Lean Six Sigma Using Sigmaxl and Minitab ABOUT the AUTHORS
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Primena Statistike U Kliničkim Istraţivanjima Sa Osvrtom Na Korišćenje Računarskih Programa
UNIVERZITET U BEOGRADU MATEMATIČKI FAKULTET Dušica V. Gavrilović Primena statistike u kliničkim istraţivanjima sa osvrtom na korišćenje računarskih programa - Master rad - Mentor: prof. dr Vesna Jevremović Beograd, 2013. godine Zahvalnica Ovaj rad bi bilo veoma teško napisati da nisam imala stručnu podršku, kvalitetne sugestije i reviziju, pomoć prijatelja, razumevanje kolega i beskrajnu podršku porodice. To su razlozi zbog kojih želim da se zahvalim: . Mom mentoru, prof. dr Vesni Jevremović sa Matematičkog fakulteta Univerziteta u Beogradu, koja je bila ne samo idejni tvorac ovog rada već i dugogodišnja podrška u njegovoj realizaciji. Njena neverovatna upornost, razne sugestije, neiscrpni optimizam, profesionalizam i razumevanje, predstavljali su moj stalni izvor snage na ovom master-putu. Članu komisije, doc. dr Zorici Stanimirović sa Matematičkog fakulteta Univerziteta u Beogradu, na izuzetnoj ekspeditivnosti, stručnoj recenziji, razumevanju, strpljenju i brojnim korisnim savetima. Članu komisije, mr Marku Obradoviću sa Matematičkog fakulteta Univerziteta u Beogradu, na stručnoj i prijateljskoj podršci kao i spremnosti na saradnju. Dipl. mat. Radojki Pavlović, šefu studentske službe Matematičkog fakulteta Univerziteta u Beogradu, na upornosti, snalažljivosti i kreativnosti u pronalaženju raznih ideja, predloga i rešenja na putu realizacije ovog master rada. Dugogodišnje prijateljstvo sa njom oduvek beskrajno cenim i oduvek mi mnogo znači. Dipl. mat. Zorani Bizetić, načelniku Data Centra Instituta za onkologiju i radiologiju Srbije, na upornosti, idejama, detaljnoj reviziji, korisnim sugestijama i svakojakoj podršci. Čak i kada je neverovatno ili dosadno ili pametno uporna, mnogo je i dugo volim – skoro ceo moj život. Mast. biol. Jelici Novaković na strpljenju, reviziji, bezbrojnim korekcijama i tehničkoj podršci svake vrste. Hvala na osmehu, budnom oku u sitne sate, izvrsnoj hrani koja me je vraćala u život, nes-kafi sa penom i transfuziji energije kada sam bila na rezervi. -

Dell VITA RFP- Revised COTS Pricing 12-17-08
COTS Software COTS Software is considered to be commercially available software read to run without customization, Gov't Pricing Academic Pricing Gov't Pricing Enter discount for publisher (This Enter discount for publisher (This will be the will be the lowest discount that you lowest discount that you will offer during the will offer during the term of the term of the contract) contract) COTS Discount % COTS Discount % Title Price Adobe 0.00% Adobe 0.00% Adobe Acrobat Professional Version 9 Windows 218.33 Autodesk 0.00% Autodesk 0.00% Adobe Photoshop CS4 Windows 635.24 Citrix 0.00% Citrix 0.00% Autodesk Sketchbook 2009 Pro 120 Corel 0.00% Corel 0.00% McAfee Active Virus Defense 14.87 DoubleTake 0.00% DoubleTake 0.00% Symantec Norton Antivirus 2009 25 Intuit 0.00% Intuit 0.00% Symantec Backup Exec 12.5 for Windows Servers 454.25 McAfee 0.00% McAfee 0.00% PRICE FOR ABOVE TITLES SHOULD BE Novell 0.00% Novell 0.00% QUOTED FOR PURCHASE OF ONE (1) COPY Nuance 0.00% Nuance 0.00% Quark Software 0.00% Quark Software 0.00% Quest Software 0.00% Quest Software 0.00% Riverdeep 0.00% Riverdeep 0.00% Academic Pricing Symantec 0.00% Symantec 0.00% Title Price Trend Micro 0.00% Trend Micro 0.00% Adobe Acrobat Professional Version 9 Windows 131.03 VMWare 0.00% VMWare 0.00% Adobe Photoshop CS4 Windows 276.43 WebSense 0.00% WebSense 0.00% Autodesk Sketchbook 2009 Pro 120 McAfee Active Virus Defense 14.87 Symantec Norton Antivirus 2009 25 Symantec Backup Exec 12.5 for Windows Servers 454.25 PRICE FOR ABOVE TITLES SHOULD BE QUOTED FOR PURCHASE OF ONE (1) COPY LICENSE AND MEDIA For purposes of evaluation VITA will create a market basket. -

Discoversim™ Version 2 Workbook
DiscoverSim™ Version 2 Workbook Contact Information: Technical Support: 1-866-475-2124 (Toll Free in North America) or 1-416-236-5877 Sales: 1-888-SigmaXL (888-744-6295) E-mail: [email protected] Web: www.SigmaXL.com Published: December 2015 Copyright © 2011 - 2015, SigmaXL, Inc. Table of Contents DiscoverSim™ Feature List Summary, Installation Notes, System Requirements and Getting Help ..................................................................................................................................1 DiscoverSim™ Version 2 Feature List Summary ...................................................................... 3 Key Features (bold denotes new in Version 2): ................................................................. 3 Common Continuous Distributions: .................................................................................. 4 Advanced Continuous Distributions: ................................................................................. 4 Discrete Distributions: ....................................................................................................... 5 Stochastic Information Packet (SIP): .................................................................................. 5 What’s New in Version 2 .................................................................................................... 6 Installation Notes ............................................................................................................... 8 DiscoverSim™ System Requirements .............................................................................. -

Essential Statistics for Applied Linguistics : Using R Or Jasp
ESSENTIAL STATISTICS FOR APPLIED LINGUISTICS : USING R OR JASP Author: Hanneke Loerts Number of Pages: 250 pages Published Date: 06 Feb 2020 Publisher: MacMillan Education UK Publication Country: London, United Kingdom Language: English ISBN: 9781352007817 DOWNLOAD: ESSENTIAL STATISTICS FOR APPLIED LINGUISTICS : USING R OR JASP Essential Statistics for Applied Linguistics : Using R or JASP PDF Book The newspaper headlines tell us that Britain's wildlife is in trouble. Every chapter opens up with a vignette called a "Decision Dilemma" about real companies, data, and business issues.Ch. This book will be an invaluable source of information for a variety of professionals working with patients with advanced disease, including palliative care doctors and specialist nurses, as there is a scarcity of consultants in pain management in the field of palliative care. Although the units are diverse and have a range of poetry and prose for teachers to use, the book presents cohesive methods for engaging children with a variety of different literary texts and improving standards of literacy. StateResponsibility. With these questions providing the building blocks for your essay, Sawyer guides you through the rest of the process, from choosing a structure to revising your essay, and answers the big questions that have probably been keeping you up at night: How do I brag in a way that doesn't sound like bragging. Important topics such as vascular lesions, warts, acne, scars, and pigmented lesions are presented and discussed in all aspects. His discovery, which he described to his king in the presence of Christopher Columbus, opened up the sea route around Africa to India and the rest of Asia. -

Certification Training Materials PRIMERS
QUALITY PROGRESS QUALITY Putting Best Practices to Work www.qualityprogress.com | June 2014 | JUNE 2014 Supply Chains Speed Up p. 22 QUALITYP PROGRESS Chain of SUPPLY CHAIN SUPPLY Command Quality tools linked to supply chain efficiency, reduced waste p. 14 Plus: VOLUME 47/NUMBER 6 Process factors: A cornerstone of supplier audits p. 28 A fail-safe FMEA p. 42 The Global Voice of QualityTM Certification Training Materials PRIMERS Our Primers are the most widely used texts for certification training. They can be taken into the exam. QCI offers 16 different Primers. SOLUTION TEXTS Detailed solutions to all questions in the corresponding Primer. CD-ROMS Interactive software to assist students preparing for ASQ exams. QUALITY COUNCIL OF INDIANA Online Orders: www.qualitycouncil.com Phone Orders: 800-660-4215 Fax Orders: 812-533-4216 Mail Orders: QCI Order Department, 602 W. Paris Ave., W. Terre Haute, IN 47885-1124 Check out a few of the NEW books from ASQ Quality Press! The FDA and Worldwide Current Good Manufacturing Practices and Quality System Requirements for Finished Pharmaceuticals This guidance book is meant as a resource to Continuous Permanent Improvement manufacturers of pharmaceuticals, providing The purpose of this book is not to expound any up-to-date information concerning required and new theory or tools, but to share experiences in recommended quality system practices. implementing existing methods with a bias toward Item: H1458 business results. In fact, one of the important lessons we have learned is that most existing models or methods, if adhered to in the right spirit, will give results. The Certified Pharmaceutical GMP Item: H1466 Professional Handbook The purpose of this handbook is to highlight and partially annotate what the founders of the Certified Pharmaceutical Good Manufacturing Practices Professional (CPGP) examination believed to be the main topics comprising worldwide pharmaceutical good manufacturing practices (GMPs). -

Insight Manufacturers, Publishers and Suppliers by Product Category
Manufacturers, Publishers and Suppliers by Product Category 2/15/2021 10/100 Hubs & Switch ASANTE TECHNOLOGIES CHECKPOINT SYSTEMS, INC. DYNEX PRODUCTS HAWKING TECHNOLOGY MILESTONE SYSTEMS A/S ASUS CIENA EATON HEWLETT PACKARD ENTERPRISE 1VISION SOFTWARE ATEN TECHNOLOGY CISCO PRESS EDGECORE HIKVISION DIGITAL TECHNOLOGY CO. LT 3COM ATLAS SOUND CISCO SYSTEMS EDGEWATER NETWORKS INC Hirschmann 4XEM CORP. ATLONA CITRIX EDIMAX HITACHI AB DISTRIBUTING AUDIOCODES, INC. CLEAR CUBE EKTRON HITACHI DATA SYSTEMS ABLENET INC AUDIOVOX CNET TECHNOLOGY EMTEC HOWARD MEDICAL ACCELL AUTOMAP CODE GREEN NETWORKS ENDACE USA HP ACCELLION AUTOMATION INTEGRATED LLC CODI INC ENET COMPONENTS HP INC ACTI CORPORATION AVAGOTECH TECHNOLOGIES COMMAND COMMUNICATIONS ENET SOLUTIONS INC HYPERCOM ADAPTEC AVAYA COMMUNICATION DEVICES INC. ENGENIUS IBM ADC TELECOMMUNICATIONS AVOCENT‐EMERSON COMNET ENTERASYS NETWORKS IMC NETWORKS ADDERTECHNOLOGY AXIOM MEMORY COMPREHENSIVE CABLE EQUINOX SYSTEMS IMS‐DELL ADDON NETWORKS AXIS COMMUNICATIONS COMPU‐CALL, INC ETHERWAN INFOCUS ADDON STORE AZIO CORPORATION COMPUTER EXCHANGE LTD EVGA.COM INGRAM BOOKS ADESSO B & B ELECTRONICS COMPUTERLINKS EXABLAZE INGRAM MICRO ADTRAN B&H PHOTO‐VIDEO COMTROL EXACQ TECHNOLOGIES INC INNOVATIVE ELECTRONIC DESIGNS ADVANTECH AUTOMATION CORP. BASF CONNECTGEAR EXTREME NETWORKS INOGENI ADVANTECH CO LTD BELDEN CONNECTPRO EXTRON INSIGHT AEROHIVE NETWORKS BELKIN COMPONENTS COOLGEAR F5 NETWORKS INSIGNIA ALCATEL BEMATECH CP TECHNOLOGIES FIRESCOPE INTEL ALCATEL LUCENT BENFEI CRADLEPOINT, INC. FORCE10 NETWORKS, INC INTELIX -

Download This PDF File
Control Theory and Informatics www.iiste.org ISSN 2224-5774 (print) ISSN 2225-0492 (online) Vol 2, No.1, 2012 The Trend Analysis of the Level of Fin-Metrics and E-Stat Tools for Research Data Analysis in the Digital Immigrant Age Momoh Saliu Musa Department of Marketing, Federal Polytechnic, P.M.B 13, Auchi, Nigeria. Tel: +2347032739670 e-mail: [email protected] Shaib Ismail Omade (Corresponding author) Department of Statistics, School of Information and Communication Technology, Federal Polytechnic, P.M.B 13, Auchi, Nigeria. Phone: +2347032808765 e-mail: [email protected] Abstract The current trend in the information technology age has taken over every spare of human discipline ranging from communication, business, governance, defense to education world as the survival of these sectors depend largely on the research outputs for innovation and development. This study evaluated the trend of the usage of fin-metrics and e-stat tools application among the researchers in their research outputs- digital data presentation and analysis in the various journal outlets. The data used for the study were sourced primarily from the sample of 1720 out of 3823 empirical on and off line journals from various science and social sciences fields. Statistical analysis was conducted to evaluate the consistency of use of the digital tools in the methodology of the research outputs. Model for measuring the chance of acceptance and originality of the research was established. The Cockhran test and Bartlet Statistic revealed that there were significant relationship among the research from the Polytechnic, University and other institution in Nigeria and beyond. It also showed that most researchers still appeal to manual rather than digital which hampered the input internationally and found to be peculiar among lecturers in the system that have not yet appreciate IT penetration in Learning. -

What We Have Learnt from Financial Econometrics Modeling?
Munich Personal RePEc Archive What we have learnt from financial econometrics modeling? Dhaoui, Elwardi Faculty of Economics and Management of Sfax 2013 Online at https://mpra.ub.uni-muenchen.de/63843/ MPRA Paper No. 63843, posted 25 Apr 2015 13:47 UTC What we have learnt from financial econometrics modeling ? WHAT WE HAVE LEARNT FROM FINANCIAL ECONOMETRICS MODELING? Elwardi Dhaoui Research Unit MODEVI, Faculty of Economics and Management of Sfax, University of Sfax, Tunisia. E-mail : [email protected] Abstract A central issue around which the recent growth literature has evolved is that of financial econometrics modeling. Expansions of interest in the modeling and analyzing of financial data and the problems to which they are applied should be taken in account.This article focuses on econometric models widely and frequently used in the examination of issues in financial economics and financial markets, which are scattered in the literature. It begins by laying out the intimate connections between finance and econometrics. We will offer an overview and discussion of the contemporary topics surrounding financial econometrics. Then, the paper follows the financial econometric modeling research conducted along some different approaches that consist of the most influential statistical models of financial-asset returns, namely Arch-Garch models; panel models and Markov Switching models. This is providing several information bases for analysis of financial econometrics modeling. Keywords: financial modeling, Arch-Garch models, panel models, Markov Switching models. Classification JEL : C21, C22, C23, C 50, C51, C58. 1Colloque « Finance, Comptabilité et Transparence Financière 2013» What we have learnt from financial econometrics modeling ? What we have learnt from financial econometrics modeling? 1. -

A Study on Defect Reduction in IT Based on Six Sigma Patterns Prabhu Thangavelu1, Research Scholar, HITS University, Chennai, Tamil Nadu,India Dr M
The International journal of analytical and experimental modal analysis ISSN NO:0886-9367 A Study on Defect Reduction in IT based on Six Sigma Patterns Prabhu Thangavelu1, Research Scholar, HITS University, Chennai, Tamil Nadu,India Dr M. Rajeswari2, Associate Professor, HITS University, Chennai, TamilNadu, India ABSTRACT Anything done by human is error prone. Software is not an exception to that. If software development has its buzz, a bisection of the buzz is because of the fault reduction. As long as there is software, there also will be fault reduction with its own hype. Both are interrelated. But getting a bird view of the software won’t suffice when it comes to pointing faults and defects. It is a painstaking task to get a holistic view to reach the quality’s pinnacle. According to GOST R ISO 9000-2001, quality is "the degree, to which the inherent characteristics of the product meet the requirements," which may not be interpreted in the field of software development. Each software has its own goal with reaching the perfect stage of functional, operational and technicality. If the product works as per the requirement in the superlative degree of it performing the operations confined to the requirement, then it is said to have quality. Six Sigma is a strategy used for defect reduction. It is a statistics-based, process-focused, data-driven strategy and methodology, coupled with management concepts and lean tools, that aims to improve the quality of process outputs. Six Sigma seeks to identify the causes of failures and minimize variability in key industrial processes in areas, such as healthcare, manufacturing, and service. -
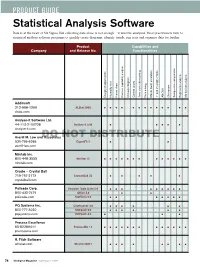
Statistical Analysis Software Data Is at the Heart of Six Sigma
PRODUCT GUIDE Statistical Analysis Software Data is at the heart of Six Sigma. But collecting data alone is not enough – it must be analyzed. Most practitioners turn to statistical analysis software programs to quickly create diagrams, identify trends, run tests and organize data for further Product Capabilities and Company and Release No. Functionalities -tests t harts awa diagram OVA ample-size computation ime series/forecasting AN Chi-square S Regression analysis Multivariate analysis Design of experiments Normality test Pareto chart Process capability analysis Ishik Control c T Data mining Monte Carlo simulation 1- and 2-sample Addinsoft 212-966-1259 XLStat 2008 •••• ••••••• •• xlstat.com Analyse-it Software Ltd. 44-113-2100708 Analyse-it 2.09 ••••• analyse-it.com DO NOT DISTRIBUTE Averill M. Law and Associates 520-795-6265 ExpertFit 7 •• averill-law.com Minitab Inc. 800-448-3555 Minitab 15 • •••••• •••••• minitab.com Oracle – Crystal Ball 719-757-2173 Crystal Ball 7.5 •• •• • crystalball.com Palisade Corp. Decision Tools Suite 5.0 ••• •••••• 800-432-7475 @Risk 5.0 •• palisade.com StatTools 5.0 •• ••••• PQ Systems Inc. Chartrunner 3.0 •••••• 800-777-3020 SQCpack 6.0 • ••• •• pqsystems.com DOEpack 4.0 ••• Process Excellence 65-82289411 ProcessMA 1.3 ••••••• •••••• processma.com R. Fitch Software winstat.com Winstat 2007.1 ••• • •• •• 74 iSixSigma Magazine July/August 2008 analysis. This directory highlights the statistical analysis features, as well as format, language and price specifics, of several programs. Some of the programs -
Insight MFR By
Manufacturers, Publishers and Suppliers by Product Category 6/16/2020 10/100 Hubs & Switch BRAINBOXES EXTRON MICRON CONSUMER PRODUCTS GROUP RARITAN MILESTONE SYSTEMS A/S BROCADE FORTINET MICROSEMI CORP RED LION CONTROLS 3COM BUFFALO TECHNOLOGY FUJITSU SCANNERS MIKROTIK RIVERBED TECHNOLOGIES 4XEM CORP. CABLE MATTERS INC. FUJITSU SERVER STORAGE MILESTONE SYSTEMS INC ROCSTOR AB DISTRIBUTING CABLE RACK GARRETTCOM MITEL ROLAND CORP ABLENET INC CABLES TO GO GEAR HEAD MONOPRICE ROSE ELECTRONIC ACCELL CALRAD ELECTRONICS GEFEN MOTOROLA ISG ROSEWILL ADESSO CHECK POINT SOFTWARE TECHNOLOGIE GEOVISION INC. MOXA TECHNOLOGIES, INC. RUCKUS WIRELESS ADTRAN CIENA HARMAN INTERNATIONAL MUXLAB SABRENT ADVANTECH AUTOMATION CORP. CISCO PRESS HAVIS SHIELD NEO4J INC SANHO ADVANTECH CO LTD CISCO SYSTEMS HEWLETT PACKARD ENTERPRISE NETAPP SANS DIGITAL AEROHIVE NETWORKS CITRIX HIKVISION DIGITAL TECHNOLOGY CO. LT NETEON TECHNOLOGIES INC. SATECHI ALCATEL LUCENT COMMUNICATION DEVICES INC. HITACHI NETGEAR, INC. SAVVIUS INC ALLEN TEL COMNET HITACHI DATA SYSTEMS NETRIA SCALE COMPUTING ALLEN‐BRADLEY COMPREHENSIVE CABLE HOWARD MEDICAL NETSCOUT SYSTEMS, INC SDA ALLIED TELESIS COMTROL HP INC NOVATEL WIRELESS SEGA OF AMERICA ALTONA CONNECTPRO HYPERCOM OMNITRON SENNHEISER ALTRONIX COOLGEAR IBM ORACLE SERVER TECH ALURATEK, INC. CP TECHNOLOGIES INNOVATIVE ELECTRONIC DESIGNS OVERLAND STORAGE SHARP AMER NETWORKS CRESTRON ELECTRONICS INSIGHT P.I. ENGINEERING SHORETEL AMX CUMULUS NETWORKS INTEL PALO ALTO NETWORKS SIGNAMAX ANKER CYBERDATA SYSTEMS INTELLINET NETWORK SOLUTIONS PANASONIC SIIG ANTAIRA TECHNOLOGIES, INC. CYBERPOWER SYSTEMS IOGEAR TECHNOLOGY PANDUIT SISOFTWARE APC DATAMATION SYSTEMS, INC. IRECORD.TV PERLE SYSTEMS SMARTAVI INC ARISTA CORPORATION DATTO, INC. IXIA PHOENIX CONTACT SMC NETWORKS ARISTA NETWORKS DELL JETWAY COMPUTER CORP. PHYBRIDGE INC SOLE SOURCE TECHNOLOGY ARRIS GROUP INC DELL EMC JUNIPER NETWORKS PICA8, INC SONUS NETWORKS, INC ASUS DIGI INTERNATIONAL KANEX PIVOT3 INC. -

Insight MFR By
Manufacturers, Publishers and Suppliers by Product Category 7/18/2019 10/100 Hubs & Switch COMPREHENSIVE CABLE IOGEAR TECHNOLOGY QUANTUM VCE COMPANY LLC 3COM COMTROL IXIA QVS INC. VERBATIM 4XEM CORP. CONNECTPRO JUNIPER NETWORKS RADWARE VERTIV ACCELL CP TECHNOLOGIES KANEX RAM MOUNTS VISIONTEK ADTRAN CRESTRON ELECTRONICS KANGURU RAPID TECHNOLOGIES LLC. VIVOTEK ADVANTECH CO LTD CYBERDATA SYSTEMS KENSINGTON RARITAN VMWARE AEROHIVE NETWORKS CYBERPOWER SYSTEMS KRAMER ELECTRONICS, LTD. RED LION CONTROLS WASP BARCODE ALCATEL LUCENT DATTO, INC. LANTRONIX RIVERBED TECHNOLOGIES WIFI‐TEXAS.COM INC ALLIED TELESIS DELL LENOVO ROSE ELECTRONIC W‐LINX TECHNOLOGY ALTRONIX DELL EMC LG ELECTRONICS ROSEWILL XIRRUS (SEE NOTES) ALURATEK, INC. DIGI INTERNATIONAL LINKSYS RUCKUS WIRELESS ZYXEL AMER NETWORKS DIGIUM MANHATTAN WIRE PRODUCTS SABRENT Adapter IDE/ATA/SATA AMX D‐LINK SYSTEMS MCAFEE SANHO ADAPTEC ANKER EATON MELLANOX SAVVIUS INC ADDONICS TECHNOLOGY INC. APC EDGECORE MICRON CONSUMER PRODUCTS GROUP SDA ALERATECH ARISTA NETWORKS EDGEWATER NETWORKS INC MICROSEMI CORP SENNHEISER ALURATEK, INC. ARRIS GROUP INC ENGENIUS MILESTONE SYSTEMS INC SHARP APRICORN ASUS ENTERASYS NETWORKS MITEL SHORETEL ARECA US ATEN TECHNOLOGY ETHERWAN MONOPRICE SIGNAMAX ATTO TECHNOLOGY ATLONA EVGA.COM MOTOROLA ISG SIIG AVAGOTECH TECHNOLOGIES AUDIOCODES, INC. EXABLAZE MOXA TECHNOLOGIES, INC. SISOFTWARE AXIOM MEMORY AUTOMATION INTEGRATED LLC EXACQ TECHNOLOGIES INC NETAPP SMARTAVI INC BYTECC AVAYA EXTREME NETWORKS NETEON TECHNOLOGIES INC. SMC NETWORKS CABLES TO GO AXIS COMMUNICATIONS EXTRON NETGEAR, INC. STAMPEDE TECHNOLOGIES INC CHENBRO B & B ELECTRONICS FORTINET NETRIA STARTECH.COM CISCO SYSTEMS BELKIN COMPONENTS FUJITSU SCANNERS NETSCOUT SYSTEMS, INC SUPERMICRO COMPUTER CORSAIR MEMORY BLACK BOX FUJITSU SERVER STORAGE NOVATEL WIRELESS SYBA TECH LTD CRU ‐ CONNECTOR RESOURCES BLACKMAGIC DESIGN USA GARRETTCOM OMNITRON TARGUS DELL BLONDER TONGUE LABORATORIES GEAR HEAD ORACLE TEK‐REPUBLIC DELL EMC BOSCH SECURITY GEFEN OVERLAND STORAGE TELEADAPT, INC.