The Production of Speech Corpora
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How to Tape-Record Primate Vocalisations Version June 2001
How To Tape-Record Primate Vocalisations Version June 2001 Thomas Geissmann Institute of Zoology, Tierärztliche Hochschule Hannover, D-30559 Hannover, Germany E-mail: [email protected] Key Words: Sound, vocalisation, song, call, tape-recorder, microphone Clarence R. Carpenter at Doi Dao (north of Chiengmai, Thailand) in 1937, with the parabolic reflector which was used for making the first sound- recordings of wild gibbons (from Carpenter, 1940, p. 26). Introduction Ornithologists have been exploring the possibilities and the methodology of tape- recording and archiving animal sounds for many decades. Primatologists, however, have only recently become aware that tape-recordings of primate sound may be just as valuable as traditional scientific specimens such as skins or skeletons, and should be preserved for posterity. Audio recordings should be fully documented, archived and curated to ensure proper care and accessibility. As natural populations disappear, sound archives will become increasingly important. This is an introductory text on how to tape-record primate vocalisations. It provides some information on the advantages and disadvantages of various types of equipment, and gives some tips for better recordings of primate vocalizations, both in the field and in the zoo. Ornithologists studying bird sound have to deal with very similar problems, and their introductory texts are recommended for further study (e.g. Budney & Grotke 1997; © Thomas Geissmann Geissmann: How to Tape-Record Primate Vocalisations 2 Kroodsman et al. 1996). For further information see also the websites listed at the end of this article. As a rule, prices for sound equipment go up over the years. Prices for equipment discussed below are in US$ and should only be used as very rough estimates. -

Common Tape Manipulation Techniques and How They Relate to Modern Electronic Music
Common Tape Manipulation Techniques and How They Relate to Modern Electronic Music Matthew A. Bardin Experimental Music & Digital Media Center for Computation & Technology Louisiana State University Baton Rouge, Louisiana 70803 [email protected] ABSTRACT the 'play head' was utilized to reverse the process and gen- The purpose of this paper is to provide a historical context erate the output's audio signal [8]. Looking at figure 1, from to some of the common schools of thought in regards to museumofmagneticsoundrecording.org (Accessed: 03/20/2020), tape composition present in the later half of the 20th cen- the locations of the heads can be noticed beneath the rect- tury. Following this, the author then discusses a variety of angular protective cover showing the machine's model in the more common techniques utilized to create these and the middle of the hardware. Previous to the development other styles of music in detail as well as provides examples of the reel-to-reel machine, electronic music was only achiev- of various tracks in order to show each technique in process. able through live performances on instruments such as the In the following sections, the author then discusses some of Theremin and other early predecessors to the modern syn- the limitations of tape composition technologies and prac- thesizer. [11, p. 173] tices. Finally, the author puts the concepts discussed into a modern historical context by comparing the aspects of tape composition of the 20th century discussed previous to the composition done in Digital Audio recording and manipu- lation practices of the 21st century. Author Keywords tape, manipulation, history, hardware, software, music, ex- amples, analog, digital 1. -

Direct-To-Master Recording
Direct-To-Master Recording J. I. Agnew S. Steldinger Magnetic Fidelity http://www.magneticfidelity.com info@magneticfidelity.com July 31, 2016 Abstract Direct-to-Master Recording is a method of recording sound, where the music is performed entirely live and captured directly onto the master medium. This is usually done entirely in the analog domain using either magnetic tape or a phonograph disk as the recording medium. The result is an intense and realistic sonic image of the performance with an outstandig dynamic range. 1 The evolution of sound tracks can now also be edited note by note to recording technology compile a solid performance that can be altered or \improved" at will. Sound recording technology has greatly evolved This technological progress has made it pos- since the 1940's, when Direct-To-Master record- sible for far less competent musicians to make ing was not actually something special, but more a more or less competent sounding album and like one of the few options for recording music. for washed out rock stars who, if all put in the This evolution has enabled us to do things that same room at the same time, would probably would be unthinkable in those early days, such as murder each other, to make an album together. multitrack recording, which allows different in- Or, at least almost together. This ability, how- struments to be recorded at different times, and ever, comes at a certain cost. The recording pro- mixed later to create what sounds like a perfor- cess has been broken up into several stages, per- mance by many instruments at the same time. -

Automation: from Consoles to Daws
California State University, Monterey Bay Digital Commons @ CSUMB Capstone Projects and Master's Theses Capstone Projects and Master's Theses 12-2016 Automation: From Consoles to DAWs Christian Ekeke California State University, Monterey Bay Follow this and additional works at: https://digitalcommons.csumb.edu/caps_thes_all Part of the Music Education Commons Recommended Citation Ekeke, Christian, "Automation: From Consoles to DAWs" (2016). Capstone Projects and Master's Theses. 41. https://digitalcommons.csumb.edu/caps_thes_all/41 This Capstone Project (Open Access) is brought to you for free and open access by the Capstone Projects and Master's Theses at Digital Commons @ CSUMB. It has been accepted for inclusion in Capstone Projects and Master's Theses by an authorized administrator of Digital Commons @ CSUMB. For more information, please contact [email protected]. Christian Ekeke 12/19/16 Capstone 2 Dr. Lanier Sammons Automation: From Consoles to DAWs Since the beginning of modern music there has always been a need to implement movement into a mix. Whether it is bringing down dynamics for a classic fade out or a filter sweep slowly building into a chorus, dynamic activity in a song has always been pleasing to the average music listeners. The process that makes these mixing techniques possible is automation. Before I get into details about automation in regards to mixing I will explain common ways automation is used. Automation in a nutshell is the use of various techniques, method, and system of operating or controlling a process by highly automatic means generally through electronic devices. In music however, automation is simply the use of a combination of multiple control devices to alter parameters in real time while a mix is being played. -

Home Audio Taping of Copyrighted Works and the Audio Home Recording Act of 1992: a Critical Analysis Joel L
Hastings Communications and Entertainment Law Journal Volume 16 | Number 2 Article 4 1-1-1993 Home Audio Taping of Copyrighted Works and the Audio Home Recording Act of 1992: A Critical Analysis Joel L. McKuin Follow this and additional works at: https://repository.uchastings.edu/ hastings_comm_ent_law_journal Part of the Communications Law Commons, Entertainment, Arts, and Sports Law Commons, and the Intellectual Property Law Commons Recommended Citation Joel L. McKuin, Home Audio Taping of Copyrighted Works and the Audio Home Recording Act of 1992: A Critical Analysis, 16 Hastings Comm. & Ent. L.J. 311 (1993). Available at: https://repository.uchastings.edu/hastings_comm_ent_law_journal/vol16/iss2/4 This Article is brought to you for free and open access by the Law Journals at UC Hastings Scholarship Repository. It has been accepted for inclusion in Hastings Communications and Entertainment Law Journal by an authorized editor of UC Hastings Scholarship Repository. For more information, please contact [email protected]. Home Audio Taping of Copyrighted Works and The Audio Home Recording Act of 1992: A Critical Analysis by JOEL L. McKuIN* Table of Contents I. Home Taping: The Problem and its Legal Status ....... 315 A. Constitutional and Statutory Background ........... 315 B. Home Taping or Home "Taking"?: The History of Home Taping's Legal Status ........................ 318 C. New Technologies Sharpen the Home Taping Problem ............................................ 321 1. The DAT Debacle .............................. 321 2. Other New Technologies ........................ 322 II. The Audio Home Recording Act of 1992 (AHRA) ..... 325 A. Serial Copy Management System (SCMS) .......... 325 B. Royalties on Digital Hardware and Media .......... 326 C. Prohibition of Copyright Infringement Actions ..... 328 III. -

Chapter 10 • Digital Audio Recording Devices And
Chapter 10 1 Digital Audio Recording Devices and Media section page 1001 Definitions ................................................274 1002 Incorporation of copying controls ..............................276 1003 Obligation to make royalty payments ...........................277 1004 Royalty payments . 278 1005 Deposit of royalty payments and deduction of expenses . 279 1006 Entitlement to royalty payments . 279 1007 Procedures for distributing royalty payments . 281 1008 Prohibition on certain infringement actions ......................282 1009 Civil remedies ..............................................282 1010 Determination of certain disputes . 284 § 1001 Digital Audio Recording Devices and Media subchapter a — defiNitioNs § 1001 · Definitions As used in this chapter, the following terms have the following meanings: (1) A “digital audio copied recording” is a reproduction in a digital re- cording format of a digital musical recording, whether that reproduction is made directly from another digital musical recording or indirectly from a transmission. (2) A “digital audio interface device” is any machine or device that is de- signed specifically to communicate digital audio information and related interface data to a digital audio recording device through a nonprofessional interface. (3) A “digital audio recording device” is any machine or device of a type commonly distributed to individuals for use by individuals, whether or not included with or as part of some other machine or device, the digital record- ing function of which is designed or marketed for the primary purpose of, and that is capable of, making a digital audio copied recording for private use, except for— (A) professional model products, and (B) dictation machines, answering machines, and other audio record- ing equipment that is designed and marketed primarily for the creation of sound recordings resulting from the fixation of nonmusical sounds. -

Compact Disc Minidisc Deck
4-245-486-12(1) Compact Disc MiniDisc Deck Operating Instructions MXD-D400 ©2003 Sony Corporation Owner’s Record WARNING The model and serial numbers are located on the rear of the unit. Record the serial number in the space To prevent fire or shock hazard, do not provided below. Refer to them whenever you call upon expose the unit to rain or moisture. your Sony dealer regarding this product. To prevent fire, do not cover the ventilation of the Model No. MXD-D400 Seral No. apparatus with news papers, table-cloths, curtains, etc. And don’t place lighted candles on the apparatus. Caution To prevent fire or shock hazard, do not place objects The use of optical instruments with this product will filled with liquids, such as vases, on the apparatus increase eye hazard. This appliance is WARNING classified as a CLASS 1 This equipment has been tested and found to comply LASER product. This with the limits for a Class B digital device, pursuant to label is located on the Part 15 of the FCC Rules. These limits are designed to rear exterior. provide reasonable protection against harmful interference in a residential installation. This The following caution label is located inside the equipment generates, uses, and can radiate radio apparatus. frequency energy and, if not installed and used in accordance with the instructions, may cause harmful interference to radio communications. However, there is no guarantee that interference will not occur in a particular installation. If this equipment does cause harmful interference to radio or television reception, which can be determined by turning the equipment off and on, the user is encouraged to try to correct the interference by one or more of the following measures: – Reorient or relocate the receiving antenna. -
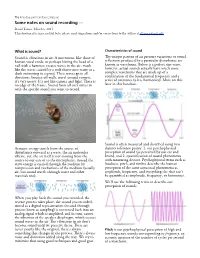
Notes on Sound Recording
The Kino-Eye.com handout collection Some notes on sound recording v.3 David Tamés, March 6, 2015 This document is in perpetual beta, please send suggestions and/or corrections to the author at [email protected] What is sound? Characteristics of sound Sound is vibrations in air. A movement, like those of Te unique pattern of air pressure variations or sound human vocal cords, or perhaps hitting the head of a refections produced by a particular disturbance are nail with a hammer, creates waves in the air, much known as waveforms. Below is a perfect sine wave, like the waves caused by a rock throw into water or a however, actual sounds actually have much more duck swimming in a pond. Tese waves go in all complex waveforms that are made up of a directions, bounce off walls, travel around corners, combination of the fundamental frequency and a it’s very messy. It’s not like camera and light. Tere is series of overtones (a.k.a. harmonics). More on this no edge of the frame. Sound from all over mixes in later in this handout. with the specifc sound you want to record. Sound is often measured and described using two Acoustic energy travels from the source of distinct reference points: 1. our psychophysical disturbance outward as a wave, the air molecules perception of sound (as perceived by our ear and vibrate, yet, the air itself is not moving from the brain), and 2. quantifcation of sound phenomena source to our ears or to the microphone, instead the with measuring devices. -

Digital Audio Tapes: Their Preservation and Conversion 1 Smithsonian Institution Archives Summer 2010
Digital Audio Tapes: Their Preservation and Conversion 1 Smithsonian Institution Archives Summer 2010 Digital Audio Tapes: Their Preservation and Conversion Susan Eldridge, Digital Services Intern Overview Digital Audio Tapes (DATs) are 4mm (or 3.81mm) magnetic tape cassettes that store audio information in a digital manner. DATS are visually similar to compact audio cassettes, though approximately half the size, use thinner tapes, and can only be recorded on one side. Developed by Sony in 1987, DATs were quite popular in recording studios and were one of the first digital recording systems to become employed in archives in the late 1980s and 1990s due to their lossless encoding. Commercial use of DATs, on the other hand, never achieved the same success as the machines were expensive and commercial recordings were not available on DAT. Depending on the tape and machine used, DATs allow four different sampling modes: 32 kHz at 12 bits quantization, and 32 kHz, 44.1 kHz, and 48 kHz at 16 bits.1 All support two-channel stereo recording. Some of the later DATs (before being discontinued) could extend the bit-depth to 24 and up to 98 kHz, however, these tapes were likely rarely playable on other models.2 DATs can run between 15 and 180 minutes in length, one again depending on the tape and quality of the sampling. Unlike some other digital media, DATs do not use lossy data compression, which is important in the lossless transferring of a digital source to a DAT. Sony ultimately discontinued the production of DAT machines in 2005.3 Composition A digital magnetic tape is composed of two primary layers: the base film and magnetic layer. -

Creating Audio for the Classroom Incorporating Sound Into a Classroom Involves Recording the Original Sound and Digitizing It Into an Appropriate Format for Importing
Creating Audio for the Classroom Incorporating sound into a classroom involves recording the original sound and digitizing it into an appropriate format for importing. Sound fills the air all around us, and our ear is working all the time to filter out unimportant sound from our consciousness so we can pay attention to the important information. This means that we are largely unaware of how much sound surrounds us at all times. If you concentrate on what you hear, you will find that silence is very hard to find. All sounds we hear with our ears are pressure waves in air. These waves can be captured when they vibrate the membrane of a microphone and can be re-created by the amplified vibrations of the membrane in a speaker. An analog recording of sound, such as on a phonographic record or cassette tape looks like this: Digital recordings take a sample of information from the wave at regular time intervals. The more samples the more precise the recordings, the higher the digital quality. It would look like this: Sample rates are measured in hertz (Hz) or cycles per second. The most common sample rates measured in Hz are 8000, 16000, 22050, 44100, 48000, 96000 and 192000 or 8Hz, 16Hz, etc. The rate most frequently used in recordings is 44.1Hz and computer sound cards tend to default to this rate. Next the sample is represented in bits of information such as 8 bits or 16 bits per sample. As you can imagine this sampling creates a huge sized file. An hour audio file might have 6 billion bits of information or 800 MB. -

Best Practices for Producing Quality Digital Audio Files
Deep Blue Deep Blue https://deepblue.lib.umich.edu/documents Research Collections Library (University of Michigan Library) 2006-07-10 Best practices for producing quality digital audio files Formats Group, Deep Blue https://hdl.handle.net/2027.42/40248 Downloaded from Deep Blue, University of Michigan's institutional repository Best practices for producing quality digital audio files Version 1.0, 10 July 2006 Just as the quality of digital images depends on resolution, color depth, and storage format, the quality of digital audio depends on the sampling rate and bit depth settings, as well as the choice of compressed (lossy or lossless) or uncompressed storage formats. Most computers’ standard configurations support CD and DV quality audio and the more common compressed audio formats. Higher quality (higher sampling rate and/or greater bit depth) audio capture may require additional internal or external hardware for both creation and playback. The recommendations below do not cover hardware, as this area constantly evolves. General recommendations Sampling Rate and Bit Depth The sampling rate determines how many times per second the sound wave is measured; bit depth is the sample size or range of possible numbers used to express the sample. Together, these determine the “resolution” of your audio file, and the size of the data file that contains your audio. Keep in mind that you can’t add resolution to an existing digital file by increasing these parameters, and you should consider the quality, recording medium, and ultimate use of any analog source recordings when choosing the quality level for your digital files. Archival Quality Sampling rate = 96 kHz Bit depth = 24-bit depth Acceptable (DVD Quality) Sampling rate = 48 kHz Bit depth = 16-bit depth Acceptable (Audio CD Quality) Sampling rate = 44.1 kHz Bit depth = 16-bit depth Frequency ranges of different sounds vary, so the requirements for a digital version of your source recordings will also vary. -

Magnetic Recording: Analog Tape
Magnetic Recording: Analog Tape Until recently, there was one dominant way of recording sounds so that they could be reproduced at a later time or in a different location: analog magnetic recording (of course, there were mechanical methods like phonograph records, but they could not be recorded easily). In fact, magnetic recording techniques are still the most common way of recording signals, but the encoding method is digital. Magnetic recording relies on the imposition of a magnetic field, derived from an electrical signal, on a magnetically susceptible medium that becomes magnetized. The magnetic medium employed in analog recording is magnetic tape: a thin plastic ribbon with randomly oriented microscopic magnetic particles glued to the surface. The record head magnetic field alters the magnetic polarization (not the physical orientation) of the tiny particles so that they align their magnetic domains with the imposed field: the stronger the imposed field, the more particles align their orientations with the field, until all of the particles are magnetized. The retained pattern of magnetization stores the representation of the signal. When the magnetized medium is moved past a read head, an electrical signal is produced by induction. Unfortunately, the process is inherently very non-linear, so the resulting playback signal is different from the original signal. Much of the circuitry employed in an analog tape recorder is necessary to undo the distortion introduced by the non-linear physics of the system. Figure 1: In a record head, magnetic flux flows through low-reluctance pathway in the tape’s magnetic coating layer. Magnetic tape Magnetic tape used for audio recording consists of a plastic ribbon onto which a layer of magnetic material is glued.