Extracting Synonyms from Bilingual Dictionaries
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
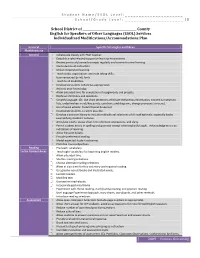
English for Speakers of Other Languages (ESOL) Services Individualized Modifications/Accommodations Plan
Student Name/ESOL Level:_____ __________ _ _ _ _ _ _ School/Grade Level: _____________________ | 1 School District of _____________________________________ County English for Speakers of Other Languages (ESOL) Services Individualized Modifications/Accommodations Plan General Specific Strategies and Ideas Modifications General Collaborate closely with ESOL teacher. Establish a safe/relaxed/supportive learning environment. Review previously learned concepts regularly and connect to new learning. Contextualize all instruction. Utilize cooperative learning. Teach study, organization, and note taking skills. Use manuscript (print) fonts. Teach to all modalities. Incorporate student culture (as appropriate). Activate prior knowledge. Allow extended time for completion of assignments and projects. Rephrase directions and questions. Simplify language. (Ex. Use short sentences, eliminate extraneous information, convert narratives to lists, underline key words/key points, use charts and diagrams, change pronouns to nouns). Use physical activity. (Total Physical Response) Incorporate students L1 when possible. Develop classroom library to include multicultural selections of all reading levels; especially books exemplifying students’ cultures. Articulate clearly, pause often, limit idiomatic expressions, and slang. Permit student errors in spelling and grammar except when explicitly taught. Acknowledge errors as indications of learning. Allow frequent breaks. Provide preferential seating. Model expected student outcomes. Prioritize course objectives. Reading Pre-teach vocabulary. in the Content Areas Teach sight vocabulary for beginning English readers. Allow extended time. Shorten reading selections. Choose alternate reading selections. Allow in-class time for free voluntary and required reading. Use graphic novels/books and illustrated novels. Leveled readers Modified text Use teacher read-alouds. Incorporate gestures/drama. Experiment with choral reading, duet (buddy) reading, and popcorn reading. -

Four Strands to Language Learning
International Journal of Innovation in English Language Teaching… ISSN: 2156-5716 Volume 1, Number 2 © 2012 Nova Science Publishers, Inc. APPLYING THE FOUR STRANDS TO LANGUAGE LEARNING Paul Nation1 and Azusa Yamamoto2 Victoria University of Wellington, New Zealand1 and Temple University Japan2 ABSTRACT The principle of the four strands says that a well balanced language course should have four equal strands of meaning focused input, meaning focused output, language focused learning, and fluency development. By applying this principle, it is possible to answer questions like How can I teach vocabulary? What should a well balanced listening course contain? How much extensive reading should we do? Is it worthwhile doing grammar translation? and How can I find out if I have a well balanced conversation course? The article describes the rationale behind such answers. The four strands principle is primarily a way of providing a balance of learning opportunities, and the article shows how this can be done in self regulated foreign language learning without a teacher. Keywords: Fluency learning, four strands, language focused learning, meaning focused input, meaning focused output. INTRODUCTION The principle of the four strands (Nation, 2007) states that a well balanced language course should consist of four equal strands – meaning focused input, meaning focused output, language focused learning, and fluency development. Each strand should receive a roughly equal amount of time in a course. The meaning focused input strand involves learning through listening and reading. This is largely incidental learning because the learners’ attention should be focused on comprehending what is being read or listened to. The meaning focused output strand involves learning through speaking and writing and in common with the meaning focused input strand involves largely incidental learning. -

Bilingual Dictionary Generation for Low-Resourced Language Pairs
Bilingual dictionary generation for low-resourced language pairs Varga István Yokoyama Shoichi Yamagata University, Yamagata University, Graduate School of Science and Engineering Graduate School of Science and Engineering [email protected] [email protected] choice and adaptation of the translation method Abstract to the problem of available translation resources between the chosen languages. Bilingual dictionaries are vital resources in One possible solution is bilingual corpus ac- many areas of natural language processing. quisition for statistical machine translation Numerous methods of machine translation re- (SMT). However, for highly accurate SMT sys- quire bilingual dictionaries with large cover- tems large bilingual corpora are required, which age, but less-frequent language pairs rarely are rarely available for less represented lan- have any digitalized resources. Since the need for these resources is increasing, but the hu- guages. Rule or sentence pattern based systems man resources are scarce for less represented are an attractive alternative, for these systems the languages, efficient automatized methods are need for a bilingual dictionary is essential. needed. This paper introduces a fully auto- Our paper targets bilingual dictionary genera- mated, robust pivot language based bilingual tion, a resource which can be used within the dictionary generation method that uses the frameworks of a rule or pattern based machine WordNet of the pivot language to build a new translation system. Our goal is to provide a low- bilingual dictionary. We propose the usage of cost, robust and accurate dictionary generation WordNet in order to increase accuracy; we method. Low cost and robustness are essential in also introduce a bidirectional selection method order to be re-implementable with any arbitrary with a flexible threshold to maximize recall. -

The Impact of Using a Bilingual Dictionary (English-Arabic) for Reading and Writing in a Saudi High School
THE IMPACT OF USING A BILINGUAL DICTIONARY (ENGLISH-ARABIC) FOR READING AND WRITING IN A SAUDI HIGH SCHOOL By Ali Almaliki A Master’s Thesis/Project Capstone Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Education Teaching English to Speakers of Other Languages (TESOL) Department of Language, Learning and leadership State University of New York at Fredonia Fredonia, New York December 2017 THE IMPACT OF USING A BILINGUAL DICTIONARY (ENGLISH-ARABIC) FOR READING AND WRITING IN A SAUDI HIGH SCHOOL ABSTRACT The purpose of this study is to explore the impact of using a bilingual dictionary (English- Arabic) for reading and writing in a Saudi high school and also to explore the Saudi Arabian students’ attitudes and EFL teachers’ perceptions toward the use of bilingual dictionaries. This study involves 65 EFL students and 5 EFL teachers in one Saudi high school in the city of Alkobar. Mixed methods research is used in which both qualitative and quantitative data are collected. For participating students, pre-test, post-test, and surveys are used to collect quantitative data. For participating teachers and students, in-person interviews are conducted with select teachers and students so as to collect qualitative data. This study has produced eight findings; first is that the use of a bilingual dictionary has a significant effect on the reading and writing scores for both high and low proficiency EFL students. Other findings include that most EFL students feel that using a bilingual dictionary in EFL classrooms is very important to help them translate and learn new vocabulary words but their use of a bilingual dictionary is limited by the strategies for use that students know or are taught, and that both invoice and experienced EFL teachers agree that the use of a bilingual dictionary is important for learning word meaning and vocabulary, but they do not all agree about which grades should use bilingual dictionaries. -

Dictionaries in the ESL Classroom
7/22/2009 The need for dictionaries in the ESL classroom: Dictionaries empower students by making them responsible for their own learning. Once students are able to use a dictionary well, they are self-sufficient in Dictionaries: finding the information on their own. Use and Function in the ESL Dictionaries present a very useful tool in the ESL classroom. However, teachers need to EXPLICITLY teach students skills so that they can be Classroom utilized to maximum extent. Dictionary use can enhance vocabulary acquisition and comprehension. If the dictionary is sufficiently current, and idiomatic colloquialisms are included, the student can [also] see representations of contemporary culture as seen through language. Why teachers need to explicitly teach dictionary skills: “If we do not teach students how to use the dictionary, it is unlikely that they will demand that they be taught, since, while teachers do not believe that students have adequate dictionary skills, students believe that they do” (Bilash, Gregoret & Loewen, 1999, p.4). Dictionary use skills: Dictionaries are not self explanatory; directions need to be made clear so that students can disentangle information, and select the appropriate meaning for the task at hand. Students need to learn how a dictionary works, how a dictionary or reference resource can help them, and also how to become aware of what they need and what kind of dictionary will best respond to their needs. Teachers need to firstly make sure that students are acquainted and familiar with the alphabet and its order. Secondly, teachers need to orientate students as to what a dictionary As students become more familiar and comfortable with basic dictionary entails, its functions, and relative terminology. -

Bilingual Word-To-Word Glossaries List: for Use with the M-STEP and MI-Access Assessments
Bilingual Word-to-Word Glossaries List: For use with the M-STEP and MI-Access Assessments List of Bilingual Word-to-Word Dictionaries and Glossaries The Office of Standards & Assessment (OSA) approves the following bilingual dictionaries and glossaries for use on Michigan Test of Educational Progress (M-STEP) and MI-Access tests (Available as appropriate, see Michigan’s Accommodations Manual). More specifically, word-to- word bilingual dictionaries may be used with the M-STEP and MI-Access Assessments only. Please note that the use of dictionaries of any kind is prohibited on the WIDA assessments: W-APT, ACCESS for ELLs, and Alternate ACCESS for ELLs. Educators should refer to the OSA accessibility tables and guidance for more information on this type of support. These word-to-word bilingual dictionaries can be used by students who are currently reported as English learners (ELs) or who have been reported as ELs in prior years and may still need this support from time-to-time in the classroom. The bilingual dictionaries and glossaries listed in this publication are limited to those that provide word-to-word translations only. A list of distributors appears at the end of this publication. This is not an exhaustive list of available bilingual word-to- word dictionaries, but is intended to aid districts in their selection process and ensuring that students who may need this support for the classroom and assessment have access to it. Additionally, students who may use electronic word-to-word dictionaries in the classroom must use a paper based version for Michigan’s assessments. -
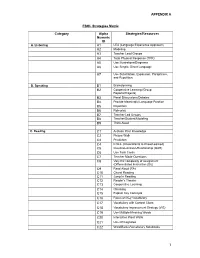
APPENDIX a ESOL Strategies Matrix Category Alpha Numeric ID
APPENDIX A ESOL Strategies Matrix Category Alpha Strategies/Resources Numeric ID A. Listening A1 LEA (Language Experience Approach) A2 Modeling A3 Teacher Lead Groups A4 Total Physical Response (TPR) A5 Use Illustrations/Diagrams A6 Use Simple, Direct Language A7 Use Substitution, Expansion, Paraphrase, and Repetition. B. Speaking B1 Brainstorming B2 Cooperative Learning (Group Reports/Projects) B3 Panel Discussions/Debates B4 Provide Meaningful Language Practice B5 Repetition B6 Role-play B7 Teacher-Led Groups B8 Teacher/Student/Modeling B9 Think Aloud C. Reading C1 Activate Prior Knowledge C2 Picture Walk C3 Prediction C4 K-W-L (Know/Wants to Know/Learned) C5 Question-Answer-Relationship (QAR) C6 Use Task Cards C7 Teacher Made Questions C8 Vary the complexity of assignment (Differentiated Instruction (DI)) C9 Read Aloud (RA) C10 Choral Reading C11 Jump In Reading C12 Reader’s Theater C13 Cooperative Learning C14 Chunking C15 Explain Key Concepts C16 Focus on Key Vocabulary C17 Vocabulary with Context Clues C18 Vocabulary Improvement Strategy (VIS) C19 Use Multiple Meaning Words C20 Interactive Word Walls C21 Use Of Cognates C22 Word Banks/Vocabulary Notebooks 1 APPENDIX A C23 Decoding/Phonics/Spelling C24 Unscramble: Sentences/Words C25 Graphic Organizers C26 Semantic Mapping C27 Timelines C28 Praise-Question-Polish (PQP) C29 Visualization C30 Reciprocal Teaching C31 Context Clues C32 Verbal Clues/Pictures C33 Schema Stories C34 Captioning C35 Venn Diagrams C36 Story Maps C37 Structural Analysis C38 Reading for a Specific Purpose C39 Pantomimes/Dramatization C40 Interview C41 Retelling C42 Think/Pair/Share C43 Dictation C44 Cloze Procedures C45 Graphic Representations C46 Student Self Assessment C47 Flexible Grouping C48 Observation/Anecdotal C49 Portfolios C50 Wordless/Picture Books C51 Highlighting Text C52 Note-Taking/ Outline Notes C53 Survey/Question/Read/Recite/Review (SQ3R) C54 Summarizing C55 Buddy/Partner Reading C56 Collaborative Groups C57 Pacing of Lessons C58 Exit Slips C59 Sustained Silent Reading (SSR) D. -

Revitalizing Indigenous Languages
Revitalizing Indigenous Languages edited by Jon Reyhner Gina Cantoni Robert N. St. Clair Evangeline Parsons Yazzie Flagstaff, Arizona 1999 Revitalizing Indigenous Languages is a compilation of papers presented at the Fifth Annual Stabilizing Indigenous Languages Symposium on May 15 and 16, 1998, at the Galt House East in Louisville, Kentucky. Symposium Advisory Board Robert N. St. Clair, Co-chair Evangeline Parsons Yazzie, Co-chair Gina Cantoni Barbara Burnaby Jon Reyhner Symposium Staff Tyra R. Beasley Sarah Becker Yesenia Blackwood Trish Burns Emil Dobrescu Peter Matallana Rosemarie Maum Jack Ramey Tina Rose Mike Sorendo Nancy Stone B. Joanne Webb Copyright © 1999 by Northern Arizona University ISBN 0-9670554-0-7 Library of Congress Catalog Card Number: 99-70356 Second Printing, 2005 Additional copies can be obtained from College of Education, Northern Ari- zona University, Box 5774, Flagstaff, Arizona, 86011-5774. Phone 520 523 5342. Reprinting and copying on a nonprofit basis is hereby allowed with proper identification of the source except for Richard Littlebear’s poem on page iv, which can only be reproduced with his permission. Publication information can be found at http://jan.ucc.nau.edu/~jar/TIL.html ii Contents Repatriated Bones, Unrepatriated Spirits iv Richard Littlebear Introduction: Some Basics of Language Revitalization v Jon Reyhner Obstacles and Opportunities for Language Revitalization 1. Some Rare and Radical Ideas for Keeping Indigenous Languages Alive 1 Richard Littlebear 2. Running the Gauntlet of an Indigenous Language Program 6 Steve Greymorning Language Revitalization Efforts and Approaches 3. Sm’algyax Language Renewal: Prospects and Options 17 Daniel S. Rubin 4. Reversing Language Shift: Can Kwak’wala Be Revived 33 Stan J. -

Best-Practice Strategies to Use with Secondary English Language Learners in Content Areas
Best-Practice Strategies to Use with Secondary English Language Learners in Content Areas Modifying Instruction for Secondary ESL in Social Studies Dr. Stella Belsky, ESL Secondary Specialist, Carrollton-Farmers Branch ISD 1 Sources • Texas Education Agency Bilingual-ESL resources - http://www.tea.state.tx.us/curriculum/biling/tearesour ces.html • Enriching Content Classes for Secondary ESOL Students. J. H. Jameson. Center for Applied Linguistics, 1998 • Classroom Instruction that Works: Research-based Strategies for Increasing Student Achievement. Robert J. Marzano, Debra J. Pickering, Jane E. Pollock. ASCD, 2001. • Middle & High School ESL Teachers, Carrollton – Farmers Branch ISD Dr. Stella Belsky, ESL Secondary Specialist, Carrollton-Farmers Branch ISD 2 Modifications for Second Language Learners • According to §89.1210 Program Content and Design, the district shall modify the instruction, pacing, and materials to ensure that limited English proficient students have a full opportunity to master the essential knowledge and skills of the required curriculum. • Teachers are required and will be held accountable for modifying the instruction, pace, and materials to ensure that LEP students have a full opportunity to master the essential knowledge and skills of the required curriculum. (TEA, July 1999) Dr. Stella Belsky, ESL Secondary Specialist, Carrollton-Farmers Branch ISD 3 This is How a Paragraph Looks to ESL Students: • Beginning ESL Students The___in New York are very___in the___. There are not many___about and the___are made by___and not___. You___the___of___in the___, the___of the___, the___of___ ___ in the___and the___of the___. • Intermediate ESL Students The___Gardens in New York are very___in the morning. There are not many persons about and the sounds are made by___and not men. -

Bilingual Dictionaries, the Lexicographer and the Translator
Bilingual Dictionaries, the Lexicographer and the Translator Rachélle Gauton, Department of African Languages, University of Pretoria, Pretoria, Republic of South Africa ([email protected]) Abstract: This article focuses on the problems, and advantages and disadvantages of the bilin- gual dictionary from both the lexicographer's and the translator's point of view, with specific refer- ence to bilingual Zulu dictionaries. It is shown that there are many and varying problems the lexi- cographer has to deal with and take cognisance of when compiling a translation dictionary. Of these, the main problem is the basic lack of equivalence or anisomorphism which exists between languages. This non-equivalence between languages is also the root cause of the difficulties with which the translator or user of the bilingual dictionary has to contend. The problems experienced by translators therefore overlap to a great extent with those which the lexicographer experiences in compiling a bilingual dictionary. It is concluded that the user of a bilingual dictionary should not only know what to expect to find in a translation dictionary, but must also treat such a dictionary with caution and discernment. It is also shown that there are clear criteria which the lexicographer can follow in compiling a bilingual dictionary, which would then enable the user (and in particular the translator as user) to disambiguate the recorded information successfully. Keywords: BILINGUAL DICTIONARIES, LEXICOGRAPHER, TRANSLATOR, ISIZULU, PROBLEMS EXPERIENCED BY LEXICOGRAPHERS, PROBLEMS EXPERIENCED BY TRANS- LATORS, NONEQUIVALENCE BETWEEN LANGUAGES, CHARACTER, SHORTCOMINGS AND ADVANTAGES OF BILINGUAL DICTIONARIES Opsomming: Tweetalige woordeboeke, die leksikograaf en die vertaler. Die fokus van hierdie artikel is op die probleme, en voor- en nadele van die tweetalige woordeboek vanuit die oogpunt van sowel die leksikograaf as die vertaler, met spesifieke verwysing na tweeta- lige Zuluwoordeboeke. -

Dictionary Policy Located on the TEA’S STAAR Resources Webpage
TEA approval is NOT required. ARF Texas Education Agency® Dictionary Description of Accommodation This accommodation, or designated support, facilitates comprehension of unfamiliar words and provides spelling assistance for a student. Assessments For a student who meets the eligibility criterion, this accommodation may be used on • STAAR and STAAR Spanish grades 3–5 reading • STAAR and STAAR Spanish grade 4 writing (all sections of the assessment) Student Eligibility Criteria A student may use this accommodation if he or she rrroutinely, independently, and effectively uses this accommodation during classroom instruction and classroom testing. Authority for Decision and Required Documentation • For a student not receiving special education or Section 504 services, the decision is made by the appropriate team of people at the campus level (e.g., RTI team, student assistance team) based on the eligibility criterion and is documented according to district policies. • For a student who is an ELL, the decision is made by the LPAC based on the eligibility criterion and is documented in the student’s permanent record file. • For a student receiving Section 504 services, the decision is made by the Section 504 committee based on the eligibility criterion and is documented in the student’s IAP. • For a student receiving special education services, the decision is made by the ARD committee based on the eligibility criterion and is documented in the student’s IEP. • In the case of an ELL with a disability, the decision is made by the applicable group above in conjunction with the student’s LPAC. The decision is to be documented by the LPAC in the student’s permanent record file and by the other applicable group, as described above. -

From the Bilingual to the Monolingual Dictionary Gabriele Stein
From the Bilingual to the Monolingual Dictionary Gabriele Stein This paper is based on the following two assumptions: 1. Vocabulary acquisition has been seriously neglected in language teaching and language learning. 2. The critical period when a massive expansion of the foreign vocabulary is needed is the intermediate level (cf. F. Twadell, 1966:79; J. C. Richards, 1976:84; E. A. Levinston, 1979:149; P. Meara, 1982:100). The main reasons for this neglect are: a. the great dependence of language teaching methodologists on the research interests and fashions in linguistics and psychology, and b. the emphasis placed by language teaching methodologists and language acquisition researchers on the beginning stage. The belief generally held is that vocabulary acquisition can be delayed until the rudiments of pronunciation and a substantial proportion of the grammatical system have been mastered. Therefore language teaching has naturally concentrated on grammar (cf. E. A. Levinston, 1979:148). Teaching methods and curricula designs vary from country to country, and from language to language. As a non-native teacher of English I can only speak for the English context, but a number of the points that I shall make may well be applicable to the teaching of other languages. What we then need in the teaching of English as a foreign and as a second language is a major reorientation in teaching methodology. A reorientation that assigns vocabulary acquisition its proper place in the language acquisition process. Who are the pupils and students that are learning English at an intermediate level? In countries in which English is taught as a foreign or as a second language they typically are science students who have to improve their knowledge of English to read scientific material, students who want to do a degree in a situation where the medium of instruction is English, professionals who need a better command of English for promotion, and the future English language/literature students.