Essays in Czech and Slovak Language and Literature
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Proceedings of the EMNLP'2014 Workshop on Language
LT4CloseLang 2014 Proceedings of the EMNLP’2014 Workshop: Language Technology for Closely Related Languages and Language Variants October 29, 2014 Doha, Qatar Production and Manufacturing by Taberg Media Group AB Box 94, 562 02 Taberg Sweden c 2014 The Association for Computational Linguistics Order copies of this and other ACL proceedings from: Association for Computational Linguistics (ACL) 209 N. Eighth Street Stroudsburg, PA 18360 USA Tel: +1-570-476-8006 Fax: +1-570-476-0860 [email protected] ISBN 978-1-937284-96-1 ii Introduction Recent initiatives in language technology have led to the development of at least minimal language processing toolkits for all EU-official languages as well as for languages with a large number of speakers worldwide such as Chinese and Arabic. This is a big step towards the automatic processing and/or extraction of information, especially from official documents and newspapers, where the standard, literary language is used. Apart from those official languages, a large number of dialects or closely-related language variants are in daily use, not only as spoken colloquial languages but also in some written media, e.g., in SMS, chats, and social networks. Building language resources and tools for them from scratch is expensive, but the efforts can often be reduced by making use of pre-existing resources and tools for related, resource-richer languages. Examples of closely-related language variants include the different variants of Spanish in Latin America, the Arabic dialects in North Africa and the Middle East, German in Germany, Austria and Switzerland, French in France and in Belgium, Dutch in the Netherlands and Flemish in Belgium, etc. -

Inflectional Suffix Priming in Czech Verbs and Nouns
Inflectional Suffix Priming in Czech Verbs and Nouns Filip Smol´ık ([email protected]) Institute of Psychology, Academy of Sciences of the Czech Republic Politickych´ vezˇ nˇu˚ 7, Praha 1, CZ-110 00, Czech Republic Abstract research suggested that only prefixes could be primed, but not suffixes (Giraudo & Graigner, 2003). Two experiments examined if processing of inflectional affixes Recently, Dunabeitia,˜ Perea, and Carreiras (2008) were is affected by morphological priming, and whether morpho- logical decomposition applies to inflectional morphemes in vi- able to show affix priming in suffixed Spanish words. Their sual word recognition. Target words with potentially ambigu- participants processed the suffixed words faster if they were ous suffixes were preceded by primes that contained identical preceded by words with the same suffixes. The effect was also suffixes, homophonous suffixes with different function, or dif- ferent suffixes. The results partially confirmed the observa- present when the primes contained isolated suffixes only, or tion that morphological decomposition initially ignores the af- suffixes attached to strings of non-letter characters. fix meaning. With verb targets and short stimulus-onset asyn- The literature thus indicates that affixes can be primed, chrony (SOA), homophonous suffixes had similar effects as identical suffixes. With noun targets, there was a tendency to even though there may be differences between prefixes and respond faster after homophonous targets. With longer SOA in suffixes in the susceptibility to priming. However, all re- verb targets, the primes with identical suffix resulted in shorter search sketched above worked with derivational affixes. It is responses than the primes with a homophonous suffix. -

A Comparison of MT Methods for Closely Related Languages
A Comparison of MT Methods for Closely Related Languages: a Case Study on Czech – Slovak Language Pair ∗ Vladislav Kubonˇ 1 Jernej Viciˇ cˇ2,3 1Institute of Formal and Applied Linguistics 2FAMNIT Faculty of Mathematics and Physics University of Primorska, Charles University in Prague 3Fran Ramovsˇ Institute of the [email protected] Slovenian Language, SRC SASA, [email protected] Abstract (Scannell, 2006) for Gaelic languages; Irish • (Gaeilge) and Scottish Gaelic (G‘aidhlig). This paper describes an experiment compar- ing results of machine translation between two (Tyers et al., 2009) for the North Sami to Lule • closely related languages, Czech and Slovak. Sami language pair. The comparison is performed by means of two MT systems, one representing rule-based ap- Guat (Viciˇ c,ˇ 2008) for Slavic languages with rich • proach, the other one representing statistical inflectional morphology, mostly language pairs approach to the task. Both sets of results are with Slovenian language. manually evaluated by native speakers of the target language. The results are discussed both Many of the systems listed above had been created from the linguistic and quantitative points of in the period when it was hard to obtain a good qual- view. ity data-driven system which would enable comparison against these systems. The existence of Google Trans- 1 Introduction late1 which nowadays enables the automatic translation even between relatively small languages made it possi- Machine translation (MT) of related languages is a spe- ble to investigate advantages and disadvantages of both cific field in the domain of MT which attracted the at- approaches. This paper introduces the first step in this tention of several research teams in the past by promis- direction - the comparison of results of two different ing relatively good results through the application of systems for two really very closely related languages - classic rule-based methods. -

Czech Language and Literature Peter Zusi
chapter 17 Czech Language and Literature Peter Zusi Recent years have seen a certain tendency to refer to Kafka as a ‘Czech’ author – a curious designation for a writer whose literary works, without exception, are composed in German. As the preceding chapter describes, Kafka indeed lived most of his life in a city where Czech language and society gradually came to predominate over the German-speaking minor- ity, and Kafka – a native German-speaker – adapted deftly to this changing social landscape. Referring to Kafka as Czech, however, is inaccurate, explicable perhaps only as an attempt to counterbalance a contrasting simplification of his complicated biography: the marked tendency within Kafka scholarship to investigate his work exclusively in the context of German, Austrian or Prague-German literary history. The Czech socio-cultural impulses that surrounded Kafka in his native Prague have primarily figured in Kafka scholarship through sociological sketches portraying ethnic animosity, lack of communication and, at times, open violence between the two largest lin- guistic communities in the city. These historical realities have given rise to the persistent image of a ‘dividing wall’ between the Czech- and German- speaking inhabitants of Prague, with the two populations reading different newspapers, attending separate cultural institutions and congregating in segregated social venues. This image of mutual indifference or antagonism has often made the question of Kafka’s relation to Czech language and cul- ture appear peripheral. Yet confronting the perplexing blend of proximity and distance, famil- iarity and resentment which characterized inter-linguistic and inter- cultural contact in Kafka’s Prague is a necessary challenge. -

International Research and Exchanges Board Records
International Research and Exchanges Board Records A Finding Aid to the Collection in the Library of Congress Prepared by Karen Linn Femia, Michael McElderry, and Karen Stuart with the assistance of Jeffery Bryson, Brian McGuire, Jewel McPherson, and Chanté Wilson-Flowers Manuscript Division Library of Congress Washington, D.C. 2011 International Research and Exchanges Board Records Page ii Collection Summary Title: International Research and Exchanges Board Records Span Dates: 1947-1991 (bulk 1956-1983) ID No: MSS80702 Creator: International Research and Exchanges Board Creator: Inter-University Committee on Travel Grants Extent: 331,000 items; 331 cartons; 397.2 linear feet Language: Collection material in English and Russian Repository: Manuscript Division, Library of Congress, Washington, D.C. Abstract: American service organization sponsoring scholarly exchange programs with the Soviet Union and Eastern Europe in the Cold War era. Correspondence, case files, subject files, reports, financial records, printed matter, and other records documenting participants’ personal experiences and research projects as well as the administrative operations, selection process, and collaborative projects of one of America’s principal academic exchange programs. International Research and Exchanges Board Records Page iii Contents Collection Summary .......................................................... ii Administrative Information ......................................................1 Organizational History..........................................................2 -

Berkeley Linguistics Society
PROCEEDINGS OF THE FORTY-FIRST ANNUAL MEETING OF THE BERKELEY LINGUISTICS SOCIETY February 7-8, 2015 General Session Special Session Fieldwork Methodology Editors Anna E. Jurgensen Hannah Sande Spencer Lamoureux Kenny Baclawski Alison Zerbe Berkeley Linguistics Society Berkeley, CA, USA Berkeley Linguistics Society University of California, Berkeley Department of Linguistics 1203 Dwinelle Hall Berkeley, CA 94720-2650 USA All papers copyright c 2015 by the Berkeley Linguistics Society, Inc. All rights reserved. ISSN: 0363-2946 LCCN: 76-640143 Contents Acknowledgments . v Foreword . vii The No Blur Principle Effects as an Emergent Property of Language Systems Farrell Ackerman, Robert Malouf . 1 Intensification and sociolinguistic variation: a corpus study Andrea Beltrama . 15 Tagalog Sluicing Revisited Lena Borise . 31 Phonological Opacity in Pendau: a Local Constraint Conjunction Analysis Yan Chen . 49 Proximal Demonstratives in Predicate NPs Ryan B . Doran, Gregory Ward . 61 Syntax of generic null objects revisited Vera Dvořák . 71 Non-canonical Noun Incorporation in Bzhedug Adyghe Ksenia Ershova . 99 Perceptual distribution of merging phonemes Valerie Freeman . 121 Second Position and “Floating” Clitics in Wakhi Zuzanna Fuchs . 133 Some causative alternations in K’iche’, and a unified syntactic derivation John Gluckman . 155 The ‘Whole’ Story of Partitive Quantification Kristen A . Greer . 175 A Field Method to Describe Spontaneous Motion Events in Japanese Miyuki Ishibashi . 197 i On the Derivation of Relative Clauses in Teotitlán del Valle Zapotec Nick Kalivoda, Erik Zyman . 219 Gradability and Mimetic Verbs in Japanese: A Frame-Semantic Account Naoki Kiyama, Kimi Akita . 245 Exhaustivity, Predication and the Semantics of Movement Peter Klecha, Martina Martinović . 267 Reevaluating the Diphthong Mergers in Japono-Ryukyuan Tyler Lau . -

Predicting Declension Class from Form and Meaning
This is a repository copy of Predicting declension class from form and meaning. White Rose Research Online URL for this paper: https://eprints.whiterose.ac.uk/161615/ Proceedings Paper: Williams, Adina, Pimentel, Tiago, McCarthy, Arya et al. (3 more authors) (2020) Predicting declension class from form and meaning. In: Proceedings of the 58th Annual Meeting for the Association of Computational Linguistics. Reuse Items deposited in White Rose Research Online are protected by copyright, with all rights reserved unless indicated otherwise. They may be downloaded and/or printed for private study, or other acts as permitted by national copyright laws. The publisher or other rights holders may allow further reproduction and re-use of the full text version. This is indicated by the licence information on the White Rose Research Online record for the item. Takedown If you consider content in White Rose Research Online to be in breach of UK law, please notify us by emailing [email protected] including the URL of the record and the reason for the withdrawal request. [email protected] https://eprints.whiterose.ac.uk/ Predicting Declension Class from Form and Meaning Adina Williams@ Tiago PimentelD Arya D. McCarthyZ Hagen BlixË Eleanor ChodroffY Ryan CotterellD,Q @Facebook AI Research DUniversity of Cambridge ZJohns Hopkins University ËNew York University YUniversity of York QETH Zurich¨ [email protected] [email protected] [email protected] [email protected] [email protected] [email protected] Abstract The noun lexica of many natural languages are divided into several declension classes with characteristic morphological properties. -
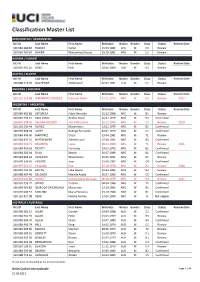
Classification Master List
Classification Master List AFGHANISTAN / AFGHANISTAN UCI ID Last Name First Name Birthdate Nation Gender Class Status Review Date 100 084 489 83 HAZRAT Qaher 15.03.1982 AFG M C3 Review 100 084 490 84 SHAIDA Mohammad Haider 29.10.1981 AFG M C2 Review ALBANIA / ALBANIE UCI ID Last Name First Name Birthdate Nation Gender Class Status Review Date 100 084 491 85 DOKU Haki 18.06.1969 ALB M H3 Review ALGERIA / ALGERIE UCI ID Last Name First Name Birthdate Nation Gender Class Status Review Date 100 088 713 39 OUCHENNE Abderraouf 02.07.1991 ALG M C2 Review ANDORRA / ANDORRE UCI ID Last Name First Name Birthdate Nation Gender Class Status Review Date 100 112 216 68 FERNANDEZ VAZQUEZ Francesc Xavier 19.11.1972 AND M H3 Review 2017 ARGENTINA / ARGENTINE UCI ID Last Name First Name Birthdate Nation Gender Class Status Review Date 100 084 492 86 ASTORECA Pablo Reinaldo 01.12.1968 ARG M B1 Review 100 084 493 87 BIGA VIDAL Andres Oscar 26.07.1979 ARG M H3 Confirmed 100 891 328 76 GALVAN AGUERO Joel Pablo Dario 20.11.1997 ARG M C3 Review 2020 100 101 236 49 GOMEZ Maximiliano 12.02.1979 ARG M B1 Confirmed 100 599 698 28 LOPEZ Rodrigo Fernando 03.01.1979 ARG M C1 Confirmed 100 084 496 90 MARTINEZ Oscar 19.04.1981 ARG M T1 Review 100 084 497 91 NATTKEMPER Alberto Lujan 07.08.1951 ARG M B2 Confirmed 100 839 719 71 NEGREIRA Lucas 08.11.2000 ARG M T1 Review 2021 100 084 499 93 RICATTI Fernando 24.02.1976 ARG M B1 Confirmed 100 084 500 94 SILVA Martin 30.07.1989 ARG M B1 Confirmed 100 599 694 24 VAQUERO Maximiliano 10.05.1991 ARG M B1 Review 100 609 336 63 VICENTE -

'New Look' in Name's Standardization in Ukraine Iryna Sofinska Abstract ***** My Country Has a Long-Going History Despite All Pa
ONOMÀSTICA BIBLIOTECA TÈCNICA DE POLÍTICA LINGÜÍSTICA 'New look' in name's standardization in Ukraine Iryna Sofinska DOI: 10.2436/15.8040.01.95 Abstract In this article I concentrate mostly on standardization applied to anthroponymy in Ukraine, however, in fact, till now there are no official standards of names. Therefore, after the ‘iron curtain’ failed among ordinary citizens there appeared a seduction for young parents to be not like the others and to give their children names, which are far from Ukrainian traditions and religious views, but popular in other countries of the world and are used in other languages. Such names entered into general Ukrainian onomasticon through the music, literature, movies, television etc. but still remain very rare. Nowadays, the main issue is dedicated to correct transcription and transliteration of registered names, and therefore, to demonstrate position of the State in this particular question. According to the reports of the Ministry of Justice of Ukraine for last five years almost ‘standardized’ onomasticon of popular names in Ukraine have not been changed seriously, however, Ukrainian forms of names prevail over the others. ***** My country has a long-going history despite all parts of the modern Ukraine since XIV century and till the end of World War II were separated. They were parts of different countries with different legal systems and anthroponymic traditions. Even during a turbulent 20th century (we can characterize it by periods of political upheaval, brutal dictatorship, forced famine, genocide, war, resistance movements, economic uncertainty and renewal of independence) territory of Ukraine was divided in several parts, which have been included into different European countries (Austria and Hungary, Czech and Slovakia, Poland, Romania and Soviet Union) with different ethnicity, language, religion, administrative and political structure, level of economic and industrial development. -

Memory and Authority in the Ninth-Century Dalmatian Duchy
Marino Kumir MEMORY AND AUTHORITY IN THE NINTH-CENTURY DALMATIAN DUCHY MA Thesis in Medieval Studies Central European University CEU eTD Collection Budapest May 2016 MEMORY AND AUTHORITY IN THE NINTH-CENTURY DALMATIAN DUCHY by Marino Kumir (Croatia) Thesis submitted to the Department of Medieval Studies, Central European University, Budapest, in partial fulfillment of the requirements of the Master of Arts degree in Medieval Studies. Accepted in conformance with the standards of the CEU. ____________________________________________ Chair, Examination Committee ____________________________________________ Thesis Supervisor ____________________________________________ Examiner ____________________________________________ Examiner CEU eTD Collection Budapest May 2016 MEMORY AND AUTHORITY IN THE NINTH-CENTURY DALMATIAN DUCHY by Marino Kumir (Croatia) Thesis submitted to the Department of Medieval Studies, Central European University, Budapest, in partial fulfillment of the requirements of the Master of Arts degree in Medieval Studies. Accepted in conformance with the standards of the CEU. ____________________________________________ External Reader CEU eTD Collection Budapest May 2016 MEMORY AND AUTHORITY IN THE NINTH-CENTURY DALMATIAN DUCHY by Marino Kumir (Croatia) Thesis submitted to the Department of Medieval Studies, Central European University, Budapest, in partial fulfillment of the requirements of the Master of Arts degree in Medieval Studies. Accepted in conformance with the standards of the CEU. ____________________________________________ External Supervisor CEU eTD Collection Budapest May 2016 I, the undersigned, Marino Kumir, candidate for the MA degree in Medieval Studies, declare herewith that the present thesis is exclusively my own work, based on my research and only such external information as properly credited in notes and bibliography. I declare that no unidentified and illegitimate use was made of the work of others, and no part of the thesis infringes on any person’s or institution’s copyright. -

Predicting Declension Class from Form and Meaning
Research Collection Conference Paper Predicting Declension Class from Form and Meaning Author(s): Williams, Adina; Pimentel, Tiago; Blix, Hagen; McCarthy, Arya D.; Chodroff, Eleanor; Cotterell, Ryan Publication Date: 2020-07 Permanent Link: https://doi.org/10.3929/ethz-b-000462306 Originally published in: http://doi.org/10.18653/v1/2020.acl-main.597 Rights / License: Creative Commons Attribution 4.0 International This page was generated automatically upon download from the ETH Zurich Research Collection. For more information please consult the Terms of use. ETH Library Predicting Declension Class from Form and Meaning Adina Williams@ Tiago PimentelD Arya D. McCarthyZ Hagen BlixË Eleanor ChodroffY Ryan CotterellD;Q @Facebook AI Research DUniversity of Cambridge ZJohns Hopkins University ËNew York University YUniversity of York QETH Zurich¨ [email protected], [email protected], [email protected], [email protected], [email protected], [email protected] Abstract The noun lexica of many natural languages are divided into several declension classes with characteristic morphological properties. Class membership is far from deterministic, but the phonological form of a noun and its + meaning can often provide imperfect clues. Here, we investigate the strength of those clues. More specifically, we operationalize “strength” as measuring how much informa- Figure 1: The conditional entropies (H) and mutual in- tion, in bits, we can glean about declension formation quantities (MI) of form (W ), meaning (V ), class from knowing the form and meaning and declension class (C), given gender (G) in German of nouns. We know that form and mean- and Czech. ing are often also indicative of grammatical gender—which, as we quantitatively verify, can itself share information with declension not are few in number. -

The Continuity Between the Enlightenment and Nationalism Politics and Historical Narratives of Narratives Andhistorical Politics
THE CONTINUITY BETWEEN THE ENLIGHTENMENT AND NATIONALISM: POLITICS AND HISTORICAL NARRATIVES OF THE CROATIAN NATIONAL REVIVAL By Vilim Pavlovic Submitted to Central European University History Department In partial fulfillment of the requirements for the degree of Master of Arts Supervisor: Professor László Kontler Second Reader: Professor Balázs Trencsényi CEU eTD Collection Budapest, Hungary 2014 Statement of Copyright Copyright in the text of this thesis rests with the Author. Copies by any process, either in full or part, may be made only in accordance with the instructions given by the Author and lodged in the Central European Library. Details may be obtained from the librarian. This page must form a part of any such copies made. Further copies made in accordance with such instructions may not be made without the written permission of the Author. CEU eTD Collection i Abstract This thesis provides a look the fundamental programmatic articles of the Croatian National Revival. It attempts to first contextualize the Croatian national movement within the context of the Habsburg Monarchy, and especially in regards to the relationship of Croatia and Hungary. Secondly, the thesis attempts to explore the possible continuity between the ideology of the Croatian National Revival and the Enlightenment. This is done using some of the fundamental documents of the national movement. Looking at the political program of the national movement, I attempt to identify the influences of the Enlightenment in both explicit and implicit level. Furthermore, as this thesis is on a fundamental level concerned with nationalism, I will explore the interaction between the political programs of the national movement and historical narratives as both are often found in the same text.