Recent Filesystem Optimisations in Freebsd
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Proceedings of the Bsdcon 2002 Conference
USENIX Association Proceedings of the BSDCon 2002 Conference San Francisco, California, USA February 11-14, 2002 THE ADVANCED COMPUTING SYSTEMS ASSOCIATION © 2002 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649 FAX: 1 510 548 5738 Email: [email protected] WWW: http://www.usenix.org Rights to individual papers remain with the author or the author's employer. Permission is granted for noncommercial reproduction of the work for educational or research purposes. This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein. Rethinking /devand devices in the UNIX kernel Poul-Henning Kamp <[email protected]> The FreeBSD Project Abstract An outstanding novelty in UNIX at its introduction was the notion of ‘‘a file is a file is a file and evenadevice is a file.’’ Going from ‘‘hardware only changes when the DEC Field engineer is here’’to‘‘my toaster has USB’’has put serious strain on the rather crude implementation of the ‘‘devices as files’’concept, an implementation which has survivedpractically unchanged for 30 years in most UNIX variants. Starting from a high-levelviewofdevices and the semantics that have grown around them overthe years, this paper takes the audience on a grand tour of the redesigned FreeBSD device-I/O system, to convey anoverviewofhow itall fits together,and to explain whythings ended up as theydid, howtouse the newfeatures and in particular hownot to. 1. Introduction tax and meaning, so that a program expecting a file name as a parameter can be passed a device name; There are really only twofundamental ways to concep- finally,special files are subject to the same protec- tualise I/O devices in an operating system: The usual tion mechanism as regular files. -

Active-Active Firewall Cluster Support in Openbsd
Active-Active Firewall Cluster Support in OpenBSD David Gwynne School of Information Technology and Electrical Engineering, University of Queensland Submitted for the degree of Bachelor of Information Technology COMP4000 Special Topics Industry Project February 2009 to leese, who puts up with this stuff ii Acknowledgements I would like to thank Peter Sutton for allowing me the opportunity to do this work as part of my studies at the University of Queensland. A huge thanks must go to Ryan McBride for answering all my questions about pf and pfsync in general, and for the many hours working with me on this problem and helping me test and debug the code. Thanks also go to Theo de Raadt, Claudio Jeker, Henning Brauer, and everyone else at the OpenBSD network hackathons who helped me through this. iii Abstract The OpenBSD UNIX-like operating system has developed several technologies that make it useful in the role of an IP router and packet filtering firewall. These technologies include support for several standard routing protocols such as BGP and OSPF, a high performance stateful IP packet filter called pf, shared IP address and fail-over support with CARP (Common Address Redundancy Protocol), and a protocol called pfsync for synchronisation of the firewalls state with firewalls over a network link. These technologies together allow the deployment of two or more computers to provide redundant and highly available routers on a network. However, when performing stateful filtering of the TCP protocol with pf, the routers must be configured in an active-passive configuration due to the current semantics of pfsync. -

Mellanox OFED for Freebsd for Connectx-4 and Above Adapter Cards User Manual
Mellanox OFED for FreeBSD for ConnectX-4 and above Adapter Cards User Manual Rev 3.5.2 www.mellanox.com Mellanox Technologies NOTE: THIS HARDWARE, SOFTWARE OR TEST SUITE PRODUCT (“PRODUCT(S)”) AND ITS RELATED DOCUMENTATION ARE PROVIDED BY MELLANOX TECHNOLOGIES “AS-IS” WITH ALL FAULTS OF ANY KIND AND SOLELY FOR THE PURPOSE OF AIDING THE CUSTOMER IN TESTING APPLICATIONS THAT USE THE PRODUCTS IN DESIGNATED SOLUTIONS. THE CUSTOMER'S MANUFACTURING TEST ENVIRONMENT HAS NOT MET THE STANDARDS SET BY MELLANOX TECHNOLOGIES TO FULLY QUALIFY THE PRODUCT(S) AND/OR THE SYSTEM USING IT. THEREFORE, MELLANOX TECHNOLOGIES CANNOT AND DOES NOT GUARANTEE OR WARRANT THAT THE PRODUCTS WILL OPERATE WITH THE HIGHEST QUALITY. ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT ARE DISCLAIMED. IN NO EVENT SHALL MELLANOX BE LIABLE TO CUSTOMER OR ANY THIRD PARTIES FOR ANY DIRECT, INDIRECT, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES OF ANY KIND (INCLUDING, BUT NOT LIMITED TO, PAYMENT FOR PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY FROM THE USE OF THE PRODUCT(S) AND RELATED DOCUMENTATION EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. Mellanox Technologies 350 Oakmead Parkway Suite 100 Sunnyvale, CA 94085 U.S.A. www.mellanox.com Tel: (408) 970-3400 Fax: (408) 970-3403 © Copyright 2019. Mellanox Technologies Ltd. All Rights Reserved. Mellanox®, Mellanox logo, Mellanox Open Ethernet®, LinkX®, Mellanox Spectrum®, Mellanox Virtual Modular Switch®, MetroDX®, MetroX®, MLNX-OS®, ONE SWITCH. -

Performance, Scalability on the Server Side
Performance, Scalability on the Server Side John VanDyk Presented at Des Moines Web Geeks 9/21/2009 Who is this guy? History • Apple // • Macintosh • Windows 3.1- Server 2008R2 • Digital Unix (Tru64) • Linux (primarily RHEL) • FreeBSD Systems Iʼve worked with over the years. Languages • Perl • Userland Frontier™ • Python • Java • Ruby • PHP Languages Iʼve worked with over the years (Userland Frontier™ʼs integrated language is UserTalk™) Open source developer since 2000 Perl/Python/PHP MySQL Apache Linux The LAMP stack. Time to Serve Request Number of Clients Performance vs. scalability. network in network out RAM CPU Storage These are the basic laws of physics. All bottlenecks are caused by one of these four resources. Disk-bound •To o l s •iostat •vmstat Determine if you are disk-bound by measuring throughput. vmstat (BSD) procs memory page disk faults cpu r b w avm fre flt re pi po fr sr tw0 in sy cs us sy id 0 2 0 799M 842M 27 0 0 0 12 0 23 344 2906 1549 1 1 98 3 3 0 869M 789M 5045 0 0 0 406 0 10 1311 17200 5301 12 4 84 3 5 0 923M 794M 5219 0 0 0 5178 0 27 1825 21496 6903 35 8 57 1 2 0 931M 784M 909 0 0 0 146 0 12 955 9157 3570 8 4 88 blocked plenty of RAM, idle processes no swapping CPUs A disk-bound FreeBSD machine. b = blocked for resources fr = pages freed/sec cs = context switches avm = active virtual pages in = interrupts flt = memory page faults sy = system calls per interval vmstat (RHEL5) # vmstat -S M 5 25 procs ---------memory-------- --swap- ---io--- --system- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 1301 194 5531 0 0 0 29 1454 2256 24 20 56 0 0 3 0 0 1257 194 5531 0 0 0 40 2087 2336 34 27 39 0 0 2 0 0 1183 194 5531 0 0 0 53 1658 2763 33 28 39 0 0 0 0 0 1344 194 5531 0 0 0 34 1807 2125 29 19 52 0 0 no blocked busy but not processes overloaded CPU in = interrupts/sec cs = context switches/sec wa = time waiting for I/O Solving disk bottlenecks • Separate spindles (logs and databases) • Get rid of atime updates! • Minimize writes • Move temp writes to /dev/shm Overview of what weʼre about to dive into. -

BSD UNIX Toolbox 1000+ Commands for Freebsd, Openbsd
76034ffirs.qxd:Toolbox 4/2/08 12:50 PM Page iii BSD UNIX® TOOLBOX 1000+ Commands for FreeBSD®, OpenBSD, and NetBSD®Power Users Christopher Negus François Caen 76034ffirs.qxd:Toolbox 4/2/08 12:50 PM Page ii 76034ffirs.qxd:Toolbox 4/2/08 12:50 PM Page i BSD UNIX® TOOLBOX 76034ffirs.qxd:Toolbox 4/2/08 12:50 PM Page ii 76034ffirs.qxd:Toolbox 4/2/08 12:50 PM Page iii BSD UNIX® TOOLBOX 1000+ Commands for FreeBSD®, OpenBSD, and NetBSD®Power Users Christopher Negus François Caen 76034ffirs.qxd:Toolbox 4/2/08 12:50 PM Page iv BSD UNIX® Toolbox: 1000+ Commands for FreeBSD®, OpenBSD, and NetBSD® Power Users Published by Wiley Publishing, Inc. 10475 Crosspoint Boulevard Indianapolis, IN 46256 www.wiley.com Copyright © 2008 by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada ISBN: 978-0-470-37603-4 Manufactured in the United States of America 10 9 8 7 6 5 4 3 2 1 Library of Congress Cataloging-in-Publication Data is available from the publisher. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600. Requests to the Publisher for permis- sion should be addressed to the Legal Department, Wiley Publishing, Inc., 10475 Crosspoint Blvd., Indianapolis, IN 46256, (317) 572-3447, fax (317) 572-4355, or online at http://www.wiley.com/go/permissions. -

Linux Kernel and Driver Development Training Slides
Linux Kernel and Driver Development Training Linux Kernel and Driver Development Training © Copyright 2004-2021, Bootlin. Creative Commons BY-SA 3.0 license. Latest update: October 9, 2021. Document updates and sources: https://bootlin.com/doc/training/linux-kernel Corrections, suggestions, contributions and translations are welcome! embedded Linux and kernel engineering Send them to [email protected] - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 1/470 Rights to copy © Copyright 2004-2021, Bootlin License: Creative Commons Attribution - Share Alike 3.0 https://creativecommons.org/licenses/by-sa/3.0/legalcode You are free: I to copy, distribute, display, and perform the work I to make derivative works I to make commercial use of the work Under the following conditions: I Attribution. You must give the original author credit. I Share Alike. If you alter, transform, or build upon this work, you may distribute the resulting work only under a license identical to this one. I For any reuse or distribution, you must make clear to others the license terms of this work. I Any of these conditions can be waived if you get permission from the copyright holder. Your fair use and other rights are in no way affected by the above. Document sources: https://github.com/bootlin/training-materials/ - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 2/470 Hyperlinks in the document There are many hyperlinks in the document I Regular hyperlinks: https://kernel.org/ I Kernel documentation links: dev-tools/kasan I Links to kernel source files and directories: drivers/input/ include/linux/fb.h I Links to the declarations, definitions and instances of kernel symbols (functions, types, data, structures): platform_get_irq() GFP_KERNEL struct file_operations - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 3/470 Company at a glance I Engineering company created in 2004, named ”Free Electrons” until Feb. -

The Complete Freebsd
The Complete FreeBSD® If you find errors in this book, please report them to Greg Lehey <grog@Free- BSD.org> for inclusion in the errata list. The Complete FreeBSD® Fourth Edition Tenth anniversary version, 24 February 2006 Greg Lehey The Complete FreeBSD® by Greg Lehey <[email protected]> Copyright © 1996, 1997, 1999, 2002, 2003, 2006 by Greg Lehey. This book is licensed under the Creative Commons “Attribution-NonCommercial-ShareAlike 2.5” license. The full text is located at http://creativecommons.org/licenses/by-nc-sa/2.5/legalcode. You are free: • to copy, distribute, display, and perform the work • to make derivative works under the following conditions: • Attribution. You must attribute the work in the manner specified by the author or licensor. • Noncommercial. You may not use this work for commercial purposes. This clause is modified from the original by the provision: You may use this book for commercial purposes if you pay me the sum of USD 20 per copy printed (whether sold or not). You must also agree to allow inspection of printing records and other material necessary to confirm the royalty sums. The purpose of this clause is to make it attractive to negotiate sensible royalties before printing. • Share Alike. If you alter, transform, or build upon this work, you may distribute the resulting work only under a license identical to this one. • For any reuse or distribution, you must make clear to others the license terms of this work. • Any of these conditions can be waived if you get permission from the copyright holder. Your fair use and other rights are in no way affected by the above. -

System Analysis and Tuning Guide System Analysis and Tuning Guide SUSE Linux Enterprise Server 15 SP1
SUSE Linux Enterprise Server 15 SP1 System Analysis and Tuning Guide System Analysis and Tuning Guide SUSE Linux Enterprise Server 15 SP1 An administrator's guide for problem detection, resolution and optimization. Find how to inspect and optimize your system by means of monitoring tools and how to eciently manage resources. Also contains an overview of common problems and solutions and of additional help and documentation resources. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents About This Guide xii 1 Available Documentation xiii -
Some Results Recall: FAT Properties FAT Assessment – Issues
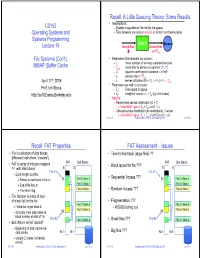
Recall: A Little Queuing Theory: Some Results • Assumptions: CS162 – System in equilibrium; No limit to the queue Operating Systems and – Time between successive arrivals is random and memoryless Systems Programming Queue Server Lecture 19 Arrival Rate Service Rate μ=1/Tser File Systems (Con’t), • Parameters that describe our system: MMAP, Buffer Cache – : mean number of arriving customers/second –Tser: mean time to service a customer (“m1”) –C: squared coefficient of variance = 2/m12 –μ: service rate = 1/Tser th April 11 , 2019 –u: server utilization (0u1): u = /μ = Tser • Parameters we wish to compute: Prof. Ion Stoica –Tq: Time spent in queue http://cs162.eecs.Berkeley.edu –Lq: Length of queue = Tq (by Little’s law) • Results: –Memoryless service distribution (C = 1): » Called M/M/1 queue: Tq = Tser x u/(1 – u) –General service distribution (no restrictions), 1 server: » Called M/G/1 queue: Tq = Tser x ½(1+C) x u/(1 – u)) 4/11/19 Kubiatowicz CS162 © UCB Spring 2019 Lec 19.2 Recall: FAT Properties FAT Assessment – Issues • File is collection of disk blocks • Time to find block (large files) ?? (Microsoft calls them “clusters”) FAT Disk Blocks FAT Disk Blocks • FAT is array of integers mapped • Block layout for file ??? 1-1 with disk blocks 0: 0: 0: 0: File #1 File #1 – Each integer is either: • Sequential Access ??? » Pointer to next block in file; or 31: File 31, Block 0 31: File 31, Block 0 » End of file flag; or File 31, Block 1 File 31, Block 1 » Free block flag File 63, Block 1 • Random Access ??? File 63, Block 1 • File Number -

Kratka Povijest Unixa Od Unicsa Do Freebsda I Linuxa
Kratka povijest UNIXa Od UNICSa do FreeBSDa i Linuxa 1 Autor: Hrvoje Horvat Naslov: Kratka povijest UNIXa - Od UNICSa do FreeBSDa i Linuxa Licenca i prava korištenja: Svi imaju pravo koristiti, mijenjati, kopirati i štampati (printati) knjigu, prema pravilima GNU GPL licence. Mjesto i godina izdavanja: Osijek, 2017 ISBN: 978-953-59438-0-8 (PDF-online) URL publikacije (PDF): https://www.opensource-osijek.org/knjige/Kratka povijest UNIXa - Od UNICSa do FreeBSDa i Linuxa.pdf ISBN: 978-953- 59438-1- 5 (HTML-online) DokuWiki URL (HTML): https://www.opensource-osijek.org/dokuwiki/wiki:knjige:kratka-povijest- unixa Verzija publikacije : 1.0 Nakalada : Vlastita naklada Uz pravo svakoga na vlastito štampanje (printanje), prema pravilima GNU GPL licence. Ova knjiga je napisana unutar inicijative Open Source Osijek: https://www.opensource-osijek.org Inicijativa Open Source Osijek je član udruge Osijek Software City: http://softwarecity.hr/ UNIX je registrirano i zaštićeno ime od strane tvrtke X/Open (Open Group). FreeBSD i FreeBSD logo su registrirani i zaštićeni od strane FreeBSD Foundation. Imena i logo : Apple, Mac, Macintosh, iOS i Mac OS su registrirani i zaštićeni od strane tvrtke Apple Computer. Ime i logo IBM i AIX su registrirani i zaštićeni od strane tvrtke International Business Machines Corporation. IEEE, POSIX i 802 registrirani i zaštićeni od strane instituta Institute of Electrical and Electronics Engineers. Ime Linux je registrirano i zaštićeno od strane Linusa Torvaldsa u Sjedinjenim Američkim Državama. Ime i logo : Sun, Sun Microsystems, SunOS, Solaris i Java su registrirani i zaštićeni od strane tvrtke Sun Microsystems, sada u vlasništvu tvrtke Oracle. Ime i logo Oracle su u vlasništvu tvrtke Oracle. -

SAP HANA Server Installation and Update Guide Company
PUBLIC SAP HANA Platform 2.0 SPS 05 Document Version: 1.1 – 2021-09-24 SAP HANA Server Installation and Update Guide company. All rights reserved. All rights company. affiliate THE BEST RUN 2021 SAP SE or an SAP SE or an SAP SAP 2021 © Content 1 SAP HANA Server Installation and Update Guide....................................9 2 SAP HANA Installation and Update Overview......................................10 2.1 SAP HANA Platform Software Components..........................................10 2.2 Software Download...........................................................11 2.3 Software Authenticity Verification.................................................13 3 Concepts and Requirements for an SAP HANA System...............................15 3.1 SAP HANA Hardware and Software Requirements.....................................15 3.2 Recommended File System Layout................................................18 3.3 SAP HANA System Concepts....................................................21 3.4 SAP HANA System Types...................................................... 22 3.5 SAP HANA Deployment Types...................................................25 3.6 SAP HANA and Virtualization....................................................27 3.7 Local Secure Store (LSS).......................................................28 4 Overview of SAP HANA Tenant Databases........................................30 4.1 Server Architecture of Tenant Databases............................................31 4.2 Scale-Out Architecture of Tenant Databases.........................................33 -

BSD Professional Certification Job Task Analysis Survey Results
BSD Professional Certification Job Task Analysis Survey Results March 21, 2010 BSD Professional Job Task Analysis Survey Results 2 Copyright © 2010 BSD Certification Group All Rights Reserved All trademarks are owned by their respective companies. This work is protected by a Creative Commons License which requires attribution and prevents commercial and derivative works. The human friendly version of the license can be viewed at http://creativecommons.org/licenses/by-nc-nd/3.0/ which also provides a hyperlink to the legal code. These conditions can only be waived by written permission from the BSD Certification Group. See the website for contact details. BSD Daemon Copyright 1988 by Marshall Kirk McKusick. All Rights Reserved. Puffy Artwork Copyright© 2004 by OpenBSD. FreeBSD® is a registered trademark of The FreeBSD Foundation, Inc. NetBSD® is a registered trademark of The NetBSD Foundation, Inc. The NetBSD Logo Copyright© 2004 by The NetBSD Foundation, Inc. Fred Artwork Copyright© 2005 by DragonFly BSD. Use of the above names, trademarks, logos, and artwork does not imply endorsement of this certification program by their respective owners. www.bsdcertification.org BSD Professional Job Task Analysis Survey Results 3 Table of Contents Executive Summary ................................................................................................................................... 9 Introduction .............................................................................................................................................