Tomlab /Snopt1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

University of California, San Diego
UNIVERSITY OF CALIFORNIA, SAN DIEGO Computational Methods for Parameter Estimation in Nonlinear Models A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Physics with a Specialization in Computational Physics by Bryan Andrew Toth Committee in charge: Professor Henry D. I. Abarbanel, Chair Professor Philip Gill Professor Julius Kuti Professor Gabriel Silva Professor Frank Wuerthwein 2011 Copyright Bryan Andrew Toth, 2011 All rights reserved. The dissertation of Bryan Andrew Toth is approved, and it is acceptable in quality and form for publication on microfilm and electronically: Chair University of California, San Diego 2011 iii DEDICATION To my grandparents, August and Virginia Toth and Willem and Jane Keur, who helped put me on a lifelong path of learning. iv EPIGRAPH An Expert: One who knows more and more about less and less, until eventually he knows everything about nothing. |Source Unknown v TABLE OF CONTENTS Signature Page . iii Dedication . iv Epigraph . v Table of Contents . vi List of Figures . ix List of Tables . x Acknowledgements . xi Vita and Publications . xii Abstract of the Dissertation . xiii Chapter 1 Introduction . 1 1.1 Dynamical Systems . 1 1.1.1 Linear and Nonlinear Dynamics . 2 1.1.2 Chaos . 4 1.1.3 Synchronization . 6 1.2 Parameter Estimation . 8 1.2.1 Kalman Filters . 8 1.2.2 Variational Methods . 9 1.2.3 Parameter Estimation in Nonlinear Systems . 9 1.3 Dissertation Preview . 10 Chapter 2 Dynamical State and Parameter Estimation . 11 2.1 Introduction . 11 2.2 DSPE Overview . 11 2.3 Formulation . 12 2.3.1 Least Squares Minimization . -

Derivative-Free Optimization: a Review of Algorithms and Comparison of Software Implementations
J Glob Optim (2013) 56:1247–1293 DOI 10.1007/s10898-012-9951-y Derivative-free optimization: a review of algorithms and comparison of software implementations Luis Miguel Rios · Nikolaos V. Sahinidis Received: 20 December 2011 / Accepted: 23 June 2012 / Published online: 12 July 2012 © Springer Science+Business Media, LLC. 2012 Abstract This paper addresses the solution of bound-constrained optimization problems using algorithms that require only the availability of objective function values but no deriv- ative information. We refer to these algorithms as derivative-free algorithms. Fueled by a growing number of applications in science and engineering, the development of derivative- free optimization algorithms has long been studied, and it has found renewed interest in recent time. Along with many derivative-free algorithms, many software implementations have also appeared. The paper presents a review of derivative-free algorithms, followed by a systematic comparison of 22 related implementations using a test set of 502 problems. The test bed includes convex and nonconvex problems, smooth as well as nonsmooth prob- lems. The algorithms were tested under the same conditions and ranked under several crite- ria, including their ability to find near-global solutions for nonconvex problems, improve a given starting point, and refine a near-optimal solution. A total of 112,448 problem instances were solved. We find that the ability of all these solvers to obtain good solutions dimin- ishes with increasing problem size. For the problems used in this study, TOMLAB/MULTI- MIN, TOMLAB/GLCCLUSTER, MCS and TOMLAB/LGO are better, on average, than other derivative-free solvers in terms of solution quality within 2,500 function evaluations. -

TOMLAB –Unique Features for Optimization in MATLAB
TOMLAB –Unique Features for Optimization in MATLAB Bad Honnef, Germany October 15, 2004 Kenneth Holmström Tomlab Optimization AB Västerås, Sweden [email protected] ´ Professor in Optimization Department of Mathematics and Physics Mälardalen University, Sweden http://tomlab.biz Outline of the talk • The TOMLAB Optimization Environment – Background and history – Technology available • Optimization in TOMLAB • Tests on customer supplied large-scale optimization examples • Customer cases, embedded solutions, consultant work • Business perspective • Box-bounded global non-convex optimization • Summary http://tomlab.biz Background • MATLAB – a high-level language for mathematical calculations, distributed by MathWorks Inc. • Matlab can be extended by Toolboxes that adds to the features in the software, e.g.: finance, statistics, control, and optimization • Why develop the TOMLAB Optimization Environment? – A uniform approach to optimization didn’t exist in MATLAB – Good optimization solvers were missing – Large-scale optimization was non-existent in MATLAB – Other toolboxes needed robust and fast optimization – Technical advantages from the MATLAB languages • Fast algorithm development and modeling of applied optimization problems • Many built in functions (ODE, linear algebra, …) • GUIdevelopmentfast • Interfaceable with C, Fortran, Java code http://tomlab.biz History of Tomlab • President and founder: Professor Kenneth Holmström • The company founded 1986, Development started 1989 • Two toolboxes NLPLIB och OPERA by 1995 • Integrated format for optimization 1996 • TOMLAB introduced, ISMP97 in Lausanne 1997 • TOMLAB v1.0 distributed for free until summer 1999 • TOMLAB v2.0 first commercial version fall 1999 • TOMLAB starting sales from web site March 2000 • TOMLAB v3.0 expanded with external solvers /SOL spring 2001 • Dash Optimization Ltd’s XpressMP added in TOMLAB fall 2001 • Tomlab Optimization Inc. -

Click to Edit Master Title Style
Click to edit Master title style MINLP with Combined Interior Point and Active Set Methods Jose L. Mojica Adam D. Lewis John D. Hedengren Brigham Young University INFORM 2013, Minneapolis, MN Presentation Overview NLP Benchmarking Hock-Schittkowski Dynamic optimization Biological models Combining Interior Point and Active Set MINLP Benchmarking MacMINLP MINLP Model Predictive Control Chiller Thermal Energy Storage Unmanned Aerial Systems Future Developments Oct 9, 2013 APMonitor.com APOPT.com Brigham Young University Overview of Benchmark Testing NLP Benchmark Testing 1 1 2 3 3 min J (x, y,u) APOPT , BPOPT , IPOPT , SNOPT , MINOS x Problem characteristics: s.t. 0 f , x, y,u t Hock Schittkowski, Dynamic Opt, SBML 0 g(x, y,u) Nonlinear Programming (NLP) Differential Algebraic Equations (DAEs) 0 h(x, y,u) n m APMonitor Modeling Language x, y u MINLP Benchmark Testing min J (x, y,u, z) 1 1 2 APOPT , BPOPT , BONMIN x s.t. 0 f , x, y,u, z Problem characteristics: t MacMINLP, Industrial Test Set 0 g(x, y,u, z) Mixed Integer Nonlinear Programming (MINLP) 0 h(x, y,u, z) Mixed Integer Differential Algebraic Equations (MIDAEs) x, y n u m z m APMonitor & AMPL Modeling Language 1–APS, LLC 2–EPL, 3–SBS, Inc. Oct 9, 2013 APMonitor.com APOPT.com Brigham Young University NLP Benchmark – Summary (494) 100 90 80 APOPT+BPOPT APOPT 70 1.0 BPOPT 1.0 60 IPOPT 3.10 IPOPT 50 2.3 SNOPT Percentage (%) 6.1 40 Benchmark Results MINOS 494 Problems 5.5 30 20 10 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 Not worse than 2 times slower than -

Specifying “Logical” Conditions in AMPL Optimization Models
Specifying “Logical” Conditions in AMPL Optimization Models Robert Fourer AMPL Optimization www.ampl.com — 773-336-AMPL INFORMS Annual Meeting Phoenix, Arizona — 14-17 October 2012 Session SA15, Software Demonstrations Robert Fourer, Logical Conditions in AMPL INFORMS Annual Meeting — 14-17 Oct 2012 — Session SA15, Software Demonstrations 1 New and Forthcoming Developments in the AMPL Modeling Language and System Optimization modelers are often stymied by the complications of converting problem logic into algebraic constraints suitable for solvers. The AMPL modeling language thus allows various logical conditions to be described directly. Additionally a new interface to the ILOG CP solver handles logic in a natural way not requiring conventional transformations. Robert Fourer, Logical Conditions in AMPL INFORMS Annual Meeting — 14-17 Oct 2012 — Session SA15, Software Demonstrations 2 AMPL News Free AMPL book chapters AMPL for Courses Extended function library Extended support for “logical” conditions AMPL driver for CPLEX Opt Studio “Concert” C++ interface Support for ILOG CP constraint programming solver Support for “logical” constraints in CPLEX INFORMS Impact Prize to . Originators of AIMMS, AMPL, GAMS, LINDO, MPL Awards presented Sunday 8:30-9:45, Conv Ctr West 101 Doors close 8:45! Robert Fourer, Logical Conditions in AMPL INFORMS Annual Meeting — 14-17 Oct 2012 — Session SA15, Software Demonstrations 3 AMPL Book Chapters now free for download www.ampl.com/BOOK/download.html Bound copies remain available purchase from usual -

Theory and Experimentation
Acta Astronautica 122 (2016) 114–136 Contents lists available at ScienceDirect Acta Astronautica journal homepage: www.elsevier.com/locate/actaastro Suboptimal LQR-based spacecraft full motion control: Theory and experimentation Leone Guarnaccia b,1, Riccardo Bevilacqua a,n, Stefano P. Pastorelli b,2 a Department of Mechanical and Aerospace Engineering, University of Florida 308 MAE-A building, P.O. box 116250, Gainesville, FL 32611-6250, United States b Department of Mechanical and Aerospace Engineering, Politecnico di Torino, Corso Duca degli Abruzzi 24, Torino 10129, Italy article info abstract Article history: This work introduces a real time suboptimal control algorithm for six-degree-of-freedom Received 19 January 2015 spacecraft maneuvering based on a State-Dependent-Algebraic-Riccati-Equation (SDARE) Received in revised form approach and real-time linearization of the equations of motion. The control strategy is 18 November 2015 sub-optimal since the gains of the linear quadratic regulator (LQR) are re-computed at Accepted 18 January 2016 each sample time. The cost function of the proposed controller has been compared with Available online 2 February 2016 the one obtained via a general purpose optimal control software, showing, on average, an increase in control effort of approximately 15%, compensated by real-time implement- ability. Lastly, the paper presents experimental tests on a hardware-in-the-loop six- Keywords: Spacecraft degree-of-freedom spacecraft simulator, designed for testing new guidance, navigation, Optimal control and control algorithms for nano-satellites in a one-g laboratory environment. The tests Linear quadratic regulator show the real-time feasibility of the proposed approach. Six-degree-of-freedom & 2016 The Authors. -
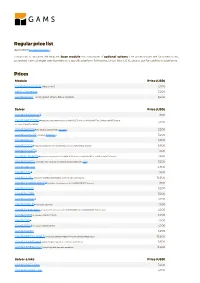
Standard Price List
Regular price list April 2021 (Download PDF ) This price list includes the required base module and a number of optional solvers. The prices shown are for unrestricted, perpetual named single user licenses on a specific platform (Windows, Linux, Mac OS X), please ask for additional platforms. Prices Module Price (USD) GAMS/Base Module (required) 3,200 MIRO Connector 3,200 GAMS/Secure - encrypted Work Files Option 3,200 Solver Price (USD) GAMS/ALPHAECP 1 1,600 GAMS/ANTIGONE 1 (requires the presence of a GAMS/CPLEX and a GAMS/SNOPT or GAMS/CONOPT license, 3,200 includes GAMS/GLOMIQO) GAMS/BARON 1 (for details please follow this link ) 3,200 GAMS/CONOPT (includes CONOPT 4 ) 3,200 GAMS/CPLEX 9,600 GAMS/DECIS 1 (requires presence of a GAMS/CPLEX or a GAMS/MINOS license) 9,600 GAMS/DICOPT 1 1,600 GAMS/GLOMIQO 1 (requires presence of a GAMS/CPLEX and a GAMS/SNOPT or GAMS/CONOPT license) 1,600 GAMS/IPOPTH (includes HSL-routines, for details please follow this link ) 3,200 GAMS/KNITRO 4,800 GAMS/LGO 2 1,600 GAMS/LINDO (includes GAMS/LINDOGLOBAL with no size restrictions) 12,800 GAMS/LINDOGLOBAL 2 (requires the presence of a GAMS/CONOPT license) 1,600 GAMS/MINOS 3,200 GAMS/MOSEK 3,200 GAMS/MPSGE 1 3,200 GAMS/MSNLP 1 (includes LSGRG2) 1,600 GAMS/ODHeuristic (requires the presence of a GAMS/CPLEX or a GAMS/CPLEX-link license) 3,200 GAMS/PATH (includes GAMS/PATHNLP) 3,200 GAMS/SBB 1 1,600 GAMS/SCIP 1 (includes GAMS/SOPLEX) 3,200 GAMS/SNOPT 3,200 GAMS/XPRESS-MINLP (includes GAMS/XPRESS-MIP and GAMS/XPRESS-NLP) 12,800 GAMS/XPRESS-MIP (everything but general nonlinear equations) 9,600 GAMS/XPRESS-NLP (everything but discrete variables) 6,400 Solver-Links Price (USD) GAMS/CPLEX Link 3,200 GAMS/GUROBI Link 3,200 Solver-Links Price (USD) GAMS/MOSEK Link 1,600 GAMS/XPRESS Link 3,200 General information The GAMS Base Module includes the GAMS Language Compiler, GAMS-APIs, and many utilities . -

Research and Development of an Open Source System for Algebraic Modeling Languages
Vilnius University Institute of Data Science and Digital Technologies LITHUANIA INFORMATICS (N009) RESEARCH AND DEVELOPMENT OF AN OPEN SOURCE SYSTEM FOR ALGEBRAIC MODELING LANGUAGES Vaidas Juseviˇcius October 2020 Technical Report DMSTI-DS-N009-20-05 VU Institute of Data Science and Digital Technologies, Akademijos str. 4, Vilnius LT-08412, Lithuania www.mii.lt Abstract In this work, we perform an extensive theoretical and experimental analysis of the char- acteristics of five of the most prominent algebraic modeling languages (AMPL, AIMMS, GAMS, JuMP, Pyomo), and modeling systems supporting them. In our theoretical comparison, we evaluate how the features of the reviewed languages match with the requirements for modern AMLs, while in the experimental analysis we use a purpose-built test model li- brary to perform extensive benchmarks of the various AMLs. We then determine the best performing AMLs by comparing the time needed to create model instances for spe- cific type of optimization problems and analyze the impact that the presolve procedures performed by various AMLs have on the actual problem-solving times. Lastly, we pro- vide insights on which AMLs performed best and features that we deem important in the current landscape of mathematical optimization. Keywords: Algebraic modeling languages, Optimization, AMPL, GAMS, JuMP, Py- omo DMSTI-DS-N009-20-05 2 Contents 1 Introduction ................................................................................................. 4 2 Algebraic Modeling Languages ......................................................................... -

MODELING LANGUAGES in MATHEMATICAL OPTIMIZATION Applied Optimization Volume 88
MODELING LANGUAGES IN MATHEMATICAL OPTIMIZATION Applied Optimization Volume 88 Series Editors: Panos M. Pardalos University o/Florida, U.S.A. Donald W. Hearn University o/Florida, U.S.A. MODELING LANGUAGES IN MATHEMATICAL OPTIMIZATION Edited by JOSEF KALLRATH BASF AG, GVC/S (Scientific Computing), 0-67056 Ludwigshafen, Germany Dept. of Astronomy, Univ. of Florida, Gainesville, FL 32611 Kluwer Academic Publishers Boston/DordrechtiLondon Distributors for North, Central and South America: Kluwer Academic Publishers 101 Philip Drive Assinippi Park Norwell, Massachusetts 02061 USA Telephone (781) 871-6600 Fax (781) 871-6528 E-Mail <[email protected]> Distributors for all other countries: Kluwer Academic Publishers Group Post Office Box 322 3300 AlI Dordrecht, THE NETHERLANDS Telephone 31 78 6576 000 Fax 31 786576474 E-Mail <[email protected]> .t Electronic Services <http://www.wkap.nl> Library of Congress Cataloging-in-Publication Kallrath, Josef Modeling Languages in Mathematical Optimization ISBN-13: 978-1-4613-7945-4 e-ISBN-13:978-1-4613 -0215 - 5 DOl: 10.1007/978-1-4613-0215-5 Copyright © 2004 by Kluwer Academic Publishers Softcover reprint of the hardcover 1st edition 2004 All rights reserved. No part ofthis pUblication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photo-copying, microfilming, recording, or otherwise, without the prior written permission ofthe publisher, with the exception of any material supplied specifically for the purpose of being entered and executed on a computer system, for exclusive use by the purchaser of the work. Permissions for books published in the USA: P"§.;r.m.i.§J?i..QD.§.@:w.k~p" ..,.g.Qm Permissions for books published in Europe: [email protected] Printed on acid-free paper. -

GEKKO Documentation Release 1.0.1
GEKKO Documentation Release 1.0.1 Logan Beal, John Hedengren Aug 31, 2021 Contents 1 Overview 1 2 Installation 3 3 Project Support 5 4 Citing GEKKO 7 5 Contents 9 6 Overview of GEKKO 89 Index 91 i ii CHAPTER 1 Overview GEKKO is a Python package for machine learning and optimization of mixed-integer and differential algebraic equa- tions. It is coupled with large-scale solvers for linear, quadratic, nonlinear, and mixed integer programming (LP, QP, NLP, MILP, MINLP). Modes of operation include parameter regression, data reconciliation, real-time optimization, dynamic simulation, and nonlinear predictive control. GEKKO is an object-oriented Python library to facilitate local execution of APMonitor. More of the backend details are available at What does GEKKO do? and in the GEKKO Journal Article. Example applications are available to get started with GEKKO. 1 GEKKO Documentation, Release 1.0.1 2 Chapter 1. Overview CHAPTER 2 Installation A pip package is available: pip install gekko Use the —-user option to install if there is a permission error because Python is installed for all users and the account lacks administrative priviledge. The most recent version is 0.2. You can upgrade from the command line with the upgrade flag: pip install--upgrade gekko Another method is to install in a Jupyter notebook with !pip install gekko or with Python code, although this is not the preferred method: try: from pip import main as pipmain except: from pip._internal import main as pipmain pipmain(['install','gekko']) 3 GEKKO Documentation, Release 1.0.1 4 Chapter 2. Installation CHAPTER 3 Project Support There are GEKKO tutorials and documentation in: • GitHub Repository (examples folder) • Dynamic Optimization Course • APMonitor Documentation • GEKKO Documentation • 18 Example Applications with Videos For project specific help, search in the GEKKO topic tags on StackOverflow. -

Insight MFR By
Manufacturers, Publishers and Suppliers by Product Category 11/6/2017 10/100 Hubs & Switches ASCEND COMMUNICATIONS CIS SECURE COMPUTING INC DIGIUM GEAR HEAD 1 TRIPPLITE ASUS Cisco Press D‐LINK SYSTEMS GEFEN 1VISION SOFTWARE ATEN TECHNOLOGY CISCO SYSTEMS DUALCOMM TECHNOLOGY, INC. GEIST 3COM ATLAS SOUND CLEAR CUBE DYCONN GEOVISION INC. 4XEM CORP. ATLONA CLEARSOUNDS DYNEX PRODUCTS GIGAFAST 8E6 TECHNOLOGIES ATTO TECHNOLOGY CNET TECHNOLOGY EATON GIGAMON SYSTEMS LLC AAXEON TECHNOLOGIES LLC. AUDIOCODES, INC. CODE GREEN NETWORKS E‐CORPORATEGIFTS.COM, INC. GLOBAL MARKETING ACCELL AUDIOVOX CODI INC EDGECORE GOLDENRAM ACCELLION AVAYA COMMAND COMMUNICATIONS EDITSHARE LLC GREAT BAY SOFTWARE INC. ACER AMERICA AVENVIEW CORP COMMUNICATION DEVICES INC. EMC GRIFFIN TECHNOLOGY ACTI CORPORATION AVOCENT COMNET ENDACE USA H3C Technology ADAPTEC AVOCENT‐EMERSON COMPELLENT ENGENIUS HALL RESEARCH ADC KENTROX AVTECH CORPORATION COMPREHENSIVE CABLE ENTERASYS NETWORKS HAVIS SHIELD ADC TELECOMMUNICATIONS AXIOM MEMORY COMPU‐CALL, INC EPIPHAN SYSTEMS HAWKING TECHNOLOGY ADDERTECHNOLOGY AXIS COMMUNICATIONS COMPUTER LAB EQUINOX SYSTEMS HERITAGE TRAVELWARE ADD‐ON COMPUTER PERIPHERALS AZIO CORPORATION COMPUTERLINKS ETHERNET DIRECT HEWLETT PACKARD ENTERPRISE ADDON STORE B & B ELECTRONICS COMTROL ETHERWAN HIKVISION DIGITAL TECHNOLOGY CO. LT ADESSO BELDEN CONNECTGEAR EVANS CONSOLES HITACHI ADTRAN BELKIN COMPONENTS CONNECTPRO EVGA.COM HITACHI DATA SYSTEMS ADVANTECH AUTOMATION CORP. BIDUL & CO CONSTANT TECHNOLOGIES INC Exablaze HOO TOO INC AEROHIVE NETWORKS BLACK BOX COOL GEAR EXACQ TECHNOLOGIES INC HP AJA VIDEO SYSTEMS BLACKMAGIC DESIGN USA CP TECHNOLOGIES EXFO INC HP INC ALCATEL BLADE NETWORK TECHNOLOGIES CPS EXTREME NETWORKS HUAWEI ALCATEL LUCENT BLONDER TONGUE LABORATORIES CREATIVE LABS EXTRON HUAWEI SYMANTEC TECHNOLOGIES ALLIED TELESIS BLUE COAT SYSTEMS CRESTRON ELECTRONICS F5 NETWORKS IBM ALLOY COMPUTER PRODUCTS LLC BOSCH SECURITY CTC UNION TECHNOLOGIES CO FELLOWES ICOMTECH INC ALTINEX, INC. -

Largest Small N-Polygons: Numerical Results and Conjectured Optima
Largest Small n-Polygons: Numerical Results and Conjectured Optima János D. Pintér Department of Industrial and Systems Engineering Lehigh University, Bethlehem, PA, USA [email protected] Abstract LSP(n), the largest small polygon with n vertices, is defined as the polygon of unit diameter that has maximal area A(n). Finding the configuration LSP(n) and the corresponding A(n) for even values n 6 is a long-standing challenge that leads to an interesting class of nonlinear optimization problems. We present numerical solution estimates for all even values 6 n 80, using the AMPL model development environment with the LGO nonlinear solver engine option. Our results compare favorably to the results obtained by other researchers who solved the problem using exact approaches (for 6 n 16), or general purpose numerical optimization software (for selected values from the range 6 n 100) using various local nonlinear solvers. Based on the results obtained, we also provide a regression model based estimate of the optimal area sequence {A(n)} for n 6. Key words Largest Small Polygons Mathematical Model Analytical and Numerical Solution Approaches AMPL Modeling Environment LGO Solver Suite For Nonlinear Optimization AMPL-LGO Numerical Results Comparison to Earlier Results Regression Model Based Optimum Estimates 1 Introduction The diameter of a (convex planar) polygon is defined as the maximal distance among the distances measured between all vertex pairs. In other words, the diameter of the polygon is the length of its longest diagonal. The largest small polygon with n vertices is the polygon of unit diameter that has maximal area. For any given integer n 3, we will refer to this polygon as LSP(n) with area A(n).