Modern Computer Arithmetic
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Radix-8 Design Alternatives of Fast Two Operands Interleaved
International Journal of Advanced Network, Monitoring and Controls Volume 04, No.02, 2019 Radix-8 Design Alternatives of Fast Two Operands Interleaved Multiplication with Enhanced Architecture With FPGA implementation & synthesize of 64-bit Wallace Tree CSA based Radix-8 Booth Multiplier Mohammad M. Asad Qasem Abu Al-Haija King Faisal University, Department of Electrical Department of Computer Information and Systems Engineering, Ahsa 31982, Saudi Arabia Engineering e-mail: [email protected] Tennessee State University, Nashville, USA e-mail: [email protected] Ibrahim Marouf King Faisal University, Department of Electrical Engineering, Ahsa 31982, Saudi Arabia e-mail: [email protected] Abstract—In this paper, we proposed different comparable researches to propose different solutions to ensure the reconfigurable hardware implementations for the radix-8 fast safe access and store of private and sensitive data by two operands multiplier coprocessor using Karatsuba method employing different cryptographic algorithms and Booth recording method by employing carry save (CSA) and kogge stone adders (KSA) on Wallace tree organization. especially the public key algorithms [1] which proved The proposed designs utilized robust security resistance against most of the attacks family with target chip device along and security halls. Public key cryptography is with simulation package. Also, the proposed significantly based on the use of number theory and designs were synthesized and benchmarked in terms of the digital arithmetic algorithms. maximum operational frequency, the total path delay, the total design area and the total thermal power dissipation. The Indeed, wide range of public key cryptographic experimental results revealed that the best multiplication systems were developed and embedded using hardware architecture was belonging to Wallace Tree CSA based Radix- modules due to its better performance and security. -

Version 0.5.1 of 5 March 2010
Modern Computer Arithmetic Richard P. Brent and Paul Zimmermann Version 0.5.1 of 5 March 2010 iii Copyright c 2003-2010 Richard P. Brent and Paul Zimmermann ° This electronic version is distributed under the terms and conditions of the Creative Commons license “Attribution-Noncommercial-No Derivative Works 3.0”. You are free to copy, distribute and transmit this book under the following conditions: Attribution. You must attribute the work in the manner specified by the • author or licensor (but not in any way that suggests that they endorse you or your use of the work). Noncommercial. You may not use this work for commercial purposes. • No Derivative Works. You may not alter, transform, or build upon this • work. For any reuse or distribution, you must make clear to others the license terms of this work. The best way to do this is with a link to the web page below. Any of the above conditions can be waived if you get permission from the copyright holder. Nothing in this license impairs or restricts the author’s moral rights. For more information about the license, visit http://creativecommons.org/licenses/by-nc-nd/3.0/ Contents Preface page ix Acknowledgements xi Notation xiii 1 Integer Arithmetic 1 1.1 Representation and Notations 1 1.2 Addition and Subtraction 2 1.3 Multiplication 3 1.3.1 Naive Multiplication 4 1.3.2 Karatsuba’s Algorithm 5 1.3.3 Toom-Cook Multiplication 6 1.3.4 Use of the Fast Fourier Transform (FFT) 8 1.3.5 Unbalanced Multiplication 8 1.3.6 Squaring 11 1.3.7 Multiplication by a Constant 13 1.4 Division 14 1.4.1 Naive -

Primality Testing for Beginners
STUDENT MATHEMATICAL LIBRARY Volume 70 Primality Testing for Beginners Lasse Rempe-Gillen Rebecca Waldecker http://dx.doi.org/10.1090/stml/070 Primality Testing for Beginners STUDENT MATHEMATICAL LIBRARY Volume 70 Primality Testing for Beginners Lasse Rempe-Gillen Rebecca Waldecker American Mathematical Society Providence, Rhode Island Editorial Board Satyan L. Devadoss John Stillwell Gerald B. Folland (Chair) Serge Tabachnikov The cover illustration is a variant of the Sieve of Eratosthenes (Sec- tion 1.5), showing the integers from 1 to 2704 colored by the number of their prime factors, including repeats. The illustration was created us- ing MATLAB. The back cover shows a phase plot of the Riemann zeta function (see Appendix A), which appears courtesy of Elias Wegert (www.visual.wegert.com). 2010 Mathematics Subject Classification. Primary 11-01, 11-02, 11Axx, 11Y11, 11Y16. For additional information and updates on this book, visit www.ams.org/bookpages/stml-70 Library of Congress Cataloging-in-Publication Data Rempe-Gillen, Lasse, 1978– author. [Primzahltests f¨ur Einsteiger. English] Primality testing for beginners / Lasse Rempe-Gillen, Rebecca Waldecker. pages cm. — (Student mathematical library ; volume 70) Translation of: Primzahltests f¨ur Einsteiger : Zahlentheorie - Algorithmik - Kryptographie. Includes bibliographical references and index. ISBN 978-0-8218-9883-3 (alk. paper) 1. Number theory. I. Waldecker, Rebecca, 1979– author. II. Title. QA241.R45813 2014 512.72—dc23 2013032423 Copying and reprinting. Individual readers of this publication, and nonprofit libraries acting for them, are permitted to make fair use of the material, such as to copy a chapter for use in teaching or research. Permission is granted to quote brief passages from this publication in reviews, provided the customary acknowledgment of the source is given. -

Dividing Whole Numbers
Dividing Whole Numbers INTRODUCTION Consider the following situations: 1. Edgar brought home 72 donut holes for the 9 children at his daughter’s slumber party. How many will each child receive if the donut holes are divided equally among all nine? 2. Three friends, Gloria, Jan, and Mie-Yun won a small lottery prize of $1,450. If they split it equally among all three, how much will each get? 3. Shawntee just purchased a used car. She has agreed to pay a total of $6,200 over a 36- month period. What will her monthly payments be? 4. 195 people are planning to attend an awards banquet. Ruben is in charge of the table rental. If each table seats 8, how many tables are needed so that everyone has a seat? Each of these problems can be answered using division. As you’ll recall from Section 1.2, the result of division is called the quotient. Here are the parts of a division problem: Standard form: dividend ÷ divisor = quotient Long division form: dividend Fraction form: divisor = quotient We use these words—dividend, divisor, and quotient—throughout this section, so it’s important that you become familiar with them. You’ll often see this little diagram as a continual reminder of their proper placement. Here is how a division problem is read: In the standard form: 15 ÷ 5 is read “15 divided by 5.” In the long division form: 5 15 is read “5 divided into 15.” 15 In the fraction form: 5 is read “15 divided by 5.” Dividing Whole Numbers page 1 Example 1: In this division problem, identify the dividend, divisor, and quotient. -

Advanced Synthesis Cookbook
Advanced Synthesis Cookbook Advanced Synthesis Cookbook 101 Innovation Drive San Jose, CA 95134 www.altera.com MNL-01017-6.0 Document last updated for Altera Complete Design Suite version: 11.0 Document publication date: July 2011 © 2011 Altera Corporation. All rights reserved. ALTERA, ARRIA, CYCLONE, HARDCOPY, MAX, MEGACORE, NIOS, QUARTUS and STRATIX are Reg. U.S. Pat. & Tm. Off. and/or trademarks of Altera Corporation in the U.S. and other countries. All other trademarks and service marks are the property of their respective holders as described at www.altera.com/common/legal.html. Altera warrants performance of its semiconductor products to current specifications in accordance with Altera’s standard warranty, but reserves the right to make changes to any products and services at any time without notice. Altera assumes no responsibility or liability arising out of the application or use of any information, product, or service described herein except as expressly agreed to in writing by Altera. Altera customers are advised to obtain the latest version of device specifications before relying on any published information and before placing orders for products or services. Advanced Synthesis Cookbook July 2011 Altera Corporation Contents Chapter 1. Introduction Blocks and Techniques . 1–1 Simulating the Examples . 1–1 Using a C Compiler . 1–2 Chapter 2. Arithmetic Introduction . 2–1 Basic Addition . 2–2 Ternary Addition . 2–2 Grouping Ternary Adders . 2–3 Combinational Adders . 2–3 Double Addsub/ Basic Addsub . 2–3 Two’s Complement Arithmetic Review . 2–4 Traditional ADDSUB Unit . 2–4 Compressors (Carry Save Adders) . 2–5 Compressor Width 6:3 . -

Obtaining More Karatsuba-Like Formulae Over the Binary Field
1 Obtaining More Karatsuba-Like Formulae over the Binary Field Haining Fan, Ming Gu, Jiaguang Sun and Kwok-Yan Lam Abstract The aim of this paper is to find more Karatsuba-like formulae for a fixed set of moduli polynomials in GF (2)[x]. To this end, a theoretical framework is established. We first generalize the division algorithm, and then present a generalized definition of the remainder of integer division. Finally, a previously generalized Chinese remainder theorem is used to achieve our initial goal. As a by-product of the generalized remainder of integer division, we rediscover Montgomery’s N-residue and present a systematic interpretation of definitions of Montgomery’s multiplication and addition operations. Index Terms Karatsuba algorithm, polynomial multiplication, Chinese remainder theorem, Montgomery algo- rithm, finite field. I. INTRODUCTION Efficient GF (2n) multiplication operation is important in cryptosystems. The main advantage of subquadratic multipliers is that their low asymptotic space complexities make it possible to implement VLSI multipliers for large values of n. The Karatsuba algorithm, which was invented by Karatsuba in 1960 [1], provides a practical solution for subquadratic GF (2n) multipliers [2]. Because time and space complexities of these multipliers depend on low-degree Karatsuba-like formulae, much effort has been devoted to obtain Karatsuba-like formulae with low multiplication complexity. Using the Chinese remainder theorem (CRT), Lempel, Seroussi and Winograd obtained a quasi-linear upper bound of the multiplicative complexity of multiplying Haining Fan, Ming Gu, Jiaguang Sun and Kwok-Yan Lam are with the School of Software, Tsinghua University, Beijing, China. E-mails: {fhn, guming, sunjg, lamky}@tsinghua.edu.cn 2 two polynomials over finite fields [3]. -

Cs51 Problem Set 3: Bignums and Rsa
CS51 PROBLEM SET 3: BIGNUMS AND RSA This problem set is not a partner problem set. Introduction In this assignment, you will be implementing the handling of large integers. OCaml’s int type is only 64 bits, so we need to write our own way to handle very 5 large numbers. Arbitrary size integers are traditionally referred to as “bignums”. You’ll implement several operations on bignums, including addition and multipli- cation. The challenge problem, should you choose to accept it, will be to implement part of RSA public key cryptography, the protocol that encrypts and decrypts data sent between computers, which requires bignums as the keys. 10 To create your repository in GitHub Classroom for this homework, click this link. Then, follow the GitHub Classroom instructions found here. Reminders. Compilation errors: In order to submit your work to the course grading server, your solution must compile against our test suite. The system will reject 15 submissions that do not compile. If there are problems that you are unable to solve, you must still write a function that matches the expected type signature, or your code will not compile. (When we provide stub code, that code will compile to begin with.) If you are having difficulty getting your code to compile, please visit office hours or post on Piazza. Emailing 20 your homework to your TF or the Head TFs is not a valid substitute for submitting to the course grading server. Please start early, and submit frequently, to ensure that you are able to submit before the deadline. Testing is required: As with the previous problem sets, we ask that you ex- plicitly add tests to your code in the file ps3_tests.ml. -

Quadratic Frobenius Probable Prime Tests Costing Two Selfridges
Quadratic Frobenius probable prime tests costing two selfridges Paul Underwood June 6, 2017 Abstract By an elementary observation about the computation of the difference of squares for large in- tegers, deterministic quadratic Frobenius probable prime tests are given with running times of approximately 2 selfridges. 1 Introduction Much has been written about Fermat probable prime (PRP) tests [1, 2, 3], Lucas PRP tests [4, 5], Frobenius PRP tests [6, 7, 8, 9, 10, 11, 12] and combinations of these [13, 14, 15]. These tests provide a probabilistic answer to the question: “Is this integer prime?” Although an affirmative answer is not 100% certain, it is answered fast and reliable enough for “industrial” use [16]. For speed, these various PRP tests are usually preceded by factoring methods such as sieving and trial division. The speed of the PRP tests depends on how quickly multiplication and modular reduction can be computed during exponentiation. Techniques such as Karatsuba’s algorithm [17, section 9.5.1], Toom-Cook multiplication, Fourier Transform algorithms [17, section 9.5.2] and Montgomery expo- nentiation [17, section 9.2.1] play their roles for different integer sizes. The sizes of the bases used are also critical. Oliver Atkin introduced the concept of a “Selfridge Unit” [18], approximately equal to the running time of a Fermat PRP test, which is called a selfridge in this paper. The Baillie-PSW test costs 1+3 selfridges, the use of which is very efficient when processing a candidate prime list. There is no known Baillie-PSW pseudoprime but Greene and Chen give a way to construct some similar counterexam- ples [19]. -

Modern Computer Arithmetic (Version 0.5. 1)
Modern Computer Arithmetic Richard P. Brent and Paul Zimmermann Version 0.5.1 arXiv:1004.4710v1 [cs.DS] 27 Apr 2010 Copyright c 2003-2010 Richard P. Brent and Paul Zimmermann This electronic version is distributed under the terms and conditions of the Creative Commons license “Attribution-Noncommercial-No Derivative Works 3.0”. You are free to copy, distribute and transmit this book under the following conditions: Attribution. You must attribute the work in the manner specified • by the author or licensor (but not in any way that suggests that they endorse you or your use of the work). Noncommercial. You may not use this work for commercial purposes. • No Derivative Works. You may not alter, transform, or build upon • this work. For any reuse or distribution, you must make clear to others the license terms of this work. The best way to do this is with a link to the web page below. Any of the above conditions can be waived if you get permission from the copyright holder. Nothing in this license impairs or restricts the author’s moral rights. For more information about the license, visit http://creativecommons.org/licenses/by-nc-nd/3.0/ Contents Contents iii Preface ix Acknowledgements xi Notation xiii 1 Integer Arithmetic 1 1.1 RepresentationandNotations . 1 1.2 AdditionandSubtraction . .. 2 1.3 Multiplication . 3 1.3.1 Naive Multiplication . 4 1.3.2 Karatsuba’s Algorithm . 5 1.3.3 Toom-Cook Multiplication . 7 1.3.4 UseoftheFastFourierTransform(FFT) . 8 1.3.5 Unbalanced Multiplication . 9 1.3.6 Squaring.......................... 12 1.3.7 Multiplication by a Constant . -
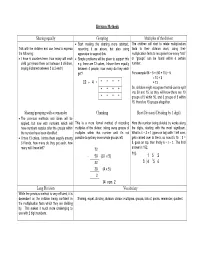
Division Methods Sharing Equally Grouping Multiples of the Divisor
Division Methods Sharing equally Grouping Multiples of the divisor • Start making the sharing more abstract, The children will start to relate multiplication Talk with the children and use items to express recording it as above, but also using facts to their division work, using their the following: apparatus to support this. multiplication facts to recognise how many “lots” • I have 6 counters here, how many will each • Simple problems will be given to support this or “groups” can be found within a certain child get (share them out between 3 children, e.g. there are 12 cakes, I share them equally number. saying 6 shared between 3 is 2 each) between 4 people, how many do they each get? For example 65 ÷ 5 = (50 + 15) ÷ 5 = 10 + 3 12 ÷ 4 = * * * * = 13 So, children might recognise that 65 can be split * * * * into 50 and 15, so they will know there are 10 * * * * groups of 5 within 50, and 3 groups of 5 within 15, therefore 13 groups altogether. Sharing/grouping with a remainder Chunking Short Division (Dividing by 1 digit) • The previous methods and ideas will be applied, but now with numbers which will This is a more formal method of recording Here the number being divided by works along have numbers surplus after the groups within multiples of the divisor, taking away groups of the digits, starting with the most significant. the number have been identified. multiples within that number until it’s not What is 4 ÷ 3 = 1 (goes on top) with 1 left over, • I have 13 cakes, I share them equally among possible to get any more whole groups left. -

Division of Whole Numbers
The Improving Mathematics Education in Schools (TIMES) Project NUMBER AND ALGEBRA Module 10 DIVISION OF WHOLE NUMBERS A guide for teachers - Years 4–7 June 2011 4YEARS 7 Polynomials (Number and Algebra: Module 10) For teachers of Primary and Secondary Mathematics 510 Cover design, Layout design and Typesetting by Claire Ho The Improving Mathematics Education in Schools (TIMES) Project 2009‑2011 was funded by the Australian Government Department of Education, Employment and Workplace Relations. The views expressed here are those of the author and do not necessarily represent the views of the Australian Government Department of Education, Employment and Workplace Relations. © The University of Melbourne on behalf of the International Centre of Excellence for Education in Mathematics (ICE‑EM), the education division of the Australian Mathematical Sciences Institute (AMSI), 2010 (except where otherwise indicated). This work is licensed under the Creative Commons Attribution‑ NonCommercial‑NoDerivs 3.0 Unported License. 2011. http://creativecommons.org/licenses/by‑nc‑nd/3.0/ The Improving Mathematics Education in Schools (TIMES) Project NUMBER AND ALGEBRA Module 10 DIVISION OF WHOLE NUMBERS A guide for teachers - Years 4–7 June 2011 Peter Brown Michael Evans David Hunt Janine McIntosh Bill Pender Jacqui Ramagge 4YEARS 7 {4} A guide for teachers DIVISION OF WHOLE NUMBERS ASSUMED KNOWLEDGE • An understanding of the Hindu‑Arabic notation and place value as applied to whole numbers (see the module Using place value to write numbers). • An understanding of, and fluency with, forwards and backwards skip‑counting. • An understanding of, and fluency with, addition, subtraction and multiplication, including the use of algorithms. -

New Arithmetic Algorithms for Hereditarily Binary Natural Numbers
1 New Arithmetic Algorithms for Hereditarily Binary Natural Numbers Paul Tarau Deptartment of Computer Science and Engineering University of North Texas [email protected] Abstract—Hereditarily binary numbers are a tree-based num- paper and discusses future work. The Appendix wraps our ber representation derived from a bijection between natural arithmetic operations as instances of Haskell’s number and numbers and iterated applications of two simple functions order classes and provides the function definitions from [1] corresponding to bijective base 2 numbers. This paper describes several new arithmetic algorithms on hereditarily binary num- referenced in this paper. bers that, while within constant factors from their traditional We have adopted a literate programming style, i.e., the counterparts for their average case behavior, make tractable code contained in the paper forms a Haskell module, avail- important computations that are impossible with traditional able at http://www.cse.unt.edu/∼tarau/research/2014/hbinx.hs. number representations. It imports code described in detail in the paper [1], from file Keywords-hereditary numbering systems, compressed number ∼ representations, arithmetic computations with giant numbers, http://www.cse.unt.edu/ tarau/research/2014/hbin.hs. A Scala compact representation of large prime numbers package implementing the same tree-based computations is available from http://code.google.com/p/giant-numbers/. We hope that this will encourage the reader to experiment inter- I. INTRODUCTION actively and validate the technical correctness of our claims. This paper is a sequel to [1]1 where we have introduced a tree based number representation, called hereditarily binary II. HEREDITARILY BINARY NUMBERS numbers.