Version 0.5.1 of 5 March 2010
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Computation of 2700 Billion Decimal Digits of Pi Using a Desktop Computer
Computation of 2700 billion decimal digits of Pi using a Desktop Computer Fabrice Bellard Feb 11, 2010 (4th revision) This article describes some of the methods used to get the world record of the computation of the digits of π digits using an inexpensive desktop computer. 1 Notations We assume that numbers are represented in base B with B = 264. A digit in base B is called a limb. M(n) is the time needed to multiply n limb numbers. We assume that M(Cn) is approximately CM(n), which means M(n) is mostly linear, which is the case when handling very large numbers with the Sch¨onhage-Strassen multiplication [5]. log(n) means the natural logarithm of n. log2(n) is log(n)/ log(2). SI and binary prefixes are used (i.e. 1 TB = 1012 bytes, 1 GiB = 230 bytes). 2 Evaluation of the Chudnovsky series 2.1 Introduction The digits of π were computed using the Chudnovsky series [10] ∞ 1 X (−1)n(6n)!(A + Bn) = 12 π (n!)3(3n)!C3n+3/2 n=0 with A = 13591409 B = 545140134 C = 640320 . It was evaluated with the binary splitting algorithm. The asymptotic running time is O(M(n) log(n)2) for a n limb result. It is worst than the asymptotic running time of the Arithmetic-Geometric Mean algorithms of O(M(n) log(n)) but it has better locality and many improvements can reduce its constant factor. Let S be defined as n2 n X Y pk S(n1, n2) = an . qk n=n1+1 k=n1+1 1 We define the auxiliary integers n Y2 P (n1, n2) = pk k=n1+1 n Y2 Q(n1, n2) = qk k=n1+1 T (n1, n2) = S(n1, n2)Q(n1, n2). -

Course Notes 1 1.1 Algorithms: Arithmetic
CS 125 Course Notes 1 Fall 2016 Welcome to CS 125, a course on algorithms and computational complexity. First, what do these terms means? An algorithm is a recipe or a well-defined procedure for performing a calculation, or in general, for transform- ing some input into a desired output. In this course we will ask a number of basic questions about algorithms: • Does the algorithm halt? • Is it correct? That is, does the algorithm’s output always satisfy the input to output specification that we desire? • Is it efficient? Efficiency could be measured in more than one way. For example, what is the running time of the algorithm? What is its memory consumption? Meanwhile, computational complexity theory focuses on classification of problems according to the com- putational resources they require (time, memory, randomness, parallelism, etc.) in various computational models. Computational complexity theory asks questions such as • Is the class of problems that can be solved time-efficiently with a deterministic algorithm exactly the same as the class that can be solved time-efficiently with a randomized algorithm? • For a given class of problems, is there a “complete” problem for the class such that solving that one problem efficiently implies solving all problems in the class efficiently? • Can every problem with a time-efficient algorithmic solution also be solved with extremely little additional memory (beyond the memory required to store the problem input)? 1.1 Algorithms: arithmetic Some algorithms very familiar to us all are those those for adding and multiplying integers. We all know the grade school algorithm for addition from kindergarten: write the two numbers on top of each other, then add digits right 1-1 1-2 1 7 8 × 2 1 3 5 3 4 1 7 8 +3 5 6 3 7 914 Figure 1.1: Grade school multiplication. -

A Scalable System-On-A-Chip Architecture for Prime Number Validation
A SCALABLE SYSTEM-ON-A-CHIP ARCHITECTURE FOR PRIME NUMBER VALIDATION Ray C.C. Cheung and Ashley Brown Department of Computing, Imperial College London, United Kingdom Abstract This paper presents a scalable SoC architecture for prime number validation which targets reconfigurable hardware This paper presents a scalable SoC architecture for prime such as FPGAs. In particular, users are allowed to se- number validation which targets reconfigurable hardware. lect predefined scalable or non-scalable modular opera- The primality test is crucial for security systems, especially tors for their designs [4]. Our main contributions in- for most public-key schemes. The Rabin-Miller Strong clude: (1) Parallel designs for Montgomery modular arith- Pseudoprime Test has been mapped into hardware, which metic operations (Section 3). (2) A scalable design method makes use of a circuit for computing Montgomery modu- for mapping the Rabin-Miller Strong Pseudoprime Test lar exponentiation to further speed up the validation and to into hardware (Section 4). (3) An architecture of RAM- reduce the hardware cost. A design generator has been de- based Radix-2 Scalable Montgomery multiplier (Section veloped to generate a variety of scalable and non-scalable 4). (4) A design generator for producing hardware prime Montgomery multipliers based on user-defined parameters. number validators based on user-specified parameters (Sec- The performance and resource usage of our designs, im- tion 5). (5) Implementation of the proposed hardware ar- plemented in Xilinx reconfigurable devices, have been ex- chitectures in FPGAs, with an evaluation of its effective- plored using the embedded PowerPC processor and the soft ness compared with different size and speed tradeoffs (Sec- MicroBlaze processor. -

Dividing Whole Numbers
Dividing Whole Numbers INTRODUCTION Consider the following situations: 1. Edgar brought home 72 donut holes for the 9 children at his daughter’s slumber party. How many will each child receive if the donut holes are divided equally among all nine? 2. Three friends, Gloria, Jan, and Mie-Yun won a small lottery prize of $1,450. If they split it equally among all three, how much will each get? 3. Shawntee just purchased a used car. She has agreed to pay a total of $6,200 over a 36- month period. What will her monthly payments be? 4. 195 people are planning to attend an awards banquet. Ruben is in charge of the table rental. If each table seats 8, how many tables are needed so that everyone has a seat? Each of these problems can be answered using division. As you’ll recall from Section 1.2, the result of division is called the quotient. Here are the parts of a division problem: Standard form: dividend ÷ divisor = quotient Long division form: dividend Fraction form: divisor = quotient We use these words—dividend, divisor, and quotient—throughout this section, so it’s important that you become familiar with them. You’ll often see this little diagram as a continual reminder of their proper placement. Here is how a division problem is read: In the standard form: 15 ÷ 5 is read “15 divided by 5.” In the long division form: 5 15 is read “5 divided into 15.” 15 In the fraction form: 5 is read “15 divided by 5.” Dividing Whole Numbers page 1 Example 1: In this division problem, identify the dividend, divisor, and quotient. -

1 Multiplication
CS 140 Class Notes 1 1 Multiplication Consider two unsigned binary numb ers X and Y . Wewanttomultiply these numb ers. The basic algorithm is similar to the one used in multiplying the numb ers on p encil and pap er. The main op erations involved are shift and add. Recall that the `p encil-and-pap er' algorithm is inecient in that each pro duct term obtained bymultiplying each bit of the multiplier to the multiplicand has to b e saved till all such pro duct terms are obtained. In machine implementations, it is desirable to add all such pro duct terms to form the partial product. Also, instead of shifting the pro duct terms to the left, the partial pro duct is shifted to the right b efore the addition takes place. In other words, if P is the partial pro duct i after i steps and if Y is the multiplicand and X is the multiplier, then P P + x Y i i j and 1 P P 2 i+1 i and the pro cess rep eats. Note that the multiplication of signed magnitude numb ers require a straight forward extension of the unsigned case. The magnitude part of the pro duct can b e computed just as in the unsigned magnitude case. The sign p of the pro duct P is computed from the signs of X and Y as 0 p x y 0 0 0 1.1 Two's complement Multiplication - Rob ertson's Algorithm Consider the case that we want to multiply two 8 bit numb ers X = x x :::x and Y = y y :::y . -

Divide-And-Conquer Algorithms
Chapter 2 Divide-and-conquer algorithms The divide-and-conquer strategy solves a problem by: 1. Breaking it into subproblems that are themselves smaller instances of the same type of problem 2. Recursively solving these subproblems 3. Appropriately combining their answers The real work is done piecemeal, in three different places: in the partitioning of problems into subproblems; at the very tail end of the recursion, when the subproblems are so small that they are solved outright; and in the gluing together of partial answers. These are held together and coordinated by the algorithm's core recursive structure. As an introductory example, we'll see how this technique yields a new algorithm for multi- plying numbers, one that is much more efficient than the method we all learned in elementary school! 2.1 Multiplication The mathematician Carl Friedrich Gauss (1777–1855) once noticed that although the product of two complex numbers (a + bi)(c + di) = ac bd + (bc + ad)i − seems to involve four real-number multiplications, it can in fact be done with just three: ac, bd, and (a + b)(c + d), since bc + ad = (a + b)(c + d) ac bd: − − In our big-O way of thinking, reducing the number of multiplications from four to three seems wasted ingenuity. But this modest improvement becomes very significant when applied recur- sively. 55 56 Algorithms Let's move away from complex numbers and see how this helps with regular multiplica- tion. Suppose x and y are two n-bit integers, and assume for convenience that n is a power of 2 (the more general case is hardly any different). -

Modern Computer Arithmetic
Modern Computer Arithmetic Richard P. Brent and Paul Zimmermann Version 0.3 Copyright c 2003-2009 Richard P. Brent and Paul Zimmermann This electronic version is distributed under the terms and conditions of the Creative Commons license “Attribution-Noncommercial-No Derivative Works 3.0”. You are free to copy, distribute and transmit this book under the following conditions: Attribution. You must attribute the work in the manner specified • by the author or licensor (but not in any way that suggests that they endorse you or your use of the work). Noncommercial. You may not use this work for commercial purposes. • No Derivative Works. You may not alter, transform, or build upon • this work. For any reuse or distribution, you must make clear to others the license terms of this work. The best way to do this is with a link to the web page below. Any of the above conditions can be waived if you get permission from the copyright holder. Nothing in this license impairs or restricts the author’s moral rights. For more information about the license, visit http://creativecommons.org/licenses/by-nc-nd/3.0/ Preface This is a book about algorithms for performing arithmetic, and their imple- mentation on modern computers. We are concerned with software more than hardware — we do not cover computer architecture or the design of computer hardware since good books are already available on these topics. Instead we focus on algorithms for efficiently performing arithmetic operations such as addition, multiplication and division, and their connections to topics such as modular arithmetic, greatest common divisors, the Fast Fourier Transform (FFT), and the computation of special functions. -

Modern Computer Arithmetic (Version 0.5. 1)
Modern Computer Arithmetic Richard P. Brent and Paul Zimmermann Version 0.5.1 arXiv:1004.4710v1 [cs.DS] 27 Apr 2010 Copyright c 2003-2010 Richard P. Brent and Paul Zimmermann This electronic version is distributed under the terms and conditions of the Creative Commons license “Attribution-Noncommercial-No Derivative Works 3.0”. You are free to copy, distribute and transmit this book under the following conditions: Attribution. You must attribute the work in the manner specified • by the author or licensor (but not in any way that suggests that they endorse you or your use of the work). Noncommercial. You may not use this work for commercial purposes. • No Derivative Works. You may not alter, transform, or build upon • this work. For any reuse or distribution, you must make clear to others the license terms of this work. The best way to do this is with a link to the web page below. Any of the above conditions can be waived if you get permission from the copyright holder. Nothing in this license impairs or restricts the author’s moral rights. For more information about the license, visit http://creativecommons.org/licenses/by-nc-nd/3.0/ Contents Contents iii Preface ix Acknowledgements xi Notation xiii 1 Integer Arithmetic 1 1.1 RepresentationandNotations . 1 1.2 AdditionandSubtraction . .. 2 1.3 Multiplication . 3 1.3.1 Naive Multiplication . 4 1.3.2 Karatsuba’s Algorithm . 5 1.3.3 Toom-Cook Multiplication . 7 1.3.4 UseoftheFastFourierTransform(FFT) . 8 1.3.5 Unbalanced Multiplication . 9 1.3.6 Squaring.......................... 12 1.3.7 Multiplication by a Constant . -

Fast Integer Multiplication Using Modular Arithmetic ∗
Fast Integer Multiplication Using Modular Arithmetic ∗ Anindya Dey Piyush P Kurur,z Computer Science Division Dept. of Computer Science and Engineering University of California at Berkeley Indian Institute of Technology Kanpur Berkeley, CA 94720, USA Kanpur, UP, India, 208016 [email protected] [email protected] Chandan Saha Ramprasad Saptharishix Dept. of Computer Science and Engineering Chennai Mathematical Institute Indian Institute of Technology Kanpur Plot H1, SIPCOT IT Park Kanpur, UP, India, 208016 Padur PO, Siruseri, India, 603103 [email protected] [email protected] Abstract ∗ We give an N · log N · 2O(log N) time algorithm to multiply two N-bit integers that uses modular arithmetic for intermediate computations instead of arithmetic over complex numbers as in F¨urer's algorithm, which also has the same and so far the best known complexity. The previous best algorithm using modular arithmetic (by Sch¨onhageand Strassen) has complexity O(N · log N · log log N). The advantage of using modular arithmetic as opposed to complex number arithmetic is that we can completely evade the task of bounding the truncation error due to finite approximations of complex numbers, which makes the analysis relatively simple. Our algorithm is based upon F¨urer'salgorithm, but uses FFT over multivariate polynomials along with an estimate of the least prime in an arithmetic progression to achieve this improvement in the modular setting. It can also be viewed as a p-adic version of F¨urer'salgorithm. 1 Introduction Computing the product of two N-bit integers is nearly a ubiquitous operation in algorithm design. -
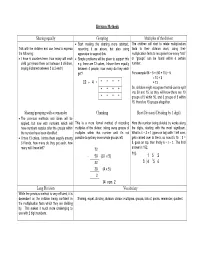
Division Methods Sharing Equally Grouping Multiples of the Divisor
Division Methods Sharing equally Grouping Multiples of the divisor • Start making the sharing more abstract, The children will start to relate multiplication Talk with the children and use items to express recording it as above, but also using facts to their division work, using their the following: apparatus to support this. multiplication facts to recognise how many “lots” • I have 6 counters here, how many will each • Simple problems will be given to support this or “groups” can be found within a certain child get (share them out between 3 children, e.g. there are 12 cakes, I share them equally number. saying 6 shared between 3 is 2 each) between 4 people, how many do they each get? For example 65 ÷ 5 = (50 + 15) ÷ 5 = 10 + 3 12 ÷ 4 = * * * * = 13 So, children might recognise that 65 can be split * * * * into 50 and 15, so they will know there are 10 * * * * groups of 5 within 50, and 3 groups of 5 within 15, therefore 13 groups altogether. Sharing/grouping with a remainder Chunking Short Division (Dividing by 1 digit) • The previous methods and ideas will be applied, but now with numbers which will This is a more formal method of recording Here the number being divided by works along have numbers surplus after the groups within multiples of the divisor, taking away groups of the digits, starting with the most significant. the number have been identified. multiples within that number until it’s not What is 4 ÷ 3 = 1 (goes on top) with 1 left over, • I have 13 cakes, I share them equally among possible to get any more whole groups left. -

Chap03: Arithmetic for Computers
CHAPTER 3 Arithmetic for Computers 3.1 Introduction 178 3.2 Addition and Subtraction 178 3.3 Multiplication 183 3.4 Division 189 3.5 Floating Point 196 3.6 Parallelism and Computer Arithmetic: Subword Parallelism 222 3.7 Real Stuff: x86 Streaming SIMD Extensions and Advanced Vector Extensions 224 3.8 Going Faster: Subword Parallelism and Matrix Multiply 225 3.9 Fallacies and Pitfalls 229 3.10 Concluding Remarks 232 3.11 Historical Perspective and Further Reading 236 3.12 Exercises 237 CMPS290 Class Notes (Chap03) Page 1 / 20 by Kuo-pao Yang 3.1 Introduction 178 Operations on integers o Addition and subtraction o Multiplication and division o Dealing with overflow Floating-point real numbers o Representation and operations x 3.2 Addition and Subtraction 178 Example: 7 + 6 Binary Addition o Figure 3.1 shows the sums and carries. The carries are shown in parentheses, with the arrows showing how they are passed. FIGURE 3.1 Binary addition, showing carries from right to left. The rightmost bit adds 1 to 0, resulting in the sum of this bit being 1 and the carry out from this bit being 0. Hence, the operation for the second digit to the right is 0 1 1 1 1. This generates a 0 for this sum bit and a carry out of 1. The third digit is the sum of 1 1 1 1 1, resulting in a carry out of 1 and a sum bit of 1. The fourth bit is 1 1 0 1 0, yielding a 1 sum and no carry. -

Division of Whole Numbers
The Improving Mathematics Education in Schools (TIMES) Project NUMBER AND ALGEBRA Module 10 DIVISION OF WHOLE NUMBERS A guide for teachers - Years 4–7 June 2011 4YEARS 7 Polynomials (Number and Algebra: Module 10) For teachers of Primary and Secondary Mathematics 510 Cover design, Layout design and Typesetting by Claire Ho The Improving Mathematics Education in Schools (TIMES) Project 2009‑2011 was funded by the Australian Government Department of Education, Employment and Workplace Relations. The views expressed here are those of the author and do not necessarily represent the views of the Australian Government Department of Education, Employment and Workplace Relations. © The University of Melbourne on behalf of the International Centre of Excellence for Education in Mathematics (ICE‑EM), the education division of the Australian Mathematical Sciences Institute (AMSI), 2010 (except where otherwise indicated). This work is licensed under the Creative Commons Attribution‑ NonCommercial‑NoDerivs 3.0 Unported License. 2011. http://creativecommons.org/licenses/by‑nc‑nd/3.0/ The Improving Mathematics Education in Schools (TIMES) Project NUMBER AND ALGEBRA Module 10 DIVISION OF WHOLE NUMBERS A guide for teachers - Years 4–7 June 2011 Peter Brown Michael Evans David Hunt Janine McIntosh Bill Pender Jacqui Ramagge 4YEARS 7 {4} A guide for teachers DIVISION OF WHOLE NUMBERS ASSUMED KNOWLEDGE • An understanding of the Hindu‑Arabic notation and place value as applied to whole numbers (see the module Using place value to write numbers). • An understanding of, and fluency with, forwards and backwards skip‑counting. • An understanding of, and fluency with, addition, subtraction and multiplication, including the use of algorithms.