Lecture No. IV
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

B. Sample Multiple Choice Questions 1
Genetics Review B. Sample Multiple Choice Questions 1. A represents the dominant allele and a represents the recessive allele of a pair. If, in 1000 offspring, 500 are aa and 500 are of some other genotype, which of the following are most probably the genotypes of the parents? a. Aa and Aa b. Aa and aa c. AA and Aa d. AA and aa e. aa and aa 2. A form of vitamin D-resistant rickets, known as hypophosphatemia, is inherited as an X-linked dominant trait. If a male with hypophosphatemia marries a normal female, which of the following predictions concerning their potential progeny would be true? a. All of their sons would inherit the disease b. All of their daughters would inherit the disease c. About 50% of their sons would inherit the disease d. About 50% of their daughters would inherit the disease e. None of their daughters would inherit the disease 3. Which of the following best describes the parents in a testcross? a. One individual has the dominant phenotype and the other has the recessive phenotype. b. Both individuals are heterozygous. c. Both individuals have the dominant phenotype. d. Both individuals have the recessive phenotype. e. Both individuals have an unknown phenotype. 4. Which of the following is the most likely explanation for a high rate of crossing-over between two genes? a. The two genes are far apart on the same chromosome. b. The two genes are both located near the centromere. c. The two genes are sex-linked. d. The two genes code for the same protein. -

3Rd Period Allele: Alternate Forms of a Genetic Locus
Glossary of Terms Commonly Encountered in Plant Breeding 1st Period - 3rd Period Allele: alternate forms of a genetic locus. For example, at a locus determining eye colour, an individual might have the allele for blue eyes, brown, etc. Breeding: the intentional development of new forms or varieties of plants or animals by crossing, hybridization, and selection of offspring for desirable characteristics Chromosome: the structure in the eukaryotic nucleus and in the prokaryotic cell that carries most of the DNA Cross-over: The point along the meiotic chromosome where the exchange of genetic material takes place. This structure can often be identified through a microscope Crossing-over: The reciprocal exchange of material between homologous chromosomes during meiosis, which is responsible for genetic recombination. The process involves the natural breaking of chromosomes, the exchange of chromosome pieces, and the reuniting of DNA molecules Domestication: the process by which plants are genetically modified by selection over time by humans for traits that are more desirable or advantageous for humans DNA: an abbreviation for “deoxyribose nucleic acid”, the carrier molecule of inherited genetic information Dwarfness: The genetically controlled reduction in plant height. For many crops, dwarfness, as long as it is not too extreme, is an advantage, because it means that less of the crop's energy is used for growing the stem. Instead, this energy is used for seed/fruit/tuber production. The Green Revolution wheat and rice varieties were based on dwarfing genes Emasculation: The removal of anthers from a flower before the pollen is shed. To produce F1 hybrid seed in a species bearing monoecious flowers, emasculation is necessary to remove any possibility of self-pollination Epigenetic: heritable variation caused by differences in the chemistry of either the DNA (methylation) or the proteins associated with the DNA (histone acetylation), rather than in the DNA sequence itself Gamete: The haploid cell produced by meiosis. -

OUTLINE 12 IV. Mendel's Work D. the Dihybrid Cross 1. Qualitative Results 2
OUTLINE 12 IV. Mendel's Work D. The dihybrid cross 1. qualitative results 2. quantitative results E. Summary of Mendel's Rules V. Probability Theory and Patterns of Inheritance A. Definitions B. Rules for probability 1. independent outcomes 2. the product rule 3. single event; multiple outcomes 4. the addition rule C. Application to the dihybrid cross VI. Extensions of Mendel’s Rules Fig 14.2 A monohybrid cross Fig 14.3 P Homozygous P P Heterozygous p P p P PP Pp p Pp pp Genotypes: PP, Pp, pp genotype ratio: 1:2:1 Phenotypes: Purple, white phenotype ratio: 3:1 Fig. 14.6 A Test Cross Table 14.1 Fig. 14.7 A Dihybrid Cross Mendel’s Laws (as he stated them) Law of unit factors “Inherited characters are controlled by discrete factors in pairs” Law of segregation “When gametes are formed, the factors segregate…and recombine in the next generation.” Law of dominance: “of the two factors controlling a trait, one may dominate the other.” Law of independent assortment: “one pair of factors can segregate from a second pair of factors.” When all outcomes of an event are equally likely, the probability that a particular outcome will occur is #ways to obtain that outcome / total # possible outcomes Examples: In a coin toss P[heads] - 1/2 (or 0.5) In tossing one die P[2] = 1/6 In tossing one die P[even #] = 3/6 Drawing a card P[Queen of spades] = 1/52 The “AND” rule Probability of observing event 1 AND event 2 = the product of their independent probabilities. -

12.2 Characteristics and Traits
334 Chapter 12 | Mendel's Experiments and Heredity 12.2 | Characteristics and Traits By the end of this section, you will be able to do the following: • Explain the relationship between genotypes and phenotypes in dominant and recessive gene systems • Develop a Punnett square to calculate the expected proportions of genotypes and phenotypes in a monohybrid cross • Explain the purpose and methods of a test cross • Identify non-Mendelian inheritance patterns such as incomplete dominance, codominance, recessive lethals, multiple alleles, and sex linkage Physical characteristics are expressed through genes carried on chromosomes. The genetic makeup of peas consists of two similar, or homologous, copies of each chromosome, one from each parent. Each pair of homologous chromosomes has the same linear order of genes. In other words, peas are diploid organisms in that they have two copies of each chromosome. The same is true for many other plants and for virtually all animals. Diploid organisms produce haploid gametes, which contain one copy of each homologous chromosome that unite at fertilization to create a diploid zygote. For cases in which a single gene controls a single characteristic, a diploid organism has two genetic copies that may or may not encode the same version of that characteristic. Gene variants that arise by mutation and exist at the same relative locations on homologous chromosomes are called alleles. Mendel examined the inheritance of genes with just two allele forms, but it is common to encounter more than two alleles for any given gene in a natural population. Phenotypes and Genotypes Two alleles for a given gene in a diploid organism are expressed and interact to produce physical characteristics. -

INTRODUCTION to GENETICS Table of Contents Heredity, Historical
INTRODUCTION TO GENETICS Table of Contents Heredity, historical perspectives | The Monk and his peas | Principle of segregation Dihybrid Crosses | Mutations | Genetic Terms | Links Heredity, Historical Perspective | Back to Top For much of human history people were unaware of the scientific details of how babies were conceived and how heredity worked. Clearly they were conceived, and clearly there was some hereditary connection between parents and children, but the mechanisms were not readily apparent. The Greek philosophers had a variety of ideas: Theophrastus proposed that male flowers caused female flowers to ripen; Hippocrates speculated that "seeds" were produced by various body parts and transmitted to offspring at the time of conception, and Aristotle thought that male and female semen mixed at conception. Aeschylus, in 458 BC, proposed the male as the parent, with the female as a "nurse for the young life sown within her". During the 1700s, Dutch microscopist Anton van Leeuwenhoek (1632-1723) discovered "animalcules" in the sperm of humans and other animals. Some scientists speculated they saw a "little man" (homunculus) inside each sperm. These scientists formed a school of thought known as the "spermists". They contended the only contributions of the female to the next generation were the womb in which the homunculus grew, and prenatal influences of the womb. An opposing school of thought, the ovists, believed that the future human was in the egg, and that sperm merely stimulated the growth of the egg. Ovists thought women carried eggs containing boy and girl children, and that the gender of the offspring was determined well before conception. -

ZOOLOGY GENETICS Topic: Back Cross & Test Cross
ZOOLOGY GENETICS Topic: Back Cross & Test Cross Introduction The characteristics of the offspring of Mendel’s crosses can be predicted from the genotype of the parents through knowledge of dominant and recessive genes i.e., TT for tall and tt for dwarf traits. Mendel wanted to know whether the genotype of the individual be determined just from its phenotype. For recessive phenotype, it is possible, because it has only one genotype for example, tt for dwarf trait. But, the phenotypically dominant individuals show two types of genotypes – homozygous dominant (TT) and heterozygous dominant (Tt). In order to determine the genotypes of such phenotypes, Mendel employed two types of crosses viz., back cross and test cross. Without the knowledge of the genotype, just by crossing experiment, one can determine the genotype of the given phenotype with the help of these crosses. BACK CROSS Backcross is a cross of a hybrid (F1) with any one of its parents i.e. homozygous dominant or homozygous recessive parent. It is used in horticulture, animal breeding and in production of gene knockout organisms. These are performed in Monohybrid and Dihybrid crosses. 1. Monohybrid Back Cross:- In a monohybrid cross of homozygous tall (TT) and homozygous dwarf (tt) pea plants, the F1 progeny are heterozygous tall (Tt). When the F1 heterozygote (hybrid) is crossed either with its dominant parent or with its recessive parent, it is known as back cross and the results obtained from such a cross is as follows:- a. Back Cross with Homozygous Dominant Parent:- The F1 heterozygote (Tt) gives rise to two kinds of gametes viz., gametes with dominant factor for tall character (T) and gametes with recessive factor for dwarf character (t). -
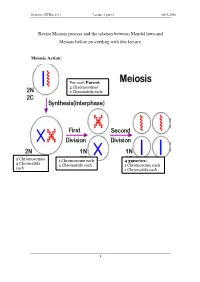
Revise Meiosis Process and the Relation Between Mendel Laws and Meiosis Before Proceeding with This Lecture
Genetics (BTBio 211) Lecture 3 part 2 2015-2016 Revise Meiosis process and the relation between Mendel laws and Meiosis before proceeding with this lecture. Meiosis Action: For each Parent 2 Chromosomes 2 Chromatids each 2 Chromosomes 1 Chromosome each 4 gametes: 4 Chromatid s 4 Chromatids each 1 Chromosome each each 1 Chromatids each 1 Genetics (BTBio 211) Lecture 3 part 2 2015-2016 LINKAGE AND CHROMOSOME MAPPING IN EUKARYOTES I. LINKAGE Genetic linkage is the tendency of genes that are located proximal to each other on a chromosome to be inherited together during meiosis. Genes whose loci are nearer to each other are less likely to be separated onto different chromatids during chromosomal crossover, and are therefore said to be genetically linked. Linked genes: Genes that are inherited together with other gene(s) in form of single unit as they are located on the same chromosome. For example: in fruit flies the genes for eye color and the genes for wing length are on the same chromosome, thus are inherited together. A couple of genes on chromosomes may be present either on the different or on the same chromosome. 1. The independent assortment of two genes located on different chromosomes. Mendel’s Law of Independent Assortment: during gamete formation, segregation of one gene pair is independent of other gene pairs because the traits he studied were determined by genes on different chromosomes. Consider two genes A and B, each with two alleles A a and B b on separate (different) chromosomes. 2 Genetics (BTBio 211) Lecture 3 part 2 2015-2016 Gametes of non-homologous chromosomes assort independently at anaphase producing 4 different genotypes AB, ab, Ab and aB with a genotypic ratio 1:1:1:1. -

Revision Guide
Revision Guide Biology - Unit 4 GCE A Level WJEC These notes have been authored by experienced teachers and are provided as support to students revising for their GCE A level exams. Though the resources are comprehensive, they may not cover every aspect of the specification and do not represent the depth of knowledge required for each unit of work. 1 Content Page Section 3 4.1 – Sexual Reproduction in Humans 13 4.2 - Sexual Reproduction in Plants 21 4.3 - Inheritance 36 4.4 - Variation and Evolution 49 4.5 - Application of Reproduction and Genetics 62 Acknowledgements 2 Section 4.1 - Sexual Reproduction in Humans The Male Reproductive System seminal vesicle vas deferens prostate gland urethra epididymis seminiferous tubules testis Male reproductive system Structure Function Scrotum External sac of skin containing the testes. Testes • Produce gametes (sperm formed by spermatogenesis), • Produce testosterone. Epididymis Sperm are stored here and mature to become fully mobile. Vas deferens Carries sperm towards the penis during ejaculation. Seminal vesicle Secretes a fluid into the vas deferens that contains a mixture of chemicals which make up approximately 60% of semen. Seminal fluid provides nutrients for sperm such as fructose for respiration and amino acids. Seminal fluid is alkaline which helps to neutralise the acidity of any urine remaining in the urethra and the acidity of the vaginal tract. Prostate gland Secretes a fluid into the vas deferens that contains a mixture of chemicals which make up approximately 30% of semen. Prostate fluid contains zinc ions and is also alkaline which helps to neutralise the acidity of any urine remaining in the urethra and the acidity of the vaginal tract. -

7.014 Problem Set 6 Solutions
MIT Department of Biology 7.014 Introductory Biology, Spring 2004 7.014 Problem Set 6 Solutions Question 1 a) Define the following terms: Dominant – In genetics, the ability of one allelic form of a gene to determine the phenotype of a heterozygous individual, in which the homologous chromosomes carries both it and a different (recessive) allele. Recessive – In genetics, an allele that does not determine phenotype in the presence of a dominant allele. Phenotype – The observable properties of an individual resulting from both genetic and environmental factors. Genotype – An exact description of the genetic constitution of an individual, either with respect to a single trait or with respect to a larger set of traits. Alleles – The alternate forms of a genetic character found at a given locus on a chromosome. Homozygous – In a diploid organism, having identical alleles of a given gene on both homologous chromosomes. An individual may be a homozygote with respect to one gene and a heterozygote with respect to another. Heterozygous – Of a diploid organism having different alleles of a given gene on the pair of homologues carrying that gene. Mendel’s First Law – Law of Segregation - In genetics, the separation of alleles, or of homologous chromosomes, from one another during meiosis so that each of the haploid daughter nuclei produced by meiosis contains one or the other member of the pair found in the diploid mother cell, but never both. Mendel’s Second Law – Law of Independent Assortment - During meiosis, the random separation of genes carried on nonhomologous chromosomes. Sex-Linked – The pattern of inheritance characteristic of genes located on the sex chromosomes of organisms having a chromosomal mechanism for sex determination. -

Learning Outcomes
Week 12 Learning Outcomes Genetics: Patterns of Inheritance • Explain the scientific reasons for the success of Mendel’s experimental work. Describe Mendel’s contributions to understanding how traits are inherited and state Mendel’s laws. • Describe the expected outcomes of monohybrid crosses involving dominant and recessive alleles. • Explain the relationship between genotypes and phenotypes in dominant and recessive gene systems • Use a Punnett square and pedigrees to predict and calculate probabilities of genotypes and phenotypes in a monohybrid cross • Explain Mendel’s law of segregation and independent assortment in terms of genetics and the events of meiosis • Explain the purpose and methods of a test cross • Identify non-Mendelian inheritance patterns such as incomplete dominance, codominance, multiple alleles, and sex linkage from the results of crosses. Use monohybrid crosses and pedigrees to predict and calculate probabilities of genotypes and phenotypes. 12 Essential Vocabulary to get started… Mendel’s Pea Plant Experiments • Phenotype • Genotype • Mendel was the first person to • Pure-bred / true breeding / homozygous analyze patterns of inheritance to deduce the fundamental • Heterozygous principles of genetics • Gene (“heritable factor”) • Studied garden peas • Allele • Easily manipulated (control over fertilization) • Can self-fertilize • Reproduce quickly • Large numbers of offspring • Many distinct traits to study; most traits had only two possible variants 34 1 Traits of Mendel’s Pea Plants Self-Fertilization produces -

Lecture 1 – Mendelian Inheritance
Introduction – Mendelian inheritance Genetics 371B Lecture 1 27 Sept. 1999 The mechanism of inheritance… Some early hypotheses: Predetermination e.g., the homunculus theory Blending of traits Introducing a more systematic approach… Gregor Mendel (1822–1884) and his experiments with garden pea But first: Choosing a model organism What is it? Why bother? Features of a good model organism: Some commonly used model organisms: Mendel's organism of choice: garden pea His question: If a pair of plant lines showing a clear character difference are crossed, will the progeny show an intermediate phenotype? He established true-breeding lines… …that showed character differences Made crosses (matings) between each pair of lines Example: Character: Phenotypes: x “F1” F1 x F1 “F2” Mendelian Genetics – Monohybrid cross Genetics 371B Lecture 2 28 Sept. 1999 Interpreting Mendel’s experiment Parents: Gametes: F1 progeny: Gametes: F2 progeny: Conclusions: 1. Determinants are particulate 2. They occur in pairs; one member may be dominant 3. Determinants segregate randomly into gametes Prediction: The F2 “Purple” class consists of two subclasses: Testing the prediction: What Mendel did: What we would do today (hindsight!): Generality of Mendel's first law: (Not just for pea plants!) Fruit fly (Drosophila melanogaster) Normal (brown) body x black body Mice Agouti x Black Humans Albinism Pedigree analysis What are pedigrees? Why bother with them? Constructing pedigrees “The inability to smell methanethiol is a recessive trait in humans. Ashley, Perry, and Gus -

Dihybrid Crosses
Dihybrid Crosses: Punnett squares for two traits Genes on Different Chromosomes If two genes are on different chromosomes, all four possible alleles combinations for two different genes in a heterozygous cross are _____________ due to independent assortment. If parents are RrYy (heterozygous for both traits) Equally R r likely to R r OR line up either way y Y Y y when dividing Ry rY RY ry Gametes: ___________________________________ Setting up a Dihybrid Cross: RrYy x RrYy Each side of a Punnett Square represents all the possible allele combinations in a gamete from a parent. Parent gametes always contain one allele for___ _______ .(____________-R or r & Y or y in this case). Four possible combinations of the alleles for the two genes are possible if heterozygous for both traits. (For example: ___________________) Due to independent assortment, each possible combination is equally likely if genes are on separate chromosomes. Therefore Punnett squares indicate probabilities for each outcome. Discuss with your table partner: A. R r Y y Which is correct for a R dihybrid cross of two r heterozygous parents RrYy x RrYy? Y y B. RR Rr rr rR C. RY Ry rY ry YY RY Yy Ry yy rY yY ry Explain how the correct answer relates to the genes passed down in each gamete (egg or sperm) Dihybrid Cross of 2 Heterozygotes 9 3 3 1 Heterozygous Dihybrid Cross Dominant Dominant Recessive Recessive for both 1st trait 1st trait for both traits Recessive Dominant traits 2nd trait 2nd trait Round Round Wrinkled Wrinkled Yellow Green Yellow Green __ __ __ __ ______ = ______ = ______ = _______ = ___ ____ ____ _____ Heterozygous cross __________ratio if independent assortment Mendel came up with the Law of Independent Assortment because he realized that the results for his dihybrid crosses matched the probability of the two genes being inherited independently.