Sequential Preference Revelation in Incomplete Information Settings”
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Use of Mixed Signaling Strategies in International Crisis Negotiations
USE OF MIXED SIGNALING STRATEGIES IN INTERNATIONAL CRISIS NEGOTIATIONS DISSERTATION Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Unislawa M. Wszolek, B.A., M.A. ***** The Ohio State University 2007 Dissertation Committee: Approved by Brian Pollins, Adviser Daniel Verdier Adviser Randall Schweller Graduate Program in Political Science ABSTRACT The assertion that clear signaling prevents unnecessary war drives much of the recent developments in research on international crises signaling, so much so that this work has aimed at identifying types of clear signals. But if clear signals are the only mechanism for preventing war, as the signaling literature claims, an important puzzle remains — why are signals that combine both carrot and stick components sent and why are signals that are partial or ambiguous sent. While these signals would seemingly work at cross-purposes undermining the signaler’s goals, actually, we observe them frequently in crises that not only end short of war but also that realize the signaler’s goals. Through a game theoretic model, this dissertation theorizes that because these alternatives to clear signals increase the attractiveness, and therefore the likelihood, of compliance they are a more cost-effective way to show resolve and avoid unnecessary conflict than clear signals. In addition to building a game theoretic model, an additional contribution of this thesis is to develop a method for observing mixed versus clear signaling strategies and use this method to test the linkage between signaling and crisis outcomes. Results of statistical analyses support theoretical expectations: clear signaling strategies might not always be the most effective way to secure peace, while mixed signaling strategies can be an effective deterrent. -

Equilibrium Refinements
Equilibrium Refinements Mihai Manea MIT Sequential Equilibrium I In many games information is imperfect and the only subgame is the original game. subgame perfect equilibrium = Nash equilibrium I Play starting at an information set can be analyzed as a separate subgame if we specify players’ beliefs about at which node they are. I Based on the beliefs, we can test whether continuation strategies form a Nash equilibrium. I Sequential equilibrium (Kreps and Wilson 1982): way to derive plausible beliefs at every information set. Mihai Manea (MIT) Equilibrium Refinements April 13, 2016 2 / 38 An Example with Incomplete Information Spence’s (1973) job market signaling game I The worker knows her ability (productivity) and chooses a level of education. I Education is more costly for low ability types. I Firm observes the worker’s education, but not her ability. I The firm decides what wage to offer her. In the spirit of subgame perfection, the optimal wage should depend on the firm’s beliefs about the worker’s ability given the observed education. An equilibrium needs to specify contingent actions and beliefs. Beliefs should follow Bayes’ rule on the equilibrium path. What about off-path beliefs? Mihai Manea (MIT) Equilibrium Refinements April 13, 2016 3 / 38 An Example with Imperfect Information Courtesy of The MIT Press. Used with permission. Figure: (L; A) is a subgame perfect equilibrium. Is it plausible that 2 plays A? Mihai Manea (MIT) Equilibrium Refinements April 13, 2016 4 / 38 Assessments and Sequential Rationality Focus on extensive-form games of perfect recall with finitely many nodes. An assessment is a pair (σ; µ) I σ: (behavior) strategy profile I µ = (µ(h) 2 ∆(h))h2H: system of beliefs ui(σjh; µ(h)): i’s payoff when play begins at a node in h randomly selected according to µ(h), and subsequent play specified by σ. -

Lecture Notes
GRADUATE GAME THEORY LECTURE NOTES BY OMER TAMUZ California Institute of Technology 2018 Acknowledgments These lecture notes are partially adapted from Osborne and Rubinstein [29], Maschler, Solan and Zamir [23], lecture notes by Federico Echenique, and slides by Daron Acemoglu and Asu Ozdaglar. I am indebted to Seo Young (Silvia) Kim and Zhuofang Li for their help in finding and correcting many errors. Any comments or suggestions are welcome. 2 Contents 1 Extensive form games with perfect information 7 1.1 Tic-Tac-Toe ........................................ 7 1.2 The Sweet Fifteen Game ................................ 7 1.3 Chess ............................................ 7 1.4 Definition of extensive form games with perfect information ........... 10 1.5 The ultimatum game .................................. 10 1.6 Equilibria ......................................... 11 1.7 The centipede game ................................... 11 1.8 Subgames and subgame perfect equilibria ...................... 13 1.9 The dollar auction .................................... 14 1.10 Backward induction, Kuhn’s Theorem and a proof of Zermelo’s Theorem ... 15 2 Strategic form games 17 2.1 Definition ......................................... 17 2.2 Nash equilibria ...................................... 17 2.3 Classical examples .................................... 17 2.4 Dominated strategies .................................. 22 2.5 Repeated elimination of dominated strategies ................... 22 2.6 Dominant strategies .................................. -

Characterizing Solution Concepts in Terms of Common Knowledge Of
Characterizing Solution Concepts in Terms of Common Knowledge of Rationality Joseph Y. Halpern∗ Computer Science Department Cornell University, U.S.A. e-mail: [email protected] Yoram Moses† Department of Electrical Engineering Technion—Israel Institute of Technology 32000 Haifa, Israel email: [email protected] March 15, 2018 Abstract Characterizations of Nash equilibrium, correlated equilibrium, and rationaliz- ability in terms of common knowledge of rationality are well known (Aumann 1987; arXiv:1605.01236v1 [cs.GT] 4 May 2016 Brandenburger and Dekel 1987). Analogous characterizations of sequential equi- librium, (trembling hand) perfect equilibrium, and quasi-perfect equilibrium in n-player games are obtained here, using results of Halpern (2009, 2013). ∗Supported in part by NSF under grants CTC-0208535, ITR-0325453, and IIS-0534064, by ONR un- der grant N00014-02-1-0455, by the DoD Multidisciplinary University Research Initiative (MURI) pro- gram administered by the ONR under grants N00014-01-1-0795 and N00014-04-1-0725, and by AFOSR under grants F49620-02-1-0101 and FA9550-05-1-0055. †The Israel Pollak academic chair at the Technion; work supported in part by Israel Science Foun- dation under grant 1520/11. 1 Introduction Arguably, the major goal of epistemic game theory is to characterize solution concepts epistemically. Characterizations of the solution concepts that are most commonly used in strategic-form games, namely, Nash equilibrium, correlated equilibrium, and rational- izability, in terms of common knowledge of rationality are well known (Aumann 1987; Brandenburger and Dekel 1987). We show how to get analogous characterizations of sequential equilibrium (Kreps and Wilson 1982), (trembling hand) perfect equilibrium (Selten 1975), and quasi-perfect equilibrium (van Damme 1984) for arbitrary n-player games, using results of Halpern (2009, 2013). -

TESIS DOCTORAL Three Essays on Game Theory
UNIVERSIDAD CARLOS III DE MADRID TESIS DOCTORAL Three Essays on Game Theory Autor: José Carlos González Pimienta Directores: Luis Carlos Corchón Francesco De Sinopoli DEPARTAMENTO DE ECONOMÍA Getafe, Julio del 2007 Three Essays on Game Theory Carlos Gonzalez´ Pimienta To my parents Contents List of Figures iii Acknowledgments 1 Chapter 1. Introduction 3 Chapter 2. Conditions for Equivalence Between Sequentiality and Subgame Perfection 5 2.1. Introduction 5 2.2. Notation and Terminology 7 2.3. Definitions 9 2.4. Results 12 2.5. Examples 24 2.6. Appendix: Notation and Terminology 26 Chapter 3. Undominated (and) Perfect Equilibria in Poisson Games 29 3.1. Introduction 29 3.2. Preliminaries 31 3.3. Dominated Strategies 34 3.4. Perfection 42 3.5. Undominated Perfect Equilibria 51 Chapter 4. Generic Determinacy of Nash Equilibrium in Network Formation Games 57 4.1. Introduction 57 4.2. Preliminaries 59 i ii CONTENTS 4.3. An Example 62 4.4. The Result 64 4.5. Remarks 66 4.6. Appendix: Proof of Theorem 4.1 70 Bibliography 73 List of Figures 2.1 Notation and terminology of finite extensive games with perfect recall 8 2.2 Extensive form where no information set is avoidable. 11 2.3 Extensive form where no information set is avoidable in its minimal subform. 12 2.4 Example of the use of the algorithm contained in the proof of Proposition 2.1 to generate a game where SPE(Γ) = SQE(Γ). 14 6 2.5 Selten’s horse. An example of the use of the algorithm contained in the proof of proposition 2.1 to generate a game where SPE(Γ) = SQE(Γ). -

Signaling Games
Signaling Games Farhad Ghassemi Abstract - We give an overview of signaling games and their relevant so- lution concept, perfect Bayesian equilibrium. We introduce an example of signaling games and analyze it. 1 Introduction In the general framework of incomplete information or Bayesian games, it is usually assumed that information is equally distributed among players; i.e. there exists a commonly known probability distribution of the unknown parameter(s) of the game. However, very often in the real life, we are confronted with games in which players have asymmetric information about the unknown parameter of the game; i.e. they have different probability distributions of the unknown parameter. As an example, consider a game in which the unknown parameter of the game can be measured by the players but with different degrees of accuracy. Those players that have access to more accurate methods of measurement are definitely in an advantageous position. In extreme cases of asymmetric information games, one player has complete information about the unknown parameter of the game while others only know it by a probability distribution. In these games, the information is completely one-sided. The informed player, for instance, may be the only player in the game who can have different types and while he knows his type, other do not (e.g. a prospect job applicant knows if he has high or low skills for a job but the employer does not) or the informed player may know something about the state of the world that others do not (e.g. a car dealer knows the quality of the cars he sells but buyers do not). -

Perfect Conditional E-Equilibria of Multi-Stage Games with Infinite Sets
Perfect Conditional -Equilibria of Multi-Stage Games with Infinite Sets of Signals and Actions∗ Roger B. Myerson∗ and Philip J. Reny∗∗ *Department of Economics and Harris School of Public Policy **Department of Economics University of Chicago Abstract Abstract: We extend Kreps and Wilson’s concept of sequential equilibrium to games with infinite sets of signals and actions. A strategy profile is a conditional -equilibrium if, for any of a player’s positive probability signal events, his conditional expected util- ity is within of the best that he can achieve by deviating. With topologies on action sets, a conditional -equilibrium is full if strategies give every open set of actions pos- itive probability. Such full conditional -equilibria need not be subgame perfect, so we consider a non-topological approach. Perfect conditional -equilibria are defined by testing conditional -rationality along nets of small perturbations of the players’ strate- gies and of nature’s probability function that, for any action and for almost any state, make this action and state eventually (in the net) always have positive probability. Every perfect conditional -equilibrium is a subgame perfect -equilibrium, and, in fi- nite games, limits of perfect conditional -equilibria as 0 are sequential equilibrium strategy profiles. But limit strategies need not exist in→ infinite games so we consider instead the limit distributions over outcomes. We call such outcome distributions per- fect conditional equilibrium distributions and establish their existence for a large class of regular projective games. Nature’s perturbations can produce equilibria that seem unintuitive and so we augment the game with a net of permissible perturbations. -

Signaling Games Y ECON 201B - Game Theory
Notes on Signaling Games y ECON 201B - Game Theory Guillermo Ordoñez UCLA February 23, 2007 1 Understanding a Signaling Game Consider the following game. This is a typical signaling game that follows the classical "beer and quiche" structure. In these notes I will discuss the elements of this particular type of games, equilibrium concepts to use and how to solve for pooling, separating, hybrid and completely mixed sequential equilibria. 1.1 Elements of the game The game starts with a "decision" by Nature, which determines whether player 1 is of type I or II with a probability p = Pr(I) (in this example we assume 1 p = 2 ). Player 1, after learning his type, must decide whether to play L or R. Since player 1 knows his type, the action will be decided conditioning on it. 0 These notes were prepared as a back up material for TA session. If you have any questions or comments,y or notice any errors or typos, please drop me a line at [email protected] 1 After player 1 moves, player 2 is able to see the action taken by player 1 but not the type of player 1. Hence, conditional on the action observed she has to decide whether to play U or D. Hence, it’spossible to de…ne strategies for each player (i) as For player 1, a mapping from types to actions 1 : I aL + (1 a)R and II bL + (1 b)R ! ! For player 2, a mapping from player 1’sactions to her own actions 2 : L xU + (1 x)D and R yU + (1 y)D ! ! In this game there is no subgame since we cannot …nd any single node where a game completely separated from the rest of the tree starts. -

Perfect Bidder Collusion Through Bribe and Request*
Perfect bidder collusion through bribe and request* Jingfeng Lu† Zongwei Lu ‡ Christian Riis§ May 31, 2021 Abstract We study collusion in a second-price auction with two bidders in a dy- namic environment. One bidder can make a take-it-or-leave-it collusion pro- posal, which consists of both an offer and a request of bribes, to the opponent. We show that there always exists a robust equilibrium in which the collusion success probability is one. In the equilibrium, for each type of initiator the expected payoff is generally higher than the counterpart in any robust equi- libria of the single-option model (Eso¨ and Schummer(2004)) and any other separating equilibria in our model. Keywords: second-price auction, collusion, multidimensional signaling, bribe JEL codes: D44, D82 arXiv:1912.03607v2 [econ.TH] 28 May 2021 *We are grateful to the editors in charge and an anonymous reviewer for their insightful comments and suggestions, which greatly improved the quality of our paper. Any remaining errors are our own. †Department of Economics, National University of Singapore. Email: [email protected]. ‡School of Economics, Shandong University. Email: [email protected]. §Department of Economics, BI Norwegian Business School. Email: [email protected]. 1 1 Introduction Under standard assumptions, auctions are a simple yet effective economic insti- tution that allows the owner of a scarce resource to extract economic rents from buyers. Collusion among bidders, on the other hand, can ruin the rents and hence should be one of the main issues that are always kept in the minds of auction de- signers with a revenue-maximizing objective. -

Selectionfree Predictions in Global Games with Endogenous
Theoretical Economics 8 (2013), 883–938 1555-7561/20130883 Selection-free predictions in global games with endogenous information and multiple equilibria George-Marios Angeletos Department of Economics, Massachusetts Institute of Technology, and Department of Economics, University of Zurich Alessandro Pavan Department of Economics, Northwestern University Global games with endogenous information often exhibit multiple equilibria. In this paper, we show how one can nevertheless identify useful predictions that are robust across all equilibria and that cannot be delivered in the common- knowledge counterparts of these games. Our analysis is conducted within a flexi- ble family of games of regime change, which have been used to model, inter alia, speculative currency attacks, debt crises, and political change. The endogeneity of information originates in the signaling role of policy choices. A novel procedure of iterated elimination of nonequilibrium strategies is used to deliver probabilis- tic predictions that an outside observer—an econometrician—can form under ar- bitrary equilibrium selections. The sharpness of these predictions improves as the noise gets smaller, but disappears in the complete-information version of the model. Keywords. Global games, multiple equilibria, endogenous information, robust predictions. JEL classification. C7, D8, E5, E6, F3. 1. Introduction In the last 15 years, the global-games methodology has been used to study a variety of socio-economic phenomena, including currency attacks, bank runs, debt crises, polit- ical change, and party leadership.1 Most of the appeal of this methodology for applied George-Marios Angeletos: [email protected] Alessandro Pavan: [email protected] This paper grew out of prior joint work with Christian Hellwig and would not have been written without our earlier collaboration; we are grateful for his contribution during the early stages of the project. -

Game Theory for Linguists
Overview Review: Session 1-3 Rationalizability, Beliefs & Best Response Signaling Games Game Theory for Linguists Fritz Hamm, Roland Mühlenbernd 9. Mai 2016 Game Theory for Linguists Overview Review: Session 1-3 Rationalizability, Beliefs & Best Response Signaling Games Overview Overview 1. Review: Session 1-3 2. Rationalizability, Beliefs & Best Response 3. Signaling Games Game Theory for Linguists Overview Review: Session 1-3 Rationalizability, Beliefs & Best Response Signaling Games Conclusions Conclusion of Sessions 1-3 I a game describes a situation of multiple players I that can make decisions (choose actions) I that have preferences over ‘interdependent’ outcomes (action profiles) I preferences are defined by a utility function I games can be defined by abstracting from concrete utility values, but describing it with a general utility function (c.f. synergistic relationship, contribution to public good) I a solution concept describes a process that leads agents to a particular action I a Nash equilibrium defines an action profile where no agent has a need to change the current action I Nash equilibria can be determined by Best Response functions, or by ‘iterated elimination’ of Dominated Actions Game Theory for Linguists Overview Review: Session 1-3 Rationalizability, Beliefs & Best Response Signaling Games Rationalizability Rationalizability I The Nash equilibrium as a solution concept for strategic games does not crucially appeal to a notion of rationality in a players reasoning. I Another concept that is more explicitly linked to a reasoning process of players in a one-shot game is called ratiolalizability. I The set of rationalizable actions can be found by the iterated strict dominance algorithm: I Given a strategic game G I Do the following step until there aren’t dominated strategies left: I for all players: remove all dominated strategies in game G Game Theory for Linguists Overview Review: Session 1-3 Rationalizability, Beliefs & Best Response Signaling Games Rationalizability Nash Equilibria and Rationalizable Actions 1. -
SS364 Game Theory
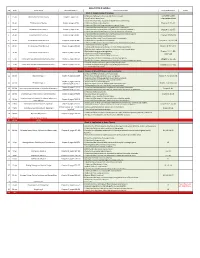
SS364 AY19-2 Syllabus LSN Date Topic/Event Required Reading Learning Objectives Assigned Problems Notes Block 1: Simple Game of Strategy 1. Understand what game theory is and where it is used. Complete Cadet 1 10-Jan Introduction to Game Theory Chapter 1, pages 3-16 2. Identify where games occur Information Sheet 1. Know the components of a game and game theory terminology. 2 14-Jan The Structure of Games Chapter 2, pages 17-41 2. Understand how to classify games. Chapter 2: U1-U4 3. Understand the underlying assumptions in game theory. 1. Understand the extensive form of a game and its components. 3 18-Jan Sequential Move Games 1 Chapter 3, pages 47-63 2. Understand how to solve games using backward induction ("rollback"). Chapter 3: U2-U5 3. Explain the difference between first- and second-mover advantage. 1. Understand the complexities that arise by adding more moves to a game. 4 23-Jan Sequential Move Games 2 Chapter 3, pages 63-81 Chapter 3: U7-U10 2. Explain the intermediate valuation function. 1. Understand the normal form of a game and its components. 5 25-Jan Simultaneous Move Games 1 Chapter 4, pages 91-108 2. Explain the concept of a Nash Equilibrium. Chapter 4: U1, U4, U6 3. Understand the process of iterated elimination of dominated strategies. 1. Understand coordination games. 6 29-Jan Simultaneous Move Games 2 Chapter 4, pages 108-120 Chapter 4: U10-U12 2. Explain what happens when there is no pure strategy equilibrium. 1. Calculate best-response rules used to solve games in continuous space.