Wiki-Reliability: a Large Scale Dataset for Content Reliability on Wikipedia
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Position Description Addenda
POSITION DESCRIPTION January 2014 Wikimedia Foundation Executive Director - Addenda The Wikimedia Foundation is a radically transparent organization, and much information can be found at www.wikimediafoundation.org . That said, certain information might be particularly useful to nominators and prospective candidates, including: Announcements pertaining to the Wikimedia Foundation Executive Director Search Kicking off the search for our next Executive Director by Former Wikimedia Foundation Board Chair Kat Walsh An announcement from Wikimedia Foundation ED Sue Gardner by Wikimedia Executive Director Sue Gardner Video Interviews on the Wikimedia Community and Foundation and Its History Some of the values and experiences of the Wikimedia Community are best described directly by those who have been intimately involved in the organization’s dramatic expansion. The following interviews are available for viewing though mOppenheim.TV . • 2013 Interview with Former Wikimedia Board Chair Kat Walsh • 2013 Interview with Wikimedia Executive Director Sue Gardner • 2009 Interview with Wikimedia Executive Director Sue Gardner Guiding Principles of the Wikimedia Foundation and the Wikimedia Community The following article by Sue Gardner, the current Executive Director of the Wikimedia Foundation, has received broad distribution and summarizes some of the core cultural values shared by Wikimedia’s staff, board and community. Topics covered include: • Freedom and open source • Serving every human being • Transparency • Accountability • Stewardship • Shared power • Internationalism • Free speech • Independence More information can be found at: https://meta.wikimedia.org/wiki/User:Sue_Gardner/Wikimedia_Foundation_Guiding_Principles Wikimedia Policies The Wikimedia Foundation has an extensive list of policies and procedures available online at: http://wikimediafoundation.org/wiki/Policies Wikimedia Projects All major projects of the Wikimedia Foundation are collaboratively developed by users around the world using the MediaWiki software. -

Wikibase Knowledge Graphs for Data Management & Data Science
Business and Economics Research Data Center https://www.berd-bw.de Baden-Württemberg Wikibase knowledge graphs for data management & data science Dr. Renat Shigapov 23.06.2021 @shigapov @_shigapov DATA Motivation MANAGEMENT 1. people DATA SCIENCE knowledg! 2. processes information linking 3. technology data things KNOWLEDGE GRAPHS 2 DATA Flow MANAGEMENT Definitions DATA Wikidata & Tools SCIENCE Local Wikibase Wikibase Ecosystem Summary KNOWLEDGE GRAPHS 29.10.2012 2030 2021 3 DATA Example: Named Entity Linking SCIENCE https://commons.wikimedia.org/wiki/File:Entity_Linking_-_Short_Example.png Rule#$as!d problems Machine Learning De!' Learning Learn data science at https://www.kaggle.com 4 https://commons.wikimedia.org/wiki/File:Data_visualization_process_v1.png DATA Example: general MANAGEMENT research data silos data fabric data mesh data space data marketplace data lake data swamp Research data lifecycle https://www.reading.ac.uk/research-services/research-data-management/ 5 https://www.dama.org/cpages/body-of-knowledge about-research-data-management/the-research-data-lifecycle KNOWLEDGE ONTOLOG( + GRAPH = + THINGS https://www.mediawiki.org https://www.wikiba.se ✔ “Things, not strings” by Google, 2012 + ✔ A knowledge graph links things in different datasets https://mariadb.org https://blazegraph.com ✔ A knowledge graph can link people & relational database graph database processes and enhance technologies The main example: “THE KNOWLEDGE GRAPH COOKBOOK RECIPES THAT WORK” by ANDREAS BLUMAUER & HELMUT NAGY, 2020. https://www.wikidata.org -
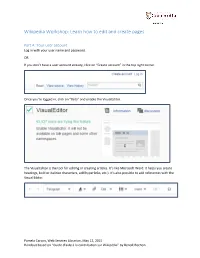
Wikipedia Workshop: Learn How to Edit and Create Pages
Wikipedia Workshop: Learn how to edit and create pages Part A: Your user account Log in with your user name and password. OR If you don’t have a user account already, click on “Create account” in the top right corner. Once you’re logged in, click on “Beta” and enable the VisualEditor. The VisualEditor is the tool for editing or creating articles. It’s like Microsoft Word: it helps you create headings, bold or italicize characters, add hyperlinks, etc.). It’s also possible to add references with the Visual Editor. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part B: Write a sentence or two about yourself Click on your username. This will lead you to your user page. The URL will be: https://en.wikipedia.org/wiki/User:[your user name] Exercise: Click on “Edit source” and write about yourself, then enter a description of your change in the “Edit summary” box and click “Save page”. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part C: Edit an existing article To edit a Wikipedia article, click on the tab “Edit” or “Edit source” (for more advanced users) available at the top of any page. These tabs are also available beside any section title within an article. Editing an entire page Editing just a section Need help? https://en.wikipedia.org/wiki/Wikipedia:Tutorial/Editing Exercise: Go to http://www.statcan.gc.ca/ and find a statistic that interests you. -

How Trust in Wikipedia Evolves: a Survey of Students Aged 11 to 25
PUBLISHED QUARTERLY BY THE UNIVERSITY OF BORÅS, SWEDEN VOL. 23 NO. 1, MARCH, 2018 Contents | Author index | Subject index | Search | Home How trust in Wikipedia evolves: a survey of students aged 11 to 25 Josiane Mothe and Gilles Sahut. Introduction. Whether Wikipedia is to be considered a trusted source is frequently questioned in France. This paper reports the results of a survey examining the levels of trust shown by young people aged eleven to twenty- five. Method. We analyse the answers given by 841 young people, aged eleven to twenty-five, to a questionnaire. To our knowledge, this is the largest study ever published on the topic. It focuses on (1) the perception young people have of Wikipedia; (2) the influence teachers and peers have on the young person’s own opinions; and (3) the variation of trends according to the education level. Analysis. All the analysis is based on ANOVA (analysis of variance) to compare the various groups of participants. We detail the results by comparing the various groups of responders and discuss these results in relation to previous studies. Results. Trust in Wikipedia depends on the type of information seeking tasks and on the education level. There are contrasting social judgments of Wikipedia. Students build a representation of a teacher’s expectations on the nature of the sources that they can use and hence the documentary acceptability of Wikipedia. The average trust attributed to Wikipedia for academic tasks could be induced by the tension between the negative academic reputation of the encyclopedia and the mostly positive experience of its credibility. -
Building a Visual Editor for Wikipedia
Building a Visual Editor for Wikipedia Trevor Parscal and Roan Kattouw Wikimania D.C. 2012 (Introduce yourself) (Introduce yourself) We’d like to talk to you about how we’ve been building a visual editor for Wikipedia Trevor Parscal Roan Kattouw Rob Moen Lead Designer and Engineer Data Model Engineer User Interface Engineer Wikimedia Wikimedia Wikimedia Inez Korczynski Christian Williams James Forrester Edit Surface Engineer Edit Surface Engineer Product Analyst Wikia Wikia Wikimedia The People Wikimania D.C. 2012 We are only 2/6ths of the VisualEditor team Our team includes 2 engineers from Wikia - they also use MediaWiki They also fight crime in their of time Parsoid Team Gabriel Wicke Subbu Sastry Lead Parser Engineer Parser Engineer Wikimedia Wikimedia The People Wikimania D.C. 2012 There’s also two remote people working on a new parser This parser makes what we are doing with the VisualEditor possible The Project Wikimania D.C. 2012 You might recognize this, it’s a Wikipedia article You should edit it! Seems simple enough, just hit the edit button and be on your way... The Complexity Problem Wikimania D.C. 2012 Or not... What is all this nonsense you may ask? Well, it’s called Wikitext! Even really smart people who have a lot to contribute to Wikipedia find it confusing The truth is, Wikitext is a lousy IQ test, and it’s holding Wikipedia back, severely Active Editors 20k 0 2001 2007 Today Growth Stagnation The Complexity Problem Wikimania D.C. 2012 The internet has normal people on it now, not just geeks and weirdoes Normal people like simple things, and simple things are growing fast We must make editing Wikipedia easier to use, not just to grow, but even just to stay alive The Complexity Problem Wikimania D.C. -

Wikipedia Citations: a Comprehensive Data Set of Citations with Identifiers Extracted from English Wikipedia
RESEARCH ARTICLE Wikipedia citations: A comprehensive data set of citations with identifiers extracted from English Wikipedia Harshdeep Singh1 , Robert West1 , and Giovanni Colavizza2 an open access journal 1Data Science Laboratory, EPFL 2Institute for Logic, Language and Computation, University of Amsterdam Keywords: citations, data, data set, Wikipedia Downloaded from http://direct.mit.edu/qss/article-pdf/2/1/1/1906624/qss_a_00105.pdf by guest on 01 October 2021 Citation: Singh, H., West, R., & ABSTRACT Colavizza, G. (2020). Wikipedia citations: A comprehensive data set Wikipedia’s content is based on reliable and published sources. To this date, relatively little of citations with identifiers extracted from English Wikipedia. Quantitative is known about what sources Wikipedia relies on, in part because extracting citations Science Studies, 2(1), 1–19. https:// and identifying cited sources is challenging. To close this gap, we release Wikipedia doi.org/10.1162/qss_a_00105 Citations, a comprehensive data set of citations extracted from Wikipedia. We extracted DOI: 29.3 million citations from 6.1 million English Wikipedia articles as of May 2020, and https://doi.org/10.1162/qss_a_00105 classified as being books, journal articles, or Web content. We were thus able to extract Received: 14 July 2020 4.0 million citations to scholarly publications with known identifiers—including DOI, PMC, Accepted: 23 November 2020 PMID, and ISBN—and further equip an extra 261 thousand citations with DOIs from Crossref. Corresponding Author: As a result, we find that 6.7% of Wikipedia articles cite at least one journal article with Giovanni Colavizza [email protected] an associated DOI, and that Wikipedia cites just 2% of all articles with a DOI currently indexed in the Web of Science. -

FOSDEM 2014 Crowdsourced Translation Using Mediawiki.Key
Crowdsourced translation using MediaWiki Siebrand Mazeland i18n/L10n contractor, Wikimedia Foundation Community Manager, translatewiki.net FOSDEM 2014 | Crowdsourced translation using MediaWiki | February 1, 2014 | Siebrand Mazeland | CC-BY-SA 3.0 Why translate using MediaWiki? Way back in 2004, MediaWiki was already there, and Niklas Laxström had an itch to scratch I.e. it wasn’t given much thought We still don’t regret it Started as a set of patches on MediaWiki core Versioning and tracking included for free Most translators already knew MediaWiki FOSDEM 2014 | Crowdsourced translation using MediaWiki | February 1, 2014 | Siebrand Mazeland | CC-BY-SA 3.0 translatewiki.net Using MediaWiki for localisation translatewiki.net the localisation platform for translation communities, language communities, and free and open source projects Supports online and offline translation for MediaWiki and other software FOSDEM 2014 | Crowdsourced translation using MediaWiki | February 1, 2014 | Siebrand Mazeland | CC-BY-SA 3.0 translatewiki.net Using MediaWiki for localisation FOSDEM 2014 | Crowdsourced translation using MediaWiki | February 1, 2014 | Siebrand Mazeland | CC-BY-SA 3.0 translatewiki.net Using MediaWiki for localisation 6.000 registered translators 25 free and open source projects 48.000 translatable strings 440 active translators per month 55.000 translations per month translators do not handle files FOSDEM 2014 | Crowdsourced translation using MediaWiki | February 1, 2014 | Siebrand Mazeland | CC-BY-SA 3.0 translatewiki.net Supported file -

The History of Mediawiki and the Prospective for the Future
The history of MediaWiki and the prospective for the future Bern, 2017-02-04 Magnus Manske https://commons.wikimedia.org/wiki/File:MediaWiki_talk,_Bern,_2017-02-04,_Magnus_Manske.pdf Overview ● History of MediaWiki, with a focus on Wikimedia ● Usage, extensions and scripts ● Wikidata ● Of course, a few tools Pre-history UseModWiki by Ward Cunningham ● Single file Perl script ● All data stored in file system ● Does not scale well ● No “special pages” beyond Recent Changes ● Default: delete revisions older than two weeks, to save disk space… ● Used for Wikipedia since 2001-01 Phase 2 ● Mea maxima culpa ● Switch on 2002-01-25 ● PHP (for better or worse) ● Using MySQL to store data ● Based on UseModWiki syntax for backwards compatibility Brion Vibber Photo by JayWalsh CC-BY-SA 3.0 Tim Starling Photo by Lane Hartwell Nostalgia Wikipedia screenshot CC-BY-SA 3.0 Phase 3 / MediaWiki ● Massive refactoring/rewrite by Lee Daniel Crocker ● Proper OO, profiling functions ● Known as “Phase 3”, subsequently renamed “MediaWiki” (July 2003) Lee Daniel Crocker Picture by User:Cowtung, CC-BY-SA 3.0 New features since UseModWiki (for Wikipedia) ● Namespaces ● Special Pages with advanced functionality ● Skins ● Local (later: Commons) file upload ● Categories ● Templates ● Parser functions ● Table syntax ● Media viewer ● Visual editor ● Kartograph MediaWiki today ● Most widely used Wiki software ● Over 2,200 extensions ● Customizable via JavaScript gadgets and user scripts ● Comprehensive API Multiple caching mechanisms for large installations (e.g. Wikipedia) -

Lessons from Citizendium
Lessons from Citizendium Wikimania 2009, Buenos Aires, 28 August 2009 HaeB [[de:Benutzer:HaeB]], [[en:User:HaeB]] Please don't take photos during this talk. Citizendium Timeline ● September 2006: Citizendium announced. Sole founder: Larry Sanger, known as former editor-in-chief of Nupedia, chief organizer of Wikipedia (2001-2002), and later as Wikipedia critic ● October 2006: Started non-public pilot phase ● January 2007: “Big Unfork”: All unmodified copies of Wikipedia articles deleted ● March 2007: Public launch ● December 2007: Decision to use CC-BY-3.0, after debate about commercial reuse and compatibility with Wikipedia ● Mid-2009: Sanger largely inactive on Citizendium, focuses on WatchKnow ● August 2009: Larry Sanger announces he will step down as editor-in-chief soon (as committed to in 2006) Citizendium and Wikipedia: Similarities and differences ● Encyclopedia ● Strict real names ● Free license policy ● ● Open (anyone can Special role for contribute) experts: “editors” can issue content ● Created by amateurs decisions, binding to ● MediaWiki-based non-editors collaboration ● Governance: Social ● Non-profit contract, elements of a constitutional republic Wikipedian views of Citizendium ● Competitor for readers, contributions ● Ally, common goal of creating free encyclopedic content ● “Who?” ● In this talk: A long-time experiment testing several fundamental policy changes, in a framework which is still similar enough to that of Wikipedia to generate valuable evidence as to what their effect might be on WP Active editors: Waiting to explode ● Sanger (October 2007): ”At some point, possibly very soon, the Citizendium will grow explosively-- say, quadruple the number of its active contributors, or even grow by an order of magnitude ....“ © Aleksander Stos, CC-BY 3.0 Number of users that made at least one edit in each month Article creation rate: Still muddling Sanger (October 2007): “It's still possible that the project will, from here until eternity, muddle on creating 14 articles per day. -

Reliability of Wikipedia 1 Reliability of Wikipedia
Reliability of Wikipedia 1 Reliability of Wikipedia The reliability of Wikipedia (primarily of the English language version), compared to other encyclopedias and more specialized sources, is assessed in many ways, including statistically, through comparative review, analysis of the historical patterns, and strengths and weaknesses inherent in the editing process unique to Wikipedia. [1] Because Wikipedia is open to anonymous and collaborative editing, assessments of its Vandalism of a Wikipedia article reliability usually include examinations of how quickly false or misleading information is removed. An early study conducted by IBM researchers in 2003—two years following Wikipedia's establishment—found that "vandalism is usually repaired extremely quickly — so quickly that most users will never see its effects"[2] and concluded that Wikipedia had "surprisingly effective self-healing capabilities".[3] A 2007 peer-reviewed study stated that "42% of damage is repaired almost immediately... Nonetheless, there are still hundreds of millions of damaged views."[4] Several studies have been done to assess the reliability of Wikipedia. A notable early study in the journal Nature suggested that in 2005, Wikipedia scientific articles came close to the level of accuracy in Encyclopædia Britannica and had a similar rate of "serious errors".[5] This study was disputed by Encyclopædia Britannica.[6] By 2010 reviewers in medical and scientific fields such as toxicology, cancer research and drug information reviewing Wikipedia against professional and peer-reviewed sources found that Wikipedia's depth and coverage were of a very high standard, often comparable in coverage to physician databases and considerably better than well known reputable national media outlets. -

Academic Research About the Reliability of Wikipedia.Odp
Academic research about the reliability of Wikipedia 台灣維基人冬聚 Taipei, January 7, 2012 T. Bayer Perspective of this talk ● About myself: – Wikipedian since 2003 (User:HaeB on de:, en:) – Editor of The Signpost on en:, 2010-11 – Working for the Foundation since July 2011 (contractor, supporting movement communications) – Editor of the Wikimedia Research Newsletter (together with WMF research analyst Dario Taraborelli): Monthly survey on recent academic research about Wikipedia Reliability of Wikipedia ● Standard criticism: “Wikipedia is not reliable because anyone can edit” – … is fallacious: ● Yes, one traditional quality control method (restrict who can write) is totally missing ● But there is a new quality control method: Anyone can correct mistakes ● But does the new method work? ● Need to examine the content, not the process that leads to it Anecdotes vs. systematic studies ● Seigenthaler scandal (2005, vandalism in biography article). Public opinion problem: Unusual, extreme cases are more newsworthy and memorable – and because of “anyone can edit”, these tend to be negative for WP. ● Scientists are trained not to rely on anecdotes: The 2005 Nature study ● “first [study] to use peer review to compare Wiki- pedia and Britannica’s coverage of science” ● 42 reviews by experts ● Errors per article: Wikipedia 4 , Britannica 3 ● Britannica protested, Nature stood by it ● 6 years later, still the most frequently cited study about Wikipedia's reliability ●Brockhaus – “the” German encyclopedia ● “generally regarded as the model for the development of many encyclopaedias in other languages” (Britannica entry “Brockhaus Enzyklopädie”) ● 1796: First edition ● 2005: 21st edition (30 volumes) ● 2009: Editorial staff dismissed, brand sold Stern (news magazine) study, 2007 ● Compared 50 random articles in German Wikipedia and Brockhaus ● Not peer-reviewed, but conducted by experienced research institute ● Wide range of topics ● Wikipedia more accurate: Brockhaus 2.3 vs. -

Semantic Mediawiki in Operation: Experiences with Building a Semantic Portal
Semantic MediaWiki in Operation: Experiences with Building a Semantic Portal Daniel M. Herzig and Basil Ell Institute AIFB Karlsruhe Institute of Technology 76128 Karlsruhe, Germany fherzig, [email protected] http://www.aifb.kit.edu Abstract. Wikis allow users to collaboratively create and maintain con- tent. Semantic wikis, which provide the additional means to annotate the content semantically and thereby allow to structure it, experience an enormous increase in popularity, because structured data is more us- able and thus more valuable than unstructured data. As an illustration of leveraging the advantages of semantic wikis for semantic portals, we report on the experience with building the AIFB portal based on Seman- tic MediaWiki. We discuss the design, in particular how free, wiki-style semantic annotations and guided input along a predefined schema can be combined to create a flexible, extensible, and structured knowledge representation. How this structured data evolved over time and its flex- ibility regarding changes are subsequently discussed and illustrated by statistics based on actual operational data of the portal. Further, the features exploiting the structured data and the benefits they provide are presented. Since all benefits have its costs, we conducted a performance study of the Semantic MediaWiki and compare it to MediaWiki, the non- semantic base platform. Finally we show how existing caching techniques can be applied to increase the performance. 1 Introduction Web portals are entry points for information presentation and exchange over the Internet about a certain topic or organization, usually powered by a community. Leveraging semantic technologies for portals and exploiting semantic content has been proven useful in the past [1] and especially the aspect of providing seman- tic data got a lot of attention lately due to the Linked Open Data initiative.