Machine Learning in Astronomy: a Workman’S Manual
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Westminsterresearch the Astrobiology Primer V2.0 Domagal-Goldman, S.D., Wright, K.E., Adamala, K., De La Rubia Leigh, A., Bond
WestminsterResearch http://www.westminster.ac.uk/westminsterresearch The Astrobiology Primer v2.0 Domagal-Goldman, S.D., Wright, K.E., Adamala, K., de la Rubia Leigh, A., Bond, J., Dartnell, L., Goldman, A.D., Lynch, K., Naud, M.-E., Paulino-Lima, I.G., Kelsi, S., Walter-Antonio, M., Abrevaya, X.C., Anderson, R., Arney, G., Atri, D., Azúa-Bustos, A., Bowman, J.S., Brazelton, W.J., Brennecka, G.A., Carns, R., Chopra, A., Colangelo-Lillis, J., Crockett, C.J., DeMarines, J., Frank, E.A., Frantz, C., de la Fuente, E., Galante, D., Glass, J., Gleeson, D., Glein, C.R., Goldblatt, C., Horak, R., Horodyskyj, L., Kaçar, B., Kereszturi, A., Knowles, E., Mayeur, P., McGlynn, S., Miguel, Y., Montgomery, M., Neish, C., Noack, L., Rugheimer, S., Stüeken, E.E., Tamez-Hidalgo, P., Walker, S.I. and Wong, T. This is a copy of the final version of an article published in Astrobiology. August 2016, 16(8): 561-653. doi:10.1089/ast.2015.1460. It is available from the publisher at: https://doi.org/10.1089/ast.2015.1460 © Shawn D. Domagal-Goldman and Katherine E. Wright, et al., 2016; Published by Mary Ann Liebert, Inc. This Open Access article is distributed under the terms of the Creative Commons Attribution Noncommercial License (http://creativecommons.org/licenses/by- nc/4.0/) which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited. The WestminsterResearch online digital archive at the University of Westminster aims to make the research output of the University available to a wider audience. -

Science Concept 5: Lunar Volcanism Provides a Window Into the Thermal and Compositional Evolution of the Moon
Science Concept 5: Lunar Volcanism Provides a Window into the Thermal and Compositional Evolution of the Moon Science Concept 5: Lunar volcanism provides a window into the thermal and compositional evolution of the Moon Science Goals: a. Determine the origin and variability of lunar basalts. b. Determine the age of the youngest and oldest mare basalts. c. Determine the compositional range and extent of lunar pyroclastic deposits. d. Determine the flux of lunar volcanism and its evolution through space and time. INTRODUCTION Features of Lunar Volcanism The most prominent volcanic features on the lunar surface are the low albedo mare regions, which cover approximately 17% of the lunar surface (Fig. 5.1). Mare regions are generally considered to be made up of flood basalts, which are the product of highly voluminous basaltic volcanism. On the Moon, such flood basalts typically fill topographically-low impact basins up to 2000 m below the global mean elevation (Wilhelms, 1987). The mare regions are asymmetrically distributed on the lunar surface and cover about 33% of the nearside and only ~3% of the far-side (Wilhelms, 1987). Other volcanic surface features include pyroclastic deposits, domes, and rilles. These features occur on a much smaller scale than the mare flood basalts, but are no less important in understanding lunar volcanism and the internal evolution of the Moon. Table 5.1 outlines different types of volcanic features and their interpreted formational processes. TABLE 5.1 Lunar Volcanic Features Volcanic Feature Interpreted Process -

Download Artist's CV
I N M A N G A L L E R Y Michael Jones McKean b. 1976, Truk Island, Micronesia Lives and works in New York City, NY and Richmond, VA Education 2002 MFA, Alfred University, Alfred, New York 2000 BFA, Marywood University, Scranton, Pennsylvania Solo Exhibitions 2018-29 (in progress) Twelve Earths, 12 global sites, w/ Fathomers, Los Angeles, CA 2019 The Commune, SuPerDutchess, New York, New York The Raw Morphology, A + B Gallery, Brescia, Italy 2018 UNTMLY MLDS, Art Brussels, Discovery Section, 2017 The Ground, The ContemPorary, Baltimore, MD Proxima Centauri b. Gleise 667 Cc. Kepler-442b. Wolf 1061c. Kepler-1229b. Kapteyn b. Kepler-186f. GJ 273b. TRAPPIST-1e., Galerie Escougnou-Cetraro, Paris, France 2016 Rivers, Carnegie Mellon University, Pittsburgh, PA Michael Jones McKean: The Ground, The ContemPorary Museum, Baltimore, MD The Drift, Pittsburgh, PA 2015 a hundred twenty six billion acres, Inman Gallery, Houston, TX three carbon tons, (two-person w/ Jered Sprecher) Zeitgeist Gallery, Nashville, TN 2014 we float above to spit and sing, Emerson Dorsch, Miami, FL Michael Jones McKean and Gilad Efrat, Inman Gallery, at UNTITLED, Miami, FL 2013 The Religion, The Fosdick-Nelson Gallery, Alfred University, Alfred, NY Seven Sculptures, (two person show with Jackie Gendel), Horton Gallery, New York, NY Love and Resources (two person show with Timur Si-Qin), Favorite Goods, Los Angeles, CA 2012 circles become spheres, Gentili APri, Berlin, Germany Certain Principles of Light and Shapes Between Forms, Bernis Center for ContemPorary Art, Omaha, NE -
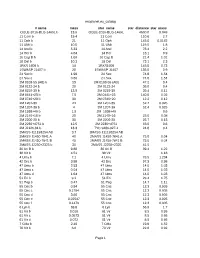
Exoplanet.Eu Catalog Page 1 # Name Mass Star Name
exoplanet.eu_catalog # name mass star_name star_distance star_mass OGLE-2016-BLG-1469L b 13.6 OGLE-2016-BLG-1469L 4500.0 0.048 11 Com b 19.4 11 Com 110.6 2.7 11 Oph b 21 11 Oph 145.0 0.0162 11 UMi b 10.5 11 UMi 119.5 1.8 14 And b 5.33 14 And 76.4 2.2 14 Her b 4.64 14 Her 18.1 0.9 16 Cyg B b 1.68 16 Cyg B 21.4 1.01 18 Del b 10.3 18 Del 73.1 2.3 1RXS 1609 b 14 1RXS1609 145.0 0.73 1SWASP J1407 b 20 1SWASP J1407 133.0 0.9 24 Sex b 1.99 24 Sex 74.8 1.54 24 Sex c 0.86 24 Sex 74.8 1.54 2M 0103-55 (AB) b 13 2M 0103-55 (AB) 47.2 0.4 2M 0122-24 b 20 2M 0122-24 36.0 0.4 2M 0219-39 b 13.9 2M 0219-39 39.4 0.11 2M 0441+23 b 7.5 2M 0441+23 140.0 0.02 2M 0746+20 b 30 2M 0746+20 12.2 0.12 2M 1207-39 24 2M 1207-39 52.4 0.025 2M 1207-39 b 4 2M 1207-39 52.4 0.025 2M 1938+46 b 1.9 2M 1938+46 0.6 2M 2140+16 b 20 2M 2140+16 25.0 0.08 2M 2206-20 b 30 2M 2206-20 26.7 0.13 2M 2236+4751 b 12.5 2M 2236+4751 63.0 0.6 2M J2126-81 b 13.3 TYC 9486-927-1 24.8 0.4 2MASS J11193254 AB 3.7 2MASS J11193254 AB 2MASS J1450-7841 A 40 2MASS J1450-7841 A 75.0 0.04 2MASS J1450-7841 B 40 2MASS J1450-7841 B 75.0 0.04 2MASS J2250+2325 b 30 2MASS J2250+2325 41.5 30 Ari B b 9.88 30 Ari B 39.4 1.22 38 Vir b 4.51 38 Vir 1.18 4 Uma b 7.1 4 Uma 78.5 1.234 42 Dra b 3.88 42 Dra 97.3 0.98 47 Uma b 2.53 47 Uma 14.0 1.03 47 Uma c 0.54 47 Uma 14.0 1.03 47 Uma d 1.64 47 Uma 14.0 1.03 51 Eri b 9.1 51 Eri 29.4 1.75 51 Peg b 0.47 51 Peg 14.7 1.11 55 Cnc b 0.84 55 Cnc 12.3 0.905 55 Cnc c 0.1784 55 Cnc 12.3 0.905 55 Cnc d 3.86 55 Cnc 12.3 0.905 55 Cnc e 0.02547 55 Cnc 12.3 0.905 55 Cnc f 0.1479 55 -

10/17/2015 1 the Origin of the Solar System Chapter 10
10/17/2015 Guidepost As you explore the origins and the materials that make up the solar system, you will discover the answers to several important questions: What are the observed properties of the solar system? Chapter 10 What is the theory for the origin of the solar system that explains the observed properties? The Origin of the Solar System How did Earth and the other planets form? What do astronomers know about other extrasolar planets orbiting other stars? In this and the following six chapters, we will explore in more detail the planets and other objects that make up our solar system, our home in the universe. A Survey of the Solar System Two Kinds of Planets The solar system consists of eight Planets of our solar system can be divided into two very major planets and several other different kinds: objects. Jovian (Jupiter- like) planets: The planets rotate on their axes and Jupiter, Saturn, revolve around the Sun. Uranus, Neptune The planets have elliptical orbits, sometimes inclined to the ecliptic, and all planets revolve in the same directly; only Venus and Uranus rotate in an alternate direction. Nearly all moons also revolve in the Terrestrial (Earthlike) same direction. planets: Mercury, Venus, Earth, Mars Terrestrial Planets Craters on Planets’ Surfaces Craters (like on our Four inner moon’s surface) are planets of the common throughout solar system the solar system. Relatively small in size Not seen on Jovian and mass planets because (Earth is the Surface of Venus they don’t have a largest and Rocky surface can not be seen solid surface. -

Proxima B: the Alien World Next Door - Is Anyone Home?
Proxima b: The Alien World Next Door - Is Anyone Home? Edward Guinan Biruni Observatory Dept. Astrophysics & Planetary Science th 40 Anniversary Workshop Villanova University 12 October, 2017 [email protected] Talking Points i. Planet Hunting: Exoplanets ii. Living with a Red Dwarf Program iii. Alpha Cen ABC -nearest Star System iv. Proxima Cen – the red dwarf star v. Proxima b Nearest Exoplanet vi. Can it support Life? vii. Planned Observations / Missions Planet Hunting: Finding Exoplanets A brief summary For citizen science projects: www.planethunters.org Early Thoughts on Extrasolar Planets and Life Thousands of years ago, Greek philosophers speculated… “There are infinite worlds both like and unlike this world of ours...We must believe that in all worlds there are living creatures and planets and other things we see in this world.” Epicurius c. 300 B.C First Planet Detected 51 Pegasi – November 1995 Mayer & Queloz / Marcy & Butler Credit: Charbonneau Many Exoplanets (400+) have been detected by the Spectroscopic Doppler Motion Technique (now can measure motions as low as 1 m/s (3.6 km/h = 2.3 mph)) Exoplanet Transit Eclipses Rp/Rs ~ [Depth of Eclipse] 1/2 Transit Eclipse Depths for Jupiter, Neptune and Earth for the Sun 0.01% (Earth-Sun) 0.15% (Neptune-Sun) 1.2% (Jupiter-Sun) Kepler Mission See: kepler.nasa.gov Has so far discovered 6000+ Confirmed & Candidate Exoplanets The Search for Planets Outside Our Solar System Exoplanet Census May 2017 Exoplanet Census (May-2017) Confirmed exoplanets: 3483+ (Doppler / Transit) 490+ Multi-planet Systems [April 2017] Exoplanet Candidates: 7900+ orbiting 2600+ stars (Mostly from the Kepler Mission) [May 2017] Other unconfirmed (mostly from CoRot)Exoplanets ~186+ Potentially Habitable Exoplanets: 51 (April 2017) Estimated Planets in the Galaxy ~ 50 -100 Billion! Most expected to be hosted by red dwarf stars Nomad (Free-floating planets) ~ 25 - 50 Billion Known planets with life: 1 so far. -

Transition from Eyeball to Snowball Driven by Sea-Ice Drift on Tidally Locked Terrestrial Planets
Transition from Eyeball to Snowball Driven by Sea-ice Drift on Tidally Locked Terrestrial Planets Jun Yang1,*, Weiwen Ji1, & Yaoxuan Zeng1 1Department of Atmospheric and Oceanic Sciences, School of Physics, Peking University, Beijing, 100871, China. *Corresponding author: J.Y., [email protected] Tidally locked terrestrial planets around low-mass stars are the prime targets for future atmospheric characterizations of potentially habitable systems1, especially the three nearby ones–Proxima b2, TRAPPIST-1e3, and LHS 1140b4. Previous studies suggest that if these planets have surface ocean they would be in an eyeball-like climate state5-10: ice-free in the vicinity of the substellar point and ice-covered in the rest regions. However, an important component of the climate system–sea ice dynamics has not been well studied in previous studies. A fundamental question is: would the open ocean be stable against a globally ice-covered snowball state? Here we show that sea-ice drift cools the ocean’s surface when the ice flows to the warmer substellar region and melts through absorbing heat from the ocean and the overlying air. As a result, the open ocean shrinks and can even disappear when atmospheric greenhouse gases are not much more abundant than on Earth, turning the planet into a snowball state. This occurs for both synchronous rotation and spin- orbit resonances (such as 3:2). These results suggest that sea-ice drift strongly reduces the open ocean area and can significantly impact the habitability of tidally locked planets. 1 Sea-ice drift, driven by surface winds and ocean currents, transports heat and freshwater across the ocean surface, directly or indirectly influencing ice concentration, ice growth and melt, ice thickness, surface albedo, and air–sea heat exchange11,12. -

How to Find Life on Other Planets?
Thermodynamic exo-civilization markers: What it takes to find them in a census of the solar neighborhood Jeff Kuhn (Svetlana Berdyugina...Dave Halliday, Caisey Harlingten) Fermi (1950): “Where is everyone?” A timescale problem Life on the Earth is 3.8Gyrs old Within 100,000 lt-yr there are about 100 billion stars In cosmic terms, the Sun is neither particularly old, nor young…. So, If any civilizations live for thousands or millions of years, why don’t we see evidence of them? “We’re not special” SETI Programs: Making the Fermi paradox an astrophysical problem Search for intentional or beaconed alien signals . Radio communication . Optical communication Power leakage classification (Kardashev 1964): . Type I: planet-scale energy use . Type II: star-scale energy use . Type III: galaxy-scale energy use But these are heavily based on assumptions about alien sociology... Unintentional signals: . Dyson (1960): thermal signature of star-enclosing biosphere . Carrigan (2009): IR survey, Type II and III, no candidates Seeing Extra-Terrestrial Civilizations, Timeline: (“We’re not special”) time ETC ETC becomes “emerges” “hot” and Earth’s detection thermodynamically technology developed visible Fraction of Number ETCs Fraction with Fraction that “Successful” Detectible Planets develop Civilization civilizations N = N f n f f f DSCS P HZ BE Number Stars Number planets Fraction that warm In detection in Habitable Zone Before Earth radius Suppose we could detect ETCs… • NS -- 600 stars bright enough (with mV < 13) within 60 light years • fP – about 50% have planets • nHZ – about 0.5 habitable zone planets per extrasolar system • fC – we’re not special, say 50% develop civilizations sometime • fBE – we’re not special, say 50% are more advanced than Earth • fS – the probability that civilization “survives” ND = 38 x fS or 7% of NS x fS The likelihood that civilization is long-lived is something we can (potentially!) learn from astronomical observations… Power Consumption Type I’s evolve toward greater power consumption . -

The Breakthrough Listen Search for Intelligent Life: Observations of 1327 Nearby Stars Over 1.10–3.45 Ghz Submitted to Apj
Draft version June 17, 2019 Typeset using LATEX twocolumn style in AASTeX62 The Breakthrough Listen Search for Intelligent Life: Observations of 1327 Nearby Stars over 1.10{3.45 GHz Danny C. Price,1, 2 J. Emilio Enriquez,1, 3 Bryan Brzycki,1 Steve Croft,1 Daniel Czech,1 David DeBoer,1 Julia DeMarines,1 Griffin Foster,1, 4 Vishal Gajjar,1 Nectaria Gizani,1, 5 Greg Hellbourg,1 Howard Isaacson,1, 6 Brian Lacki,7 Matt Lebofsky,1 David H. E. MacMahon,1 Imke de Pater,1 Andrew P. V. Siemion,1, 8, 3, 9 Dan Werthimer,1 James A. Green,10 Jane F. Kaczmarek,10 Ronald J. Maddalena,11 Stacy Mader,10 Jamie Drew,12 and S. Pete Worden12 1Department of Astronomy, University of California Berkeley, Berkeley CA 94720 2Centre for Astrophysics & Supercomputing, Swinburne University of Technology, Hawthorn, VIC 3122, Australia 3Department of Astrophysics/IMAPP,Radboud University, Nijmegen, Netherlands 4Astronomy Department, University of Oxford, Keble Rd, Oxford, OX13RH, United Kingdom 5Hellenic Open University, School of Science & Technology, Parodos Aristotelous, Perivola Patron, Greece 6University of Southern Queensland, Toowoomba, QLD 4350, Australia 7Breakthrough Listen, Department of Astronomy, University of California Berkeley, Berkeley CA 94720 8SETI Institute, Mountain View, California 9University of Malta, Institute of Space Sciences and Astronomy 10Australia Telescope National Facility, CSIRO, PO Box 76, Epping, NSW 1710, Australia 11Green Bank Observatory, West Virginia, 24944, USA 12The Breakthrough Initiatives, NASA Research Park, Bld. 18, Moffett Field, CA, 94035, USA (Received June 17, 2019; Revised June 17, 2019; Accepted XXX) Submitted to ApJ ABSTRACT Breakthrough Listen (BL) is a ten-year initiative to search for signatures of technologically capable life beyond Earth via radio and optical observations of the local Universe. -

Exoplanet.Eu Catalog Page 1 Star Distance Star Name Star Mass
exoplanet.eu_catalog star_distance star_name star_mass Planet name mass 1.3 Proxima Centauri 0.120 Proxima Cen b 0.004 1.3 alpha Cen B 0.934 alf Cen B b 0.004 2.3 WISE 0855-0714 WISE 0855-0714 6.000 2.6 Lalande 21185 0.460 Lalande 21185 b 0.012 3.2 eps Eridani 0.830 eps Eridani b 3.090 3.4 Ross 128 0.168 Ross 128 b 0.004 3.6 GJ 15 A 0.375 GJ 15 A b 0.017 3.6 YZ Cet 0.130 YZ Cet d 0.004 3.6 YZ Cet 0.130 YZ Cet c 0.003 3.6 YZ Cet 0.130 YZ Cet b 0.002 3.6 eps Ind A 0.762 eps Ind A b 2.710 3.7 tau Cet 0.783 tau Cet e 0.012 3.7 tau Cet 0.783 tau Cet f 0.012 3.7 tau Cet 0.783 tau Cet h 0.006 3.7 tau Cet 0.783 tau Cet g 0.006 3.8 GJ 273 0.290 GJ 273 b 0.009 3.8 GJ 273 0.290 GJ 273 c 0.004 3.9 Kapteyn's 0.281 Kapteyn's c 0.022 3.9 Kapteyn's 0.281 Kapteyn's b 0.015 4.3 Wolf 1061 0.250 Wolf 1061 d 0.024 4.3 Wolf 1061 0.250 Wolf 1061 c 0.011 4.3 Wolf 1061 0.250 Wolf 1061 b 0.006 4.5 GJ 687 0.413 GJ 687 b 0.058 4.5 GJ 674 0.350 GJ 674 b 0.040 4.7 GJ 876 0.334 GJ 876 b 1.938 4.7 GJ 876 0.334 GJ 876 c 0.856 4.7 GJ 876 0.334 GJ 876 e 0.045 4.7 GJ 876 0.334 GJ 876 d 0.022 4.9 GJ 832 0.450 GJ 832 b 0.689 4.9 GJ 832 0.450 GJ 832 c 0.016 5.9 GJ 570 ABC 0.802 GJ 570 D 42.500 6.0 SIMP0136+0933 SIMP0136+0933 12.700 6.1 HD 20794 0.813 HD 20794 e 0.015 6.1 HD 20794 0.813 HD 20794 d 0.011 6.1 HD 20794 0.813 HD 20794 b 0.009 6.2 GJ 581 0.310 GJ 581 b 0.050 6.2 GJ 581 0.310 GJ 581 c 0.017 6.2 GJ 581 0.310 GJ 581 e 0.006 6.5 GJ 625 0.300 GJ 625 b 0.010 6.6 HD 219134 HD 219134 h 0.280 6.6 HD 219134 HD 219134 e 0.200 6.6 HD 219134 HD 219134 d 0.067 6.6 HD 219134 HD -

Do M Dwarfs Pulsate? the Search with the Beating Red Dots Project Using HARPS
Highlights on Spanish Astrophysics X, Proceedings of the XIII Scientific Meeting of the Spanish Astronomical Society held on July 16 – 20, 2018, in Salamanca, Spain. B. Montesinos, A. Asensio Ramos, F. Buitrago, R. Schödel, E. Villaver, S. Pérez-Hoyos, I. Ordóñez-Etxeberria (eds.), 2019 Do M dwarfs pulsate? The search with the Beating Red Dots project using HARPS. Zaira M. Berdi~nas 1, Eloy Rodr´ıguez 2, Pedro J. Amado 2, Cristina Rodr´ıguez-L´opez2, Guillem Anglada-Escud´e 3, and James S. Jenkins1 1 Departamento de Astronom´ıa,Universidad de Chile, Camino el Observatorio 1515, Las Condes, Santiago, Chile. 2 Instituto de Astrof´ısica de Andaluc´ıa–CSIC,Glorieta de la Astonom´ıaS/N, E-18008 Granada, Spain 3 School of Physics and Astronomy, Queen Mary University of London, 327 Mile End Rd., London, E1 4NS, UK. Abstract Only a few decades have been necessary to change our picture of a lonely Universe. Nowa- days, red stars have become one of the most exciting hosts of exoplanets (e.g. Proxima Cen [1], Trappist-1 [8], Barnard's star [12]). However, the most popular techniques used to detect exoplanets, i.e. the radial velocities and transit methods, are indirect. As a consequence, the exoplanet parameters obtained are always relative to the stellar parameters. The study of stellar pulsations has demonstrated to be able to give some of the stellar parameters at an unprecedented level of accuracy, thus accordingly decreasing the uncertainties of the mass and radii parameters estimated for their exoplanets. Theoretical studies predict that M dwarfs can pulsate, i.e. -

The Search for Extraterrestrial Intelligence (Seti)
27 Jul 2001 20:34 AR AR137-13.tex AR137-13.SGM ARv2(2001/05/10) P1: GSR Annu. Rev. Astron. Astrophys. 2001. 39:511–48 Copyright c 2001 by Annual Reviews. All rights reserved THE SEARCH FOR EXTRATERRESTRIAL INTELLIGENCE (SETI) Jill Tarter SETI Institute, 2035 Landings Drive, Mountain View, California 94043; e-mail: [email protected] Key Words exobiology, astrobiology, bioastronomy, optical SETI, life in the universe ■ Abstract The search for evidence of extraterrestrial intelligence is placed in the broader astronomical context of the search for extrasolar planets and biomarkers of primitive life elsewhere in the universe. A decision tree of possible search strategies is presented as well as a brief history of the search for extraterrestrial intelligence (SETI) projects since 1960. The characteristics of 14 SETI projects currently operating on telescopes are discussed and compared using one of many possible figures of merit. Plans for SETI searches in the immediate and more distant future are outlined. Plans for success, the significance of null results, and some opinions on deliberate transmission of signals (as well as listening) are also included. SETI results to date are negative, but in reality, not much searching has yet been done. INTRODUCTION From the dawn of civilization, humans have looked skyward and wondered whether by University of Oregon on 09/13/06. For personal use only. we share this universe with other sentient beings. For millennia we have asked our philosophers and priests to answer this question for us. Answers have always been forthcoming and have reflected the belief system represented by the person providing the answers (Dick 1998).