Learning to Communicate Implicitly by Actions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introducion to Duplicate
INTRODUCTION to DUPLICATE INTRODUCTION TO DUPLICATE BRIDGE This book is not about how to bid, declare or defend a hand of bridge. It assumes you know how to do that or are learning how to do those things elsewhere. It is your guide to playing Duplicate Bridge, which is how organized, competitive bridge is played all over the World. It explains all the Laws of Duplicate and the process of entering into Club games or Tournaments, the Convention Card, the protocols and rules of player conduct; the paraphernalia and terminology of duplicate. In short, it’s about the context in which duplicate bridge is played. To become an accomplished duplicate player, you will need to know everything in this book. But you can start playing duplicate immediately after you read Chapter I and skim through the other Chapters. © ACBL Unit 533, Palm Springs, Ca © ACBL Unit 533, 2018 Pg 1 INTRODUCTION to DUPLICATE This book belongs to Phone Email I joined the ACBL on ____/____ /____ by going to www.ACBL.com and signing up. My ACBL number is __________________ © ACBL Unit 533, 2018 Pg 2 INTRODUCTION to DUPLICATE Not a word of this book is about how to bid, play or defend a bridge hand. It assumes you have some bridge skills and an interest in enlarging your bridge experience by joining the world of organized bridge competition. It’s called Duplicate Bridge. It’s the difference between a casual Saturday morning round of golf or set of tennis and playing in your Club or State championships. As in golf or tennis, your skills will be tested in competition with others more or less skilled than you; this book is about the settings in which duplicate happens. -

Acol Bidding Notes
SECTION 1 - INTRODUCTION The following notes are designed to help your understanding of the Acol system of bidding and should be used in conjunction with Crib Sheets 1 to 5 and the Glossary of Terms The crib sheets summarise the bidding in tabular form, whereas these notes provide a fuller explanation of the reasons for making particular bids and bidding strategy. These notes consist of a number of short chapters that have been structured in a logical order to build on the things learnt in the earlier chapters. However, each chapter can be viewed as a mini-lesson on a specific area which can be read in isolation rather than trying to absorb too much information in one go. It should be noted that there is not a single set of definitive Acol ‘rules’. The modern Acol bidding style has developed over the years and different bridge experts recommend slightly different variations based on their personal preferences and playing experience. These notes are based on the methods described in the book The Right Way to Play Bridge by Paul Mendelson, which is available at all good bookshops (and some rubbish ones as well). They feature a ‘Weak No Trump’ throughout and ‘Strong Two’ openings. +++++++++++++++++++++++++++++++++++++ INDEX Section 1 Introduction Chapter 1 Bidding objectives & scoring Chapter 2 Evaluating the strength of your hand Chapter 3 Evaluating the shape of your hand . Section 2 Balanced Hands Chapter 21 1NT opening bid & No Trumps responses Chapter 22 1NT opening bid & suit responses Chapter 23 Opening bids with stronger balanced hands Chapter 24 Supporting responder’s major suit Chapter 25 2NT opening bid & responses Chapter 26 2 Clubs opening bid & responses Chapter 27 No Trumps responses after an opening suit bid Chapter 28 Summary of bidding with Balanced Hands . -
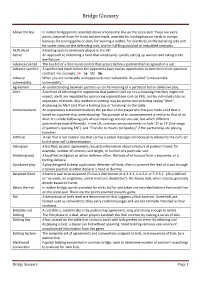
Bridge Glossary
Bridge Glossary Above the line In rubber bridge points recorded above a horizontal line on the score-pad. These are extra points, beyond those for tricks bid and made, awarded for holding honour cards in trumps, bonuses for scoring game or slam, for winning a rubber, for overtricks on the declaring side and for under-tricks on the defending side, and for fulfilling doubled or redoubled contracts. ACOL/Acol A bidding system commonly played in the UK. Active An approach to defending a hand that emphasizes quickly setting up winners and taking tricks. See Passive Advance cue bid The cue bid of a first round control that occurs before a partnership has agreed on a suit. Advance sacrifice A sacrifice bid made before the opponents have had an opportunity to determine their optimum contract. For example: 1♦ - 1♠ - Dbl - 5♠. Adverse When you are vulnerable and opponents non-vulnerable. Also called "unfavourable vulnerability vulnerability." Agreement An understanding between partners as to the meaning of a particular bid or defensive play. Alert A method of informing the opponents that partner's bid carries a meaning that they might not expect; alerts are regulated by sponsoring organizations such as EBU, and by individual clubs or organisers of events. Any method of alerting may be authorised including saying "Alert", displaying an Alert card from a bidding box or 'knocking' on the table. Announcement An explanatory statement made by the partner of the player who has just made a bid that is based on a partnership understanding. The purpose of an announcement is similar to that of an Alert. -

C.C.Tatham & Associates Ltd
C.C.Tatham & Associates Ltd. Consulting Engineers STEPHENSON ROAD I BRIDGE Town of Bracebridge ond Town of H u ntsville Municipol Closs Environmentol Assessment Proiect File prepared by: prepared for C.C. Tatham & Associates Ltd. The Town of Bracebridge and the Town of Huntsville I Banon Drive Bracebridge, ON P1L 0A1 November 17,2014 Tel: (705) 645-7756 Fax: (705)645-8'159 [email protected] CCTA File 212529-1 Toble of Contents 1 lntroduction and Background 1 1.1 I nhoduction/Backg rou nd I 1.2 Class Environmental Assessment Process 2 1.2.1 Class EA Schedules 2 1.2.2 Class EA Terminology 4 1.2.3 SelectedSchedule 4 2 Need & Justification 6 2.1 Existing Conditions and Background 6 2.1.1 StructuralCondition 7 2.1.2 TrafficConditions 10 2.1.3 Utilities 10 2.1.4 HydraulicAssessment 10 2.1.5 Geometry 11 21.6 BarrierProtection 11 2.2 Problem/Opportun ity Statement 11 3 Gonsultation - Study Commencement 12 3,1 Notification 12 3.2 Public Comments 12 3.3 Agency Comments 13 4 Alternative Solutions '14 4.1 Alternative 1 - Do Nothing 14 4.2 Alternative 2 - Rehabilitate the Bridge 4,3 Alternative 3 - Replace the Bridge 5 Environment lnventory 5.1 Natural Environment 5.2 Social Environment 5.2.1 Archaeological lnvestigation 5.2.2 Cultural Heritage Evaluation Report 5.2.3 Property Acquisition 5.3 Physical Environment 5.3.1 Existing Bridge Structure 5.3.2 Existing Approaches 5,3,3 Traffic Operations 5,3,4 Utilities 5.3.5 Hydraulics 5.3.6 Barriers 5.3.7 Geotechnical Considerations 5.4 Economic Environment 6 Evaluation of Alternative Solutions 6.1 Evaluation -

Bridge for Dummies‰
01_924261 ffirs.qxp 8/17/06 2:49 PM Page i Bridge FOR DUMmIES‰ 2ND EDITION by Eddie Kantar 01_924261 ffirs.qxp 8/17/06 2:49 PM Page iv 01_924261 ffirs.qxp 8/17/06 2:49 PM Page i Bridge FOR DUMmIES‰ 2ND EDITION by Eddie Kantar 01_924261 ffirs.qxp 8/17/06 2:49 PM Page ii Bridge For Dummies®, 2nd Edition Published by Wiley Publishing, Inc. 111 River St. Hoboken, NJ 07030-5774 www.wiley.com Copyright © 2006 by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permis- sion of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, 978-750-8400, fax 978-646-8600. Requests to the Publisher for permission should be addressed to the Legal Department, Wiley Publishing, Inc., 10475 Crosspoint Blvd., Indianapolis, IN 46256, 317-572-3447, fax 317-572-4355, or online at http://www. wiley.com/go/permissions. Trademarks: Wiley, the Wiley Publishing logo, For Dummies, the Dummies Man logo, A Reference for the Rest of Us!, The Dummies Way, Dummies Daily, The Fun and Easy Way, Dummies.com and related trade dress are trademarks or registered trademarks of John Wiley & Sons, Inc. and/or its affiliates in the United States and other countries, and may not be used without written permission. -

Beat Them at the One Level Eastbourne Epic
National Poetry Day Tablet scoring - the rhyme and reason Rosen - beat them at the one level Byrne - Ode to two- suited overcalls Gold - time to jump shift? Eastbourne Epic – winners and pictures English Bridge INSIDE GUIDE © All rights reserved From the Chairman 5 n ENGLISH BRIDGE Major Jump Shifts – David Gold 6 is published every two months by the n Heather’s Hints – Heather Dhondy 8 ENGLISH BRIDGE UNION n Bridge Fiction – David Bird 10 n Broadfields, Bicester Road, Double, Bid or Pass? – Andrew Robson 12 Aylesbury HP19 8AZ n Prize Leads Quiz – Mould’s questions 14 n ( 01296 317200 Fax: 01296 317220 Add one thing – Neil Rosen N 16 [email protected] EW n Web site: www.ebu.co.uk Basic Card Play – Paul Bowyer 18 n ________________ Two-suit overcalls – Michael Byrne 20 n World Bridge Games – David Burn 22 Editor: Lou Hobhouse n Raggett House, Bowdens, Somerset, TA10 0DD Ask Frances – Frances Hinden 24 n Beat Today’s Experts – Bird’s questions 25 ( 07884 946870 n [email protected] Sleuth’s Quiz – Ron Klinger’s questions 27 n ________________ Bridge with a Twist – Simon Cochemé 28 n Editorial Board Pairs vs Teams – Simon Cope 30 n Jeremy Dhondy (Chairman), Bridge Ha Ha & Caption Competition 32 n Barry Capal, Lou Hobhouse, Peter Stockdale Poetry special – Various 34 n ________________ Electronic scoring review – Barry Morrison 36 n Advertising Manager Eastbourne results and pictures 38 n Chris Danby at Danby Advertising EBU News, Eastbourne & Calendar 40 n Fir Trees, Hall Road, Hainford, Ask Gordon – Gordon Rainsford 42 n Norwich NR10 3LX -

Introduction to Bridge Scoring and Bidding
Introduction to Bridge Scoring and Bidding By Matthew Kidd Bridge is about taking tricks. On each hand, one partnership promises (“contracts”) to take at least a certain number of tricks, often aided by a trump suit but sometimes without the help of a trump suit, i.e. in a notrump contract. Each trick taken beyond the 6th trick is worth a small amount: 20 points if the trump suit is clubs or diamonds, 30 if the trump suit is hearts or spades, and 30 if there is no trump suit, except that in no trump the first trick is worth 40 points. But the big money comes from the game bonus of 300 or 500 when the value of your tricks equals or exceeds 100. Therefore the minimum game levels are: 3 NT 40 + 30 + 30 = 100 NT = no trump 4♠/4♥ 30 x 4 = 120 > 100 ♠ and ♥ are the major suits 5♦/♣ 20 x 5 = 100 ♦ and ♣ are the minor suits You must bid to the game level or higher to get the game bonus. For example, if you bid to 3♠ and take 10 tricks, you will only score 4 x 30 = 120 + the small part-score bonus of 50 points for a total of 170. Bidding 4♠ and taking the same 10 tricks would have been worth either 420 or 620 (4 x 30 + 300 or 500). The different game bonus values depend on something called the vulnerability which comes from the old rubber bridge form of scoring. A rubber ends after one partnership scores two games. -

Surrey County Bridge Association Newsletter #17 March 2015
Surrey County Bridge Association Newsletter #17 March 2015 In this edition • President’s Introduction • The 2014-2015 calendar • Don’t get too clever by Frances Hinden • Hall of fame • Surrey February Sim. Pairs • Schools Cup • Charity events • SCBA goes to the County Show • Club news, events and other snippets • Teachers advertise • Peter Bentley Obituary • Duplicate scoring on your iPhone (BRIAN) President’s Introduction The bridge season is well underway and I hope that many of you have found competitions of interest in the Surrey Calendar. As ever, the committee is interested to hear any comments members have about the format of the competitions or the venues used. Each year, the President selects a charity for the Sims Pairs event in February. This year I choose the Meath Epilepsy Centre in Godalming and I would like to thank all those who played in the event contributing to this very worthwhile cause. Many of you will have heard that Peter Bentley passed away a few weeks ago. I would like to pay tribute to the many years he served on the Surrey Committee and as Tollemache Captain. Despite his illness worsening in recent months he continued to attend EBU shareholder meetings for Surrey and was at the most recent Surrey Committee meeting in January. He will be missed by many. I am pleased to say that the Surrey University Bridge club is now established and meeting regularly. The association is funding a teacher in the early months and up to twelve students having been attending. We hope that we can build on the foundation that we have established. -

Bridge Scoring – a Tutorial
Bridge Scoring – A Tutorial In this tutorial, I will explain how scoring in bridge works and how it affects both the bidding and play. I will cover the following topics: Basic Scoring IMP Scoring Match Point Scoring Tactical Considerations Based On Scoring Basic Scoring Although I am sure you know this, let me just state the obvious basic scoring principle: In order for declarer to get a positive score, he must take at least as many tricks as he contracted for. So, for example, if the contract is 2, declarer must take at least 8 tricks in order to get a positive score. Similarly, in order for the defenders to get a positive score, they must prevent declarer from taking the number of tricks he contracted for. So if the contract is 3NT, they must hold declarer to 8 or fewer tricks in order to get a positive score. In this tutorial, I will be discussing duplicate bridge scoring. There is another form of scoring called rubber bridge scoring, which used to be very popular in social bridge games. These days, even most social bridge players use what is known as "Chicago" scoring, which is identical to duplicate bridge scoring. Scoring When You Make Your Contract Trick score for each trick taken over 6: . and contracts – 20 points per trick and contracts – 30 points per trick NT contracts – 40 points for 1st trick; 30 points per trick thereafter. Let me clarify some terms: Part Score – a part score is a contract where, if you make your contract exactly, the trick score is less than 100. -

Four Card Majors: Western Natural Updated
Foreword It is easy to dismiss Marvin French as a crank or a curmudgeon or as the contrarian that he certainly was but this does not do justice to the man’s life. Marvin was Life Master 10231 achieving the rank in 1956, “when it was hard” as he liked to say. This was not a boast, just a fact not well understood by many who started playing later, particularly after the great masterpoint inflation that kicked off shortly into the new millennium. Marvin was a force on the west coast bridge scene. Local San Diego Diamond LM, Anne Terry, never one to withhold an opinion positive or negative, called Marvin the “best of the best.” D22 Director, Ken Monzingo said, “Like him or not, he was a unique man. A leader, not a follower. A brilliant man of honesty and integrity.” Marvin made significant contributions to bridge literature and less known contributions to bidding theory. He was a contributor to Bridge World, Popular Bridge (published in the 1960s and 1970s), and the D22 Contract Bridge Forum, and editor for the latter prior to Joel Hoersch. For many years Marvin maintained his own website where he posted his writings on bridge, blackjack, and literature. His 90 page Squeeze Refresher (For Good Players) is undoubtedly the best reference that is available for free. Sometime in 2011 I got to know Marvin better because we started exchanging e-mail on various bridge topics in part because I had been reading his website and had taken some interest in his discussion of four card vs. -

2017 AUGUST–SEPTEMBER Vol
2017 AUGUST–SEPTEMBER Vol. 82, No. 3 Engaging women of influence ... for over 100 years Community Outreach . 3 Social Activities . 5 Tuesday Programs . 8 Expand Your Horizons . 9 What’s Happening . 12 Book Groups .............. 13 Calendar ....................15 The Spring Tea A PROGRESS REPORT FROM THE BOARD May 10, 2017 Dear Member, We have heard the feedback from members about rolling up our collective sleeves and making some important organizational changes, including some practical cost- cutting measures and integration of employee positions at the Club. Accordingly, you will see some changes around the Club: • Kristin Schurrer, our Executive Director, was let go in July. It did not make fiscal sense to continue to employ a full-time executive director to manage a 300-member charitable organization. Employees and Board members have agreed to step up, and you will see that there will continue to be accountability and responses to member questions. Kristin has many talents and we are grateful for her contributions over the last year. • We also made the difficult decision to remove our catering director, Tim Welsh. Tim has been a key contributor to the Club for over 30 years. His focus on member needs was superb. • We will continue to streamline workflows and make good use of Club funds by hiring a full-time accountant/bookkeeper rather than pay contractors. Interviews for this position are ongoing and our contractors are helping us with the selection. They see the value in their roles being taken by an internal position. • We will stop publishing the Bulletin in its current form. -

Voters Now Class B Teams in the State
·s.~ . <II •c: .,j 0 !":,..., ...'-l . ~ ..... (!.) ... p ., .... Important to You! '$.4 ~ •• 'I) 0 J'.)j r>t hi} t·~ t::! !'; ,,..., ···~ MODERATING ·r.. , ~t Pt r.·,4 Slightly modorotlng trend Thur•· tr.l C.JJ, day through Saturday; co/dar Sunday wllh Snow flurr/u, Volume 105, No. 9 • 30 Pages Wednesday, February 26, 1964 Mason Gains Mason· Schools Through 1970 Tourney Bye Mason drew a bye In the Class B East Jacltson bas· ltetball tournament, one of the toughest collection of District· Voters Now Class B teams in the state. The tournament will of· fer 2 games Tuesday night, March 3, 2 games Thursday School District Will Decide night, March 5, and the fl· nals on Saturday, March 7. Tucsd~y games will pit Extra Millage Tuesday Jackson Northwest, 0·15, Tuesday is the day of r1e school board member provld· against Jacltson Western, cis!on for Mason school dis· 11·3, at 7 o'clock and East ed these figures based on local trict electors. assessed valuation in the var· 'Jacltson, 12·2, against Jack· Voters will go to the po11s son St. ,John, 10·3, at 8:45, iotis townships served by the to settle 2 school finanP.e i~· Mason school system and the. Thursday night at 7 Jaclt· sues. One calls for lcvv.irw G city of Mason. son St. Mary, 10·5, will mills fo1' opel'ational · fu;;cls Charles Brown, school trus· meet the winner of .the East for the Ma~on ~chool sv.~tPm. Jackson-Jaclcson St. John tee, pointed out that the fa].