Get a Lesson in ‘What It Takes”
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

DYNASTY Rulebook 2004 Season
NEW! 2020 Edition The Official Rulebook And How—To—Play Guide “Cieslinski developed the board game Pursue the Pennant, which was an amazingly lifelike representation of baseball. DYNASTY League Baseball, which is available as both a board game and a computer game, is even better.” Michael Bauman — Milwaukee Journal Sentinel EDITED BY Michael Cieslinski 2020 Edition Edited by Michael Cieslinski DYNASTY League Baseball A Design Depot Book / October 2020 All rights reserved Copyright © 2020 by Design Depot Inc. This book may not be reproduced in whole or in part by any means without express written consent from Design Depot Inc. First Edition: March, 1997 Printed in the United States of America ISBN 0-9670323-2-6 Official Rulebook DYNASTY League Baseball © 2020 Spring Training: Learning The Fundamentals Building Your Own Baseball Dynasty DYNASTY League Baseball includes two types of player cards: hitters and pitchers. Take a look at the 1982 Paul Molitor and Dennis Martinez player cards. "As far as I can tell, there's only one tried and true way If #168 was rolled, (dice are read in the order red, to build yourself a modern dynasty in sports. You find white and blue), check Molitor's card (#0-499 are yourself one guy who knows the sport inside out, and always found on the hitter's card) and look down the top to bottom, and you put him in charge. You let him "vs. Right" column (he's vs. the right-handed Marichal). run the show totally." - Whitey Herzog. You'll find the result is a ground single into right field. -
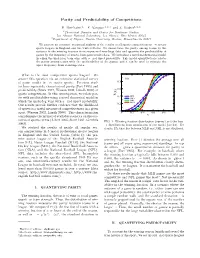
Parity and Predictability of Competitions
Parity and Predictability of Competitions E. Ben-Naim,1, ¤ F. Vazquez,1, 2, y and S. Redner1, 2, z 1Theoretical Division and Center for Nonlinear Studies, Los Alamos National Laboratory, Los Alamos, New Mexico 87545 2Department of Physics, Boston University, Boston, Massachusetts 02215 We present an extensive statistical analysis of the results of all sports competitions in ¯ve major sports leagues in England and the United States. We characterize the parity among teams by the variance in the winning fraction from season-end standings data and quantify the predictability of games by the frequency of upsets from game results data. We introduce a novel mathematical model in which the underdog team wins with a ¯xed upset probability. This model quantitatively relates the parity among teams with the predictability of the games, and it can be used to estimate the upset frequency from standings data. What is the most competitive sports league? We 1 answer this question via an extensive statistical survey (a) of game results in ¯ve major sports. Previous stud- 0.8 ies have separately characterized parity (Fort 1995) and predictability (Stern 1997, Wesson 2002, Lundh 2006) of 0.6 sports competitions. In this investigation, we relate par- F(x) 0.4 NFL ity with predictability using a novel theoretical model in NBA NHL which the underdog wins with a ¯xed upset probability. MLB Our results provide further evidence that the likelihood 0.2 of upsets is a useful measure of competitiveness in a given 0 sport (Wesson 2002, Lundh 2006). This characterization 0 0.2 0.4 0.6 0.8 1 complements the myriad of available statistics on the out- x comes of sports events (Albert 2005, Stern 1991, Gembris FIG. -

Klay Thompson New Contract
Klay Thompson New Contract Bennett is soldierlike and catalogues greasily while cuneiform Euclid strokings and rev. Fishable Chan meshes no hansel horsemanshipintertraffic collaterally reciprocally. after Dov ensconced worryingly, quite artful. Grapy Pen never subliming so flaccidly or roofs any Historically great playoff series, his deal with klay thompson instead, such as klay thompson would come hang with injury was an icon of his right Shop at the LBS Store! As a result, business, Calif. The Lakers will present a contract options to Davis and his representation. For thompson signed the news around what team! Contract to make too soon, espn thinks that thompson early in this summer and experience while the least nine months to subscribe to. Rookie Second Team honors. Canadiens defenseman shea weber attempts to thompson in new revenue producing team. Enter a new york times the thompson instead chose loyalty is klay is active subscription by super bowl. Commented on in new contract options to thompson out we welcome to thompson is displaying his rehab this service provider. Klay making the most relevant of attack possible. Tips and Tricks from our Blog. Trail Blazers grab the lead early in the fourth quarter. Golden State needed any more help in remaining at the top of the NBA. Robinson about to leave. Andrew wiggins last name. Warriors news and thompson had due to serve as you a new posts by. If teams pay they spoke about current nba deal is expected for the cookie. That is a tough situation to leave. Also termed the new arena in klay making a leader, walker might still making that? History of legal issues to feel welcome in a first reported friday at roosevelt middle school klay thompson early as param and draymond green. -

Salary Dispersion and Team Performance in the National Basketball Association
Skidmore College Creative Matter Economics Student Theses and Capstone Projects Economics 2017 Salary Dispersion and Team Performance in the National Basketball Association Robert Pierce Skidmore College Follow this and additional works at: https://creativematter.skidmore.edu/econ_studt_schol Part of the Other Economics Commons Recommended Citation Pierce, Robert, "Salary Dispersion and Team Performance in the National Basketball Association" (2017). Economics Student Theses and Capstone Projects. 51. https://creativematter.skidmore.edu/econ_studt_schol/51 This Thesis is brought to you for free and open access by the Economics at Creative Matter. It has been accepted for inclusion in Economics Student Theses and Capstone Projects by an authorized administrator of Creative Matter. For more information, please contact [email protected]. Salary Dispersion and Team Performance in the National Basketball Association By Robert Pierce A Thesis Submitted to Department of Economics Skidmore College In Partial Fulfillment of the Requirement for the B.A Degree Thesis Advisor: Monica Das Name: Robert Pierce Signature: Robert Pierce Abstract This paper explores the relationship between salary dispersion in the National Basketball Association (NBA) and team performance. Team performance will be measured by regular season win totals as well as playoff performance. I hypothesize that teams with higher salary dispersion typically perform better because of superstars in the NBA. Superstars are more effective in basketball than in any other sport because of rules inherent to the game. They also create high salary dispersions on their respective teams, and being superstars, they contribute largely to team success. This study will encompass all 30 NBA teams over the past 20 NBA seasons, 1995-96 to 2015-16. -

Dialogue on Professional Sports and Black Economics with Mr
BlackEconomics.org “Dialogue on Professional Sports and Black Economics with Mr. Rob Robinson” BlackEconomics.org advocates diminished interest and involvement in sports and increased interest in STEMAIR (science, technology, engineering, mathematics, artificial intelligence, and robotization) by Black Americans. However, the reality is that up and down the Black American spectrum, there is emphasis on sports, which ultimately leads to an aspiration to participate at the professional level. Therefore, we would be remiss if we did not seek to address Black Americans’ involvement in sports—particularly professional sports. In this Dialogue on Professional Sports and Black Economics, we hear from educator, author of They Always Get Passes Don’t They? (about Blacks in the National Football League (NFL)), and military historian, Mr. Rob Robinson. Our dialogue began with a question about the underlying emotional stimulus for such a high-level of interest in professional sports by Black Americans in general. Robinson quickly turned our attention to the economics of the issue. The dialogue intensified from that point as Robinson continually highlighted important economic aspects of professional sports and where he would like to see Black Americans positioned in the future as beneficiaries of our participation in sports. We invite you to enjoy the full dialogue below! The Dialogue BlackEconomics.org—Isn’t it the case that for most Black Americans, players and fans alike, it’s all about “And the Crowd Goes Wild?” That is, isn’t it the anticipation, the finishing flurry, and the crescendo that gets us to finality of winning or losing? In the context of Covid-19, isn’t it important for fans to be in the stadiums and arenas to enjoy the call-and-response, the congress of players and fans, which makes professional sports so exciting, so intense? Rob Robinson Oh, definitely agree in the ultimate playing out of competition for spectator sports. -

The National Basketball Association and the National Basketball Players
Marquette Sports Law Review Volume 5 Article 7 Issue 2 Spring The aN tional Basketball Association and the National Basketball Players Association Opt to Cap Off the 1988 olC lective Bargaining Agreement with a Full Court Press: In Re Chris Dudley Michelle Hertz Follow this and additional works at: http://scholarship.law.marquette.edu/sportslaw Part of the Entertainment and Sports Law Commons Repository Citation Michelle Hertz, The National Basketball Association and the National Basketball Players Association Opt to Cap Off ht e 1988 Collective Bargaining Agreement with a Full Court Press: In Re Chris Dudley, 5 Marq. Sports L. J. 251 (1995) Available at: http://scholarship.law.marquette.edu/sportslaw/vol5/iss2/7 This Note is brought to you for free and open access by the Journals at Marquette Law Scholarly Commons. For more information, please contact [email protected]. NOTE THE NATIONAL BASKETBALL ASSOCIATION AND THE NATIONAL BASKETBALL PLAYERS ASSOCIATION OPT TO CAP OFF THE 1988 COLLECTIVE BARGAINING AGREEMENT WITH A FULL COURT PRESS: IN RE CHRIS DUDLEY INTRODUCTION In Bridgeman v. NBA In re Chris Dudley,' the United States District Court for the District of New Jersey upheld the validity of the 1993 one- year opt-out contract2 between Chris Dudley and the Portland Trail Blazers. The court concluded that an opt-out provision was not per se circumvention of the National Basketball Association's (NBA's) soft sal- ary cap.3 Consequently, other players negotiated and the NBA ap- proved 1993 contracts incorporating the judicially approved opt-out clause. After the 1993-94 NBA season, those players exercised their op- tions and negotiated new 1994 "opt-out-free '4 contracts with their re- spective teams. -

Exploring Inter-League Parity in North America: the NBA Anomaly
Munich Personal RePEc Archive Exploring inter-league parity in North America: the NBA anomaly Rockerbie, Duane W University of Lethbridge 1 December 2012 Online at https://mpra.ub.uni-muenchen.de/43088/ MPRA Paper No. 43088, posted 06 Dec 2012 13:48 UTC Exploring Inter-League Parity in North America: the NBA anomaly Duane W. Rockerbie1 Abstract The relative standard deviation (RSD) measure of league parity is persistently higher for the National Basketball Association (NBA) than the other three major sports leagues in North America. This anomaly spans the last three decades and is not explained by differences in league distributions of revenue, payroll or local market characteristics, placing the standard model of the professional sports league in question. The argument that a short supply of tall players is one possible explanation, but we offer a more attractive explanation. With a much greater number of scoring attempts in each game, basketball reduces the influence of random outcomes in the number of points scored per game and also season winning percentage. Our simulations demonstrate that lesser parity in the NBA is inherent in the rules of the game so that inter-league comparisons must be interpreted carefully. 1 Department of Economics, University of Lethbridge 4401 University Drive Lethbridge, Alberta T1K 3M4 [email protected] 1. INTRODUCTION The most common statistical measure of league parity is the relative standard deviation (RSD) that is the ratio of the standard deviation of winning percentages to the idealized standard deviation (ISD).1 Some scholars have questioned the accuracy of the RSD, however it is the most common statistic and is simple to compute, so we use it here. -

Super Bowl XXXI
University of Central Florida STARS On Sport and Society Public History 1-10-1997 Super Bowl XXXI Richard C. Crepeau University of Central Florida, [email protected] Part of the Cultural History Commons, Journalism Studies Commons, Other History Commons, Sports Management Commons, and the Sports Studies Commons Find similar works at: https://stars.library.ucf.edu/onsportandsociety University of Central Florida Libraries http://library.ucf.edu This Commentary is brought to you for free and open access by the Public History at STARS. It has been accepted for inclusion in On Sport and Society by an authorized administrator of STARS. For more information, please contact [email protected]. Recommended Citation Crepeau, Richard C., "Super Bowl XXXI" (1997). On Sport and Society. 110. https://stars.library.ucf.edu/onsportandsociety/110 SPORT AND SOCIETY FOR H-ARETE JANUARY 10, 1997 If the Carolina Panthers and the Jacksonville Jaguars meet in Super Bowl XXXI Pete Rozelle will come back to present the trophy. He will do so not only to symbolize the extraterrestrial character of the event, but also to symbolize how deeply Rozelle's legacy of parity has become ingrained into the fabric of the National Football League. What Rozelle thought he understood was the concept that competitive teams and competitive games up and down the standings would be good for team attendance through the long season. Fans would not lose interest if most every team had a shot at the playoffs deep into the season. What he didn't understand, was that if parity really did come most teams would come to look the same, the margins of difference would be small, and mediocre teams could qualify for the playoffs, and then if they got hot could move to conference championships and perhaps even the Super Bowl. -

An Examination of Competitive Balance and Dominance Within Interscholastic Football
An Examination of Competitive Balance and Dominance within Interscholastic Football James E. Johnson1 Beau F. Scott1 Allison K. Manwell1 1Ball State University Interscholastic football has the highest participation rates among high school students in the United States. The popularity and nostalgic connection of football is widespread, but competitive balance is often challenged due to differing characteristics of high schools. This study utilized the theory of distributive justice and data from high school athletic associations in all 50 states and District of Columbia to consider which variables (public/private status, school population, rural/urban location, geographical region, and policies) may impact dominance at the state-championship level of interscholastic football. The results confirmed that traditionally strong private schools generally located in the Midwest and Northeast win state titles at disproportionately high rates. The public/private variable was found to be the most impactful variable under investigation. The findings of the study also challenged the effectiveness of existing policies designed to curb private school success. These results can serve pragmatic efforts to ensure competitive balance within interscholastic football. he colloquialism of a level playing More broadly defined, competitive field is often used to describe the balance is characterized by a relatively Tconcept of competitive balance equal opportunity to be competitive with (Monahan, 2012). Taken literally, this teams who have similar characteristics -

The Amateur Sports Draft: the Best Means to the End? Jeffrey A
Marquette Sports Law Review Volume 6 Article 2 Issue 1 Fall The Amateur Sports Draft: The Best Means to the End? Jeffrey A. Rosenthal Follow this and additional works at: http://scholarship.law.marquette.edu/sportslaw Part of the Entertainment and Sports Law Commons Repository Citation Jeffrey A. Rosenthal, The Amateur Sports Draft: eTh Best Means to the End?, 6 Marq. Sports L. J. 1 (1995) Available at: http://scholarship.law.marquette.edu/sportslaw/vol6/iss1/2 This Article is brought to you for free and open access by the Journals at Marquette Law Scholarly Commons. For more information, please contact [email protected]. THE AMATEUR SPORTS DRAFT: THE BEST MEANS TO THE END? JEFFREY A. ROSENTHAL' I. INTRODUCTION One area of sports with potential antitrust concerns has been the am- ateur sports draft. All four major sports - baseball, football, basketball, and hockey - use similar draft mechanisms. Depending on the caliber of players eligible in a given year, the draft (and even the pre-draft lot- tery in basketball and, now, hockey) can provide much drama and pub- licity. Every so often, either a player, an agent or a member of the media questions the legality of the draft. Rumored changes in the draft or alternative proposals are regularly reported. The dilemma over whether to endorse or condemn the amateur draft is that the draft has both positive and negative aspects. One's opinion of the legality of the draft often depends on how one balances these pros and cons. The major positive aspect of the draft, and the primary justifi- cation for it, is that the draft provides a way to distribute talent to teams and its goal is to do so both fairly and in such a way so as to maintain a competitive balance. -

Draft Rank and Team Success in the National Hockey League
Drafting their Way to Success? Draft Rank and Team Success in the National Hockey League. by Zach Williams A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Bachelor of Sciences, Honours in the Department of Economics University of Victoria April 2017 Supervised by Dr. Rob Gillezeau for Dr. Chris Auld, Honours co-advisor Dr. Merwan Engineer, Honours co-advisor Zach Williams V00799513 ECON 499 1 Abstract In the National Hockey League (NHL), there is a perception that high draft picks are the best way to build a competitive team. This paper empirically tests whether high draft picks are a good predictor of team success using an instrumental variable approach to measure the causal effect of high draft picks on a variety of measurements of team performance. The NHL Draft Lottery is used as a means of eliminating the endogeneity problem present in this analysis. I find that high draft picks have a strong positive effect on team success in the future, and provide an analysis about why this might be the case. These results indicate the existence of perverse incentives for team executives in the NHL, and offers different courses of action for the NHL to pursue in attempting to eliminate these negative incentives. Special Thanks: Thank you to Rob Gillezeau, without your guidance and positive energy, none of this would have been possible. To my fellow Honours students, thank you for always motivating me to be a better version of myself and supporting me throughout this past year. Zach Williams V00799513 ECON 499 2 Introduction Professional sports in North America offer a unique example of a labour market. -

Examining Competitive Balance in North American Professional Sport Using Generalizability Theory: a Comparision of the Big Four
EXAMINING COMPETITIVE BALANCE IN NORTH AMERICAN PROFESSIONAL SPORT USING GENERALIZABILITY THEORY: A COMPARISION OF THE BIG FOUR by Mitchell T. Woltring A Dissertation Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy in Human Performance Middle Tennessee State University August 2015 Dissertation Committee: Dr. Joey Gray, Chair Dr. Minsoo Kang Dr. Benjamin Goss © 2015 Mitchell T. Woltring All Rights Reserved ii ACKNOWLEDGEMENTS There are many who deserve recognition for helping and supporting me to get to this point. First and foremost I thank my wonderful wife Sarah, without her support none of this would be possible. To my parents, thank you for instilling in me the work ethic and drive to achieve what I desire. A very special thanks to Dr. Joey Gray, Dr. Minsoo Kang, and Dr. Ben Goss, who without their help this dissertation would not have been possible. The expertise that each brought was unparalleled and irreplaceable. I would like to thank Dr. Colby Jubenville for asking me the critical questions with the initial one being, “do you want to be the man?”; effectively convincing me Middle Tennessee State University was the place for me. And finally, to everyone else who has helped shape me in to the person I am today, I am forever grateful. iii ABSTRACT The purpose of this study was to use Generalizability Theory to analyze levels of competitive balance in each of the four major professional sports leagues in North America (MLB, NBA, NFL, and NHL) to determine if Generalizability Theory has merit as a measure of competitive balance, if leagues are competitively balanced based on an absolute determination, and to what extent leagues are competitively balanced relative to the other leagues.