The Usage and Spread of Sentence-Internal Capitalization in Early New High German: a Multifactorial Approach
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Vol. 123 Style Sheet
THE YALE LAW JOURNAL VOLUME 123 STYLE SHEET The Yale Law Journal follows The Bluebook: A Uniform System of Citation (19th ed. 2010) for citation form and the Chicago Manual of Style (16th ed. 2010) for stylistic matters not addressed by The Bluebook. For the rare situations in which neither of these works covers a particular stylistic matter, we refer to the Government Printing Office (GPO) Style Manual (30th ed. 2008). The Journal’s official reference dictionary is Merriam-Webster’s Collegiate Dictionary, Eleventh Edition. The text of the dictionary is available at www.m-w.com. This Style Sheet codifies Journal-specific guidelines that take precedence over these sources. Rules 1-21 clarify and supplement the citation rules set out in The Bluebook. Rule 22 focuses on recurring matters of style. Rule 1 SR 1.1 String Citations in Textual Sentences 1.1.1 (a)—When parts of a string citation are grammatically integrated into a textual sentence in a footnote (as opposed to being citation clauses or citation sentences grammatically separate from the textual sentence): ● Use semicolons to separate the citations from one another; ● Use an “and” to separate the penultimate and last citations, even where there are only two citations; ● Use textual explanations instead of parenthetical explanations; and ● Do not italicize the signals or the “and.” For example: For further discussion of this issue, see, for example, State v. Gounagias, 153 P. 9, 15 (Wash. 1915), which describes provocation; State v. Stonehouse, 555 P. 772, 779 (Wash. 1907), which lists excuses; and WENDY BROWN & JOHN BLACK, STATES OF INJURY: POWER AND FREEDOM 34 (1995), which examines harm. -
Capitalization and Punctuation Rules
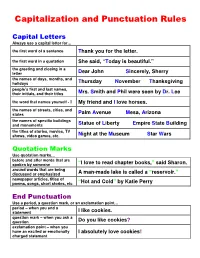
Capitalization and Punctuation Rules Capital Letters Always use a capital letter for… the first word of a sentence Thank you for the letter. the first word in a quotation She said, “ Today is beautiful.” the greeting and closing in a letter Dear John Sincerely, Sherry the names of days, months, and holidays Thursday November Thanksgiving people’s first and last names, their initials, and their titles Mrs. Smith and Phil were seen by Dr. Lee the word that names yourself - I My friend and I love horses. the names of streets, cities, and states Palm Avenue Mesa, Arizona the names of specific buildings and monuments Statue of Liberty Empire State Building the titles of stories, movies, TV shows, video games, etc. Night at the Museum Star Wars Quotation Marks Use quotation marks… before and after words that are spoken by someone “I love to read chapter books, ” said Sharon. around words that are being discussed or emphasized A man-made lake is called a “reservoir. ” newspaper articles, titles of poems, songs, short stories, etc “Hot and Cold ” by Katie Perry End Punctuation Use a period, a question mark, or an exclamation point… period – when you end a statement I like cookies . question mark – when you ask a question Do you like cookies ? exclamation point – when you have an excited or emotionally I absolutely love cookies ! charged statement Commas Always use a comma to separate… a city and a state Miami , Florida Mesa , Arizona the date from the year December 25 , 2009 April 15 , 2010 the greeting and closing of a letter Dear Jane , Sincerely , two adjectives that tell about the same noun Shawn is a clever , smart boy. -

Appendix B Capitalization
Appendix B: Capitalization BACKGROUND: This instruction sheet provides capitalization guidelines for establishing genre/form terms. 1. Policy for established genre/form terms. Transcribe existing genre/form terms exactly as they appear in authority records, using capital letters as indicated. 2. Proper nouns and adjectives. Capitalize proper nouns and adjectives in genre/form terms and references regardless of whether they are in the initial position. Example: Feast of the Transfiguration music 3. Initial words. Capitalize the first word of a genre/form term or reference regardless of whether it is a proper word. Example: Melic poetry BT Lyric poetry 4. Capitalization according to reference sources. Capitalize any letter within a genre/form term that appears as such in reference sources. 5. Conjunctions, prepositions, and articles. Do not capitalize conjunctions, prepositions and the articles a, an, and the and their equivalents in other languages if they are not the first word in the authorized term, subdivision, or reference. Examples: Bop (Poetry) UF The bop (Poetry) Comedies of humours Exception: Capitalize The if it is the first word in a parenthetical qualifier. Genre/Form Terms Manual Appendix B Page 1 May 2021 Appendix B: Capitalization 6. Inverted UF references. Capitalize the word following a comma that would be in the initial position if the authorized reference were expressed as a phrase in direct word order. Examples: Census data UF Data, Census Radio actualities UF Actualities, Radio 7. Parenthetical qualifiers. Capitalize the first word in a parenthetical qualifier, as well as any proper nouns or adjectives within a parenthetical qualifier. Examples: Hornpipes (Music) Medical films (Motion pictures) 8. -

THE PEPPER FONT COMPLETE MANUAL Version
THE PEPPER FONT COMPLETE MANUAL Version 2.1 (for Microsoft Word 2013 and 2016) A Set of Phonetic Symbols for Use in Windows Documents Lawrence D. Shriberg David L. Wilson Diane Austin The Phonology Project Waisman Center on Mental Retardation and Human Development University of Wisconsin-Madison 1500 Highland Avenue Madison, WI 53705 8 1997-2017 The Phonology Project CONTENTS ABOUT THE PEPPER FONT ................................................................................................................ 3 ABOUT VERSION 2/2.1 .......................................................................................................................... 3 REFERENCES .......................................................................................................................................... 3 INSTALLATION ...................................................................................................................................... 4 GENERAL INFORMATION ................................................................................................................... 4 Overview ........................................................................................................................................ 4 Manual Conventions ..................................................................................................................... 4 GENERAL INSTRUCTIONS .................................................................................................................. 5 General Instructions for Windows Applications -

Chapter 3. CAPITALIZATION RULES
3. CAPITALIZATION RULES (See also ‘‘Abbreviations and Letter Symbols’’ and ‘‘Capitalization Examples’’) 3.1. It is impossible to give rules that will cover every conceiv- able problem in capitalization; but by considering the purpose to be served and the underlying principles, it is possible to attain a con- siderable degree of uniformity. The list of approved forms given in chapter 4 will serve as a guide. Obviously such a list cannot be complete. The correct usage with respect to any term not included can be determined by analogy or by application of the rules. Proper names 3.2. Proper names are capitalized. Rome John Macadam Italy Brussels Macadam family Anglo-Saxon Derivatives of proper names 3.3. Derivatives of proper names used with a proper meaning are capitalized. Roman (of Rome) Johannean Italian 3.4. Derivatives of proper names used with acquired independ- ent common meaning, or no longer identified with such names, are set lowercased. Since this depends upon general and long-continued usage, a more definite and all-inclusive rule cannot be formulated in advance. roman (type) macadam (crushed italicize brussels sprouts rock) anglicize venetian blinds watt (electric unit) pasteurize plaster of paris Common nouns and adjectives in proper names 3.5. A common noun or adjective forming an essential part of a proper name is capitalized; the common noun used alone as a sub- stitute for the name of a place or thing is not capitalized. Massachusetts Avenue; the avenue Washington Monument; the monument Statue of Liberty; the statue Hoover -

Basque Style Guide
Basque Style Guide Published: June, 2017 Microsoft Basque Style Guide Contents 1 About this style guide ......................................................................................................................... 4 1.1 Recommended style references .............................................................................................. 4 2 Microsoft voice ...................................................................................................................................... 5 2.1 Choices that reflect Microsoft voice ...................................................................................... 6 2.1.1 Word choice ........................................................................................................................... 6 2.1.2 Words and phrases to avoid ............................................................................................ 8 2.2 Sample Microsoft voice text ................................................................................................... 10 2.2.1 Address the user to take action .................................................................................... 10 2.2.2 Promote a feature .............................................................................................................. 10 2.2.3 Provide how-to guidelines .............................................................................................. 11 2.2.4 Explanatory text and support ....................................................................................... -

Swedish Institutional Investors As Large Stake Owners: Enhancing Sustainable Stakeholder Capitalism
Swedish institutional investors as large stake owners: Enhancing sustainable stakeholder capitalism Sophie Nachemson-Ekwall1 INTRODUCTION This chapter focuses on the special role domestic institutional capital, collected in pension, state and private, and retail funds, might play as owners on the stock markets and how these, when seen as long-term engaged stakeholders, might contribute to building sustainable business models (Eccles et al. 2011; Gore and Blood 2012). Institutional investors have emerged as the most important investor category in globalized capital markets, accounting for 40 percent of the listed shares (OECD 2013).i The value of long-term committed institutional capital has as a result become a central topic within both the corporate governance paradigm (Mayer, 2012) and the sustainability discourse, with a number of calls for responsible engagement coming from international bodies.ii Sweden is used as a case study. Strand and Freeman (2015) claim that Scandinavian companies are exceptionally skilled at implementing value-creating sustainable strategies based on cooperation with their stakeholders, and in the process creating a cooperative advantage. Here it is added that the Swedish shareholder-friendly corporate governance system enables owners to play a more active role as governors than is usually possible in other countries. Historically, however, regulations and norms have generally prevented domestic institutional investors from engaging more actively, as has been discussed in a number of policy reports highlighting concerns with the lack of long-term and committed institutional capital to small and mid-sized Swedish enterprises, or SMEs (Nasdaq OMX Stockholm 2013/2016; EU Commission Research and Innovation 2013; Confederation of Swedish Industries 2014: Nachemson-Ekwall 2016). -

Examining Students' Strategies in German Capitalization Tasks
What you apply is not what you learn! Examining students' strategies in German capitalization tasks Nathalie Rzepka Hans-Georg Müller Katharina Simbeck Hochschule für Technik und Wirtschaft Universität Potsdam Hochschule für Technik und Wirtschaft Berlin Potsdam Berlin [email protected] [email protected] katharina.simbeck @htw-berlin.de ABSTRACT Previous research has further indicated that these cognitive strate- The ability to spell correctly is a fundamental skill for participating gies for capitalization result in different patterns of errors that can in society and engaging in professional work. In the German lan- be distinguished from each other [18]. While some learners con- guage, the capitalization of nouns and proper names presents major sider the entire phrase when deciding whether to capitalize a word, difficulties for both native and nonnative learners, since the defini- others focus on only the word itself, especially the word ending, as tion of what is a noun varies according to one’s linguistic perspec- an indication of the correct capitalization. Other learners use the tive. In this paper, we hypothesize that learners use different cogni- words’ meaning or take a pragmatic approach. tive strategies to identify nouns. To this end, we examine capitali- This paper aims to contribute to a better understanding of learners’ zation exercises from more than 30,000 users of an online spelling cognitive strategies while processing capitalization tasks in Ger- training platform. The cognitive strategies identified are syntactic, man spelling courses. To this end, we use anonymized learning data semantic, pragmatic, and morphological approaches. The strategies on capitalization from the online platform orthografietrainer.net. -

ECL Style Guide August ‘07
1 ECL Style Guide August ‘07 Eighteenth-Century Life first adheres to the rules in this style guide. For issues not covered in the style guide, refer to the fifteenth edition of The Chicago Manual of Style (hereinafter, CMS17) for guidance. This is available online at https://www.chicagomanualofstyle.org/home.html Eighteenth-Century Life prefers to receive submissions by e-mail, either in Microsoft Word or in WordPerfect. If that is not possible, sending in 3 ½” disks is preferable to submitting mss. If mss. are submitted, please send three copies. ABBREVIATIONS Corporate, municipal, national, and supranational abbreviations and acronyms appear in full caps. Most initialisms (abbreviations pronounced as strings of letters) are preceded by the. Latin abbreviations, such as e.g. and i.e., are usually restricted to parenthetical text and set in Roman type, not italics, except for sic, which is italicized for visibility’s sake. Pace, Latin for “contrary to,” is italicized to avoid confusion with “pace.” We’ll allow e.g. and i.e. to appear in the text of the notes. According to Chicago Manual, if used in running text, abbreviations should be confined to parenthetical expressions. Personal initials have periods and are spaced. W. E. B. DuBois; C. D. Wright BYLINE AND AFFILIATION The author’s name and affiliation appear on the opening page of each article. No abbreviations are used within the affiliation. If more than one author appears, an ampersand separates the authors. James Smith University of Arizona John Abrams University of Florida & Maureen O’Brien University of Virginia AMPERSANDS The use of ampersands is limited to “The College of William & Mary” on the cover, on the title page, and in copyright slugs, and to separating multiple authors in the byline on article-opening pages. -

Capitalization Glossary1 Abrahamic Covenant Age AD
Capitalization Glossary1 Abrahamic Covenant Age AD (Latin abbreviation for “in the year of our Lord”) goes before the date (AD 2014) Apostolic Age Bronze Age church age Iron Age Stone Age Almighty God amillennial, amillenarian Ancient Near East the Antichrist anti-Christian antichrists (many) the Apocrypha (but: apocryphal) apostle(s) (but: the Twelve Apostles, the Twelve) apostolic archaeology ark (any reference) Ascension (specific biblical event) Atonement (of Christ) BC (English abbreviation for “before Christ”) goes after the date (586 BC) Beatitudes believer-priests Bible biblical black theology body of Christ Book of books (Bible) book of Job a book of the Bible book of life (mentioned in Rev. 20:15) Bread of Life bride of Christ Calvary Captivity (the Babylonian; others, lowercase) Catholics Catholicism (but: catholic, meaning universal) 1 For additional resource, see “Appendix A: Capitalization and Spelling Examples,” in The SBL Handbook of Style: For Eastern, Near Eastern, Biblical, and Early Christian Studies (Peabody, MA: Henrickson Publishers, 1999), 154-65. 1 chapter (general term) Chapter 6 (specific chapter) charismatic chief priest(s) children of Israel Christ Child Christian education (but: Department of Christian Education) Christlike Christological Christology Christ’s kingdom church (both universal and local) the early church fathers (but: the Fathers) the commandments (capitalize only when referring to the whole Decalogue: Ten Commandments, but: first commandment) commencement communion (the ordinance) communists, -

Capitalization
1 Palm Beach Atlantic University Center for Writing Excellence CAPITALIZATION There are three main types of words that need to be capitalized: (1) the first word of a sentence, (2) titles of books and other works, and (3) proper nouns and adjectives. (1) Incorrect: writing is so much fun. Correct: Writing is so much fun. When joining two sentences using a semicolon ( ; ), one does not need to capitalize the first word after the semicolon. The thoughts on both sides of the semicolon join to form one complete sentence. Incorrect: It was raining when I took my cat for a walk; My cat got soaked. Correct: It was raining when I took my cat for a walk; my cat got soaked. (2) Titles of books, movies, essays, journal articles, paintings, musical compositions, and other works are also capitalized. One should always capitalize the first word of the title and capitalize most of the remaining words in the title (with a few exceptions). DO NOT capitalize: ● prepositions (into, of, by, for, etc.) ● articles (a, an, the) ● conjunctions (and, but, or, etc.) ● the word to if used with a verb in the infinitive (to run, to think, to write) Incorrect: “on the Subjection of Women” Always capitalize the first word of a Correct: “On the Subjection of Women” title. Do not capitalize prepositions, Incorrect: The Catcher In The Rye articles, conjunctions, or “to” as part Correct: The Catcher in the Rye of an infinitive verb. 2 Capitalize proper nouns and adjectives Proper nouns name specific things, places, or people. When proper nouns are made into adjectives, they are also capitalized. -

Capitalization and Punctuation Capitalizing Sentences, Quotations, & Salutations
Capitalization AND Punctuation Capitalizing Sentences, Quotations, & Salutations Rule 1: Capitalize the first word of EVERY sentence. The Lady Falcons are in Monroe County. Rule 2: Capitalize the first word of a direct quote that is a complete sentence. A direct quote is the speakers exact words. Mrs. Michelle said, “Bring your new folder.” Capitalizing Sentences, Quotations, & Salutations Rule 3: When a quoted sentence is interrupted by explanatory words, such as she said, do NOT begin the second part of the sentence with a capital letter, unless it is a new sentence. “Mr. Alexander,” Tommy said, “can I go to the bathroom?” “I went to the state tournament,” the coach said. “M y team won the game.” Rule 4: Do NOT capitalize an indirect quote. An indirect quote does not repeat the person’s exact words. Tom said his mom bought a new car. Capitalizing Sentences, Quotations, & Salutations Rule 5: Capitalize the first word in the greeting and closing of a letter. Capitalize the title and name of the person addressed. Dear Chris, To whom it may concern, Yours truly Sincerely yours, Capitalizing Names and Titles of People Rule 1: Capitalize the names of people and the initials that stand for their names. Katresa Collins E.B. White Rule 2: Capitalize a title or an abbreviation of a title when it comes before a person’s name or when it is used in direct address. Mr. Murphy Mrs. Connie Capitalizing Names and Titles of People Rule 3: Capitalize the names and abbreviations of academic degrees that follow a person’s name.