Concepts of Programming Languages, Eleventh Edition, Global Edition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Configuring UNIX-Specific Settings: Creating Symbolic Links : Snap
Configuring UNIX-specific settings: Creating symbolic links Snap Creator Framework NetApp September 23, 2021 This PDF was generated from https://docs.netapp.com/us-en/snap-creator- framework/installation/task_creating_symbolic_links_for_domino_plug_in_on_linux_and_solaris_hosts.ht ml on September 23, 2021. Always check docs.netapp.com for the latest. Table of Contents Configuring UNIX-specific settings: Creating symbolic links . 1 Creating symbolic links for the Domino plug-in on Linux and Solaris hosts. 1 Creating symbolic links for the Domino plug-in on AIX hosts. 2 Configuring UNIX-specific settings: Creating symbolic links If you are going to install the Snap Creator Agent on a UNIX operating system (AIX, Linux, and Solaris), for the IBM Domino plug-in to work properly, three symbolic links (symlinks) must be created to link to Domino’s shared object files. Installation procedures vary slightly depending on the operating system. Refer to the appropriate procedure for your operating system. Domino does not support the HP-UX operating system. Creating symbolic links for the Domino plug-in on Linux and Solaris hosts You need to perform this procedure if you want to create symbolic links for the Domino plug-in on Linux and Solaris hosts. You should not copy and paste commands directly from this document; errors (such as incorrectly transferred characters caused by line breaks and hard returns) might result. Copy and paste the commands into a text editor, verify the commands, and then enter them in the CLI console. The paths provided in the following steps refer to the 32-bit systems; 64-bit systems must create simlinks to /usr/lib64 instead of /usr/lib. -
Administering Unidata on UNIX Platforms
C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\ADMINUNIX\ADMINUNIXTITLE.fm March 5, 2010 1:34 pm Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta UniData Administering UniData on UNIX Platforms UDT-720-ADMU-1 C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\ADMINUNIX\ADMINUNIXTITLE.fm March 5, 2010 1:34 pm Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Notices Edition Publication date: July, 2008 Book number: UDT-720-ADMU-1 Product version: UniData 7.2 Copyright © Rocket Software, Inc. 1988-2010. All Rights Reserved. Trademarks The following trademarks appear in this publication: Trademark Trademark Owner Rocket Software™ Rocket Software, Inc. Dynamic Connect® Rocket Software, Inc. RedBack® Rocket Software, Inc. SystemBuilder™ Rocket Software, Inc. UniData® Rocket Software, Inc. UniVerse™ Rocket Software, Inc. U2™ Rocket Software, Inc. U2.NET™ Rocket Software, Inc. U2 Web Development Environment™ Rocket Software, Inc. wIntegrate® Rocket Software, Inc. Microsoft® .NET Microsoft Corporation Microsoft® Office Excel®, Outlook®, Word Microsoft Corporation Windows® Microsoft Corporation Windows® 7 Microsoft Corporation Windows Vista® Microsoft Corporation Java™ and all Java-based trademarks and logos Sun Microsystems, Inc. UNIX® X/Open Company Limited ii SB/XA Getting Started The above trademarks are property of the specified companies in the United States, other countries, or both. All other products or services mentioned in this document may be covered by the trademarks, service marks, or product names as designated by the companies who own or market them. License agreement This software and the associated documentation are proprietary and confidential to Rocket Software, Inc., are furnished under license, and may be used and copied only in accordance with the terms of such license and with the inclusion of the copyright notice. -

Typology of Programming Languages E Early Languages E
Typology of programming languages e Early Languages E Typology of programming languages Early Languages 1 / 71 The Tower of Babel Typology of programming languages Early Languages 2 / 71 Table of Contents 1 Fortran 2 ALGOL 3 COBOL 4 The second wave 5 The finale Typology of programming languages Early Languages 3 / 71 IBM Mathematical Formula Translator system Fortran I, 1954-1956, IBM 704, a team led by John Backus. Typology of programming languages Early Languages 4 / 71 IBM 704 (1956) Typology of programming languages Early Languages 5 / 71 IBM Mathematical Formula Translator system The main goal is user satisfaction (economical interest) rather than academic. Compiled language. a single data structure : arrays comments arithmetics expressions DO loops subprograms and functions I/O machine independence Typology of programming languages Early Languages 6 / 71 FORTRAN’s success Because: programmers productivity easy to learn by IBM the audience was mainly scientific simplifications (e.g., I/O) Typology of programming languages Early Languages 7 / 71 FORTRAN I C FIND THE MEAN OF N NUMBERS AND THE NUMBER OF C VALUES GREATER THAN IT DIMENSION A(99) REAL MEAN READ(1,5)N 5 FORMAT(I2) READ(1,10)(A(I),I=1,N) 10 FORMAT(6F10.5) SUM=0.0 DO 15 I=1,N 15 SUM=SUM+A(I) MEAN=SUM/FLOAT(N) NUMBER=0 DO 20 I=1,N IF (A(I) .LE. MEAN) GOTO 20 NUMBER=NUMBER+1 20 CONTINUE WRITE (2,25) MEAN,NUMBER 25 FORMAT(11H MEAN = ,F10.5,5X,21H NUMBER SUP = ,I5) STOP TypologyEND of programming languages Early Languages 8 / 71 Fortran on Cards Typology of programming languages Early Languages 9 / 71 Fortrans Typology of programming languages Early Languages 10 / 71 Table of Contents 1 Fortran 2 ALGOL 3 COBOL 4 The second wave 5 The finale Typology of programming languages Early Languages 11 / 71 ALGOL, Demon Star, Beta Persei, 26 Persei Typology of programming languages Early Languages 12 / 71 ALGOL 58 Originally, IAL, International Algebraic Language. -

Marcelo Camargo (Haskell Camargo) – Résumé Projects
Marcelo Camargo (Haskell Camargo) – Résumé https://github.com/haskellcamargo [email protected] http://coderbits.com/haskellcamargo Based in Joinville / SC – Brazil Knowledge • Programming languages domain: ◦ Ada, AdvPL, BASIC, C, C++, C#, Clipper, Clojure, CoffeeScript, Common LISP, Elixir, Erlang, F#, FORTRAN, Go, Harbour, Haskell, Haxe, Hy, Java, JavaScript, Ink, LiveScript, Lua, MATLAB, Nimrod, OCaml, Pascal, PHP, PogoScript, Processing, PureScript, Python, Ruby, Rust, Self, Shell, Swift, TypeScript, VisualBasic [.NET], Whip, ZPL. • Markup, style and serialization languages: ◦ Markdown, reStructuredText, [X] HTML, XML, CSS, LESS, SASS, Stylus, Yaml, JSON, DSON. • Database management systems: ◦ Oracle, MySQL, SQL Server, IBM DB2, PostgreSQL. • Development for operating systems: ◦ Unix based, Windows (CE mobile included), Android, Firefox OS. • Parsers and compilers: ◦ Macros: ▪ Sweet.js, preprocessor directives. ◦ Parser and scanner generators: ▪ ANTLR, PEG.js, Jison, Flex, re2c, Lime. • Languages: ◦ Portuguese (native) ◦ English (native) ◦ Spanish (fluent) ◦ French (fluent) ◦ Turkish (intermediate) ◦ Chinese (mandarin) (intermediate) ◦ Esperanto (intermediate) Projects • Prelude AdvPL – a library that implements functional programming in AdvPL and extends its syntax to a more expressive one; it's a port of Haskell's Prelude; • Frida – a LISP dialect that runs on top of Node.js; • PHPP – A complete PHP preprocessor with a grammar able to identify and replace tokens and extend/modify the language syntax, meant to be implemented -

Installing Visual Flagship for MS-Windows
First Steps with Visual FlagShip 8 for MS-Windows 1. Requirements This instruction applies for FlagShip port using Microsoft Visual Studio 2017 (any edition, also the free Community), or the Visual Studio 2015. The minimal requirements are: • Microsoft Windows 32bit or 64bit operating system like Windows-10 • 2 GB RAM (more is recommended for performance) • 300 MB free hard disk space • Installed Microsoft MS-Visual Studio 2017 or 2015 (see step 2). It is re- quired for compiling .c sources and to link with corresponding FlagShip library. This FlagShip version will create 32bit or 64bit objects and native executables (.exe files) applicable for MS-Windows 10 and newer. 2. Install Microsoft Visual Studio 2017 or 2015 If not available yet, download and install Microsoft Visual Studio, see this link for details FlagShip will use only the C/C++ (MS-VC) compiler and linker from Visual Studio 2017 (or 2015) to create 64-bit and/or 32- bit objects and executables from your sources. Optionally, check the availability and the correct version of MS-VC compiler in CMD window (StartRuncmd) by invoking C:\> cd "C:\Program Files (x86)\Microsoft Visual Studio\ 2017\Community\VC\Tools\MSVC\14.10.25017\bin\HostX64\x64" C:\> CL.exe should display: Microsoft (R) C/C++ Optimizing Compiler Version 19.10.25019 for x64 Don’t worry if you can invoke CL.EXE only directly with the path, FlagShip’s Setup will set the proper path for you. Page 1 3. Download FlagShip In your preferred Web-Browser, open http://www.fship.com/windows.html and download the Visual FlagShip setup media using MS-VisualStudio and save it to any folder of your choice. -

Types and Programming Languages by Benjamin C
< Free Open Study > . .Types and Programming Languages by Benjamin C. Pierce ISBN:0262162091 The MIT Press © 2002 (623 pages) This thorough type-systems reference examines theory, pragmatics, implementation, and more Table of Contents Types and Programming Languages Preface Chapter 1 - Introduction Chapter 2 - Mathematical Preliminaries Part I - Untyped Systems Chapter 3 - Untyped Arithmetic Expressions Chapter 4 - An ML Implementation of Arithmetic Expressions Chapter 5 - The Untyped Lambda-Calculus Chapter 6 - Nameless Representation of Terms Chapter 7 - An ML Implementation of the Lambda-Calculus Part II - Simple Types Chapter 8 - Typed Arithmetic Expressions Chapter 9 - Simply Typed Lambda-Calculus Chapter 10 - An ML Implementation of Simple Types Chapter 11 - Simple Extensions Chapter 12 - Normalization Chapter 13 - References Chapter 14 - Exceptions Part III - Subtyping Chapter 15 - Subtyping Chapter 16 - Metatheory of Subtyping Chapter 17 - An ML Implementation of Subtyping Chapter 18 - Case Study: Imperative Objects Chapter 19 - Case Study: Featherweight Java Part IV - Recursive Types Chapter 20 - Recursive Types Chapter 21 - Metatheory of Recursive Types Part V - Polymorphism Chapter 22 - Type Reconstruction Chapter 23 - Universal Types Chapter 24 - Existential Types Chapter 25 - An ML Implementation of System F Chapter 26 - Bounded Quantification Chapter 27 - Case Study: Imperative Objects, Redux Chapter 28 - Metatheory of Bounded Quantification Part VI - Higher-Order Systems Chapter 29 - Type Operators and Kinding Chapter 30 - Higher-Order Polymorphism Chapter 31 - Higher-Order Subtyping Chapter 32 - Case Study: Purely Functional Objects Part VII - Appendices Appendix A - Solutions to Selected Exercises Appendix B - Notational Conventions References Index List of Figures < Free Open Study > < Free Open Study > Back Cover A type system is a syntactic method for automatically checking the absence of certain erroneous behaviors by classifying program phrases according to the kinds of values they compute. -

Object-Oriented Programming Basics with Java
Object-Oriented Programming Object-Oriented Programming Basics With Java In his keynote address to the 11th World Computer Congress in 1989, renowned computer scientist Donald Knuth said that one of the most important lessons he had learned from his years of experience is that software is hard to write! Computer scientists have struggled for decades to design new languages and techniques for writing software. Unfortunately, experience has shown that writing large systems is virtually impossible. Small programs seem to be no problem, but scaling to large systems with large programming teams can result in $100M projects that never work and are thrown out. The only solution seems to lie in writing small software units that communicate via well-defined interfaces and protocols like computer chips. The units must be small enough that one developer can understand them entirely and, perhaps most importantly, the units must be protected from interference by other units so that programmers can code the units in isolation. The object-oriented paradigm fits these guidelines as designers represent complete concepts or real world entities as objects with approved interfaces for use by other objects. Like the outer membrane of a biological cell, the interface hides the internal implementation of the object, thus, isolating the code from interference by other objects. For many tasks, object-oriented programming has proven to be a very successful paradigm. Interestingly, the first object-oriented language (called Simula, which had even more features than C++) was designed in the 1960's, but object-oriented programming has only come into fashion in the 1990's. -

Constructive Design of a Hierarchy of Semantics of a Transition System by Abstract Interpretation
1 Constructive Design of a Hierarchy of Semantics of a Transition System by Abstract Interpretation Patrick Cousota aD´epartement d’Informatique, Ecole´ Normale Sup´erieure, 45 rue d’Ulm, 75230 Paris cedex 05, France, [email protected], http://www.di.ens.fr/~cousot We construct a hierarchy of semantics by successive abstract interpretations. Starting from the maximal trace semantics of a transition system, we derive the big-step seman- tics, termination and nontermination semantics, Plotkin’s natural, Smyth’s demoniac and Hoare’s angelic relational semantics and equivalent nondeterministic denotational se- mantics (with alternative powerdomains to the Egli-Milner and Smyth constructions), D. Scott’s deterministic denotational semantics, the generalized and Dijkstra’s conser- vative/liberal predicate transformer semantics, the generalized/total and Hoare’s partial correctness axiomatic semantics and the corresponding proof methods. All the semantics are presented in a uniform fixpoint form and the correspondences between these seman- tics are established through composable Galois connections, each semantics being formally calculated by abstract interpretation of a more concrete one using Kleene and/or Tarski fixpoint approximation transfer theorems. Contents 1 Introduction 2 2 Abstraction of Fixpoint Semantics 3 2.1 Fixpoint Semantics ............................... 3 2.2 Fixpoint Semantics Approximation ...................... 4 2.3 Fixpoint Semantics Transfer .......................... 5 2.4 Semantics Abstraction ............................. 7 2.5 Fixpoint Semantics Fusion ........................... 8 2.6 Fixpoint Iterates Reordering .......................... 8 3 Transition/Small-Step Operational Semantics 9 4 Finite and Infinite Sequences 9 4.1 Sequences .................................... 9 4.2 Concatenation of Sequences .......................... 10 4.3 Junction of Sequences ............................. 10 5 Maximal Trace Semantics 10 2 5.1 Fixpoint Finite Trace Semantics ....................... -

Introduction for Position ID Senior C++ Developer 11611
Introduction for position Senior C++ Developer ID 11611 CURRICULUM VITAE Place of Residence Stockholm Profile A C++ programming expert with consistent success on difficult tasks. Expert in practical use of C++ (25+ years), C++11, C++14, C++17 integration with C#, Solid Windows, Linux, Minimal SQL. Dated experience with other languages, including assemblers. Worked in a number of domains, including finance, business and industrial automation, software development tools. Skills & Competences - Expert with consistent success on difficult tasks, dedicated and team lead in various projects. - Problems solving quickly, sometimes instantly; - Manage how to work under pressure. Application Software - Excellent command of the following software: Solid Windows, Linux. Minimal SQL. - Use of C++ (25+ years), C++11, C++14, C++17 integration with C#. Education High School Work experience Sep 2018 – Present Expert C++ Programmer – Personal Project Your tasks/responsibilities - Continuing personal project: writing a parser for C++ language, see motivation in this CV after the Saxo Bank job. - Changed implementation language from Scheme to C++. Implemented a C++ preprocessor of decent quality, extractor of compiler options from a MS Visual Studio projects. - Generated the formal part of the parser from a publicly available grammar. - Implemented “pack rat” optimization for the (recursive descent) parser. - Implementing a parsing context data structure efficient for recursive descent approach; the C++ name lookup algorithm.- Implementing a parsing context data structure efficient for recursive descent approach; the C++ name lookup algorithm. May 2015 – Sep 2018 C++ Programmer - Stockholm Your tasks/responsibilities - Provided C++ expertise to an ambitious company developing a fast database engine and a business software platform. -

Simula Mother Tongue for a Generation of Nordic Programmers
Simula! Mother Tongue! for a Generation of! Nordic Programmers! Yngve Sundblad HCI, CSC, KTH! ! KTH - CSC (School of Computer Science and Communication) Yngve Sundblad – Simula OctoberYngve 2010Sundblad! Inspired by Ole-Johan Dahl, 1931-2002, and Kristen Nygaard, 1926-2002" “From the cold waters of Norway comes Object-Oriented Programming” " (first line in Bertrand Meyer#s widely used text book Object Oriented Software Construction) ! ! KTH - CSC (School of Computer Science and Communication) Yngve Sundblad – Simula OctoberYngve 2010Sundblad! Simula concepts 1967" •# Class of similar Objects (in Simula declaration of CLASS with data and actions)! •# Objects created as Instances of a Class (in Simula NEW object of class)! •# Data attributes of a class (in Simula type declared as parameters or internal)! •# Method attributes are patterns of action (PROCEDURE)! •# Message passing, calls of methods (in Simula dot-notation)! •# Subclasses that inherit from superclasses! •# Polymorphism with several subclasses to a superclass! •# Co-routines (in Simula Detach – Resume)! •# Encapsulation of data supporting abstractions! ! KTH - CSC (School of Computer Science and Communication) Yngve Sundblad – Simula OctoberYngve 2010Sundblad! Simula example BEGIN! REF(taxi) t;" CLASS taxi(n); INTEGER n;! BEGIN ! INTEGER pax;" PROCEDURE book;" IF pax<n THEN pax:=pax+1;! pax:=n;" END of taxi;! t:-NEW taxi(5);" t.book; t.book;" print(t.pax)" END! Output: 7 ! ! KTH - CSC (School of Computer Science and Communication) Yngve Sundblad – Simula OctoberYngve 2010Sundblad! -
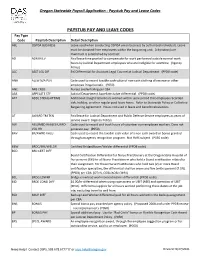
Oregon Statewide Payroll Application ‐ Paystub Pay and Leave Codes
Oregon Statewide Payroll Application ‐ Paystub Pay and Leave Codes PAYSTUB PAY AND LEAVE CODES Pay Type Code Paystub Description Detail Description ABL OSPOA BUSINESS Leave used when conducting OSPOA union business by authorized individuals. Leave must be donated from employees within the bargaining unit. A donation/use maximum is established by contract. AD ADMIN LV Paid leave time granted to compensate for work performed outside normal work hours by Judicial Department employees who are ineligible for overtime. (Agency Policy) ALC ASST LGL DIF 5% Differential for Assistant Legal Counsel at Judicial Department. (PPDB code) ANA ALLW N/A PLN Code used to record taxable cash value of non-cash clothing allowance or other employee fringe benefit. (P050) ANC NRS CRED Nurses credentialing per CBA ASA APPELATE STF Judicial Department Appellate Judge differential. (PPDB code) AST ADDL STRAIGHTTIME Additional straight time hours worked within same period that employee recorded sick, holiday, or other regular paid leave hours. Refer to Statewide Policy or Collective Bargaining Agreement. Hours not used in leave and benefit calculations. AT AWARD TM TKN Paid leave for Judicial Department and Public Defense Service employees as years of service award. (Agency Policy) AW ASSUMED WAGES-UNPD Code used to record and track hours of volunteer non-employee workers. Does not VOL HR generate pay. (P050) BAV BP/AWRD VALU Code used to record the taxable cash value of a non-cash award or bonus granted through an agency recognition program. Not PERS subject. (P050 code) BBW BRDG/BM/WELDR Certified Bridge/Boom/Welder differential (PPDB code) BCD BRD CERT DIFF Board Certification Differential for Nurse Practitioners at the Oregon State Hospital of five percent (5%) for all Nurse Practitioners who hold a Board certification related to their assignment. -

Small Group Instructional Diagnosis: Final Report
DOCUMENT RESUME JC 820 333 , ED 217 954 AUTHOR Clark, D. Joseph; Redmond, Mark V. TITLE Small Group Instructional Diagnosis: Final Report. INSTITUTION Washington Univ., Seattle. Dept. of Biology c Education. ., 'SPONS AGENCY Fund for the Improwsent of Postsecondary Education . (ED), Washington, D.C. , PUB DATE [82] NOTE 21p.; Appendices mentioned in the report are not _ included. EDRS PRICE , 401/PC01 Plus Postage. DESCRIPTORS *Course Evaluation; *Evaluation Methods; *Instructional Improvement; Postsecondary Education; *Student Evaluation of Teacher Performance;- tudent , Reaction; *Teacher Attitudes; Teacher Workshop IDENTIFIERS *Small group Instructional Diagnosis, ABSTRACT- A procedure for student evaluation andfeedback on faculty instruction was developed at the University of Washington. The system involved the use of,faculty members as facilitatorsin ,conducting Small Group Instructional Diagnosis (SGID) to generate student feedback to instructors about- the courses' strengths, areas needing improvement, and suggestions for bringing about these improvements. The SGID.procedure involves a number of steps:contact between the facilitator and instructor; classroomintervention to ascertain student opinions; a feedback session between facilitator and instructor; instructor. review of the SGID with the class;and ,a follow-up session between the facilitator and instructor.Following the development of the SGID process, handouts andvideotapes were produced to explain the procedure and the SGID technique was demonstrated in over 130 classes