The Need for Speed of AI Applications: Performance Comparison Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Install and Configure Cisco Anyconnect VPN
Install and Configure Cisco AnyConnect VPN PURPOSE: • Installing and configuring Cisco AnyConnect • Enabling and Disabling Cisco AnyConnect VERSION SUPPORTED: 4.5.02033 HOW TO INSTALL AND CONFIGURE CISCO ANYCONNECT VPN FOR WINDOWS: From the desktop, open up a web browser (Google Chrome, Mozilla Firefox, Microsoft Edge, or Internet Explorer). Note: Google Chrome will be used in this example. Type in vpn01.cu.edu into the address bar. You will reach a login page, login using your CU System Username and Password. Contact UIS Call: 303-860-4357 Email:[email protected] Click on the AnyConnect button on the bottom of the list on the left-hand side. Select the “Start AnyConnect” button on that page. It will then load a few items, after it finishes click the blue link for “AnyConnect VPN” Contact UIS Call: 303-860-4357 Email:[email protected] This will download the client in the web browser, in Google Chrome this shows up on the bottom section of the page, but other browsers may place the download in a different location. If you cannot find the download, it should go to the Downloads folder within Windows. Contact UIS Call: 303-860-4357 Email:[email protected] We will then run this download by clicking on it in Chrome. Other browsers may offer a “Run” option instead, which acts the same. It will then open up an installer. Click “Next.” Select the “I accept the terms in the License Agreement” button. Click “Next.” Contact UIS Call: 303-860-4357 Email:[email protected] Select “Install”, this will require the username and password you use to login to your personal computer. -

Machine Learning in the Browser
Machine Learning in the Browser The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:38811507 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA Machine Learning in the Browser a thesis presented by Tomas Reimers to The Department of Computer Science in partial fulfillment of the requirements for the degree of Bachelor of Arts in the subject of Computer Science Harvard University Cambridge, Massachusetts March 2017 Contents 1 Introduction 3 1.1 Background . .3 1.2 Motivation . .4 1.2.1 Privacy . .4 1.2.2 Unavailable Server . .4 1.2.3 Simple, Self-Contained Demos . .5 1.3 Challenges . .5 1.3.1 Performance . .5 1.3.2 Poor Generality . .7 1.3.3 Manual Implementation in JavaScript . .7 2 The TensorFlow Architecture 7 2.1 TensorFlow's API . .7 2.2 TensorFlow's Implementation . .9 2.3 Portability . .9 3 Compiling TensorFlow into JavaScript 10 3.1 Motivation to Compile . 10 3.2 Background on Emscripten . 10 3.2.1 Build Process . 12 3.2.2 Dependencies . 12 3.2.3 Bitness Assumptions . 13 3.2.4 Concurrency Model . 13 3.3 Experiences . 14 4 Results 15 4.1 Benchmarks . 15 4.2 Library Size . 16 4.3 WebAssembly . 17 5 Developer Experience 17 5.1 Universal Graph Runner . -

Replication: Why We Still Can't Browse in Peace
Replication: Why We Still Can’t Browse in Peace: On the Uniqueness and Reidentifiability of Web Browsing Histories Sarah Bird, Ilana Segall, and Martin Lopatka, Mozilla https://www.usenix.org/conference/soups2020/presentation/bird This paper is included in the Proceedings of the Sixteenth Symposium on Usable Privacy and Security. August 10–11, 2020 978-1-939133-16-8 Open access to the Proceedings of the Sixteenth Symposium on Usable Privacy and Security is sponsored by USENIX. Replication: Why We Still Can’t Browse in Peace: On the Uniqueness and Reidentifiability of Web Browsing Histories Sarah Bird Ilana Segall Martin Lopatka Mozilla Mozilla Mozilla Abstract This work seeks to reproduce the findings of Olejnik, Castel- We examine the threat to individuals’ privacy based on the luccia, and Janc [48] regarding the leakage of private infor- feasibility of reidentifying users through distinctive profiles mation when users browse the web. The reach of large-scale of their browsing history visible to websites and third par- providers of analytics and advertisement services into the ties. This work replicates and extends the 2012 paper Why overall set of web properties shows a continued increase in Johnny Can’t Browse in Peace: On the Uniqueness of Web visibility [64] by such parties across a plurality of web prop- Browsing History Patterns [48]. The original work demon- erties. This makes the threat of history-based profiling even strated that browsing profiles are highly distinctive and stable. more tangible and urgent now than when originally proposed. We reproduce those results and extend the original work to detail the privacy risk posed by the aggregation of browsing 2 Background and related work histories. -

Embedded Linux for Thin Clients Next Generation (Elux® NG) Version 1.25
Embedded Linux for Thin Clients Next Generation (eLux® NG) Version 1.25 Administrator’s Guide Build Nr.: 23 UniCon Software GmbH www.myelux.com eLux® NG Information in this document is subject to change without notice. Companies, names and data used in examples herein are fictitious unless otherwise noted. No part of this document may be reproduced or transmitted in any form or by any means, electronic or mechanical, for any purpose, without the express consent of UniCon Software GmbH. © by UniCon 2005 Software GmbH. All rights reserved eLux is a registered trademark of UniCon Software GmbH in Germany. Accelerated-X is a trademark of Xi Graphics, Inc. Adobe, Acrobat Reader and PostScript are registered trademarks of Adobe Systems Incorporated in the United States and/or other countries. Broadcom is a registered trademark of Broadcom Corporation in the U.S. and/or other countries. CardOS is a registered trademark and CONNECT2AIR is a trademark of Siemens AG in Germany and/or other countries. Cisco and Aironet are registered trademarks of Cisco Systems, Inc. and/or its affiliates in the U.S. and certain other countries. Citrix, Independent Computing Architecture (ICA), Program Neighborhood, MetaFrame, and MetaFrame XP are registered trademarks or trademarks of Citrix Systems, Inc. in the United States and other countries. CUPS and the Common UNIX Printing System are the trademark property of Easy Software Products. DivX is a trademark of Project Mayo. Ericom and PowerTerm are registered trademarks of Ericom Software in the United States and/or other countries. Gemplus is a registered trademark and GemSAFE a trademark of Gemplus. -
![Browser Versions Carry 10.5 Bits of Identifying Information on Average [Forthcoming Blog Post]](https://docslib.b-cdn.net/cover/0737/browser-versions-carry-10-5-bits-of-identifying-information-on-average-forthcoming-blog-post-190737.webp)
Browser Versions Carry 10.5 Bits of Identifying Information on Average [Forthcoming Blog Post]
Browser versions carry 10.5 bits of identifying information on average [forthcoming blog post] Technical Analysis by Peter Eckersley This is part 3 of a series of posts on user tracking on the modern web. You can also read part 1 and part 2. Whenever you visit a web page, your browser sends a "User Agent" header to the website saying what precise operating system and browser you are using. We recently ran an experiment to see to what extent this information could be used to track people (for instance, if someone deletes their browser cookies, would the User Agent, alone or in combination with some other detail, be enough to re-create their old cookie?). Our experiment to date has shown that the browser User Agent string usually carries 5-15 bits of identifying information (about 10.5 bits on average). That means that on average, only one person in about 1,500 (210.5) will have the same User Agent as you. On its own, that isn't enough to recreate cookies and track people perfectly, but in combination with another detail like an IP address, geolocation to a particular ZIP code, or having an uncommon browser plugin installed, the User Agent string becomes a real privacy problem. User Agents: An Example of Browser Characteristics Doubling As Tracking Tools When we analyse the privacy of web users, we usually focus on user accounts, cookies, and IP addresses, because those are the usual means by which a request to a web server can be associated with other requests and/or linked back to an individual human being, computer, or local network. -

HTTP Cookie - Wikipedia, the Free Encyclopedia 14/05/2014
HTTP cookie - Wikipedia, the free encyclopedia 14/05/2014 Create account Log in Article Talk Read Edit View history Search HTTP cookie From Wikipedia, the free encyclopedia Navigation A cookie, also known as an HTTP cookie, web cookie, or browser HTTP Main page cookie, is a small piece of data sent from a website and stored in a Persistence · Compression · HTTPS · Contents user's web browser while the user is browsing that website. Every time Request methods Featured content the user loads the website, the browser sends the cookie back to the OPTIONS · GET · HEAD · POST · PUT · Current events server to notify the website of the user's previous activity.[1] Cookies DELETE · TRACE · CONNECT · PATCH · Random article Donate to Wikipedia were designed to be a reliable mechanism for websites to remember Header fields Wikimedia Shop stateful information (such as items in a shopping cart) or to record the Cookie · ETag · Location · HTTP referer · DNT user's browsing activity (including clicking particular buttons, logging in, · X-Forwarded-For · Interaction or recording which pages were visited by the user as far back as months Status codes or years ago). 301 Moved Permanently · 302 Found · Help 303 See Other · 403 Forbidden · About Wikipedia Although cookies cannot carry viruses, and cannot install malware on 404 Not Found · [2] Community portal the host computer, tracking cookies and especially third-party v · t · e · Recent changes tracking cookies are commonly used as ways to compile long-term Contact page records of individuals' browsing histories—a potential privacy concern that prompted European[3] and U.S. -

Marcia Knous: My Name Is Marcia Knous
Olivia Ryan: Can you just state your name? Marcia Knous: My name is Marcia Knous. OR: Just give us your general background. How did you come to work at Mozilla and what do you do for Mozilla now? MK: Basically, I started with Mozilla back in the Netscape days. I started working with Mozilla.org shortly after AOL acquired Netscape which I believe was in like the ’99- 2000 timeframe. I started working at Netscape and then in one capacity in HR shortly after I moved working with Mitchell as part of my shared responsibility, I worked for Mozilla.org and sustaining engineering to sustain the communicator legacy code so I supported them administratively. That’s basically what I did for Mozilla. I did a lot of I guess what you kind of call of blue activities where we have a process whereby people get access to our CVS repository so I was the gatekeeper for all the CVS forms and handle all the bugs that were related to CVS requests, that kind of thing. Right now at Mozilla, I do quality assurance and I run both our domestic online store as well as our international store where we sell all of our Mozilla gear. Tom Scheinfeldt: Are you working generally alone in small groups? In large groups? How do you relate to other people working on the project? MK: Well, it’s a rather interesting project. My capacity as a QA person, we basically relate with the community quite a bit because we have a very small internal QA organization. -

Analisi Del Progetto Mozilla
Università degli studi di Padova Facoltà di Scienze Matematiche, Fisiche e Naturali Corso di Laurea in Informatica Relazione per il corso di Tecnologie Open Source Analisi del progetto Mozilla Autore: Marco Teoli A.A 2008/09 Consegnato: 30/06/2009 “ Open source does work, but it is most definitely not a panacea. If there's a cautionary tale here, it is that you can't take a dying project, sprinkle it with the magic pixie dust of "open source", and have everything magically work out. Software is hard. The issues aren't that simple. ” Jamie Zawinski Indice Introduzione................................................................................................................................3 Vision .........................................................................................................................................4 Mozilla Labs...........................................................................................................................5 Storia...........................................................................................................................................6 Mozilla Labs e i progetti di R&D...........................................................................................8 Mercato.......................................................................................................................................9 Tipologia di mercato e di utenti..............................................................................................9 Quote di mercato (Firefox).....................................................................................................9 -
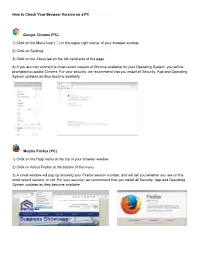
How to Check Your Browser Version on a PC
How to Check Your Browser Version on a PC Google Chrome (PC) 1) Click on the Menu Icon ( ) in the upper right corner of your browser window. 2) Click on Settings 3) Click on the About tab on the left-hand side of the page. 4) If you are not running the most recent version of Chrome available for your Operating System, you will be prompted to update Chrome. For your security, we recommend that you install all Security, App and Operating System updates as they become available. Mozilla Firefox (PC) 1) Click on the Help menu at the top of your browser window. 2) Click on About Firefox at the bottom of the menu. 3) A small window will pop up showing your Firefox version number, and will tell you whether you are on the most recent version, or not. For your security, we recommend that you install all Security, App and Operating System updates as they become available. Internet Explorer (PC) 1) Click on the Gear Icon at the top of your browser window. 2) Click on the About Internet Explorer option. 3) A window will pop up showing you your Internet Explorer version. 4) If you are using Internet Explorer 9 or 10, you will need to make sure that you have TLS 1.2 enabled by: A) Clicking on the Gear Icon again. B) Click on Internet Options. C) Click on the Advanced Tab and scroll down to the option titled “Use TLS 1.2”. (This should be found at the bottome of the list of options.) The box next to this should be checked. -

Mozillamessaging.Com Site Redesign Site Map — Version 3.0 — September 22, 2008
Mozillamessaging.com Site Redesign Site Map — Version 3.0 — September 22, 2008 While this document can be printed at 8.5” x 11” it may be hard to read and is intended to be printed at 11” x 17”. Mozillamessaging.com Site Redesign Version 3.0 Other Systems and Features 03 05 Mozilla Messaging Languages http://www.mozillamessaging.com/en-US/features.html http://www.mozillamessaging.com/en-US/all.html Thunderbird 02 Release Notes 04 Download Page 18 (Overview) http://www.mozillamessaging.com/ http://www.mozillamessaging.com/en-US/releasenotes/ http://www.mozillamessaging.com/en-US/download.html ?? URL TBD en-US/thunderbird Secure Email TBD http://www.mozillamessaging.com/en-US/email.html All Add-Ons https://addons.mozilla.org/en-US/thunderbird/ Supported Servers TBD http://www.mozillamessaging.com/en-US/servers Recommended https://addons.mozilla.org/en-US/thunderbird/recommended Add-Ons Popular https://addons.mozilla.org/en-US/ https://addons.mozilla.org/en-US/thunderbird/browse/type:1/cat:all?sort=popular thunderbird/ FAQ Themes http://www.mozilla.org/support/thunderbird/faq https://addons.mozilla.org/en-US/thunderbird/browse/type:2 Tips & Tricks Dictionaries http://www.mozilla.org/support/thunderbird/tips https://addons.mozilla.org/en-US/thunderbird/browse/type:3 Keyboard Shortcuts http://www.mozilla.org/support/thunderbird/keyboard Mouse Shortcuts Add-Ons Support 06 http://www.mozilla.org/support/thunderbird/mouse https://addons.mozilla.org/en-US/thunderbird/ (Overview) http://www.mozillamessaging.com/ Menu References Bugzilla en-US/support http://www.mozilla.org/support/thunderbird/menu https://bugzilla.mozilla.org/ Editing Config. -

Mozilla Messaging and Thunderbird: Why, And
Email is essential. Let’s make it great. An Introduction to Mozilla Messaging David Ascher [email protected] Why am I here? • To introduce Mozilla • To discuss the current email & messaging challenges • To share the Thunderbird vision • To listen and learn Core Belief The Mozilla project is a global community of people who believe that openness, innovation, and opportunity are key to the continued health of the Internet. A short history 2000 Mozilla Foundation 2005 2008 MozillaMozilla CorporationMessaging Focus and Scope Mozilla Foundation (MoFo) ❖ Everything else Mozilla Corp (MoCo) Mozilla Messaging (MoMo) ❖ Web standards ❖ Email & Calendaring ❖ Web Privacy standards ❖ ❖ Weave Email privacy ❖ ❖ Prism Mobile messaging ❖ Mobile web ❖ Calendaring ❖ IM, etc. Expectation Reset • Mozilla is a public benefit organization • Driven by non-financial outcomes • Use the tools of business and markets to further our agenda What’s the problem with “email”? Instant Messaging News Home Email Email Twitter Web Forums Work Email Pownce Jaiku RSS/Atom MySpace Pulse Atom Pub Facebook FriendFeed LinkedIn Xing VoIP Voicemail SMS What’s the problem with “email”? Instant Messaging News THIS HomeDOES Email Email Twitter Web Forums Work Email Pownce Jaiku RSS/AtomNOTMySpace FIT OURPulse Atom Pub Facebook FriendFeed LinkedIn Xing VoIP Voicemail BRAINS!SMS How did we get here? • Email design predates current internet architecture • Email was “solved”, consolidated, dead. • The Web is changing everything ❖ Economies of clouds & services ❖ Monetization strategies ❖ Social graphs and Identity crisis Still • Messaging is still key to the user experience of the internet • It needs to be: ❖ Open, competitive, interoperable, secure ❖ More effective ❖ Less stressful ❖ Fun again! So? The Mozilla Manifesto 1. -

Internal Message
Earlier today, Mozilla Corporation CEO and Mozilla Foundation Chairwoman Mitchell Baker sent the following message to Mozilla employees. We are making significant changes at Mozilla Corporation today. Pre-COVID, our plan for 2020 was a year of change: building a better internet by accelerating product value in Firefox, increasing innovation, and adjusting our finances to ensure financial stability over the long term. We started with immediate cost-saving measures such as pausing our hiring, reducing our wellness stipend and cancelling our All-Hands. But COVID-19 has accelerated the need and magnified the depth for these changes. Our pre-COVID plan is no longer workable. We have talked about the need for change — including the likelihood of layoffs — since the spring. Today these changes become real. We are also restructuring to put a crisper focus on new product development and go to market activities. In the long run, I am confident that the new organizational structure will serve our product and market impact goals well, but we will talk in detail about this in a bit. But, before that is the painful part. Yes — we need to reduce the size of our workforce. This is hard to internalize and I desperately wish there was some other way to set Mozilla up for success in building a better internet. I desperately wish that all those who choose Mozilla as an employer could stay as long as interest and skills connect. Unfortunately, we can’t make that happen today. We are reducing the size of the MoCo workforce by approximately 250 roles, including closing our current operations in Taipei, Taiwan.