Based Alpha-Taxonomy of Eusocial Organisms
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genus Claviger Preyssler, 1790 (Coleoptera: Staphylinidae: Pselaphinae) in the Low Beskid Mts.(Poland) - New Sites and Host Affiliation
View metadata, citation and similar papers at core.ac.uk brought to you by CORE Title: Genus Claviger Preyssler, 1790 (Coleoptera: Staphylinidae: Pselaphinae) in the Low Beskid Mts.(Poland) - new sites and host affiliation Author: Artur Taszakowski, Bartosz Baran, Natalia Kaszyca, Łukasz Depa Citation style: Taszakowski Artur, Baran Bartosz, Kaszyca Natalia, Depa Łukasz. (2015). Genus Claviger Preyssler, 1790 (Coleoptera: Staphylinidae: Pselaphinae) in the Low Beskid Mts.(Poland) - new sites and host affiliation. "Nature Journal" (Nr 48 (2015), s. 114-119) NATURE JOURNAL VOL. 48: 114–119 (2015) OPOLE SCIENTIFIC SOCIETY GENUS CLAVIGER PREYSSLER , 1790 (C OLEOPTERA : STAPHYLINIDAE : PSELAPHINAE ) IN THE LOW BESKID MTS . (P OLAND ) – NEW SITES AND HOST A FFILIATION 1,3 2,4 1,2,5 1,6 ARTUR TASZAKOWSKI , BARTOSZ BARAN , NATALIA KASZYCA , ŁUKASZ DEPA 1 University of Silesia, Faculty of Biology and Environmental Protection, Department of Zoology, Bankowa 9, 40 – 007 Katowice 2Students’ Scientific Association of Zoologists „Faunatycy” U Ś [email protected], [email protected], [email protected], [email protected] ABSTRACT : In the area of Poland there occur two species of the genus: Claviger longicornis P.W.J. Müller, 1818 and Claviger testaceus Preyssler, 1790. Both species are rare in Poland. Beetles of the genus Claviger are specialized myrmecophiles and are dependent on their host ants throughout the whole life cycle. During the field research, which were conducted in the Low Beskid Mts. (South-Eastern Poland), new sites of both species were found. C. longicornis was recorded in a colony of Lasius sabularum (Bondroit, 1918) and this is the first record of this ant as its host . -

Anet Newsletter 8
30 APRIL 2006 No. 8 ANeT Newsletter International Network for the Study of Asian Ants / DIWPA Network for Social Insect Collections / DIVERSITAS in West Pacific and Asia Proceedings of Committee Meeting of 5th ANeT Workshop Minutes prepared by: Prof. Datin Dr. Maryati Mohamed Institute for Tropical Biology & Conservation Universiti Malaysia Sabah, MALAYSIA Place and Date of the Committee Meeting Committee meeting of 5th ANeT Workshop was held on 30th November 2005 at the National Museum, Kuala Lumpur. The meeting started at 12.30 with a discussion on the draft of Action Plan tabled by Dr. John Fellowes and meeting then chaired by Prof. Maryati Mohamed at 1.00 pm. Meeting adjourned at 3.00 p.m. Members Attending Prof. Maryati Mohamed, the President of ANeT (Malaysia) Prof. Seiki Yamane (Japan) Prof. Kazuo Ogata (Japan) Dr. Rudy Kohout (Australia) Dr. John R. Fellowes (Hong Kong/UK) Mr. Suputa (Indonesia) Dr. Yoshiaki Hashimoto (Japan) Dr. Decha Wiwatwitaya (Thailand) Dr. Bui Tuan Viet (Vietnam) Dr. Himender Bharti (India) Dr. Sriyani Dias (Sri Lanka) Mr. Bakhtiar Effendi Yahya, the Secretariat of ANeT (Japan) Ms. Petherine Jimbau, the Secretariat of ANeT (Malaysia) Agenda Agreed 1. Discussion on Proposal on Action Plan as tabled by Dr. John Fellowes 2. Proceedings/Journal 3. Next meeting - 6th ANeT Seminar and Meeting (date and venue) 4. New members and structure of committee membership 5. Any other business ANeT Newsletter No. 8. 30 April 2006 Agenda Item 1: Discussion on Proposal on Action Plan as tabled by Dr. John Fellowes Draft of Proposal was distributed. During the discussion no amendments were proposed to the draft Action Plan objectives. -
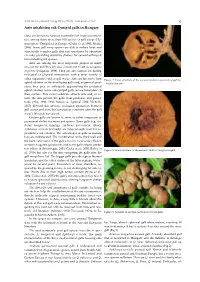
Ants Inhabiting Oak Cynipid Galls in Hungary
North-Western Journal of Zoology 2020, vol.16 (1) - Correspondence: Notes 95 Ants inhabiting oak Cynipid galls in Hungary Oaks are known to harbour extremely rich insect communi- ties, among them more than 100 species of gall wasps (Hy- menoptera: Cynipidae) in Europe (Csóka et al. 2005, Melika 2006). Some gall wasp species are able to induce large and structurally complex galls that can sometimes be abundant on oaks, providing attractive shelters for several arthropod taxa including ant species. Ants are among the most important players in many ecosystems and they are also considered to act as ecosystem engineers (Folgarait, 1998). They are also famous for having ecological or physical interactions with a great variety of other organisms, such as gall wasps. Ants are known to tend Figure 1. Inner structure of the asexual Andricus quercustozae gall in- aphid colonies on the developing galls and, as general pred- habited by ants. ators, they prey on arthropods approaching the protected aphid colonies. Some oak cynipid galls secrete honeydew on their surface. This sweet substrate attracts ants and, in re- turn, the ants protect the galls from predators and parasi- toids (Abe, 1988, 1992; Inouye & Agrawal 2004; Nicholls, 2017). Beyond this obvious ecological interaction between gall wasps and ants, this association continues after the gall wasp’s life cycle has ceased. Certain galls are known to serve as either temporary or permanent shelter for many ant species. Some galls (e.g. An- dricus hungaricus (Hartig), Andricus quercustozae (Bosc), Aphelonyx cerricola (Giraud)) are large enough even for re- productive ant colonies. The advantages of galls as nesting logs are multifaceted. -

Alternative Reproductive Tactics in the Ant Genus Hypoponera
Alternative reproductive tactics in the ant genus Hypoponera Dissertation zur Erlangung des Doktorgrades der Naturwissenschaften an der Fakultät für Biologie der Ludwig-Maximilians-Universität München vorgelegt von Markus H. Rüger aus Marktoberdorf 2007 Erklärung Diese Dissertation wurde im Sinne von § 12 der Promotionsordnung von Frau Prof. Dr. Susanne Foitzik betreut. Ich erkläre hiermit, dass die Dissertation keiner anderen Prüfungskommission vorgelegt worden ist und dass ich mich nicht anderweitig einer Doktorprüfung ohne Erfolg unterzogen habe. Ehrenwörtliche Versicherung Ich versichere hiermit ehrenwörtlich, dass die vorgelegte Dissertation von mir selbständig und ohne unerlaubte Hilfe angefertigt wurde. München den 9. Oktober 2007 ........................................................................... Markus H. Rüger Dissertation eingereicht am: 9. Oktober 2007 1. Gutachter: Prof. Dr. Susanne Foitzik 2. Gutachter: Prof. Dr. Bart Kempenaers Mündliche Prüfung am: 20. Februar 2008 Table of Contents General Introduction…………………………………………………………………. 9 Chapter I: Alternative reproductive tactics and sex allocation in the bivoltine ant Hypoponera opacior…………………………………….... 21 Abstract………………………………………………………………………… 23 Introduction……………………………………………………………………. 25 Material & Methods…………………………………………………………… 27 Results.………………………………………………………………………… 30 Discussion……………………………………………………........................... 38 Conclusions......................................................................................................... 43 Acknowledgements……………………………………………………………. -

Larvae of the Green Lacewing Mallada Desjardinsi (Neuroptera: Chrysopidae) Protect Themselves Against Aphid-Tending Ants by Carrying Dead Aphids on Their Backs
Appl Entomol Zool (2011) 46:407–413 DOI 10.1007/s13355-011-0053-y ORIGINAL RESEARCH PAPER Larvae of the green lacewing Mallada desjardinsi (Neuroptera: Chrysopidae) protect themselves against aphid-tending ants by carrying dead aphids on their backs Masayuki Hayashi • Masashi Nomura Received: 6 March 2011 / Accepted: 11 May 2011 / Published online: 28 May 2011 Ó The Japanese Society of Applied Entomology and Zoology 2011 Abstract Larvae of the green lacewing Mallada desj- Introduction ardinsi Navas are known to place dead aphids on their backs. To clarify the protective role of the carried dead Many ants tend myrmecophilous homopterans such as aphids against ants and the advantages of carrying them for aphids and scale insects, and utilize the secreted honeydew lacewing larvae on ant-tended aphid colonies, we carried as a sugar resource; in return, the homopterans receive out some laboratory experiments. In experiments that beneficial services from the tending ants (Way 1963; Breton exposed lacewing larvae to ants, approximately 40% of the and Addicott 1992; Nielsen et al. 2010). These mutualistic larvae without dead aphids were killed by ants, whereas no interactions between ants and homopterans reduce the larvae carrying dead aphids were killed. The presence of survival and abundance of other arthropods, including the dead aphids did not affect the attack frequency of the non-honeydew-producing herbivores and other predators ants. When we introduced the lacewing larvae onto plants (Bristow 1984; Buckley 1987; Suzuki et al. 2004; Kaplan colonized by ant-tended aphids, larvae with dead aphids and Eubanks 2005), because the tending ants become more stayed for longer on the plants and preyed on more aphids aggressive and attack arthropods that they encounter on than larvae without dead aphids. -

James K. Wetterer
James K. Wetterer Wilkes Honors College, Florida Atlantic University 5353 Parkside Drive, Jupiter, FL 33458 Phone: (561) 799-8648; FAX: (561) 799-8602; e-mail: [email protected] EDUCATION UNIVERSITY OF WASHINGTON, Seattle, WA, 9/83 - 8/88 Ph.D., Zoology: Ecology and Evolution; Advisor: Gordon H. Orians. MICHIGAN STATE UNIVERSITY, East Lansing, MI, 9/81 - 9/83 M.S., Zoology: Ecology; Advisors: Earl E. Werner and Donald J. Hall. CORNELL UNIVERSITY, Ithaca, NY, 9/76 - 5/79 A.B., Biology: Ecology and Systematics. UNIVERSITÉ DE PARIS III, France, 1/78 - 5/78 Semester abroad: courses in theater, literature, and history of art. WORK EXPERIENCE FLORIDA ATLANTIC UNIVERSITY, Wilkes Honors College 8/04 - present: Professor 7/98 - 7/04: Associate Professor Teaching: Biodiversity, Principles of Ecology, Behavioral Ecology, Human Ecology, Environmental Studies, Tropical Ecology, Field Biology, Life Science, and Scientific Writing 9/03 - 1/04 & 5/04 - 8/04: Fulbright Scholar; Ants of Trinidad and Tobago COLUMBIA UNIVERSITY, Department of Earth and Environmental Science 7/96 - 6/98: Assistant Professor Teaching: Community Ecology, Behavioral Ecology, and Tropical Ecology WHEATON COLLEGE, Department of Biology 8/94 - 6/96: Visiting Assistant Professor Teaching: General Ecology and Introductory Biology HARVARD UNIVERSITY, Museum of Comparative Zoology 8/91- 6/94: Post-doctoral Fellow; Behavior, ecology, and evolution of fungus-growing ants Advisors: Edward O. Wilson, Naomi Pierce, and Richard Lewontin 9/95 - 1/96: Teaching: Ethology PRINCETON UNIVERSITY, Department of Ecology and Evolutionary Biology 7/89 - 7/91: Research Associate; Ecology and evolution of leaf-cutting ants Advisor: Stephen Hubbell 1/91 - 5/91: Teaching: Tropical Ecology, Introduction to the Scientific Method VANDERBILT UNIVERSITY, Department of Psychology 9/88 - 7/89: Post-doctoral Fellow; Visual psychophysics of fish and horseshoe crabs Advisor: Maureen K. -

Bee Viruses: Routes of Infection in Hymenoptera
fmicb-11-00943 May 27, 2020 Time: 14:39 # 1 REVIEW published: 28 May 2020 doi: 10.3389/fmicb.2020.00943 Bee Viruses: Routes of Infection in Hymenoptera Orlando Yañez1,2*, Niels Piot3, Anne Dalmon4, Joachim R. de Miranda5, Panuwan Chantawannakul6,7, Delphine Panziera8,9, Esmaeil Amiri10,11, Guy Smagghe3, Declan Schroeder12,13 and Nor Chejanovsky14* 1 Institute of Bee Health, Vetsuisse Faculty, University of Bern, Bern, Switzerland, 2 Agroscope, Swiss Bee Research Centre, Bern, Switzerland, 3 Laboratory of Agrozoology, Department of Plants and Crops, Faculty of Bioscience Engineering, Ghent University, Ghent, Belgium, 4 INRAE, Unité de Recherche Abeilles et Environnement, Avignon, France, 5 Department of Ecology, Swedish University of Agricultural Sciences, Uppsala, Sweden, 6 Environmental Science Research Center, Faculty of Science, Chiang Mai University, Chiang Mai, Thailand, 7 Department of Biology, Faculty of Science, Chiang Mai University, Chiang Mai, Thailand, 8 General Zoology, Institute for Biology, Martin-Luther-University of Halle-Wittenberg, Halle (Saale), Germany, 9 Halle-Jena-Leipzig, German Centre for Integrative Biodiversity Research (iDiv), Leipzig, Germany, 10 Department of Biology, University of North Carolina at Greensboro, Greensboro, NC, United States, 11 Department Edited by: of Entomology and Plant Pathology, North Carolina State University, Raleigh, NC, United States, 12 Department of Veterinary Akio Adachi, Population Medicine, College of Veterinary Medicine, University of Minnesota, Saint Paul, MN, United States, -

James K. Wetterer
James K. Wetterer Wilkes Honors College, Florida Atlantic University 5353 Parkside Drive, Jupiter, FL 33458 Phone: (561) 799-8648; FAX: (561) 799-8602; e-mail: [email protected] EDUCATION UNIVERSITY OF WASHINGTON, Seattle, WA, 9/83 - 8/88 Ph.D., Zoology: Ecology and Evolution; Advisor: Gordon H. Orians. MICHIGAN STATE UNIVERSITY, East Lansing, MI, 9/81 - 9/83 M.S., Zoology: Ecology; Advisors: Earl E. Werner and Donald J. Hall. CORNELL UNIVERSITY, Ithaca, NY, 9/76 - 5/79 A.B., Biology: Ecology and Systematics. UNIVERSITÉ DE PARIS III, France, 1/78 - 5/78 Semester abroad: courses in theater, literature, and history of art. WORK EXPERIENCE FLORIDA ATLANTIC UNIVERSITY, Wilkes Honors College 8/04 - present: Professor 7/98 - 7/04: Associate Professor Teaching: Principles of Ecology, Behavioral Ecology, Human Ecology, Environmental Studies, Tropical Ecology, Biodiversity, Life Science, and Scientific Writing 9/03 - 1/04 & 5/04 - 8/04: Fulbright Scholar; Ants of Trinidad and Tobago COLUMBIA UNIVERSITY, Department of Earth and Environmental Science 7/96 - 6/98: Assistant Professor Teaching: Community Ecology, Behavioral Ecology, and Tropical Ecology WHEATON COLLEGE, Department of Biology 8/94 - 6/96: Visiting Assistant Professor Teaching: General Ecology and Introductory Biology HARVARD UNIVERSITY, Museum of Comparative Zoology 8/91- 6/94: Post-doctoral Fellow; Behavior, ecology, and evolution of fungus-growing ants Advisors: Edward O. Wilson, Naomi Pierce, and Richard Lewontin 9/95 - 1/96: Teaching: Ethology PRINCETON UNIVERSITY, Department of Ecology and Evolutionary Biology 7/89 - 7/91: Research Associate; Ecology and evolution of leaf-cutting ants Advisor: Stephen Hubbell 1/91 - 5/91: Teaching: Tropical Ecology, Introduction to the Scientific Method VANDERBILT UNIVERSITY, Department of Psychology 9/88 - 7/89: Post-doctoral Fellow; Visual psychophysics of fish and horseshoe crabs Advisor: Maureen K. -

Download PDF File (155KB)
Myrmecological News 16 35-38 Vienna, January 2012 The westernmost locations of Lasius jensi SEIFERT, 1982 (Hymenoptera: Formicidae): first records in the Iberian Peninsula David CUESTA-SEGURA, Federico GARCÍA & Xavier ESPADALER Abstract Three populations of Lasius jensi SEIFERT, 1982, a temporary social parasite, from two separate regions in Spain were detected. These locations represent the westernmost populations of the species. Lasius jensi is a new record for the Iberian Peninsula, bringing the total number of native ant species to 285. Dealate queens were captured with pitfall traps from mid July to mid August. Taking into account the other species present in the three populations, the host species could be Lasius alienus (FÖRSTER, 1850), Lasius grandis FOREL, 1909 or Lasius piliferus SEIFERT, 1992. The zoogeographical significance of those populations, probably a relict from glacial refuge, is briefly discussed. Key words: Ants, Formicidae, Lasius jensi, Chthonolasius, Spain, Iberian Peninsula, new record. Myrmecol. News 16: 35-38 (online 30 June 2011) ISSN 1994-4136 (print), ISSN 1997-3500 (online) Received 21 January 2011; revision received 26 April 2011; accepted 29 April 2011 Subject Editor: Florian M. Steiner David Cuesta-Segura (contact author), Department of Biodiversity and Environmental Management, Area of Zoology, University of León, E-24071 León, Spain. E-mail: [email protected] Federico García, C/ Sant Fructuós 113, 3º 3ª, E-08004 Barcelona, Spain. E-mail: [email protected] Xavier Espadaler, Animal Biodiversity Group, Ecology Unit and CREAF, Autonomous University of Barcelona, E-08193 Bellaterra, Spain. Introduction Lasius jensi SEIFERT, 1982 belongs to the subgenus Chtho- tribution data. A fortiori, a distinctive situation occurs at nolasius RUZSKY, 1912, whose species are temporary so- the description of any new species. -

Is Lasius Bicornis (Förster, 1850) a Very Rare Ant Species?
Bulletin de la Société royale belge d’Entomologie/Bulletin van de Koninklijke Belgische Vereniging voor Entomologie, 154 (2018): 37–43 Is Lasius bicornis (Förster, 1850) a very rare ant species? (Hymenoptera: Formicidae) François VANKERKHOVEN1, Luc CRÈVECOEUR2, Maarten JACOBS3, David MULS4 & Wouter DEKONINCK5 1 Mierenwerkgroep Polyergus, Wolvenstraat 9, B-3290 Diest (e-mail: [email protected]) 2 Provinciaal Natuurcentrum, Craenevenne 86, B-3600 Genk (e-mail: [email protected]) 3 Beukenlaan 14, B-2200 Herentals (e-mail: [email protected]) 4 Tuilstraat 15, B-1982 Elewijt (e-mail: [email protected]) 5 Royal Belgian Institute of Natural Sciences, Vautierstraat 29, B-1000 Brussels (e-mail: [email protected]) Abstract Since its description based on a single alate gyne by the German entomologist Arnold Förster, Lasius bicornis (Förster, 1850), previously known as Formicina bicornis, has been sporadically observed in the Eurasian region and consequently been characterized as very rare. Here, we present the Belgian situation and we consider some explanations for the status of this species. Keywords: Hymenoptera, Formicidae, Lasius bicornis, faunistics, Belgium Samenvatting Vanaf de beschrijving door de Duitse entomoloog Arnold Förster, werd Laisus bicornis (Förster, 1850), voordien Formicina bicornis en beschreven op basis van een enkele gyne, slechts sporadisch waargenomen in de Euraziatische regio. De soort wordt dan meer dan 150 jaar later als ‘zeer zeldzaam’ genoteerd. In dit artikel geven we een overzicht van de Belgische situatie en overwegen enkele punten die de zeldzaamheid kunnen verklaren. Résumé Depuis sa description par l’entomologiste allemand Arnold Förster, Lasius bicornis (Förster, 1850), anciennement Formicina bicornis décrite sur base d'une seule gyne ailée, n'a été observée que sporadiquement en Eurasie, ce qui lui donne un statut de «très rare». -

Terrestrial Arthropod Surveys on Pagan Island, Northern Marianas
Terrestrial Arthropod Surveys on Pagan Island, Northern Marianas Neal L. Evenhuis, Lucius G. Eldredge, Keith T. Arakaki, Darcy Oishi, Janis N. Garcia & William P. Haines Pacific Biological Survey, Bishop Museum, Honolulu, Hawaii 96817 Final Report November 2010 Prepared for: U.S. Fish and Wildlife Service, Pacific Islands Fish & Wildlife Office Honolulu, Hawaii Evenhuis et al. — Pagan Island Arthropod Survey 2 BISHOP MUSEUM The State Museum of Natural and Cultural History 1525 Bernice Street Honolulu, Hawai’i 96817–2704, USA Copyright© 2010 Bishop Museum All Rights Reserved Printed in the United States of America Contribution No. 2010-015 to the Pacific Biological Survey Evenhuis et al. — Pagan Island Arthropod Survey 3 TABLE OF CONTENTS Executive Summary ......................................................................................................... 5 Background ..................................................................................................................... 7 General History .............................................................................................................. 10 Previous Expeditions to Pagan Surveying Terrestrial Arthropods ................................ 12 Current Survey and List of Collecting Sites .................................................................. 18 Sampling Methods ......................................................................................................... 25 Survey Results .............................................................................................................. -

Above-Belowground Effects of the Invasive Ant Lasius Neglectus in an Urban Holm Oak Forest
U B Universidad Autónoma de Barce lona Departamento de Biología Animal, de Biología Vegetal y de Ecología Unidad de Ecología Above-belowground effects of the invasive ant Lasius neglectus in an urban holm oak forest Tesis doctoral Carolina Ivon Paris Bellaterra, Junio 2007 U B Universidad Autónoma de Barcelona Departamento de Biología Animal, de Biología Vegetal y de Ecología Unidad de Ecología Above-belowground effects of the invasive ant Lasius neglectus in an urban holm oak forest Memoria presentada por: Carolina Ivon Paris Para optar al grado de Doctora en Ciencias Biológicas Con el Vº. Bº.: Dr Xavier Espadaler Carolina Ivon Paris Investigador de la Unidad de Ecología Doctoranda Director de tesis Bellaterra, Junio de 2007 A mis padres, Andrés y María Marta, y a mi gran amor Pablo. Agradecimientos. En este breve texto quiero homenajear a través de mi más sincero agradecimiento a quienes me ayudaron a mejorar como persona y como científica. Al Dr Xavier Espadaler por admitirme como doctoranda, por estar siempre dispuesto a darme consejos tanto a nivel profesional como personal, por darme la libertad necesaria para crecer como investigadora y orientarme en los momentos de inseguridad. Xavier: nuestras charlas más de una vez trascendieron el ámbito académico y fue un gustazo escucharte y compartir con vos algunos almuerzos. Te prometo que te enviaré hormigas de la Patagonia Argentina para tu deleite taxonómico. A Pablo. ¿Qué puedo decirte mi amor qué ya no te haya dicho? Gracias por la paciencia, el empuje y la ayuda que me diste en todo momento. Estuviste atento a los más mínimos detalles para facilitarme el trabajo de campo y de escritura.