AMD Raven Ridge
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Titan X Amd 1.2 V4 Ig 20210319
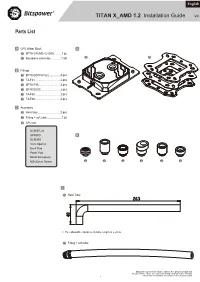
English TITAN X_AMD 1.2 Installation Guide V4 Parts List A CPU Water Block A A-1 BPTA-CPUMS-V2-SKA ..........1 pc A-1 A-2 A-2 Backplane assembly ..............1 set B Fittings B-1 BPTA-DOTFH1622 ...............4 pcs B-2 TA-F61 ...................................2 pcs B-3 BPTA-F95 ..............................2 pcs B-4 BP-RIGOS5 ...........................2 pcs B-5 TA-F60 ..................................2 pcs B-6 TA-F40 ..................................2 pcs C Accessory C-1 Hard tube ..............................2 pcs C-2 Fitting + soft tube ....................1 pc C-3 CPU set SCM3FL20 SPRING B SCM3F6 1mm Spacer Back Pad Paste Pad Metal Backplane M3x32mm Screw B-1 B-2 B-3 B-4 B-5 B-6 C C-1 Hard Tube ※ The allowable variance in tube length is ± 2mm C-2 Fitting + soft tube Bitspower reserves the right to change the product design and interpretations. These are subject to change without notice. Product colors and accessories are based on the actual product. — 1 — I. AMD Motherboard system 54 AMD SOCKET 939 / 754 / 940 IN 48 AMD SOCKET AM4 AMD SOCKET AM3 / AM3+ AMD SOCKET AM2 / AM2+ AMD SOCKET FM1 / FM2+ Bitspower Fan and DRGB RF Remote Controller Hub (Not included) are now available at microcenter.com DRGB PIN on Motherboard or other equipment. 96 90 BPTA-RFCHUB The CPU water block has a DRGB cable, which AMD SOCKET AM4 AMD SOCKET AM3 AM3+ / AMD SOCKET AM2 AM2+ / AMD SOCKET FM1 / FM2+ can be connected to the DRGB extension cable of the radiator fans. Fan and DRGB RF Remote Motherboard Controller Hub (Not included) OUT DRGB LED Do not over-tighten the thumb screws Installation (SCM3FL20). -

ATI Radeon™ HD 4870 Computation Highlights
AMD Entering the Golden Age of Heterogeneous Computing Michael Mantor Senior GPU Compute Architect / Fellow AMD Graphics Product Group [email protected] 1 The 4 Pillars of massively parallel compute offload •Performance M’Moore’s Law Î 2x < 18 Month s Frequency\Power\Complexity Wall •Power Parallel Î Opportunity for growth •Price • Programming Models GPU is the first successful massively parallel COMMODITY architecture with a programming model that managgped to tame 1000’s of parallel threads in hardware to perform useful work efficiently 2 Quick recap of where we are – Perf, Power, Price ATI Radeon™ HD 4850 4x Performance/w and Performance/mm² in a year ATI Radeon™ X1800 XT ATI Radeon™ HD 3850 ATI Radeon™ HD 2900 XT ATI Radeon™ X1900 XTX ATI Radeon™ X1950 PRO 3 Source of GigaFLOPS per watt: maximum theoretical performance divided by maximum board power. Source of GigaFLOPS per $: maximum theoretical performance divided by price as reported on www.buy.com as of 9/24/08 ATI Radeon™HD 4850 Designed to Perform in Single Slot SP Compute Power 1.0 T-FLOPS DP Compute Power 200 G-FLOPS Core Clock Speed 625 Mhz Stream Processors 800 Memory Type GDDR3 Memory Capacity 512 MB Max Board Power 110W Memory Bandwidth 64 GB/Sec 4 ATI Radeon™HD 4870 First Graphics with GDDR5 SP Compute Power 1.2 T-FLOPS DP Compute Power 240 G-FLOPS Core Clock Speed 750 Mhz Stream Processors 800 Memory Type GDDR5 3.6Gbps Memory Capacity 512 MB Max Board Power 160 W Memory Bandwidth 115.2 GB/Sec 5 ATI Radeon™HD 4870 X2 Incredible Balance of Performance,,, Power, Price -

An Evolution of Mobile Graphics
AN EVOLUTION OF MOBILE GRAPHICS Michael C. Shebanow Vice President, Advanced Processor Lab Samsung Electronics July 20, 20131 DISCLAIMER • The views herein are my own • They do not represent Samsung’s vision nor product plans 2 • The Mobile Market • Review of GPU Tech • GPU Efficiency • User Experience • Tech Challenges • Summary 3 The Rise of the Mobile GPU & Connectivity A NEW WORLD COMING? 4 DISCRETE GPU MARKET Flattening 5 MOBILE GPU MARKET Smart • In 2012, an estimated 800+ Phones million mobile GPUs shipped “Phablets” • ~123M tablets • ~712M smart phones Tablets • Will easily exceed 1B in the coming years • Trend: • Discrete GPU relatively flat • Mobile is growing rapidly 6 WW INTERNET TRAFFIC • Source: Cisco VNI Mobile INET IP Traffic growth Traffic • Internet traffic growth Year (TB/sec) rate (TB/sec) rate is staggering 2005 0.9 0.00 2006 1.5 65% 0.00 • 2012 total traffic is 2007 2.5 61% 0.01 13.7 GB per person 2008 3.8 54% 0.01 per month 2009 5.6 45% 0.04 2010 7.8 40% 0.10 • 2012 smart phone 2011 10.6 36% 0.23 traffic at 2012 12.4 17% 0.34 0.342 GB per person per month • 2017 smart phone traffic expected at 2.7 GB per person per month 7 WHERE ARE WE HEADED?… • Enormous quantity of GPUs • Large amount of interconnectivity • Better I/O 8 GPU Pipelines A BRIEF REVIEW OF GPU TECH 9 MOBILE GPU PIPELINE ARCHITECTURES Tile-based immediate mode rendering IA VS CCV RS PS ROP (TBIMR) Tile-based deferred IA VS CCV scene rendering (TBDR) RS PS ROP IA = input assembler VS = vertex shader CCV = cull, clip, viewport transform RS = rasterization, -

NVIDIA Quadro P4000
NVIDIA Quadro P4000 GP104 1792 112 64 8192 MB GDDR5 256 bit GRAPHICS PROCESSOR CORES TMUS ROPS MEMORY SIZE MEMORY TYPE BUS WIDTH The Quadro P4000 is a professional graphics card by NVIDIA, launched in February 2017. Built on the 16 nm process, and based on the GP104 graphics processor, the card supports DirectX 12.0. The GP104 graphics processor is a large chip with a die area of 314 mm² and 7,200 million transistors. Unlike the fully unlocked GeForce GTX 1080, which uses the same GPU but has all 2560 shaders enabled, NVIDIA has disabled some shading units on the Quadro P4000 to reach the product's target shader count. It features 1792 shading units, 112 texture mapping units and 64 ROPs. NVIDIA has placed 8,192 MB GDDR5 memory on the card, which are connected using a 256‐bit memory interface. The GPU is operating at a frequency of 1227 MHz, which can be boosted up to 1480 MHz, memory is running at 1502 MHz. We recommend the NVIDIA Quadro P4000 for gaming with highest details at resolutions up to, and including, 5760x1080. Being a single‐slot card, the NVIDIA Quadro P4000 draws power from 1x 6‐pin power connectors, with power draw rated at 105 W maximum. Display outputs include: 4x DisplayPort. Quadro P4000 is connected to the rest of the system using a PCIe 3.0 x16 interface. The card measures 241 mm in length, and features a single‐slot cooling solution. Graphics Processor Graphics Card GPU Name: GP104 Released: Feb 6th, 2017 Architecture: Pascal Production Active Status: Process Size: 16 nm Bus Interface: PCIe 3.0 x16 Transistors: 7,200 -

Graphics Card Support List
Graphics card support list Device Name Chipset ASUS GTXTITAN-6GD5 NVIDIA GeForce GTX TITAN ZOTAC GTX980 NVIDIA GeForce GTX980 ASUS GTX980-4GD5 NVIDIA GeForce GTX980 MSI GTX980-4GD5 NVIDIA GeForce GTX980 Gigabyte GV-N980D5-4GD-B NVIDIA GeForce GTX980 MSI GTX970 GAMING 4G GOLDEN EDITION NVIDIA GeForce GTX970 Gigabyte GV-N970IXOC-4GD NVIDIA GeForce GTX970 ASUS GTX780TI-3GD5 NVIDIA GeForce GTX780Ti ASUS GTX770-DC2OC-2GD5 NVIDIA GeForce GTX770 ASUS GTX760-DC2OC-2GD5 NVIDIA GeForce GTX760 ASUS GTX750TI-OC-2GD5 NVIDIA GeForce GTX750Ti ASUS ENGTX560-Ti-DCII/2D1-1GD5/1G NVIDIA GeForce GTX560Ti Gigabyte GV-NTITAN-6GD-B NVIDIA GeForce GTX TITAN Gigabyte GV-N78TWF3-3GD NVIDIA GeForce GTX780Ti Gigabyte GV-N780WF3-3GD NVIDIA GeForce GTX780 Gigabyte GV-N760OC-4GD NVIDIA GeForce GTX760 Gigabyte GV-N75TOC-2GI NVIDIA GeForce GTX750Ti MSI NTITAN-6GD5 NVIDIA GeForce GTX TITAN MSI GTX 780Ti 3GD5 NVIDIA GeForce GTX780Ti MSI N780-3GD5 NVIDIA GeForce GTX780 MSI N770-2GD5/OC NVIDIA GeForce GTX770 MSI N760-2GD5 NVIDIA GeForce GTX760 MSI N750 TF 1GD5/OC NVIDIA GeForce GTX750 MSI GTX680-2GB/DDR5 NVIDIA GeForce GTX680 MSI N660Ti-PE-2GD5-OC/2G-DDR5 NVIDIA GeForce GTX660Ti MSI N680GTX Twin Frozr 2GD5/OC NVIDIA GeForce GTX680 GIGABYTE GV-N670OC-2GD NVIDIA GeForce GTX670 GIGABYTE GV-N650OC-1GI/1G-DDR5 NVIDIA GeForce GTX650 GIGABYTE GV-N590D5-3GD-B NVIDIA GeForce GTX590 MSI N580GTX-M2D15D5/1.5G NVIDIA GeForce GTX580 MSI N465GTX-M2D1G-B NVIDIA GeForce GTX465 LEADTEK GTX275/896M-DDR3 NVIDIA GeForce GTX275 LEADTEK PX8800 GTX TDH NVIDIA GeForce 8800GTX GIGABYTE GV-N26-896H-B -

Vorbereitung Auf Comptia A+
Markus Kammermann, Ramon Kratzer CompTIA A+ Systemtechnik und Support von A bis Z Vorbereitung auf die Prüfungen 220-901 und 220-902 Bibliografische Information der Deutschen Nationalbibliothek Die Deutsche Nationalbibliothek verzeichnet diese Publikation in der Deutschen Nationalbibliografie; detaillierte bibliografische Daten sind im Internet über <http://dnb.d-nb.de> abrufbar. ISBN 978-3-95845-466-8 4. Auflage 2016 www.mitp.de E-Mail: [email protected] Telefon: +49 7953 / 7189 – 079 Telefax: +49 7953 / 7189 – 082 © 2016 mitp Verlags GmbH & Co. KG Dieses Werk, einschließlich aller seiner Teile, ist urheberrechtlich geschützt. Jede Verwertung außerhalb der engen Grenzen des Urheberrechtsgesetzes ist ohne Zustimmung des Verlages unzulässig und straf- bar. Dies gilt insbesondere für Vervielfältigungen, Übersetzungen, Mikroverfilmungen und die Einspei- cherung und Verarbeitung in elektronischen Systemen. Die Wiedergabe von Gebrauchsnamen, Handelsnamen, Warenbezeichnungen usw. in diesem Werk berechtigt auch ohne besondere Kennzeichnung nicht zu der Annahme, dass solche Namen im Sinne der Warenzeichen- und Markenschutz-Gesetzgebung als frei zu betrachten wären und daher von jedermann benutzt werden dürften. Dieses Lehrmittel wurde für das CompTIA Authorized Curriculum durch ProCert Labs geprüft und ist CAQC-zertifiziert. Weitere Informationen zu dieser Qualifizierung erhalten Sie unter www.comptia.org/ certification/caqc/ sowie unter der Adresse www.procertlabs.com Das Bildmaterial in diesem Buch, soweit es nicht von uns selber erstellt -

AMD Radeon E8860
Components for AMD’s Embedded Radeon™ E8860 GPU INTRODUCTION The E8860 Embedded Radeon GPU available from CoreAVI is comprised of temperature screened GPUs, safety certi- fiable OpenGL®-based drivers, and safety certifiable GPU tools which have been pre-integrated and validated together to significantly de-risk the challenges typically faced when integrating hardware and software components. The plat- form is an off-the-shelf foundation upon which safety certifiable applications can be built with confidence. Figure 1: CoreAVI Support for E8860 GPU EXTENDED TEMPERATURE RANGE CoreAVI provides extended temperature versions of the E8860 GPU to facilitate its use in rugged embedded applications. CoreAVI functionally tests the E8860 over -40C Tj to +105 Tj, increasing the manufacturing yield for hardware suppliers while reducing supply delays to end customers. coreavi.com [email protected] Revision - 13Nov2020 1 E8860 GPU LONG TERM SUPPLY AND SUPPORT CoreAVI has provided consistent and dedicated support for the supply and use of the AMD embedded GPUs within the rugged Mil/Aero/Avionics market segment for over a decade. With the E8860, CoreAVI will continue that focused support to ensure that the software, hardware and long-life support are provided to meet the needs of customers’ system life cy- cles. CoreAVI has extensive environmentally controlled storage facilities which are used to store the GPUs supplied to the Mil/ Aero/Avionics marketplace, ensuring that a ready supply is available for the duration of any program. CoreAVI also provides the post Last Time Buy storage of GPUs and is often able to provide additional quantities of com- ponents when COTS hardware partners receive increased volume for existing products / systems requiring additional inventory. -

Amd Athlon Ii X2 270 Manual
Amd Athlon Ii X2 270 Manual Specifications. Please visit AMD Athlon II X2 215 (rev. C3) and AMD Athlon II X2 270 pages for more detailed specifications. Review, Differences, Benchmarks, Specifications, Comments Athlon II X2 270. CPUBoss recommends the AMD Athlon II X2 270 based on its. See full details. Specifications. Please visit AMD Athlon II X2 270 and AMD Athlon II X2 280 pages for more detailed specifications of both. Far Cry 4 on AMD Athlon x2 340(Dual Core) 4GB RAM HD 6570 PC Specifications. Specifications. Please visit AMD Athlon II X2 270 and AMD FX-6300 pages for more detailed specifications of both. AMD Athlon II x2 260 (3.2GHz) Although the specifications of this cpu list 74C as the max temp, i prefer to stick to the old "65C max" rule-of-thumb for amd cpus. Amd Athlon Ii X2 270 Manual Read/Download AMD Athlon II X2 270u. 2 GHz, Dual core. Front view of AMD Athlon II X2 270u. 5.9 Out of 10. VS Review, Differences, Benchmarks, Specifications, Comments. Photos of the AMD Athlon II X2 270 Black Edition from the KitGuru Price Comparison Engine. Specifications. Please visit AMD Athlon II X2 270 and AMD FX-4300 pages for more detailed specifications of both. SPECIFICATIONS : Model : AMD Athlon II X2 270. CPU Clock Speed : 3.4 GHz. Core : 2. Total L2 Cache : 2 MB Sockets : Socket AM2+,Socket AM3 Supported. up vote -5 down vote favorite. These are my specifications: AMD Athlon II x2 270 CPU, AMD 760g GPU, 4GB RAM. grand-theft-auto-5. -

Motherboards, Processors, and Memory
220-1001 COPYRIGHTED MATERIAL c01.indd 03/23/2019 Page 1 Chapter Motherboards, Processors, and Memory THE FOLLOWING COMPTIA A+ 220-1001 OBJECTIVES ARE COVERED IN THIS CHAPTER: ✓ 3.3 Given a scenario, install RAM types. ■ RAM types ■ SODIMM ■ DDR2 ■ DDR3 ■ DDR4 ■ Single channel ■ Dual channel ■ Triple channel ■ Error correcting ■ Parity vs. non-parity ✓ 3.5 Given a scenario, install and configure motherboards, CPUs, and add-on cards. ■ Motherboard form factor ■ ATX ■ mATX ■ ITX ■ mITX ■ Motherboard connectors types ■ PCI ■ PCIe ■ Riser card ■ Socket types c01.indd 03/23/2019 Page 3 ■ SATA ■ IDE ■ Front panel connector ■ Internal USB connector ■ BIOS/UEFI settings ■ Boot options ■ Firmware upgrades ■ Security settings ■ Interface configurations ■ Security ■ Passwords ■ Drive encryption ■ TPM ■ LoJack ■ Secure boot ■ CMOS battery ■ CPU features ■ Single-core ■ Multicore ■ Virtual technology ■ Hyperthreading ■ Speeds ■ Overclocking ■ Integrated GPU ■ Compatibility ■ AMD ■ Intel ■ Cooling mechanism ■ Fans ■ Heat sink ■ Liquid ■ Thermal paste c01.indd 03/23/2019 Page 4 A personal computer (PC) is a computing device made up of many distinct electronic components that all function together in order to accomplish some useful task, such as adding up the numbers in a spreadsheet or helping you to write a letter. Note that this defi nition describes a computer as having many distinct parts that work together. Most PCs today are modular. That is, they have components that can be removed and replaced with another component of the same function but with different specifi cations in order to improve performance. Each component has a specifi c function. Much of the computing industry today is focused on smaller devices, such as laptops, tablets, and smartphones. -

MSI MEG X570 GODLIKE Datasheet
MOTHERBOARD MEG X570 GODLIKE ONE BOARD TO RULE THEM ALL FEATURE Mystic Light Infinity II Personalize your PC with 16.8 million colors / 29 effects with MSI Mystic Light APP, making your system come alive with infinity. Dynamic Dashboard Built-in dynamic panel that indicates the status of GODLIKE and shows off your own personality. Lightning Gen4 solution The latest Gen4 PCI-E and M.2 solution with up to 64GB/s bandwidth for maximum transfer speed. Frozr Heatsink Design Designed with the patented fan and double ball bearings to SPECIFICATION provide best performance for enthusiast gamers and prosumers. Extended Heat-Pipe Design Enlarge the surface of heat dissipation, connecting from Model Name MEG X570 GODLIKE MOS heatsink to chipset heatsink. CPU Support Supports 2nd and 3rd Gen AMD Ryzen™ / Ryzen™ with Radeon™ Vega Graphics and 2nd Gen AMD Ryzen™ with Radeon™ Graphics Desktop Processors M.2 Shield FROZR CPU Socket Socket AM4 Strengthened built-in M.2 thermal solution. Keeps M.2 SSDs ® Chipset AMD X570 Chipset safe while preventing throttling, making them run faster. Graphics Interface 4 x PCI-E 4.0 x16 slots Supports 2-way SLI / 4-way CrossFire WIFI 6 Memory Support 4 DIMMs, Dual Channel DDR4 Storage 3 x Lightning Gen 4 M.2 slots The latest wireless solution supports MU-MIMO and BSS 6 x SATA 6Gb/s ports color technology, delivering speeds up to 2400Mbps. USB Ports 5 x USB 3.2 (Gen2, 3A+2C) + 6 x USB 3.2 (Gen1) + 4 x USB 2.0 Core Boost LAN Killer™ E3000 2.5G LAN, Killer™ E2600 Gigabit LAN Wi-Fi / BT Killer™ Wi-Fi 6 AX1650 Combining dual 8 pin power connectors and IR digital power Audio 8-Channel (7.1) HD Audio with XTREME AUDIO DAC design, the GODLIKE is ready for more cores also provide better performance. -

AMD Ryzen™ PRO & Athlon™ PRO Processors Quick Reference Guide
AMD Ryzen™ PRO & Athlon™ PRO Processors Quick Reference guide AMD Ryzen™ PRO Processors with Radeon™ Graphics for Business Laptops (Socket FP6/FP5) 1 Core/Thread Frequency Boost/Base L2+L3 Cache Graphics Node TDP Intel vPro Core/Thread Frequency Boost*/Base L2+L3 Cache Graphics Node TDP AMD PRO technologies COMPARED TO 4.9/1.1 Radeon™ 6/12 UHD AMD Ryzen™ 7 PRO 8/16 Up to 12MB Graphics 7nm 15W intel Intel Core i7 10810U GHz 13MB 4750U 4.1/1.7 GHz CORE i7 14nm 15W (7 Cores) 10th Gen Intel Core i7 10610U 4/8 4.9/1.8 9MB UHD GHz AMD Ryzen™ 7 PRO Up to Radeon™ intel 4/8 6MB 10 12nm 15W 4.8/1.9 3700U 4.0/2.3 GHz Vega CORE i7 Intel Core i7 8665U 4/8 9MB UHD 14nm 15W 8th Gen GHz Radeon™ AMD Ryzen™ 5 PRO 6/12 Up to 11MB Graphics 7nm 15W intel 4.4/1.7 4650U 4.0/2.1 GHz CORE i5 Intel Core i5 10310U 4/8 7MB UHD 14nm 15W GHz (6 Cores) 10th Gen AMD Ryzen™ 5 PRO 4/8 Up to 6MB Radeon™ 12nm 15W intel 4.1/1.6 3500U 3.7/2.1 GHz Vega8 CORE i5 Intel Core i5 8365U 4/8 7MB UHD 14nm 15W th GHz 8 Gen Radeon™ AMD Ryzen™ 3 PRO 4/8 Up to 6MB Graphics 7nm 15W intel 4.1/2.1 4450U 3.7/2.5 GHz CORE i3 Intel Core i3 10110U 2/4 5MB UHD 14nm 15W (5 Cores) 10th Gen GHz AMD Ryzen™ 3 PRO 4/4 Up to 6MB Radeon™ 12nm 15W intel 3.9/2.1 3300U 3.5/2.1 GHz Vega6 CORE i3 Intel Core i3 8145U 2/4 4.5MB UHD 14nm 15W 8th Gen GHz AMD Athlon™ PRO Processors with Radeon™ Vega Graphics for Business Laptops (Socket FP5) AMD Athlon™ PRO Up to Radeon™ intel Intel Pentium 4415U 2/4 2.3 GHz 2.5MB HD 610 14nm 15W 300U 2/4 3.3/2.4 GHz 5MB Vega3 12nm 15W 1. -

AMD FX Cpus Now Faster Than Ever—Unlocked Performance with Maximum Cores
How to Sell the New AMD FX CPUs Now Faster than Ever—Unlocked Performance with Maximum Cores Who’s it for? Gamers and Enthusiasts who want the most out of their PC. Sell it in 5 seconds. More Cores. More Speed. Unlocked1 More Cores > Up to 8 Cores > Only 8 Core Desktop Processor—2 cores more than Intel1 Maximum Speed > Up to 4.2GHz Turbo Clock Speed > Latest Technology and Worlds Highest Frequencies2 Unlocked & Overclockable > Get the Maximum Tunable Performance > Go up to 5.0 GHz with aggressive cooling solutions from AMD3 Sell it in 60 seconds. Unlocked Performance for Less Money1,4 Performance Ferocious power right out of the box. > The groundbreaking AMD FX 8-Core Processor Black Edition comes unlocked. No premium to pay. No code to input.Just unrestrained, overclocked power right away.4 > Groundbreaking technology. Epic performance. > This next-generation architecture takes 8-core processing to a new level. Test the limits to play harder and get more done. Speed The need for speed. AMD FX Processors—Unlocked and overclocked.4 > Incredible speed out of the box and more in the tank; AMD Turbo CORE Technology automatically kicks in, boosting performance to a user’s varied workload. > The sky’s the limit with this processor’s massive headroom. Go up to 5.0 GHz with aggressive cooling solutions from AMD.5 Price Price and performance that keeps getting better and more bang for your buck. Unlocked technology.4 Unbelievable pricing. > With more speed than ever and more aggressive price points – New AMD FX Processors raise the bar for 8-core computing.