Assessing the Accuracy and Quality of Wikipedia Entries Compared to Popular Online Encyclopaedias
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cultural Anthropology Through the Lens of Wikipedia: Historical Leader Networks, Gender Bias, and News-Based Sentiment
Cultural Anthropology through the Lens of Wikipedia: Historical Leader Networks, Gender Bias, and News-based Sentiment Peter A. Gloor, Joao Marcos, Patrick M. de Boer, Hauke Fuehres, Wei Lo, Keiichi Nemoto [email protected] MIT Center for Collective Intelligence Abstract In this paper we study the differences in historical World View between Western and Eastern cultures, represented through the English, the Chinese, Japanese, and German Wikipedia. In particular, we analyze the historical networks of the World’s leaders since the beginning of written history, comparing them in the different Wikipedias and assessing cultural chauvinism. We also identify the most influential female leaders of all times in the English, German, Spanish, and Portuguese Wikipedia. As an additional lens into the soul of a culture we compare top terms, sentiment, emotionality, and complexity of the English, Portuguese, Spanish, and German Wikinews. 1 Introduction Over the last ten years the Web has become a mirror of the real world (Gloor et al. 2009). More recently, the Web has also begun to influence the real world: Societal events such as the Arab spring and the Chilean student unrest have drawn a large part of their impetus from the Internet and online social networks. In the meantime, Wikipedia has become one of the top ten Web sites1, occasionally beating daily newspapers in the actuality of most recent news. Be it the resignation of German national soccer team captain Philipp Lahm, or the downing of Malaysian Airlines flight 17 in the Ukraine by a guided missile, the corresponding Wikipedia page is updated as soon as the actual event happened (Becker 2012. -

Position Description Addenda
POSITION DESCRIPTION January 2014 Wikimedia Foundation Executive Director - Addenda The Wikimedia Foundation is a radically transparent organization, and much information can be found at www.wikimediafoundation.org . That said, certain information might be particularly useful to nominators and prospective candidates, including: Announcements pertaining to the Wikimedia Foundation Executive Director Search Kicking off the search for our next Executive Director by Former Wikimedia Foundation Board Chair Kat Walsh An announcement from Wikimedia Foundation ED Sue Gardner by Wikimedia Executive Director Sue Gardner Video Interviews on the Wikimedia Community and Foundation and Its History Some of the values and experiences of the Wikimedia Community are best described directly by those who have been intimately involved in the organization’s dramatic expansion. The following interviews are available for viewing though mOppenheim.TV . • 2013 Interview with Former Wikimedia Board Chair Kat Walsh • 2013 Interview with Wikimedia Executive Director Sue Gardner • 2009 Interview with Wikimedia Executive Director Sue Gardner Guiding Principles of the Wikimedia Foundation and the Wikimedia Community The following article by Sue Gardner, the current Executive Director of the Wikimedia Foundation, has received broad distribution and summarizes some of the core cultural values shared by Wikimedia’s staff, board and community. Topics covered include: • Freedom and open source • Serving every human being • Transparency • Accountability • Stewardship • Shared power • Internationalism • Free speech • Independence More information can be found at: https://meta.wikimedia.org/wiki/User:Sue_Gardner/Wikimedia_Foundation_Guiding_Principles Wikimedia Policies The Wikimedia Foundation has an extensive list of policies and procedures available online at: http://wikimediafoundation.org/wiki/Policies Wikimedia Projects All major projects of the Wikimedia Foundation are collaboratively developed by users around the world using the MediaWiki software. -

A Topic-Aligned Multilingual Corpus of Wikipedia Articles for Studying Information Asymmetry in Low Resource Languages
Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), pages 2373–2380 Marseille, 11–16 May 2020 c European Language Resources Association (ELRA), licensed under CC-BY-NC A Topic-Aligned Multilingual Corpus of Wikipedia Articles for Studying Information Asymmetry in Low Resource Languages Dwaipayan Roy, Sumit Bhatia, Prateek Jain GESIS - Cologne, IBM Research - Delhi, IIIT - Delhi [email protected], [email protected], [email protected] Abstract Wikipedia is the largest web-based open encyclopedia covering more than three hundred languages. However, different language editions of Wikipedia differ significantly in terms of their information coverage. We present a systematic comparison of information coverage in English Wikipedia (most exhaustive) and Wikipedias in eight other widely spoken languages (Arabic, German, Hindi, Korean, Portuguese, Russian, Spanish and Turkish). We analyze the content present in the respective Wikipedias in terms of the coverage of topics as well as the depth of coverage of topics included in these Wikipedias. Our analysis quantifies and provides useful insights about the information gap that exists between different language editions of Wikipedia and offers a roadmap for the Information Retrieval (IR) community to bridge this gap. Keywords: Wikipedia, Knowledge base, Information gap 1. Introduction other with respect to the coverage of topics as well as Wikipedia is the largest web-based encyclopedia covering the amount of information about overlapping topics. -

Wikibase Knowledge Graphs for Data Management & Data Science
Business and Economics Research Data Center https://www.berd-bw.de Baden-Württemberg Wikibase knowledge graphs for data management & data science Dr. Renat Shigapov 23.06.2021 @shigapov @_shigapov DATA Motivation MANAGEMENT 1. people DATA SCIENCE knowledg! 2. processes information linking 3. technology data things KNOWLEDGE GRAPHS 2 DATA Flow MANAGEMENT Definitions DATA Wikidata & Tools SCIENCE Local Wikibase Wikibase Ecosystem Summary KNOWLEDGE GRAPHS 29.10.2012 2030 2021 3 DATA Example: Named Entity Linking SCIENCE https://commons.wikimedia.org/wiki/File:Entity_Linking_-_Short_Example.png Rule#$as!d problems Machine Learning De!' Learning Learn data science at https://www.kaggle.com 4 https://commons.wikimedia.org/wiki/File:Data_visualization_process_v1.png DATA Example: general MANAGEMENT research data silos data fabric data mesh data space data marketplace data lake data swamp Research data lifecycle https://www.reading.ac.uk/research-services/research-data-management/ 5 https://www.dama.org/cpages/body-of-knowledge about-research-data-management/the-research-data-lifecycle KNOWLEDGE ONTOLOG( + GRAPH = + THINGS https://www.mediawiki.org https://www.wikiba.se ✔ “Things, not strings” by Google, 2012 + ✔ A knowledge graph links things in different datasets https://mariadb.org https://blazegraph.com ✔ A knowledge graph can link people & relational database graph database processes and enhance technologies The main example: “THE KNOWLEDGE GRAPH COOKBOOK RECIPES THAT WORK” by ANDREAS BLUMAUER & HELMUT NAGY, 2020. https://www.wikidata.org -

Modeling Popularity and Reliability of Sources in Multilingual Wikipedia
information Article Modeling Popularity and Reliability of Sources in Multilingual Wikipedia Włodzimierz Lewoniewski * , Krzysztof W˛ecel and Witold Abramowicz Department of Information Systems, Pozna´nUniversity of Economics and Business, 61-875 Pozna´n,Poland; [email protected] (K.W.); [email protected] (W.A.) * Correspondence: [email protected] Received: 31 March 2020; Accepted: 7 May 2020; Published: 13 May 2020 Abstract: One of the most important factors impacting quality of content in Wikipedia is presence of reliable sources. By following references, readers can verify facts or find more details about described topic. A Wikipedia article can be edited independently in any of over 300 languages, even by anonymous users, therefore information about the same topic may be inconsistent. This also applies to use of references in different language versions of a particular article, so the same statement can have different sources. In this paper we analyzed over 40 million articles from the 55 most developed language versions of Wikipedia to extract information about over 200 million references and find the most popular and reliable sources. We presented 10 models for the assessment of the popularity and reliability of the sources based on analysis of meta information about the references in Wikipedia articles, page views and authors of the articles. Using DBpedia and Wikidata we automatically identified the alignment of the sources to a specific domain. Additionally, we analyzed the changes of popularity and reliability in time and identified growth leaders in each of the considered months. The results can be used for quality improvements of the content in different languages versions of Wikipedia. -

Wiki-Reliability: a Large Scale Dataset for Content Reliability on Wikipedia
Wiki-Reliability: A Large Scale Dataset for Content Reliability on Wikipedia KayYen Wong∗ Miriam Redi Diego Saez-Trumper Outreachy Wikimedia Foundation Wikimedia Foundation Kuala Lumpur, Malaysia London, United Kingdom Barcelona, Spain [email protected] [email protected] [email protected] ABSTRACT Wikipedia is the largest online encyclopedia, used by algorithms and web users as a central hub of reliable information on the web. The quality and reliability of Wikipedia content is maintained by a community of volunteer editors. Machine learning and information retrieval algorithms could help scale up editors’ manual efforts around Wikipedia content reliability. However, there is a lack of large-scale data to support the development of such research. To fill this gap, in this paper, we propose Wiki-Reliability, the first dataset of English Wikipedia articles annotated with a wide set of content reliability issues. To build this dataset, we rely on Wikipedia “templates”. Tem- plates are tags used by expert Wikipedia editors to indicate con- Figure 1: Example of an English Wikipedia page with several tent issues, such as the presence of “non-neutral point of view” template messages describing reliability issues. or “contradictory articles”, and serve as a strong signal for detect- ing reliability issues in a revision. We select the 10 most popular 1 INTRODUCTION reliability-related templates on Wikipedia, and propose an effective method to label almost 1M samples of Wikipedia article revisions Wikipedia is one the largest and most widely used knowledge as positive or negative with respect to each template. Each posi- repositories in the world. People use Wikipedia for studying, fact tive/negative example in the dataset comes with the full article checking and a wide set of different information needs [11]. -

Omnipedia: Bridging the Wikipedia Language
Omnipedia: Bridging the Wikipedia Language Gap Patti Bao*†, Brent Hecht†, Samuel Carton†, Mahmood Quaderi†, Michael Horn†§, Darren Gergle*† *Communication Studies, †Electrical Engineering & Computer Science, §Learning Sciences Northwestern University {patti,brent,sam.carton,quaderi}@u.northwestern.edu, {michael-horn,dgergle}@northwestern.edu ABSTRACT language edition contains its own cultural viewpoints on a We present Omnipedia, a system that allows Wikipedia large number of topics [7, 14, 15, 27]. On the other hand, readers to gain insight from up to 25 language editions of the language barrier serves to silo knowledge [2, 4, 33], Wikipedia simultaneously. Omnipedia highlights the slowing the transfer of less culturally imbued information similarities and differences that exist among Wikipedia between language editions and preventing Wikipedia’s 422 language editions, and makes salient information that is million monthly visitors [12] from accessing most of the unique to each language as well as that which is shared information on the site. more widely. We detail solutions to numerous front-end and algorithmic challenges inherent to providing users with In this paper, we present Omnipedia, a system that attempts a multilingual Wikipedia experience. These include to remedy this situation at a large scale. It reduces the silo visualizing content in a language-neutral way and aligning effect by providing users with structured access in their data in the face of diverse information organization native language to over 7.5 million concepts from up to 25 strategies. We present a study of Omnipedia that language editions of Wikipedia. At the same time, it characterizes how people interact with information using a highlights similarities and differences between each of the multilingual lens. -

Title of Thesis: ABSTRACT CLASSIFYING BIAS
ABSTRACT Title of Thesis: CLASSIFYING BIAS IN LARGE MULTILINGUAL CORPORA VIA CROWDSOURCING AND TOPIC MODELING Team BIASES: Brianna Caljean, Katherine Calvert, Ashley Chang, Elliot Frank, Rosana Garay Jáuregui, Geoffrey Palo, Ryan Rinker, Gareth Weakly, Nicolette Wolfrey, William Zhang Thesis Directed By: Dr. David Zajic, Ph.D. Our project extends previous algorithmic approaches to finding bias in large text corpora. We used multilingual topic modeling to examine language-specific bias in the English, Spanish, and Russian versions of Wikipedia. In particular, we placed Spanish articles discussing the Cold War on a Russian-English viewpoint spectrum based on similarity in topic distribution. We then crowdsourced human annotations of Spanish Wikipedia articles for comparison to the topic model. Our hypothesis was that human annotators and topic modeling algorithms would provide correlated results for bias. However, that was not the case. Our annotators indicated that humans were more perceptive of sentiment in article text than topic distribution, which suggests that our classifier provides a different perspective on a text’s bias. CLASSIFYING BIAS IN LARGE MULTILINGUAL CORPORA VIA CROWDSOURCING AND TOPIC MODELING by Team BIASES: Brianna Caljean, Katherine Calvert, Ashley Chang, Elliot Frank, Rosana Garay Jáuregui, Geoffrey Palo, Ryan Rinker, Gareth Weakly, Nicolette Wolfrey, William Zhang Thesis submitted in partial fulfillment of the requirements of the Gemstone Honors Program, University of Maryland, 2018 Advisory Committee: Dr. David Zajic, Chair Dr. Brian Butler Dr. Marine Carpuat Dr. Melanie Kill Dr. Philip Resnik Mr. Ed Summers © Copyright by Team BIASES: Brianna Caljean, Katherine Calvert, Ashley Chang, Elliot Frank, Rosana Garay Jáuregui, Geoffrey Palo, Ryan Rinker, Gareth Weakly, Nicolette Wolfrey, William Zhang 2018 Acknowledgements We would like to express our sincerest gratitude to our mentor, Dr. -

International Journal of Computational Linguistics
International Journal of Computational Linguistics & Chinese Language Processing Aims and Scope International Journal of Computational Linguistics and Chinese Language Processing (IJCLCLP) is an international journal published by the Association for Computational Linguistics and Chinese Language Processing (ACLCLP). This journal was founded in August 1996 and is published four issues per year since 2005. This journal covers all aspects related to computational linguistics and speech/text processing of all natural languages. Possible topics for manuscript submitted to the journal include, but are not limited to: • Computational Linguistics • Natural Language Processing • Machine Translation • Language Generation • Language Learning • Speech Analysis/Synthesis • Speech Recognition/Understanding • Spoken Dialog Systems • Information Retrieval and Extraction • Web Information Extraction/Mining • Corpus Linguistics • Multilingual/Cross-lingual Language Processing Membership & Subscriptions If you are interested in joining ACLCLP, please see appendix for further information. Copyright © The Association for Computational Linguistics and Chinese Language Processing International Journal of Computational Linguistics and Chinese Language Processing is published four issues per volume by the Association for Computational Linguistics and Chinese Language Processing. Responsibility for the contents rests upon the authors and not upon ACLCLP, or its members. Copyright by the Association for Computational Linguistics and Chinese Language Processing. All rights reserved. No part of this journal may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical photocopying, recording or otherwise, without prior permission in writing form from the Editor-in Chief. Cover Calligraphy by Professor Ching-Chun Hsieh, founding president of ACLCLP Text excerpted and compiled from ancient Chinese classics, dating back to 700 B.C. -
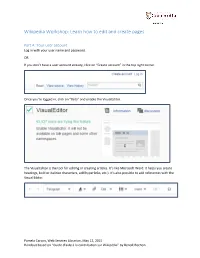
Wikipedia Workshop: Learn How to Edit and Create Pages
Wikipedia Workshop: Learn how to edit and create pages Part A: Your user account Log in with your user name and password. OR If you don’t have a user account already, click on “Create account” in the top right corner. Once you’re logged in, click on “Beta” and enable the VisualEditor. The VisualEditor is the tool for editing or creating articles. It’s like Microsoft Word: it helps you create headings, bold or italicize characters, add hyperlinks, etc.). It’s also possible to add references with the Visual Editor. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part B: Write a sentence or two about yourself Click on your username. This will lead you to your user page. The URL will be: https://en.wikipedia.org/wiki/User:[your user name] Exercise: Click on “Edit source” and write about yourself, then enter a description of your change in the “Edit summary” box and click “Save page”. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part C: Edit an existing article To edit a Wikipedia article, click on the tab “Edit” or “Edit source” (for more advanced users) available at the top of any page. These tabs are also available beside any section title within an article. Editing an entire page Editing just a section Need help? https://en.wikipedia.org/wiki/Wikipedia:Tutorial/Editing Exercise: Go to http://www.statcan.gc.ca/ and find a statistic that interests you. -

The Culture of Wikipedia
Good Faith Collaboration: The Culture of Wikipedia Good Faith Collaboration The Culture of Wikipedia Joseph Michael Reagle Jr. Foreword by Lawrence Lessig The MIT Press, Cambridge, MA. Web edition, Copyright © 2011 by Joseph Michael Reagle Jr. CC-NC-SA 3.0 Purchase at Amazon.com | Barnes and Noble | IndieBound | MIT Press Wikipedia's style of collaborative production has been lauded, lambasted, and satirized. Despite unease over its implications for the character (and quality) of knowledge, Wikipedia has brought us closer than ever to a realization of the centuries-old Author Bio & Research Blog pursuit of a universal encyclopedia. Good Faith Collaboration: The Culture of Wikipedia is a rich ethnographic portrayal of Wikipedia's historical roots, collaborative culture, and much debated legacy. Foreword Preface to the Web Edition Praise for Good Faith Collaboration Preface Extended Table of Contents "Reagle offers a compelling case that Wikipedia's most fascinating and unprecedented aspect isn't the encyclopedia itself — rather, it's the collaborative culture that underpins it: brawling, self-reflexive, funny, serious, and full-tilt committed to the 1. Nazis and Norms project, even if it means setting aside personal differences. Reagle's position as a scholar and a member of the community 2. The Pursuit of the Universal makes him uniquely situated to describe this culture." —Cory Doctorow , Boing Boing Encyclopedia "Reagle provides ample data regarding the everyday practices and cultural norms of the community which collaborates to 3. Good Faith Collaboration produce Wikipedia. His rich research and nuanced appreciation of the complexities of cultural digital media research are 4. The Puzzle of Openness well presented. -
Building a Visual Editor for Wikipedia
Building a Visual Editor for Wikipedia Trevor Parscal and Roan Kattouw Wikimania D.C. 2012 (Introduce yourself) (Introduce yourself) We’d like to talk to you about how we’ve been building a visual editor for Wikipedia Trevor Parscal Roan Kattouw Rob Moen Lead Designer and Engineer Data Model Engineer User Interface Engineer Wikimedia Wikimedia Wikimedia Inez Korczynski Christian Williams James Forrester Edit Surface Engineer Edit Surface Engineer Product Analyst Wikia Wikia Wikimedia The People Wikimania D.C. 2012 We are only 2/6ths of the VisualEditor team Our team includes 2 engineers from Wikia - they also use MediaWiki They also fight crime in their of time Parsoid Team Gabriel Wicke Subbu Sastry Lead Parser Engineer Parser Engineer Wikimedia Wikimedia The People Wikimania D.C. 2012 There’s also two remote people working on a new parser This parser makes what we are doing with the VisualEditor possible The Project Wikimania D.C. 2012 You might recognize this, it’s a Wikipedia article You should edit it! Seems simple enough, just hit the edit button and be on your way... The Complexity Problem Wikimania D.C. 2012 Or not... What is all this nonsense you may ask? Well, it’s called Wikitext! Even really smart people who have a lot to contribute to Wikipedia find it confusing The truth is, Wikitext is a lousy IQ test, and it’s holding Wikipedia back, severely Active Editors 20k 0 2001 2007 Today Growth Stagnation The Complexity Problem Wikimania D.C. 2012 The internet has normal people on it now, not just geeks and weirdoes Normal people like simple things, and simple things are growing fast We must make editing Wikipedia easier to use, not just to grow, but even just to stay alive The Complexity Problem Wikimania D.C.