intensity values to vary widely several times in a small area, for example, within an 8 8 × image block. much of the information in an image is repeated, hence “spa- • tial redundancy”. 3 Li & Drew c Prentice Hall 2003 ! Fundamentals of Multimedia, Chapter 9 Observations for JPEG Image Compression (cont’d) Observation 2: Psychophysical experiments suggest that hu- mans are much less likely to notice the loss of very high spatial frequency components than the loss of lower frequency compo- nents. -

Lossy Image Compression Based on Prediction Error and Vector Quantisation Mohamed Uvaze Ahamed Ayoobkhan* , Eswaran Chikkannan and Kannan Ramakrishnan
Ayoobkhan et al. EURASIP Journal on Image and Video Processing (2017) 2017:35 EURASIP Journal on Image DOI 10.1186/s13640-017-0184-3 and Video Processing RESEARCH Open Access Lossy image compression based on prediction error and vector quantisation Mohamed Uvaze Ahamed Ayoobkhan* , Eswaran Chikkannan and Kannan Ramakrishnan Abstract Lossy image compression has been gaining importance in recent years due to the enormous increase in the volume of image data employed for Internet and other applications. In a lossy compression, it is essential to ensure that the compression process does not affect the quality of the image adversely. The performance of a lossy compression algorithm is evaluated based on two conflicting parameters, namely, compression ratio and image quality which is usually measured by PSNR values. In this paper, a new lossy compression method denoted as PE-VQ method is proposed which employs prediction error and vector quantization (VQ) concepts. An optimum codebook is generated by using a combination of two algorithms, namely, artificial bee colony and genetic algorithms. The performance of the proposed PE-VQ method is evaluated in terms of compression ratio (CR) and PSNR values using three different types of databases, namely, CLEF med 2009, Corel 1 k and standard images (Lena, Barbara etc.). Experiments are conducted for different codebook sizes and for different CR values. The results show that for a given CR, the proposed PE-VQ technique yields higher PSNR value compared to the existing algorithms. It is also shown that higher PSNR values can be obtained by applying VQ on prediction errors rather than on the original image pixels.