Proceedings of the EMNLP'2014 Workshop on Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Comparison of MT Methods for Closely Related Languages
A Comparison of MT Methods for Closely Related Languages: a Case Study on Czech – Slovak Language Pair ∗ Vladislav Kubonˇ 1 Jernej Viciˇ cˇ2,3 1Institute of Formal and Applied Linguistics 2FAMNIT Faculty of Mathematics and Physics University of Primorska, Charles University in Prague 3Fran Ramovsˇ Institute of the [email protected] Slovenian Language, SRC SASA, [email protected] Abstract (Scannell, 2006) for Gaelic languages; Irish • (Gaeilge) and Scottish Gaelic (G‘aidhlig). This paper describes an experiment compar- ing results of machine translation between two (Tyers et al., 2009) for the North Sami to Lule • closely related languages, Czech and Slovak. Sami language pair. The comparison is performed by means of two MT systems, one representing rule-based ap- Guat (Viciˇ c,ˇ 2008) for Slavic languages with rich • proach, the other one representing statistical inflectional morphology, mostly language pairs approach to the task. Both sets of results are with Slovenian language. manually evaluated by native speakers of the target language. The results are discussed both Many of the systems listed above had been created from the linguistic and quantitative points of in the period when it was hard to obtain a good qual- view. ity data-driven system which would enable comparison against these systems. The existence of Google Trans- 1 Introduction late1 which nowadays enables the automatic translation even between relatively small languages made it possi- Machine translation (MT) of related languages is a spe- ble to investigate advantages and disadvantages of both cific field in the domain of MT which attracted the at- approaches. This paper introduces the first step in this tention of several research teams in the past by promis- direction - the comparison of results of two different ing relatively good results through the application of systems for two really very closely related languages - classic rule-based methods. -

Czech Language and Literature Peter Zusi
chapter 17 Czech Language and Literature Peter Zusi Recent years have seen a certain tendency to refer to Kafka as a ‘Czech’ author – a curious designation for a writer whose literary works, without exception, are composed in German. As the preceding chapter describes, Kafka indeed lived most of his life in a city where Czech language and society gradually came to predominate over the German-speaking minor- ity, and Kafka – a native German-speaker – adapted deftly to this changing social landscape. Referring to Kafka as Czech, however, is inaccurate, explicable perhaps only as an attempt to counterbalance a contrasting simplification of his complicated biography: the marked tendency within Kafka scholarship to investigate his work exclusively in the context of German, Austrian or Prague-German literary history. The Czech socio-cultural impulses that surrounded Kafka in his native Prague have primarily figured in Kafka scholarship through sociological sketches portraying ethnic animosity, lack of communication and, at times, open violence between the two largest lin- guistic communities in the city. These historical realities have given rise to the persistent image of a ‘dividing wall’ between the Czech- and German- speaking inhabitants of Prague, with the two populations reading different newspapers, attending separate cultural institutions and congregating in segregated social venues. This image of mutual indifference or antagonism has often made the question of Kafka’s relation to Czech language and cul- ture appear peripheral. Yet confronting the perplexing blend of proximity and distance, famil- iarity and resentment which characterized inter-linguistic and inter- cultural contact in Kafka’s Prague is a necessary challenge. -

International Research and Exchanges Board Records
International Research and Exchanges Board Records A Finding Aid to the Collection in the Library of Congress Prepared by Karen Linn Femia, Michael McElderry, and Karen Stuart with the assistance of Jeffery Bryson, Brian McGuire, Jewel McPherson, and Chanté Wilson-Flowers Manuscript Division Library of Congress Washington, D.C. 2011 International Research and Exchanges Board Records Page ii Collection Summary Title: International Research and Exchanges Board Records Span Dates: 1947-1991 (bulk 1956-1983) ID No: MSS80702 Creator: International Research and Exchanges Board Creator: Inter-University Committee on Travel Grants Extent: 331,000 items; 331 cartons; 397.2 linear feet Language: Collection material in English and Russian Repository: Manuscript Division, Library of Congress, Washington, D.C. Abstract: American service organization sponsoring scholarly exchange programs with the Soviet Union and Eastern Europe in the Cold War era. Correspondence, case files, subject files, reports, financial records, printed matter, and other records documenting participants’ personal experiences and research projects as well as the administrative operations, selection process, and collaborative projects of one of America’s principal academic exchange programs. International Research and Exchanges Board Records Page iii Contents Collection Summary .......................................................... ii Administrative Information ......................................................1 Organizational History..........................................................2 -
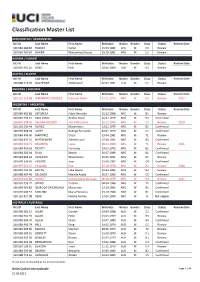
Classification Master List
Classification Master List AFGHANISTAN / AFGHANISTAN UCI ID Last Name First Name Birthdate Nation Gender Class Status Review Date 100 084 489 83 HAZRAT Qaher 15.03.1982 AFG M C3 Review 100 084 490 84 SHAIDA Mohammad Haider 29.10.1981 AFG M C2 Review ALBANIA / ALBANIE UCI ID Last Name First Name Birthdate Nation Gender Class Status Review Date 100 084 491 85 DOKU Haki 18.06.1969 ALB M H3 Review ALGERIA / ALGERIE UCI ID Last Name First Name Birthdate Nation Gender Class Status Review Date 100 088 713 39 OUCHENNE Abderraouf 02.07.1991 ALG M C2 Review ANDORRA / ANDORRE UCI ID Last Name First Name Birthdate Nation Gender Class Status Review Date 100 112 216 68 FERNANDEZ VAZQUEZ Francesc Xavier 19.11.1972 AND M H3 Review 2017 ARGENTINA / ARGENTINE UCI ID Last Name First Name Birthdate Nation Gender Class Status Review Date 100 084 492 86 ASTORECA Pablo Reinaldo 01.12.1968 ARG M B1 Review 100 084 493 87 BIGA VIDAL Andres Oscar 26.07.1979 ARG M H3 Confirmed 100 891 328 76 GALVAN AGUERO Joel Pablo Dario 20.11.1997 ARG M C3 Review 2020 100 101 236 49 GOMEZ Maximiliano 12.02.1979 ARG M B1 Confirmed 100 599 698 28 LOPEZ Rodrigo Fernando 03.01.1979 ARG M C1 Confirmed 100 084 496 90 MARTINEZ Oscar 19.04.1981 ARG M T1 Review 100 084 497 91 NATTKEMPER Alberto Lujan 07.08.1951 ARG M B2 Confirmed 100 839 719 71 NEGREIRA Lucas 08.11.2000 ARG M T1 Review 2021 100 084 499 93 RICATTI Fernando 24.02.1976 ARG M B1 Confirmed 100 084 500 94 SILVA Martin 30.07.1989 ARG M B1 Confirmed 100 599 694 24 VAQUERO Maximiliano 10.05.1991 ARG M B1 Review 100 609 336 63 VICENTE -

'New Look' in Name's Standardization in Ukraine Iryna Sofinska Abstract ***** My Country Has a Long-Going History Despite All Pa
ONOMÀSTICA BIBLIOTECA TÈCNICA DE POLÍTICA LINGÜÍSTICA 'New look' in name's standardization in Ukraine Iryna Sofinska DOI: 10.2436/15.8040.01.95 Abstract In this article I concentrate mostly on standardization applied to anthroponymy in Ukraine, however, in fact, till now there are no official standards of names. Therefore, after the ‘iron curtain’ failed among ordinary citizens there appeared a seduction for young parents to be not like the others and to give their children names, which are far from Ukrainian traditions and religious views, but popular in other countries of the world and are used in other languages. Such names entered into general Ukrainian onomasticon through the music, literature, movies, television etc. but still remain very rare. Nowadays, the main issue is dedicated to correct transcription and transliteration of registered names, and therefore, to demonstrate position of the State in this particular question. According to the reports of the Ministry of Justice of Ukraine for last five years almost ‘standardized’ onomasticon of popular names in Ukraine have not been changed seriously, however, Ukrainian forms of names prevail over the others. ***** My country has a long-going history despite all parts of the modern Ukraine since XIV century and till the end of World War II were separated. They were parts of different countries with different legal systems and anthroponymic traditions. Even during a turbulent 20th century (we can characterize it by periods of political upheaval, brutal dictatorship, forced famine, genocide, war, resistance movements, economic uncertainty and renewal of independence) territory of Ukraine was divided in several parts, which have been included into different European countries (Austria and Hungary, Czech and Slovakia, Poland, Romania and Soviet Union) with different ethnicity, language, religion, administrative and political structure, level of economic and industrial development. -

Memory and Authority in the Ninth-Century Dalmatian Duchy
Marino Kumir MEMORY AND AUTHORITY IN THE NINTH-CENTURY DALMATIAN DUCHY MA Thesis in Medieval Studies Central European University CEU eTD Collection Budapest May 2016 MEMORY AND AUTHORITY IN THE NINTH-CENTURY DALMATIAN DUCHY by Marino Kumir (Croatia) Thesis submitted to the Department of Medieval Studies, Central European University, Budapest, in partial fulfillment of the requirements of the Master of Arts degree in Medieval Studies. Accepted in conformance with the standards of the CEU. ____________________________________________ Chair, Examination Committee ____________________________________________ Thesis Supervisor ____________________________________________ Examiner ____________________________________________ Examiner CEU eTD Collection Budapest May 2016 MEMORY AND AUTHORITY IN THE NINTH-CENTURY DALMATIAN DUCHY by Marino Kumir (Croatia) Thesis submitted to the Department of Medieval Studies, Central European University, Budapest, in partial fulfillment of the requirements of the Master of Arts degree in Medieval Studies. Accepted in conformance with the standards of the CEU. ____________________________________________ External Reader CEU eTD Collection Budapest May 2016 MEMORY AND AUTHORITY IN THE NINTH-CENTURY DALMATIAN DUCHY by Marino Kumir (Croatia) Thesis submitted to the Department of Medieval Studies, Central European University, Budapest, in partial fulfillment of the requirements of the Master of Arts degree in Medieval Studies. Accepted in conformance with the standards of the CEU. ____________________________________________ External Supervisor CEU eTD Collection Budapest May 2016 I, the undersigned, Marino Kumir, candidate for the MA degree in Medieval Studies, declare herewith that the present thesis is exclusively my own work, based on my research and only such external information as properly credited in notes and bibliography. I declare that no unidentified and illegitimate use was made of the work of others, and no part of the thesis infringes on any person’s or institution’s copyright. -

The Continuity Between the Enlightenment and Nationalism Politics and Historical Narratives of Narratives Andhistorical Politics
THE CONTINUITY BETWEEN THE ENLIGHTENMENT AND NATIONALISM: POLITICS AND HISTORICAL NARRATIVES OF THE CROATIAN NATIONAL REVIVAL By Vilim Pavlovic Submitted to Central European University History Department In partial fulfillment of the requirements for the degree of Master of Arts Supervisor: Professor László Kontler Second Reader: Professor Balázs Trencsényi CEU eTD Collection Budapest, Hungary 2014 Statement of Copyright Copyright in the text of this thesis rests with the Author. Copies by any process, either in full or part, may be made only in accordance with the instructions given by the Author and lodged in the Central European Library. Details may be obtained from the librarian. This page must form a part of any such copies made. Further copies made in accordance with such instructions may not be made without the written permission of the Author. CEU eTD Collection i Abstract This thesis provides a look the fundamental programmatic articles of the Croatian National Revival. It attempts to first contextualize the Croatian national movement within the context of the Habsburg Monarchy, and especially in regards to the relationship of Croatia and Hungary. Secondly, the thesis attempts to explore the possible continuity between the ideology of the Croatian National Revival and the Enlightenment. This is done using some of the fundamental documents of the national movement. Looking at the political program of the national movement, I attempt to identify the influences of the Enlightenment in both explicit and implicit level. Furthermore, as this thesis is on a fundamental level concerned with nationalism, I will explore the interaction between the political programs of the national movement and historical narratives as both are often found in the same text. -

General Information
MISSION STATEMENT International Youth Nuclear Congress 2000 'Youth, Future, Nuclear' (IYNC 2000), organized for the first time by a new generation of professionals in the nuclear field from different countries, was held in Bratislava Slovakia on April 9-14, 2000 to: - develop new approaches to communicate benefits of nuclear power, as part of a balanced energy mix; - promote further use of nuclear science and technology for the welfare of mankind; - transfer knowledge from the current generation of leading scientists to the next generation; - encourage the creation of a global network among young professionals. IYNC 2000 International Youth Executive Committee General Chair Alexandre Tsyboulia, IPPE Obninsk, Russia Organizing Chair Stanislav Rapavy, VUJE Trnava, Slovakia Technical Program Chair Florence Avezou, COGEMA, France Public Relations Chair Emmy Roos, Rocky Mountain Remediation Services, USA Publications & Web Chair Shannon Bragg-Sitton, University of Michigan, USA Technical Tours & Special Events Chair Robert Holy, Mochovce NPP, Slovakia International Chair Serguei Klykov, INPE Obninsk, Russia Reservations Chair Marian Kristof, Nuclear Regulatory Authority, Slovakia Registration Chair Kristina Kristofova, Decom, Slovakia Finance Chair Vladimir Michal, VUJE Trnava, Slovakia Corporate Relations Chair August Pipkin-Fern, Utility.com, USA Web-Master Sergei Tsyganov, Kurchatov Institute, Russia History Nuclear science and technology is not as popular as it was a few decades ago. There is the threat of its loss caused by the lack of -

Syllabus for SLA105, Introduction to Slavic Studies Petko Ivanov Connecticut College, [email protected]
Connecticut College Digital Commons @ Connecticut College Slavic Studies Course Materials Slavic Studies Department Fall 2014 Syllabus for SLA105, Introduction to Slavic Studies Petko Ivanov Connecticut College, [email protected] Follow this and additional works at: http://digitalcommons.conncoll.edu/slaviccourse Recommended Citation Ivanov, Petko, "Syllabus for SLA105, Introduction to Slavic Studies" (2014). Slavic Studies Course Materials. Paper 7. http://digitalcommons.conncoll.edu/slaviccourse/7 This Course Materials is brought to you for free and open access by the Slavic Studies Department at Digital Commons @ Connecticut College. It has been accepted for inclusion in Slavic Studies Course Materials by an authorized administrator of Digital Commons @ Connecticut College. For more information, please contact [email protected]. The views expressed in this paper are solely those of the author. C o n n e c t i c u t C o l l e g e Fall 2014 SLA 105 Slavic Church Emanuel, Portland, Oregon Introduction to Slavic Studies Prof. Petko Ivanov SLA 105: Slavic Studies Connecticut College Fall 2014 SLA 105: Introduction to Slavic Studies Fall 2014, Monday/Wednesday 7:00-8:45 PM Location: Blaustein 208 Slavistics for Beginners (Beck, Mast & Tapper 1997: 13) Instructor: Petko Ivanov Blaustein 330, x5449, [email protected] Office hours M/W 1:30-2:30 and by appointment Course Description The existence of “Slavic identity” in the contemporary world seems to be taken as self- evident both on the level of international politics and as an institutionalized field of knowledge (viz. Slavic Departments). Yet the very concept of Slavicness is inherently problematic. Objectively, the only feature that binds all Slavs together is linguistic – the common genealogy and the present similarities of their languages. -

The Making of the Slavs: History and Archaeology of the Lower Danube
The Making of the Slavs This book offers a new approach to the problem of Slavic ethnicity in south- eastern Europe between c. and c. , from the perspective of current anthropological theories. The conceptual emphasis here is on the relation between material culture and ethnicity. The author demonstrates that the history of the Sclavenes and the Antes begins only at around . He also points to the significance of the archaeological evidence, which suggests that specific artifacts may have been used as identity markers. This evidence also indicates the role of local leaders in building group boundaries and in leading successful raids across the Danube. The names of many powerful leaders appear in written sources, some being styled “kings.”Because of these military and political developments, Byzantine authors began employing names such as Sclavenes and Antes in order to make sense of the process of group identification that was taking place north of the Danube frontier. Slavic ethnicity is therefore shown to be a Byzantine invention. is Assistant Professor of Medieval History, University of Florida THE MAKING OF THE SLAVS History and Archaeology of the Lower Danube Region, c. – FLORIN CURTA CONTENTS List of figures page ix List of tables xiii Acknowledgments xiv List of abbreviations xv Introduction Slavic ethnicity and the ethnie of the Slavs: concepts and approaches Sources for the history of the early Slavs (c. –) The Slavs in early medieval sources (c. –) The Balkans and the Danube limes during the sixth and seventh centuries -

Hungarian Stamp Information 2016
18 Hungarian tamp Information S 2016/ JAN JESSENIUS WAS BORN 450 YEARS AGO THE FOREIGN PHILATELIC RELEASES OF THE JOINT ISSUE Polish FDC and stamp Slovak FDC, black print and stamp Czech stamp and FDC The Czech Republic, Hungary, Poland and Slovakia commemorated the 450th JESSENIUS450 - FOREIGN anniversary of the birth of Jan Jessenius by issuing a joint stamp with a label. RELEASES The countries involved in the issue are linked by hundreds of years of history, an example of Order codes: which is the life and work of Jan Jessenius from the village of Nagyjeszen in present-day 4104898: Czech stamp with a label Slovakia, who lived at the turn of the 16th and 17th centuries. The joint stamp issue also 4104901: Czech FDC underlines the historical background of the participating countries that is the same in many 4104899: Polish stamp with a label 4104905: Polish FDC respects and their similar cultural community. 4104900: Slovak stamp with a label The stamps with a label were made using the same graphic design. The stamp features a 4104902: Slovak FDC 4104903: Slovak black print portrait of Jan Jessenius by the Nuremberg engraver Lucas Kilian made in 1618 and the label 4104904: Slovak stamp set shows the title page of Jan Jessenius’ work Anatomy published in Wittenberg in 1601. Selling prices: The Czech, Slovak and Hungarian issues were printed using the gravure process in the Postal Czech stamp with a label: HUF 395 Printing House of Securities Prague Inc. (Poštovní tiskárna cenin Praha a.s.). The use of this Czech FDC: HUF 630 printing technique means that the portrait on the stamp has extremely rich tones and details. -

International Court of Justice Case Concerning
INTERNATIONAL COURT OF JUSTICE CASE CONCERNING APPLICATION OF THE INTERNATIONAL CONVENTION FOR THE SUPPRESSION OF THE FINANCING OF TERRORISM AND OF THE INTERNATIONAL CONVENTION ON THE ELIMINATION OF ALL FORMS OF RACIAL DISCRIMINATION (UKRAINE V. RUSSIAN FEDERATION) MEMORIAL SUBMITTED BY UKRAINE 12 JUNE 2018 TABLE OF CONTENTS Page Part I: INTRODUCTION ............................................................................................................ 1 Russia’s Campaign for Hegemony in Ukraine ................................ 3 Structure of the Memorial .............................................................. 9 Part II: THE RUSSIAN FEDERATION’S VIOLATIONS OF THE INTERNATIONAL CONVENTION FOR THE SUPPRESSION OF THE FINANCING OF TERRORISM .. 14 Section A: Evidence Showing the Financing of Terrorism in Ukraine ..................... 17 Chapter 1. Systematic Terrorism by Russia’s Proxies in Ukraine ............................ 17 Since Their Inception, Russia’s Proxies Have Engaged in a Pattern of Terrorist Acts to Intimidate Civilians and Coerce the Ukrainian Government .........................................................18 The Shoot-Down of Malaysia Airlines Flight 17 ......................... 28 The Shelling Attacks on Civilians in Donbas .............................. 37 The Campaign of Bombing Attacks in Ukrainian Cities............. 67 Chapter 2. Russian Financing of Terrorism in Ukraine ........................................... 80 The Massive, Russian-Supplied Arsenal of Weapons to Illegal Armed Groups in Ukraine