Computational Methods for Breast Cancer Diagnosis, Prognosis, and Treatment Prediction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Order Estimation Based Approach to Identify Response Genes
AN ORDER ESTIMATION BASED APPROACH TO IDENTIFY RESPONSE GENES FOR MICRO ARRAY TIME COURSE DATA A Thesis Presented to The Faculty of Graduate Studies of The University of Guelph by ZHIHENG LU In partial fulfilment of requirements for the degree of Doctor of Philosophy September, 2008 © Zhiheng Lu, 2008 Library and Bibliotheque et 1*1 Archives Canada Archives Canada Published Heritage Direction du Branch Patrimoine de I'edition 395 Wellington Street 395, rue Wellington Ottawa ON K1A0N4 Ottawa ON K1A0N4 Canada Canada Your file Votre reference ISBN: 978-0-494-47605-5 Our file Notre reference ISBN: 978-0-494-47605-5 NOTICE: AVIS: The author has granted a non L'auteur a accorde une licence non exclusive exclusive license allowing Library permettant a la Bibliotheque et Archives and Archives Canada to reproduce, Canada de reproduire, publier, archiver, publish, archive, preserve, conserve, sauvegarder, conserver, transmettre au public communicate to the public by par telecommunication ou par Plntemet, prefer, telecommunication or on the Internet, distribuer et vendre des theses partout dans loan, distribute and sell theses le monde, a des fins commerciales ou autres, worldwide, for commercial or non sur support microforme, papier, electronique commercial purposes, in microform, et/ou autres formats. paper, electronic and/or any other formats. The author retains copyright L'auteur conserve la propriete du droit d'auteur ownership and moral rights in et des droits moraux qui protege cette these. this thesis. Neither the thesis Ni la these ni des extraits substantiels de nor substantial extracts from it celle-ci ne doivent etre imprimes ou autrement may be printed or otherwise reproduits sans son autorisation. -

Valproic Acid Reversed Pathologic Endothelial Cell Gene Expression Profile Associated with Ischemia– Reperfusion Injury in a Swine Hemorrhagic Shock Model
From the Peripheral Vascular Surgery Society Valproic acid reversed pathologic endothelial cell gene expression profile associated with ischemia– reperfusion injury in a swine hemorrhagic shock model Marlin Wayne Causey, MD,a Shashikumar Salgar, PhD,b Niten Singh, MD,a Matthew Martin, MD,a and Jonathan D. Stallings, PhD,b Tacoma, Wash Background: Vascular endothelial cells serve as the first line of defense for end organs after ischemia and reperfusion injuries. The full etiology of this dysfunction is poorly understood, and valproic acid (VPA) has proven to be beneficial after traumatic injury. The purpose of this study was to determine the mechanism of action through which VPA exerts its beneficial effects. Methods: Sixteen Yorkshire swine underwent a standardized protocol for an ischemia–reperfusion injury through received (6 ؍ hemorrhage and a supraceliac cross-clamp with ensuing 6-hour resuscitation. The experimental swine (n Aortic .(5 ؍ and injury-control models (n (5 ؍ VPA at cross-clamp application and were compared with sham (n endothelium was harvested, and microarray analysis was performed along with a functional clustering analysis with gene transcript validation using relative quantitative polymerase chain reaction. Results: Clinical comparison of experimental swine matched for sex, weight, and length demonstrated that VPA significantly decreased resuscitative requirements, with improved hemodynamics and physiologic laboratory measure- ments. Six transcript profiles from the VPA treatment were compared with the 1536 gene transcripts (529 up and 1007 down) from sham and injury-control swine. Microarray analysis and a Database for Annotation, Visualization and Integrated Discovery functional pathway analysis approach identified biologic processes associated with pathologic vascular endothelial function, specifically through functional cluster pathways involving apoptosis/cell death and angiogenesis/vascular development, with five specific genes (THBS1, TNFRSF12A, ANGPTL4, RHOB, and RTN4) identified as members of both functional clusters. -

Role and Regulation of the P53-Homolog P73 in the Transformation of Normal Human Fibroblasts
Role and regulation of the p53-homolog p73 in the transformation of normal human fibroblasts Dissertation zur Erlangung des naturwissenschaftlichen Doktorgrades der Bayerischen Julius-Maximilians-Universität Würzburg vorgelegt von Lars Hofmann aus Aschaffenburg Würzburg 2007 Eingereicht am Mitglieder der Promotionskommission: Vorsitzender: Prof. Dr. Dr. Martin J. Müller Gutachter: Prof. Dr. Michael P. Schön Gutachter : Prof. Dr. Georg Krohne Tag des Promotionskolloquiums: Doktorurkunde ausgehändigt am Erklärung Hiermit erkläre ich, dass ich die vorliegende Arbeit selbständig angefertigt und keine anderen als die angegebenen Hilfsmittel und Quellen verwendet habe. Diese Arbeit wurde weder in gleicher noch in ähnlicher Form in einem anderen Prüfungsverfahren vorgelegt. Ich habe früher, außer den mit dem Zulassungsgesuch urkundlichen Graden, keine weiteren akademischen Grade erworben und zu erwerben gesucht. Würzburg, Lars Hofmann Content SUMMARY ................................................................................................................ IV ZUSAMMENFASSUNG ............................................................................................. V 1. INTRODUCTION ................................................................................................. 1 1.1. Molecular basics of cancer .......................................................................................... 1 1.2. Early research on tumorigenesis ................................................................................. 3 1.3. Developing -

Gene Discovery in Developmental Neuropsychiatric Disorders : Clues from Chromosomal Rearrangements Thomas V
Yale University EliScholar – A Digital Platform for Scholarly Publishing at Yale Yale Medicine Thesis Digital Library School of Medicine 2005 Gene discovery in developmental neuropsychiatric disorders : clues from chromosomal rearrangements Thomas V. Fernandez Yale University Follow this and additional works at: http://elischolar.library.yale.edu/ymtdl Recommended Citation Fernandez, Thomas V., "Gene discovery in developmental neuropsychiatric disorders : clues from chromosomal rearrangements" (2005). Yale Medicine Thesis Digital Library. 2578. http://elischolar.library.yale.edu/ymtdl/2578 This Open Access Thesis is brought to you for free and open access by the School of Medicine at EliScholar – A Digital Platform for Scholarly Publishing at Yale. It has been accepted for inclusion in Yale Medicine Thesis Digital Library by an authorized administrator of EliScholar – A Digital Platform for Scholarly Publishing at Yale. For more information, please contact [email protected]. YALE UNIVERSITY CUSHING/WHITNEY MEDICAL LIBRARY Permission to photocopy or microfilm processing of this thesis for the purpose of individual scholarly consultation or reference is hereby granted by the author. This permission is not to be interpreted as affecting publication of this work or otherwise placing it in the public domain, and the author reserves all rights of ownership guaranteed under common law protection of unpublished manuscripts. Digitized by the Internet Archive in 2017 with funding from The National Endowment for the Humanities and the Arcadia Fund https://archive.org/details/genediscoveryindOOfern Gene discovery in developmental neuropsychiatric disorders: Clues from chromosomal rearrangements A Thesis Submitted to the Yale University School of Medicine In Partial Fulfillment of the Requirements for the Degree of Doctor of Medicine by Thomas V. -

Supplementary Table 3 Gene Microarray Analysis: PRL+E2 Vs
Supplementary Table 3 Gene microarray analysis: PRL+E2 vs. control ID1 Field1 ID Symbol Name M Fold P Value 69 15562 206115_at EGR3 early growth response 3 2,36 5,13 4,51E-06 56 41486 232231_at RUNX2 runt-related transcription factor 2 2,01 4,02 6,78E-07 41 36660 227404_s_at EGR1 early growth response 1 1,99 3,97 2,20E-04 396 54249 36711_at MAFF v-maf musculoaponeurotic fibrosarcoma oncogene homolog F 1,92 3,79 7,54E-04 (avian) 42 13670 204222_s_at GLIPR1 GLI pathogenesis-related 1 (glioma) 1,91 3,76 2,20E-04 65 11080 201631_s_at IER3 immediate early response 3 1,81 3,50 3,50E-06 101 36952 227697_at SOCS3 suppressor of cytokine signaling 3 1,76 3,38 4,71E-05 16 15514 206067_s_at WT1 Wilms tumor 1 1,74 3,34 1,87E-04 171 47873 238623_at NA NA 1,72 3,30 1,10E-04 600 14687 205239_at AREG amphiregulin (schwannoma-derived growth factor) 1,71 3,26 1,51E-03 256 36997 227742_at CLIC6 chloride intracellular channel 6 1,69 3,23 3,52E-04 14 15038 205590_at RASGRP1 RAS guanyl releasing protein 1 (calcium and DAG-regulated) 1,68 3,20 1,87E-04 55 33237 223961_s_at CISH cytokine inducible SH2-containing protein 1,67 3,19 6,49E-07 78 32152 222872_x_at OBFC2A oligonucleotide/oligosaccharide-binding fold containing 2A 1,66 3,15 1,23E-05 1969 32201 222921_s_at HEY2 hairy/enhancer-of-split related with YRPW motif 2 1,64 3,12 1,78E-02 122 13463 204015_s_at DUSP4 dual specificity phosphatase 4 1,61 3,06 5,97E-05 173 36466 227210_at NA NA 1,60 3,04 1,10E-04 117 40525 231270_at CA13 carbonic anhydrase XIII 1,59 3,02 5,62E-05 81 42339 233085_s_at OBFC2A oligonucleotide/oligosaccharide-binding -

Untersuchungen Zum Einfluss Von Infrarot-A Strahlung Auf Die Genexpression in Humanen Dermalen Fibroblasten
Untersuchungen zum Einfluss von Infrarot-A Strahlung auf die Genexpression in humanen dermalen Fibroblasten Inaugural-Dissertation zur Erlangung des Doktorgrades der Mathematisch-Naturwissenschaftlichen Fakult¨at der Heinrich-Heine-Universit¨at Dusseldorf¨ vorgelegt von Christian Calles aus Dusseldorf¨ Dusseldorf,¨ Oktober 2009 Aus dem Institut fur¨ umweltmedizinische Forschung an der Heinrich-Heine-Universit¨at Dusseldorf¨ gGmbH. Gedruckt mit der Genehmigung der Mathematisch-Naturwissen- schaftlichen Fakult¨at der Heinrich-Heine-Universit¨at Dusseldorf.¨ Referent: Prof. Dr. J. Krutmann Koreferent: Prof. Dr. R. Wagner Tag der mundlichen¨ Prufung:¨ 10. Dezember 2009 Danksagung Bei Prof. Dr. J. Krutmann m¨ochte ich mich dafur¨ bedanken, dass er mir diese Arbeit am Institut fur¨ umweltmedizinische Forschung erm¨oglichte, bei Peet Schroeder fur¨ die super Betreuung uber¨ die ganze Zeit und der ganzen Arbeitsgruppe fur¨ das nun seit Jahren anhaltende erstklassige Arbeitsklima. Prof. Dr. R. Wagner danke ich fur¨ die bereitwillige Ubernahme¨ des Koreferates. Marc, Bianca, Fina und Tereza danke ich fur¨ Ihren Einsatz beim Korrekturlesen und Jochen fur¨ die Unterstutzung¨ in der ein oder anderen (bio)-informatischen Frage und den Tips zu LATEX. 4 Inhaltsverzeichnis 1 Einleitung 1 1.1 Infrarot A (IRA) und das solare Spektrum . 1 1.2 Photobiologische Effekte nicht-ionisierender Strahlung . 2 1.3 Aufbau & Struktur der menschlichen Haut . 4 1.3.1 Die extrazellul¨are Matrix (ECM) der Dermis und die Rolle von Ma- trixmetalloproteinasen . 5 1.4 Intrinsische Hautalterung . 8 1.5 Extrinsische Hautalterung durch Lichteinflusse:¨ Photoaging . 8 1.5.1 Biologische Effekte von Infrarotstrahlung in der menschlichen Haut 9 1.6 Bedeutung von reaktiven Sauerstoffspezies in lichtinduzierten Alterungs- prozessen . 11 1.7 Fragestellung . -

Wo 2010/065567 A2
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date 10 June 2010 (10.06.2010) WO 2010/065567 A2 (51) International Patent Classification: (81) Designated States (unless otherwise indicated, for every A61K 36/889 (2006.01) A61K 31/16 (2006.01) kind of national protection available): AE, AG, AL, AM, A61K 36/736 (2006.01) A61K 31/05 (2006.01) AO, AT, AU, AZ, BA, BB, BG, BH, BR, BW, BY, BZ, A61K 31/166 (2006.01) A61P 5/00 (2006.01) CA, CH, CL, CN, CO, CR, CU, CZ, DE, DK, DM, DO, DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, (21) International Application Number: HN, HR, HU, ID, IL, IN, IS, JP, KE, KG, KM, KN, KP, PCT/US2009/066294 KR, KZ, LA, LC, LK, LR, LS, LT, LU, LY, MA, MD, (22) International Filing Date: ME, MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, 1 December 2009 (01 .12.2009) NO, NZ, OM, PE, PG, PH, PL, PT, RO, RS, RU, SC, SD, SE, SG, SK, SL, SM, ST, SV, SY, TJ, TM, TN, TR, TT, (25) Filing Language: English TZ, UA, UG, US, UZ, VC, VN, ZA, ZM, ZW. (26) Publication Language: English (84) Designated States (unless otherwise indicated, for every (30) Priority Data: kind of regional protection available): ARIPO (BW, GH, 61/1 18,945 1 December 2008 (01 .12.2008) US GM, KE, LS, MW, MZ, NA, SD, SL, SZ, TZ, UG, ZM, ZW), Eurasian (AM, AZ, BY, KG, KZ, MD, RU, TJ, (71) Applicant (for all designated States except US): LIFES¬ TM), European (AT, BE, BG, CH, CY, CZ, DE, DK, EE, PAN EXTENSION LLC [US/US]; 933 First Colonial ES, FI, FR, GB, GR, HR, HU, IE, IS, IT, LT, LU, LV, Road, Suite 114, Virginia Beach, VA 23454 (US). -

University of California, San Diego
UC San Diego UC San Diego Electronic Theses and Dissertations Title Analysis of pluripotent mouse stem cell proteomes : insights into post- transcriptional regulation of pluripotency and differentiation Permalink https://escholarship.org/uc/item/5wb983jr Author O'Brien, Robert Norman Publication Date 2010 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA, SAN DIEGO Analysis of pluripotent mouse stem cell proteomes: insights into post- transcriptional regulation of pluripotency and differentiation A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Biology by Robert Norman O’Brien Committee in charge: Professor Steven P. Briggs, Chair Professor Lawrence Goldstein Professor Cornelius Murre Professor Karl Willert Professor Yang Xu 2010 Copyright Robert Norman O’Brien, 2010 All rights reserved. The Dissertation of Robert Norman O’Brien is approved, and it is acceptable in quality and form for publication on microfilm and electronically: Chair University of California, San Diego 2010 iii DEDICATION To all of my friends and family who made this possible. I can’t thank all of you enough. I especially dedicate this to Chi, who has been my companion, friend and love throughout my time in graduate school: your unwavering support was essential in getting me to this point. iv EPIGRAPH My feet tug at the floor And my head sways to my shoulder Sometimes when I watch trees sway, From the window or the door. I shall set forth for somewhere, I shall make the reckless choice Some day when they are in voice And tossing so as to scare The white clouds over them on. -

Ep 2 136 209 A1
(19) & (11) EP 2 136 209 A1 (12) EUROPEAN PATENT APPLICATION published in accordance with Art. 153(4) EPC (43) Date of publication: (51) Int Cl.: 23.12.2009 Bulletin 2009/52 G01N 33/15 (2006.01) G01N 33/50 (2006.01) (21) Application number: 08721397.1 (86) International application number: PCT/JP2008/053977 (22) Date of filing: 05.03.2008 (87) International publication number: WO 2008/111464 (18.09.2008 Gazette 2008/38) (84) Designated Contracting States: • SAGANE, Koji AT BE BG CH CY CZ DE DK EE ES FI FR GB GR Tsukuba-shi HR HU IE IS IT LI LT LU LV MC MT NL NO PL PT Ibaraki 300-2635 (JP) RO SE SI SK TR • UESUGI, Mai Tsukuba-shi (30) Priority: 05.03.2007 US 904774 P Ibaraki 300-2635 (JP) 28.09.2007 US 960403 P • KADOWAKI, Tadashi Tsukuba-shi (71) Applicant: Eisai R&D Management Co., Ltd. Ibaraki 300-2635 (JP) Tokyo 112-8088 (JP) • YOSHIDA, Taku Tsukuba-shi (72) Inventors: Ibaraki 300-2635 (JP) • MIZUI, Yoshiharu Tsukuba-shi (74) Representative: Woods, Geoffrey Corlett Ibaraki 300-2635 (JP) J.A. Kemp & Co. • HATA, Naoko 14 South Square Tsukuba-shi Gray’s Inn Ibaraki 300-2635 (JP) London • IWATA, Masao WC1R 5JJ (GB) Tsukuba-shi Ibaraki 300-2635 (JP) (54) METHOD FOR EXAMINATION OF ACTION OF ANTI-CANCER AGENT UTILIZING SPLICING DEFECT AS MEASURE (57) An object of the present invention is to provide a method, a probe, a primer, an antibody, a reagent, and a kit for assaying an action of a pladienolide derivative to a living subject. -

Université Paris Xi Faculté De Médecine Paris-Sud
UNIVERSITÉ PARIS XI FACULTÉ DE MÉDECINE PARIS-SUD Année 2010 N°attribué par la bibliothèque THESE Pour obtenir le grade de DOCTEUR DE L’UNIVERSITE PARIS XI Champ disciplinaire : Médecine Ecole Doctorale de rattachement : ED418 Cancérologie, Biologie, Médecine,Santé Présentée et soutenue publiquement par L’Emira Ghida HARFOUCHE Le 12 février 2010 Titre: FIBROBLAST GROWTH FACTOR 2 AND DNA REPAIR INVOLVEMENT IN THE KERATINOCYTE STEM CELL RESPONSE TO IONIZING RADIATION Directrice de thèse: MARTIN Michèle JURY Pr. BOURHIS Jean Président Dr. DOUKY Thierry Rapporteur Pr. LAMARTINE Jérôme Rapporteur Dr. BRETON Lionel Examinateur Dr. MOYAL Elisabeth Examinateur Dr. MARTIN Michèle Directrice de thèse ACKNOWLEDGEMENTS First of all, I would like to thank my thesis advisor, Dr. Michele Martin, for her guidance and her expertise in stem cell radiobiology. I appreciate her enthusiasm and encouragement during the course of the study. I have learned a lot and have grown a lot through all the experiences in her lab, not only as a scientist but also as a person. I would like to acknowledge my thesis committee Dr. Thierry Douky and Pr. Jérôme Lamartine for accepting to be my “rapporteurs”, for evaluating my work, for carefully reading this thesis and giving me helpful instructions and for being part of the jury members, along with Pr. Jean Bourhis, Dr. Lionel Breton, and Dr. Elisabeth Moyal. Their contributions to the judgment of this work and to this thesis as readers are very much appreciated. I would like to thank Dr. Nicolas Fortunel for his encouragement, invaluable advices and discussions that made me leap up one more step as a scientist. -
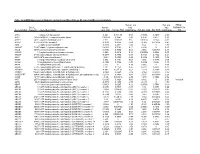
Mrna Expression in Human Leiomyoma and Eker Rats As Measured by Microarray Analysis
Table 3S: mRNA Expression in Human Leiomyoma and Eker Rats as Measured by Microarray Analysis Human_avg Rat_avg_ PENG_ Entrez. Human_ log2_ log2_ RAPAMYCIN Gene.Symbol Gene.ID Gene Description avg_tstat Human_FDR foldChange Rat_avg_tstat Rat_FDR foldChange _DN A1BG 1 alpha-1-B glycoprotein 4.982 9.52E-05 0.68 -0.8346 0.4639 -0.38 A1CF 29974 APOBEC1 complementation factor -0.08024 0.9541 -0.02 0.9141 0.421 0.10 A2BP1 54715 ataxin 2-binding protein 1 2.811 0.01093 0.65 0.07114 0.954 -0.01 A2LD1 87769 AIG2-like domain 1 -0.3033 0.8056 -0.09 -3.365 0.005704 -0.42 A2M 2 alpha-2-macroglobulin -0.8113 0.4691 -0.03 6.02 0 1.75 A4GALT 53947 alpha 1,4-galactosyltransferase 0.4383 0.7128 0.11 6.304 0 2.30 AACS 65985 acetoacetyl-CoA synthetase 0.3595 0.7664 0.03 3.534 0.00388 0.38 AADAC 13 arylacetamide deacetylase (esterase) 0.569 0.6216 0.16 0.005588 0.9968 0.00 AADAT 51166 aminoadipate aminotransferase -0.9577 0.3876 -0.11 0.8123 0.4752 0.24 AAK1 22848 AP2 associated kinase 1 -1.261 0.2505 -0.25 0.8232 0.4689 0.12 AAMP 14 angio-associated, migratory cell protein 0.873 0.4351 0.07 1.656 0.1476 0.06 AANAT 15 arylalkylamine N-acetyltransferase -0.3998 0.7394 -0.08 0.8486 0.456 0.18 AARS 16 alanyl-tRNA synthetase 5.517 0 0.34 8.616 0 0.69 AARS2 57505 alanyl-tRNA synthetase 2, mitochondrial (putative) 1.701 0.1158 0.35 0.5011 0.6622 0.07 AARSD1 80755 alanyl-tRNA synthetase domain containing 1 4.403 9.52E-05 0.52 1.279 0.2609 0.13 AASDH 132949 aminoadipate-semialdehyde dehydrogenase -0.8921 0.4247 -0.12 -2.564 0.02993 -0.32 AASDHPPT 60496 aminoadipate-semialdehyde -

Table 1. Antibodies Used for Chromatin Immunoprecipitation (Chip)
Table 1. Antibodies used for chromatin immunoprecipitation (ChIP) Protein Antibody Manufacturer References Western blot ChIP p65 sc-372 Santa Cruz (1, 2) (3-5) Biotechnology p50 sc-1190 Santa Cruz (6) (7) Biotechnology RelB sc-226 Santa Cruz (8) (5) Biotechnology c-Rel sc-71 Santa Cruz (8) (5, 9) Biotechnology p52 06-413 Upstate Biotechnology, (10) Lake Placid, NY E2F4 sc-1082 Santa Cruz (11) (12) Biotechnology Pol II 8WG16 (13) (14) The fact that the p65 dataset has no targets in unstimulated cells confirms the lack of background enrichment from the Dynal magnetic beads. The number of p50 targets in unstimulated cells is higher than for the other subunits. We were concerned that this might be due to the antibody used. Therefore, we tested another antibody raised against the N-terminus of the protein (sc-1191). In test experiments, 90% of enriched gene promoters were shared between the two p50 antibodies (data not shown). 1. Rodriguez, M. S., Thompson, J., Hay, R. T. & Dargemont, C. (1999) J. Biol. Chem. 274, 9108-9115. 2. Huang, T. T., Kudo, N., Yoshida, M. & Miyamoto, S. (2000) Proc. Natl. Acad. Sci. USA 97, 1014-1019. 3. Nissen, R. M. & Yamamoto, K. R. (2000) Genes Dev. 14, 2314-2329. 4. Martone, R., Euskirchen, G., Bertone, P., Hartman, S., Royce, T. E., Luscombe, N. M., Rinn, J. L., Nelson, F. K., Miller, P., Gerstein, M., et al. (2003) Proc. Natl. Acad. Sci. USA 100, 12247-12252. 5. Saccani, S., Pantano, S. & Natoli, G. (2003) Mol. Cell 11, 1563-1574. 6. Yamazaki, T. & Kurosaki, T.