Large-Scale Cluster Analysis of Elite Male and Female Swimmers' Race
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
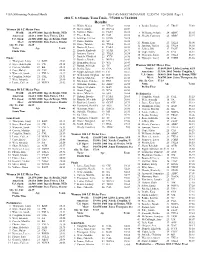
2004 Olympic Trials Results
USA Swimming-National Meets Hy-Tek's MEET MANAGER 12:55 PM 1/26/2005 Page 1 2004 U. S. Olympic Team Trials - 7/7/2004 to 7/14/2004 Results 13 Walsh, Mason 19 VTAC 26.08 8 Benko, Lindsay 27 TROJ 55.69 Women 50 LC Meter Free 15 Silver, Emily 18 NOVA 26.09 World: 24.13W 2000 Inge de Bruijn, NED 16 Vollmer, Dana 16 FAST 26.12 9 Williams, Stefanie 24 ABSC 55.95 American: 24.63A 2000 Dara Torres, USA 17 Price, Keiko 25 CAL 26.16 10 Shealy, Courtney 26 ABSC 55.97 18 Jennings, Emilee 15 KING 26.18 U.S. Open: 24.50O 2000 Inge de Bruijn, NED 19 Radke, Katrina 33 SC 26.22 Meet: 24.90M 2000 Dara Torres, Stanfor 11 Phenix, Erin 23 TXLA 56.00 20 Stone, Tammie 28 TXLA 26.23 Oly. Tr. Cut: 26.39 12 Jamison, Tanica 22 TXLA 56.02 21 Boutwell, Lacey 21 PASA 26.29 Name Age Team 13 Jeffrey, Rhi 17 FAST 56.09 22 Harada, Kimberly 23 STAR 26.33 Finals Time 14 Cope, Haley 25 CAJ 56.11 23 Jamison, Tanica 22 TXLA 26.34 15 Wanezek, Sarah 21 TXLA 56.19 24 Daniels, Elizabeth 22 JCCS 26.36 Finals 16 Nymeyer, Lacey 18 FORD 56.56 25 Boncher, Brooke 21 NOVA 26.42 1 Thompson, Jenny 31 BAD 25.02 26 Hernandez, Sarah 19 WA 26.43 2 Joyce, Kara Lynn 18 CW 25.11 27 Bastak, Ashleigh 22 TC 26.47 Women 100 LC Meter Free 3 Correia, Maritza 22 BA 25.15 28 Denby, Kara 18 CSA 26.50 World: 53.66W 2004 Libby Lenton, AUS 4 Cope, Haley 25 CAJ 25.22 29 Ripple Johnston, Shell 23 ES 26.51 American: 53.99A 2002 Natalie Coughlin, U 5 Wanezek, Sarah 21 TXLA 25.27 29 Medendorp, Meghan 22 IST 26.51 U.S. -

Articolo GAZZETTA DI PARMA 08/09/2003 Scarica E Bocchia Le
Articolo GAZZETTA DI PARMA 08/09/2003 NUOTO—Inizia una stagione densa di avvenimenti importanti che culminerà con le Olimpiadi Scarica e Bocchia le stelle del «Club 91» La stagione agonistica 2003-2004 si apre con grandi attese per il nuoto parmense. Ne è la riprova il fatto che il Nuoto Club 91 Parma, dopo sole due settimane di riposo, vede già i suoi atleti impegnati nei primi allenamenti per prepararsi al meglio agli appuntamenti che più contano. All'orizzonte, vi sono i campionati Europei di Madrid in calendario per il mese di maggio ed in agosto nientemeno che le Olimpiadi di Atene. Per la società di Parma, che annovera nelle sue file atleti della nazionale assoluta e giovanile, quali Michele Scarica e Federico Bocchia, oltre ad altri atleti di livello nazionale e regionale, la stagione si presenta, dunque, colma di impegni che proviamo a sintetizzare ed analizzare col d.t. Andrea Avanzini. Una stagione ricca di grandi gare; quali saranno le principali? «La stagione presenta almeno quattro appuntamenti importantissimi: a dicembre i campionati mondiali in vasca corta; a marzo i campionati italiani primaverili, validi per la qualificazione olimpica; a maggio i campionati europei a Madrid ed infine, ad agosto, le Olimpiadi di Atene». In quest'ottica su cosa puntate per Scarica e Bocchia? «Sarà una stagione ricca di avvenimenti e Michele deve centrare la qualificazione olimpica. Per questo, nei prossimi giorni, avrò un incontro coi vertici della nazionale per decidere i dettagli dei raduni collegiali pre-olimpici in programmi in America e Sud Africa. Attualmente Michele è già in collegiale con la Nazionale a Riccione dal 25 agosto e vi rimarrà fino al 7 settembre, unitamente a tutti gli atleti pre-selezionati per le Olimpiadi 2004. -

Massimiliano Rosolino Speaker Profile
Massimiliano Rosolino Gold Medal Winning Olympic Swimmer Massimiliano Rosolino is Italy's most successful swimmer ever. At the Sydney Olympics in 2000 he won three medals including gold in the 200m medley setting an Olympic Record in the process. He has also competed successfully in the world and European championships with a host of gold, silver and bronze medals to his name. He currently holds the Italian 200m medley and 800m freestyle records. "An Italian sporting icon In detail Languages Massimiliano was born in Naples and moved to Australia when he He presents in English or Italian. was a child. He first participated at the Olympics in 1996 in Atlanta where he reached three finals (200m, 400m and 4x200m Want to know more? freestyle), finishing sixth in all of them. It wasn't until the World Give us a call or send us an e-mail to find out exactly what he Championships in Perth in 1998 when he won a silver medal that could bring to your event. he showed his true ability as one of world's great swimmers. How to book him? What he offers you Simply phone, fax or e-mail us. Drawing on his own personal experiences competing around the world at the highest level, Massimiliano shows audiences the Credentials drive and determination that have made him into a champion. He Olympic Games inspires and motivates audiences with his infectious winning spirit Gold 2000 Sydney 200m Individual Medley and spurs individuals on to succeed beyond their wildest dreams. Silver 2000 Sydney 400m Freestyle How he presents Bronze 2000 Sydney 200m FreestyleBronze 2004 Athens 4x200m Freestyle Relay A charismatic individual Massimiliano's presentations empower Bronze 2004 Athens 4x200m Freestyle Relay audiences with their mix of confidence building strategies and entertaining anecdotes. -

Men's Butterfly
Men’s All-Time World LCM Performers-Performances Rankings Page 1 of 125 100 METER BUTTERFLY Top 6460 Performances 49.82** Michael Phelps, USA 13th World Championships Rome 08-01-09 (Splits: 23.36, 49.82 [26.46]. (Reaction Time: +0.69. (Note: Phelps’ third world-record in 100 fly, second time in 23 days he has broken it. Last man to break wr twice in same year was Australian Michael Klim, who did it twice in two days in December of 1999 in Canberra, when he swam 52.03 [12/10] and 51.81 two days later. (Note: first time record has been broken in Rome and/or Italy. (Note: Phelps’ second-consecutive gold. Ties him with former U.S. teammate Ian Crocker for most wins in this event [2]. Phelps also won @ Melbourne [2007] in a then pr 50.77. U.S. has eight of 13 golds overall. (Note: Phelps first man to leave a major international competition holding both butterfly world records since Russia’s Denis Pankratov following the European Championships in Vienna 14 years ago [August 1995]. Pankratov first broke the 200 world record of USA’s Melvin Sewart [1:55.69 to win gold @ the 1991 World Championships in Perth] with his 1:55.22 @ Canet in June of ’95. The Russian then won the gold and broke the global-standard in the 100 w/his 52.32 @ Vienna two months later. That swim took down the USA’s Pablo Morales’ 52.84 from the U.S. World Championship Trials in Orlando nine years earlier [June ‘86]. -

Conférence De Presse Présentation Des Championnats De France De Natation Angers – Piscine Jean Bouin
Conférence de presse Présentation des Championnats de France de Natation Angers – Piscine Jean Bouin 2 Présentation des Championnats de France de natation petit bassin Angers, les 5, 6 et 7 décembre 2008 CONFERENCE DE PRESSE Mercredi 5 novembre,11H00 à la Piscine Jean Bouin Sommaire > Le comité d’organisation > Présentation des championnats > Information sur la billetterie Toutes les infos sur les Championnats de France de Natation d’Angers > www.ffnatation.fr et www.angers-natation.com Le site : Piscine Jean Bouin, 31 boulevard Pierre de Coubertin, 49000 Angers 2 Le Comité d’Organisation Suite au succès d’organisation des Championnats de France des Maîtres en 2007 (2300 nageurs pendant 4 jours), Angers Natation s’est positionné auprès de la FFN pour accueillir d’autres grandes manifestation. L’opportunité s’est présentée rapidement avec le désistement de Lyon en juin pour problème de capacité hôtelière (autres manifestations simultanées). La FFN, via les comités régionaux, a sollicité les clubs ayant un bassin homologué pour ce type de compétitions. Le 17 septembre 2008, la FFN accorde à Angers Natation l’organisation. Pour favoriser cette réussite, le club s’est assuré du soutien du Comité Départemental de natation et des partenariats suivants : - Ville d’Angers - Conseil Général de Maine et Loire - Conseil Régional des Pays de la Loire - aiiinsi qu’Angers LiLoire Métropo le, la Mu tua lité d’An jou, le CéditCrédit MtMutue l, le Courrier de l’Ouest, Groupe Excel, Sport 2000, ABG, la Clinique du sport,3 Super U les Justices… Un plateau attendu ! A trois jours seulement des Championnats d’Europe petit bassin où l’élite de la natation française ssenvolera’envolera pour la Croatie, les médaillés olympiques Alain Bernard, Amaury Leveaux, Hugues Duboscq, Frédérick Bousquet et Fabien Gilot, seront présents à Angers pour participer aux championnats de France. -

Code De Conduite Pour Le Water Polo
HistoFINA SWIMMING MEDALLISTS AND STATISTICS AT OLYMPIC GAMES Last updated in November, 2016 (After the Rio 2016 Olympic Games) Fédération Internationale de Natation Ch. De Bellevue 24a/24b – 1005 Lausanne – Switzerland TEL: (41-21) 310 47 10 – FAX: (41-21) 312 66 10 – E-mail: [email protected] Website: www.fina.org Copyright FINA, Lausanne 2013 In memory of Jean-Louis Meuret CONTENTS OLYMPIC GAMES Swimming – 1896-2012 Introduction 3 Olympic Games dates, sites, number of victories by National Federations (NF) and on the podiums 4 1896 – 2016 – From Athens to Rio 6 Olympic Gold Medals & Olympic Champions by Country 21 MEN’S EVENTS – Podiums and statistics 22 WOMEN’S EVENTS – Podiums and statistics 82 FINA Members and Country Codes 136 2 Introduction In the following study you will find the statistics of the swimming events at the Olympic Games held since 1896 (under the umbrella of FINA since 1912) as well as the podiums and number of medals obtained by National Federation. You will also find the standings of the first three places in all events for men and women at the Olympic Games followed by several classifications which are listed either by the number of titles or medals by swimmer or National Federation. It should be noted that these standings only have an historical aim but no sport signification because the comparison between the achievements of swimmers of different generations is always unfair for several reasons: 1. The period of time. The Olympic Games were not organised in 1916, 1940 and 1944 2. The evolution of the programme. -

1/4/2004 Piscina Olímpica Encantada T
Untitled 1/5/04 10:24 AM Licensed to Natacion Fernando Delgado Hy-Tek's Meet Manager II WINTER TRAINING MEET - 1/4/2004 PISCINA OLÍMPICA ENCANTADA TRUJILLO ALTO, PUERTO RICO Results Event 1 Women Open 200 LC Meter Medley Relay =============================================================================== MEET RECORD: * 2:07.03 1/5/2003 SYRACUSE, SYRACUSE- R Wrede, J Jonusaitis, E McDonough, C Jansen School Seed Finals =============================================================================== 1 NOTRE DAME SWIMMING 'A' 2:00.78 2:05.38* 2 NOTRE DAME SWIMMING 'B' 2:05.85 2:06.39* 3 SYRACUSE ORANGEMEN 'A' 2:04.13 2:07.59 4 YALE 'A' 1:59.10 2:09.30 5 ST'S. JOHNS UNIVERSITY 'A' 1:58.35 2:09.94 6 NADADORES SANTURCE 'A' 2:11.51 2:12.48 7 SETON HALL UNIVERSITY 'A' 2:07.98 2:13.43 8 YALE 'B' 2:03.60 2:13.86 9 ST'S. JOHNS UNIVERSITY 'B' 2:01.50 2:14.43 10 GEORGETOWN SWIMMING 'A' 2:10.33 2:15.81 11 ST'S. JOHNS UNIVERSITY 'C' 2:05.00 2:16.53 12 BRANDIES UNIVERSITY 'A' 3:11.00 2:17.50 13 YALE 'C' 2:05.70 2:17.73 14 SETON HALL UNIVERSITY 'B' 2:15.64 2:20.05 15 NADADORES SANTURCE 'B' 2:15.87 2:20.21 16 NOTRE DAME SWIMMING 'C' 2:10.77 2:22.08 17 GEORGETOWN SWIMMING 'B' 2:14.55 2:22.68 18 MONTCLAIR STATE UNIVERSITY 'A' 2:07.30 2:29.65 19 BRANDIES UNIVERSITY 'B' 3:20.00 2:29.75 Event 2 Men Open 200 LC Meter Medley Relay =============================================================================== MEET RECORD: * 1:53.79 1/5/2003 YALE UNIVERSITY, YALE- School Seed Finals =============================================================================== 1 SETON HALL UNIVERSITY 'A' 1:44.09 1:51.80* 2 YALE 'A' 1:44.30 1:53.18* 3 SYRACUSE ORANGEMEN 'A' 1:46.22 1:54.65 4 NADADORES SANTURCE 'A' 1:58.39 1:55.65 5 NADADORES SANTURCE 'B' 2:02.01 1:56.01 6 YALE 'B' 1:49.70 1:56.66 7 ST'S. -

Southern California Swimming, Inc
$6 SOUTHERN CALIFORNIA SWIMMING, INC. a local swimming committee of USA SWIMMING, INC 2011 Swim Guide Published by the House of Delegates of Southern California Swimming Jeri Marshburn, General Chairman Mary J. Swalley, Executive Director SWIM OFFICE 41 Hitchcock Way, Suite B Santa Barbara, California 93105-3101 Post Office Box 30530 Santa Barbara, CA 93130-0530 (805) 682-0135 In Southern California: (800) 824-6206 Monday - Friday, 9 a.m. - 5 p.m. FAX: (805) 687-4175 Visit SCS on the internet at www.socalswim.org Email: [email protected] 1 TABLE OF CONTENTS Southern California Swimming Directory Page 3 Board of Directors & Board of Review Page 4 Committee Officers Page 6 Club Rosters Page 13 Swim Calendar Page 28 Rules and Procedures Page 43 Glossary for Southern California Swimming Page 44 Part One-General Rules and Procedures Page 47 I. Authority and Relationships Page 47 II. Integrity of the Competition Page 48 III. Registration and Affiliation Page 49 IV. Entry into the Competition Page 51 V. Administrative Procedures Page 53 VI. Southern California Swimming Funds Page 54 Part Two-Conduct of the Competition Page 58 I. Conduct of Meets, General Page 58 II. Conduct of Meets, "Timed Finals" Page 58 III. Conduct of Meets, "Heats and Finals" Page 59 IV. Conduct of Meets, "Time Trials" Page 60 V. Submission of Entries Page 60 VI. Limitation on Entries Page 61 VII. Entry Times Page 61 VIII. Errors Related to Entries Page 62 IX. Administration Page 62 Part Three-Senior Competition Page 64 I. Eligibility Page 64 II. Senior Invitationals Page 64 III. -

Analysis of Stroke Rates in Freestyle Events at 2000 Olympics
ANALYSIS OF STROKE RATES IN FREESTYLE EVENTS AT 2000 OLYMPICS By David Pyne & Cassie Trewin Department of Physiology, Australian Institute of Sport The aim of this article is to examine the patterns of stroke rates of successful swimmers during the 2000 Sydney Olympic Games. Stroke rates of swimmers in the Final (top 8 swimmers) of selected Freestyle events were taken from the Competition Analysis of the 2000 Olympic Games (courtesy of the Biomechanics Department, Australian Institute of Sport). The stroke rates for each 25, 50 or 100m race split and placing in the 50, 100, 200 and 400 m freestyle events were collated. The interesting questions are … Were there differences in stroke rates between the sprint (50 and 100m) and middle-distance (200 and 400m) events? Were there any differences in stroke rates between the Men’s and Women’s events? How much variation in stroke rate was evident between swimmers in the same event? And how much difference was observed between first and last lap stroke rates compared to the average for the event for each individual swimmer. The individual and mean stroke rates for each of the finalists in the 50, 100, 200 and 400 Freestyle events are presented in Table 1. Statistical analysis (data not shown) indicated that there were no significant correlations between average stroke rate on any lap and final placing. The only exception was the Women’s 400m Freestyle where the placegetters had a significantly higher average stroke rate over the race than those swimmers finishing outside the medals. This indicates that there is considerable variation in stroke rate between different swimmers at the Olympic level. -

Men's All-Time World Performers-Performances Rankings
Men’s All-Time World Performers-Performances Rankings Page 1 of 127 50 METER BACKSTROKE Top 2660 Performances 24.04** Liam Tancock, GBR 13th World Championships Rome 08-02-09 (Reaction Time: +0.60. (Note: Great Britain’s first male backstroke gold-medalist [50, 100, 200]. Tancock’s first international gold/second world- record. (Note: bronze medalist [2005, Montreal; ’07, Melbourne]) 24.07*# Camille Lacourt, FRA XXX European Championships Budapest 08-12-10 (Reaction Time: +0.74. (Nore: also clocked European-record/history’second-fastest 100 back en route to gold several days earlieir [52.11]) 24.08sf1 Tancock 13th World Championships Rome 08-01-09 (Reaction Time: +0.57) 24.23 Lacourt 16th World Championships Kazan 08-09-15 (Reaction Time: +0.68, gold medalist) 24.24a Junya Koga, JPN 13th World Championships Rome 08-02-09 (Reaction Time: +0.50. (Note: won 100 back gold in an Asian-record 52.26 clocking several days earlier.) 24.27sf2 Lacourt 16th World Championships Kazan 08-08-15 (Reaction Time: +0.69) 24.28 Koga 17th Asian Games Incheon 09-21-14 (Reaction Time: +0.52 [fastest of race]. (Note: Games record, Koga’s third-consecutive gold/record. Won @ Doha in 2K6 [25.40]; Guangzhou, 2K10 [25.08]) 24.29sf2 Koga 13th World Championships Rome 08-01-09 (Reaction Time: +0.48) 24.30sf1 Lacourt XXX European Championships Budapest 08-11-10 (Reaction Time: +0.71) 24.33* Randall Bal, USA/Stanford Eindhoven Swim Cup Eindhoven 12-05-08 (Reaction Time: +0.66) 24.34* Gerhard Zandberg, RSA/Arizona 13th World Championshps Rome 08-02-09 (Note: African record.) 24.36 Lacourt FRA Nationals/WCTs Strasbouug 03-27-11 (Note: French Open-“All Comers” record.) 24.37 Lacourt FRA Nats./Euro. -

EUROPEAN SHORT COURSE Swimming Championships Finalists
EUROPEAN SHORT COURSE Swimming Championships Finalists 20191 Some of the stars of the European Short Course Championships in Copenhagen- top row, left Kirill Prigoda (Russia), centre, Adam Peaty (Great Britain), right, Ruta Meilutyte (Lithuania); middle row, left, Radoslaw Kawecki (Poland), centre, Maxence Orange (France), right, Fanny Lecluyse (Belgium); bottom, left, Andri Govorov (Ukraine), centre, Sarah Koehler (Germany) and Julia Hassler (Liechtenstein), right, Matteo Rivolta (Italy) (Photos: Giorgio Scala & Andrea Staccioli, Deepbluemedia/Insidefoto) 2 European Short Course Swimming Championships Finalists Contents European Sprint Results - Men 4 European Sprint Results - Women 7 European Short Course Championship Venues 10 Short Course Results - Men 11 Short Course Results - Women 88 Short Course Results - Mixed 164 European Sprint Championships Medals Tables - by country 167 European Sprint Championships Medals Tables - by event 169 European Short Course Medals Tables - by country 172 European Short Course Medals Tables - by event 178 European Short Course Leading Medallists - all time 191 Please note that, unless stated otherwise, the photos in this book were taken at the 2017 European Short Course Championships in Copenhagen 3 European Sprints Results 1991 to 1994 This book is in two sections. The first The first European Sprints were held section deals with the European Sprint between December 6th and 8th 1991 at Championships held between 1991 and Gelsenkirchen, Germany when the city 1994; the second, with the European agreed to organise the event with only Short Course Championships from 1996 to four months notice. The first European the present time. The tables of individual Short Course Championships in Rostock medals and event medal tables at the end in 1996 saw a significant expansion with of this publication, therefore, treats them some 36 events. -

Scs-Swim-Guide.Pdf (Socalswim.Org
SOUTHERN CALIFORNIA SWIMMING, INC. (CA) CA is a Local Swimming Committee of USA SWIMMING, INC 2021 Swim Guide Published by the House of Delegates of Southern California Swimming Terry Stoddard, General Chairman SWIM OFFICE 28000 S. Western Ave., #226 San Pedro, CA 90732 -or- Postal Annex – Rancho Palos Verdes Attn: Southern California Swimming 28625 S. Western Ave., Box #182 Rancho Palos Verdes, CA 90275 (310) 684-1151 Monday - Friday, 8:30 a.m. - 4 p.m. Visit Southern California Swimming (CA) on the internet at https://www.socalswim.org Email: [email protected] NOTE: Updates to the 2021 Swim Guide will be available during the calendar year online at socalswim.org 1 Greetings, and Welcome to Southern California Swimming (CA)! CA is one of 59 Local Swimming Committees (LSCs) within USA Swimming. USA Swimming is one of the National Governing Bodies (NGBs) under the United States Olympic Committee (USOC) and the USOC is part of the Federation Internationale de Natation (FINA). FINA is the swimming organization within the International Olympic Committee (IOC)….the group that organizes the Olympics. So, your club is the grassroots level of membership for swimming that goes all the way up to the Olympics! From San Luis Obispo down to San Clemente and over to Las Vegas, we have about 25,000 athletes, coaches, officials and parent volunteers in our membership. Because our LSC is so large--the largest membership in the country--we have 6 Geographic sub- Committees: Coastal, Desert, Eastern, Metro, Pacific and Orange to help with administration and local competitions. CA oversees registration for all our clubs and individual members, swim meet sanctions—roughly 400 swim meets per year are sanctioned/approved by CA, multiple camps and all-star teams, as well as educational programs for everyone.