Mdn Workshop 2019
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

I N H a L T S V E R Z E I C H N
SWR BETEILIGUNGSBERICHT 2018 Beteiligungsübersicht 2018 Südwestrundfunk 100% Tochtergesellschaften Beteiligungsgesellschaften ARD/ZDF Beteiligungen SWR Stiftungen 33,33% Schwetzinger SWR Festspiele 49,00% MFG Medien- und Filmgesellschaft 25,00% Verwertungsgesellschaft der Experimentalstudio des SWR e.V. gGmbH, Schwetzingen BaWü mbH, Stuttgart Film- u. Fernsehproduzenten mbH Baden-Baden 45,00% Digital Radio Südwest GmbH 14,60% ARD/ZDF-Medienakademie Stiftung Stuttgart gGmbH, Nürnberg Deutsches Rundfunkarchiv Frankfurt 16,67% Bavaria Film GmbH 11,43% IRT Institut für Rundfunk-Technik Stiftung München GmbH, München Hans-Bausch-Media-Preis 11,11% ARD-Werbung SALES & SERV. GmbH 11,11% Degeto Film GmbH Frankfurt München 0,88% AGF Videoforschung GmbH 8,38% ARTE Deutschland TV GmbH Frankfurt Baden-Baden Mitglied Haus des Dokumentarfilms 5,56% SportA Sportrechte- u. Marketing- Europ. Medienforum Stgt. e. V. agentur GmbH, München Stammkapital der Vereinsbeiträge 0,98% AGF Videoforschung GmbH Frankfurt Finanzverwaltung, Controlling, Steuerung und weitere Dienstleistungen durch die SWR Media Services GmbH SWR Media Services GmbH Stammdaten I. Name III. Rechtsform SWR Media Services GmbH GmbH Sitz Stuttgart IV. Stammkapital in Euro 3.100.000 II. Anschrift V. Unternehmenszweck Standort Stuttgart - die Produktion und der Vertrieb von Rundfunk- Straße Neckarstraße 230 sendungen, die Entwicklung, Produktion und PLZ 70190 Vermarktung von Werbeeinschaltungen, Ort Stuttgart - Onlineverwertungen, Telefon (07 11) 9 29 - 0 - die Beschaffung, Produktion und Verwertung -

Facts and Figures 2020 ZDF German Television | Facts and Figures 2020
Facts and Figures 2020 ZDF German Television | Facts and Figures 2020 Facts about ZDF ZDF (Zweites Deutsches Fern German channels PHOENIX and sehen) is Germany’s national KiKA, and the European chan public television. It is run as an nels 3sat and ARTE. independent nonprofit corpo ration under the authority of The corporation has a permanent the Länder, the sixteen states staff of 3,600 plus a similar number that constitute the Federal of freelancers. Since March 2012, Republic of Germany. ZDF has been headed by Direc torGeneral Thomas Bellut. He The nationwide channel ZDF was elected by the 60member has been broadcasting since governing body, the ZDF Tele 1st April 1963 and remains one vision Council, which represents of the country’s leading sources the interests of the general pub of information. Today, ZDF lic. Part of its role is to establish also operates the two thematic and monitor programme stand channels ZDFneo and ZDFinfo. ards. Responsibility for corporate In partnership with other pub guide lines and budget control lic media, ZDF jointly operates lies with the 14member ZDF the internetonly offer funk, the Administrative Council. ZDF’s head office in Mainz near Frankfurt on the Main with its studio complex including the digital news studio and facilities for live events. Seite 2 ZDF German Television | Facts and Figures 2020 Facts about ZDF ZDF is based in Mainz, but also ZDF offers fullrange generalist maintains permanent bureaus in programming with a mix of the 16 Länder capitals as well information, education, arts, as special editorial and production entertainment and sports. -
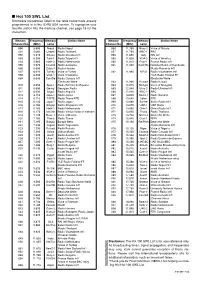
Hot 100 SWL List Shortwave Frequencies Listed in the Table Below Have Already Programmed in to the IC-R5 USA Version
I Hot 100 SWL List Shortwave frequencies listed in the table below have already programmed in to the IC-R5 USA version. To reprogram your favorite station into the memory channel, see page 16 for the instruction. Memory Frequency Memory Station Name Memory Frequency Memory Station Name Channel No. (MHz) name Channel No. (MHz) name 000 5.005 Nepal Radio Nepal 056 11.750 Russ-2 Voice of Russia 001 5.060 Uzbeki Radio Tashkent 057 11.765 BBC-1 BBC 002 5.915 Slovak Radio Slovakia Int’l 058 11.800 Italy RAI Int’l 003 5.950 Taiw-1 Radio Taipei Int’l 059 11.825 VOA-3 Voice of America 004 5.965 Neth-3 Radio Netherlands 060 11.910 Fran-1 France Radio Int’l 005 5.975 Columb Radio Autentica 061 11.940 Cam/Ro National Radio of Cambodia 006 6.000 Cuba-1 Radio Havana /Radio Romania Int’l 007 6.020 Turkey Voice of Turkey 062 11.985 B/F/G Radio Vlaanderen Int’l 008 6.035 VOA-1 Voice of America /YLE Radio Finland FF 009 6.040 Can/Ge Radio Canada Int’l /Deutsche Welle /Deutsche Welle 063 11.990 Kuwait Radio Kuwait 010 6.055 Spai-1 Radio Exterior de Espana 064 12.015 Mongol Voice of Mongolia 011 6.080 Georgi Georgian Radio 065 12.040 Ukra-2 Radio Ukraine Int’l 012 6.090 Anguil Radio Anguilla 066 12.095 BBC-2 BBC 013 6.110 Japa-1 Radio Japan 067 13.625 Swed-1 Radio Sweden 014 6.115 Ti/RTE Radio Tirana/RTE 068 13.640 Irelan RTE 015 6.145 Japa-2 Radio Japan 069 13.660 Switze Swiss Radio Int’l 016 6.150 Singap Radio Singapore Int’l 070 13.675 UAE-1 UAE Radio 017 6.165 Neth-1 Radio Netherlands 071 13.680 Chin-1 China Radio Int’l 018 6.175 Ma/Vie Radio Vilnius/Voice -

Lara Marie Müller
Lara Marie M¨uller Doctoral Candidate Contact Information Email: [email protected] Phone: +49 151 651 050 44 Academic Education PhD in Economics since 2020 University of Cologne, Cologne Graduate School of Economics Research Interest: Media Economics and Economics of Digitization Supervisors: Prof. Dr. Johannes M¨unster,Prof. Dr. Bettina Rockenbach Double Degree: Master in Economics 2018 - 2020 University of Cologne, Germany (M.Sc.) and Keio University, Japan (M.A.) One year of studies at each institution Bachelor of Science in Economics 2014 - 2018 University of Cologne Including two exchange semesters: - Warsaw School of Economics, Poland (SS2016) - Pontif´ıciaUniversidade Cat´olicado Rio de Janeiro, Brazil (WS2015/16) Research Interest I am interested in how we can design media markets that best serve society. For this, I aim to conduct mainly experimental research to gain insights on Welfare effects on digital media markets, for example in the context of personalisation or misinformation. Professional Experience Research Associate since 07/2020 Chair of Media Economics, Prof. Dr. Johannes M¨unster,University of Cologne Teaching: Exercise in Media Economics (Bachelor and Master), Seminar on Media Mar- kets (Bachelor), Supervision of Bachelor Theses Freelance Journalist 2018 - 2020 Covering mainly economics for German news outlets, magazines and broadcasters. Cus- tomers included: Handelsblatt, Welt am Sonntag, ada, Die Welt, WDR, FAZ.net, Frank- furter Allgemeine Sonntagszeitung, among others. Lecturer at K¨olnerJournalistenschule -

Download This PDF File
internet resources John H. Barnett Global voices, global visions International radio and television broadcasts via the Web he world is calling—are you listening? used international broadcasting as a method of THere’s how . Internet radio and tele communicating news and competing ideologies vision—tuning into information, feature, during the Cold War. and cultural programs broadcast via the In more recent times, a number of reli Web—piqued the interest of some educators, gious broadcasters have appeared on short librarians, and instructional technologists in wave radio to communicate and evangelize the 1990s. A decade ago we were still in the to an international audience. Many of these early days of multimedia content on the Web. media outlets now share their programming Then, concerns expressed in the professional and their messages free through the Internet, literature centered on issues of licensing, as well as through shortwave radio, cable copyright, and workable business models.1 television, and podcasts. In my experiences as a reference librar This article will help you find your way ian and modern languages selector trying to to some of the key sources for freely avail make Internet radio available to faculty and able international Internet radio and TV students, there were also information tech programming, focusing primarily on major nology concerns over bandwidth usage and broadcasters from outside the United States, audio quality during that era. which provide regular transmissions in What a difference a decade makes. Now English. Nonetheless, one of the benefi ts of with the rise of podcasting, interest in Web tuning into Internet radio and TV is to gain radio and TV programming has recently seen access to news and knowledge of perspec resurgence. -

BECOMING PAN-EUROPEAN? Transnational Media and the European Public Sphere
The International Communication Gazette © The Author(s), 2009. Reprints and permissions: http://www.sagepub.co.uk/journalsPermissions.nav the International Communication Gazette, 1748-0485; Vol. 71(8): 693–712; DOI: 10.1177/1748048509345064 http://gaz.sagepub.com BECOMING PAN-EUROPEAN? Transnational Media and the European Public Sphere Michael Brüggemann and Hagen Schulz-Forberg Abstract / Research about the European public sphere has so far mainly focused on the analysis of national media, neglecting a dimension of transnational communication, namely transnational media. These media could serve as horizontal links between the still nationally segmented public spheres and they could be platforms of a transnational European discourse. Four ideal-types of transnational media can be distinguished: (1) national media with a transnational mission, (2) inter- national media, (3) pan-regional media and (4) global media. Within this framework the article analyses transnational media in Europe, showing that a multitude of transnational media have developed in Europe. They have acquired a small but growing and influential audience. Whether transnational media fulfil the normative demands related to the concept of a transnational public sphere remains an open question as some of these media heavily depend on government subsidies and there is a clear lack of research on the European discourses represented in these media. Keywords / EU / European media / European integration / international communication / public sphere / transnational communication / transnational media Introduction: Transnational Media and the European Public Sphere Current research on the European public sphere focuses mainly on the European- ization of national public spheres as opposed to transnational spaces of communi- cation. This approach developed out of research proposals and projects beginning in the 1990s and early 2000s that operationalized a nation-based media analysis in order to understand the public sphere’s development in the EU. -

TV News Channels in Europe: Offer, Establishment and Ownership European Audiovisual Observatory (Council of Europe), Strasbourg, 2018
TV news channels in Europe: Offer, establishment and ownership TV news channels in Europe: Offer, establishment and ownership European Audiovisual Observatory (Council of Europe), Strasbourg, 2018 Director of publication Susanne Nikoltchev, Executive Director Editorial supervision Gilles Fontaine, Head of Department for Market Information Author Laura Ene, Analyst European Television and On-demand Audiovisual Market European Audiovisual Observatory Proofreading Anthony A. Mills Translations Sonja Schmidt, Marco Polo Sarl Press and Public Relations – Alison Hindhaugh, [email protected] European Audiovisual Observatory Publisher European Audiovisual Observatory 76 Allée de la Robertsau, 67000 Strasbourg, France Tel.: +33 (0)3 90 21 60 00 Fax. : +33 (0)3 90 21 60 19 [email protected] http://www.obs.coe.int Cover layout – ALTRAN, Neuilly-sur-Seine, France Please quote this publication as Ene L., TV news channels in Europe: Offer, establishment and ownership, European Audiovisual Observatory, Strasbourg, 2018 © European Audiovisual Observatory (Council of Europe), Strasbourg, July 2018 If you wish to reproduce tables or graphs contained in this publication please contact the European Audiovisual Observatory for prior approval. Opinions expressed in this publication are personal and do not necessarily represent the view of the European Audiovisual Observatory, its members or the Council of Europe. TV news channels in Europe: Offer, establishment and ownership Laura Ene Table of contents 1. Key findings ...................................................................................................................... -

“MISSION EUROPE” a Bilingual Radio Fiction & a Quest
“MISSION EUROPE” A bilingual radio fiction & a quest “Mission Europe” aims to help young Europeans become familiar with other European languages and cultures. The project is based on an original concept drafted by RFI which enables listeners to follow a bilingual radio-drama with little to no effort. The listeners follow the story of a heroine who speaks in their native tongue, and must learn to get by in a foreign culture with another language. Radio France Internationale, Deutsche Welle and Polskie Radio have joined forces in order to produce three series of 26 episodes. “Mission Berlin”, “Misja Kraków” and “Mission Paris” are three quests, each set in a video game. The player must guide his avatar on dangerous missions in Gemany, France and Poland respectively, finding clues and winning points. The player and his avatar must not only face extraordinary challenges, but also cope with everyday problems as they navigate the cities. In order to do this successfully they must ask for help and unveil their enemies’ identities by learning communication skills appropriate to the country’s language and culture. The listeners follow the video game adventures from the point of view of the player and his avatar who – just like the computer - speak the listeners’ mothertongue. The three series will be broadcast in Europe by the three radio stations involved as well as any other radiostations that are interested. It is possible to produce versions of the series combining any two languages. The co-producers will ensure the promotion of this original concept, by targeting organisations such as radio stations, language learning centres, cultural exchange networks and tourist boards. -

Climate Change and the Media
THE HEAT IS ON CLIMATE CHanGE anD THE MEDIA PROGRAM INTERNATIONAL ConFerence 3-5 JUNE 2009 INTERNATIONALWorl CONFERENCED CONFERENCE CENTER BONN 21-23 JUNE 2010 WORLD CONFERENCE CENTER BONN 3 WE KEEP THINGS MOving – AND AN EYE ON THE ENVIRONMENT. TABLE OF CONTENTS THAt’s hoW WE GOGREEN. MESSAGE FROM THE ORGANIZERS 4 HOSTS AND SuppORTING ORGANIZATIONS 11 PROTECTING THE ENVIRONMENT 15 GLOBAL STudY ON CLIMATE CHANGE 19 PROGRAM OVERVIEw 22 SITE PLAN 28 PROGRAM: MONDAY, 21 JUNE 2010 33 PROGRAM: TuESDAY, 22 JUNE 2010 82 PROGRAM: WEDNESDAY, 23 JUNE 2010 144 SidE EVENTS 164 GENERAL INFORMATION 172 ALPHABETICAL LIST OF PARTICipANTS 178 For more information go to MAp 192 www.dhl-gogreen.com IMPRINT 193 21–23 JUNE 2010 · BONN, GERMANY GoGreen_Anz_DHL_e_Deutsche Welle_GlobalMediaForum_148x210.indd 1 30.03.2010 12:51:02 Uhr 4 5 MESSAGE FROM THE MESSAGE FROM THE HOST FEDERAL MiNISTER FOR FOREIGN AFFAIRS Nothing is currently together more than 50 partners, sponsors, Extreme weather, With its manifold commitment, Germany being debated more media representatives, NGOs, government crop failure, fam- has demonstrated that it is willing to accept than climate change. and inter-government institutions. Co-host ine – the poten- responsibility for climate protection at an It has truly captured of the Deutsche Welle Global Media Forum tially catastrophic international level. Our nation is known for the world’s atten- is the Foundation for International Dialogue consequences that its clean technology and ideas, and for cham- tion. Do we still have of the Sparkasse in Bonn. The convention is climate change will pioning sustainable economic structures that enough time to avoid also supported by Germany’s Federal Foreign have for millions of pursue both economic and ecological aims. -

Shifting Powers
S h i ft i n g powers May 27 – 28, 2019 Bonn, Germany dw.com/gmf | #dw_gmf ADVERTISEMENT Curious about Germany? Getty Images (4) Discover a diverse, modern country on www.deutschland.de. Everything you need to know about politics, business, society and culture – and the most important tips on studying and working in Germany. facebook.com/deutschland.de twitter.com/en_germany instagram.com/deutschland_de blog.deutschland.de DW-GMF-ENG-A6-Anzeige.indd 1 01.04.2019 16:54:34 TABLE OF CONTENTS Curious about Germany? Message from the host 5 Our main partners 6 Supporting organizations 8 Social media 10 Site plan 12 Program: Monday, May 27 15 Program: Tuesday, May 28 16 Arts and culture 18 Getty Images (4) Side events 22 Imprint 30 Discover a diverse, modern country on www.deutschland.de. Everything you need to know about politics, business, society and culture – and the most important tips on studying and working in Germany. facebook.com/deutschland.de twitter.com/en_germany instagram.com/deutschland_de blog.deutschland.de 3 DW-GMF-ENG-A6-Anzeige.indd 1 01.04.2019 16:54:34 ADVERTISEMENT Message from the Host TARAFSIZ GÜNDEME BAĞLAN dw.com/whereicomefrom 4 MESSAGE FROM THE HOST A warm welcome to DW’s Global Media Forum! At this year’s Global Media Forum we are go- ing to discuss the eff ects of shifting powers DW around the world. Populists from all ends of © the spectrum are threatening the integrity of Europe. Autocrats are forging their positions — with or without the ballot box. Controlling access to information has become a tool of power. -

A Bilingual Radio Fiction & a Quest “Mission Europe”
“MISSION EUROPE” A bilingual radio fiction & a quest “Mission Europe” aims to help young Europeans become familiar with other European languages and cultures. The project is based on an original concept drafted by RFI which enables listeners to follow a bilingual radio-drama with little to no effort. The listeners follow the story of a heroine who speaks in their native tongue, and must learn to get by in a foreign culture with another language. Radio France Internationale, Deutsche Welle and Polskie Radio have joined forces in order to produce three series of 26 episodes. “Mission Berlin” , “Misja Kraków” and “Mission Paris” are three quests, each set in a video game. The player must guide his avatar on dangerous missions in Gemany, France and Poland respectively, finding clues and winning points. The player and his avatar must not only face extraordinary challenges, but also cope with everyday problems as they navigate the cities. In order to do this successfully they must ask for help and unveil their enemies’ identities by learning communication skills appropriate to the country’s language and culture. The listeners follow the video game adventures from the point of view of the player and his avatar who – just like the computer - speak the listeners’ mothertongue. The three series will be broadcast in Europe by the three radio stations involved as well as any other radiostations that are interested. It is possible to produce versions of the series combining any two languages. The co-producers will ensure the promotion of this original concept, by targeting organisations such as radio stations, language learning centres, cultural exchange networks and tourist boards. -

Standardformular 2
Supplement zum Amtsblatt der Europäischen Union Infos und Online-Formulare: http://simap.ted.europa.eu Auftragsbekanntmachung Richtlinie 2014/24/EU Abschnitt I: Öffentlicher Auftraggeber I.1) Name und Adressen (in beliebiger Anzahl wiederholen)(alle für das Verfahren verantwortlichen öffentlichen Auftraggeber angeben) Offizielle Bezeichnung: Nationale Identifikationsnummer: Deutsche Welle, Standort Bonn (falls zutreffend) Postanschrift: Kurt-Schumacher-Str. 3 Ort: Bonn Postleitzahl: 53113 Land: DE NUTS-Code: DEA22 Kontaktstelle(n): Procurement and Travel Telefon: +49 2284292342 E-Mail: [email protected] Fax: +49 2284292350 Internet-Adresse(n) Hauptadresse: http://www.dw.com/zentraleinkauf Adresse des Beschafferprofils (URL): http://www.dtvp.de Offizielle Bezeichnung: Nationale Identifikationsnummer: Mitteldeutscher Rundfunk (falls zutreffend) Postanschrift: Ort: Leipzig Postleitzahl: 04275 Land: DE NUTS-Code: DED51 Kontaktstelle(n): Telefon: +49 2284292342 E-Mail: [email protected] Fax: +49 2284292350 Internet-Adresse(n) Hauptadresse: http://www.dtvp.de Adresse des Beschafferprofils (URL): I.2) Gemeinsame Beschaffung Der Auftrag betrifft eine gemeinsame Beschaffung Im Falle einer gemeinsamen Beschaffung, an der verschiedene Länder beteiligt sind – geltendes nationales Beschaffungsrecht: Der Auftrag wird von einer zentralen Beschaffungsstelle vergeben I.3) Kommunikation Die Auftragsunterlagen stehen für einen uneingeschränkten und vollständigen direkten Zugang gebührenfrei zur Verfügung unter: (URL) https://www.dtvp.de/Satellite/notice/CXS0Y5AYYHP/documents