Fast Division of Large Integers --- a Comparison of Algorithms
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Computation of 2700 Billion Decimal Digits of Pi Using a Desktop Computer
Computation of 2700 billion decimal digits of Pi using a Desktop Computer Fabrice Bellard Feb 11, 2010 (4th revision) This article describes some of the methods used to get the world record of the computation of the digits of π digits using an inexpensive desktop computer. 1 Notations We assume that numbers are represented in base B with B = 264. A digit in base B is called a limb. M(n) is the time needed to multiply n limb numbers. We assume that M(Cn) is approximately CM(n), which means M(n) is mostly linear, which is the case when handling very large numbers with the Sch¨onhage-Strassen multiplication [5]. log(n) means the natural logarithm of n. log2(n) is log(n)/ log(2). SI and binary prefixes are used (i.e. 1 TB = 1012 bytes, 1 GiB = 230 bytes). 2 Evaluation of the Chudnovsky series 2.1 Introduction The digits of π were computed using the Chudnovsky series [10] ∞ 1 X (−1)n(6n)!(A + Bn) = 12 π (n!)3(3n)!C3n+3/2 n=0 with A = 13591409 B = 545140134 C = 640320 . It was evaluated with the binary splitting algorithm. The asymptotic running time is O(M(n) log(n)2) for a n limb result. It is worst than the asymptotic running time of the Arithmetic-Geometric Mean algorithms of O(M(n) log(n)) but it has better locality and many improvements can reduce its constant factor. Let S be defined as n2 n X Y pk S(n1, n2) = an . qk n=n1+1 k=n1+1 1 We define the auxiliary integers n Y2 P (n1, n2) = pk k=n1+1 n Y2 Q(n1, n2) = qk k=n1+1 T (n1, n2) = S(n1, n2)Q(n1, n2). -

Course Notes 1 1.1 Algorithms: Arithmetic
CS 125 Course Notes 1 Fall 2016 Welcome to CS 125, a course on algorithms and computational complexity. First, what do these terms means? An algorithm is a recipe or a well-defined procedure for performing a calculation, or in general, for transform- ing some input into a desired output. In this course we will ask a number of basic questions about algorithms: • Does the algorithm halt? • Is it correct? That is, does the algorithm’s output always satisfy the input to output specification that we desire? • Is it efficient? Efficiency could be measured in more than one way. For example, what is the running time of the algorithm? What is its memory consumption? Meanwhile, computational complexity theory focuses on classification of problems according to the com- putational resources they require (time, memory, randomness, parallelism, etc.) in various computational models. Computational complexity theory asks questions such as • Is the class of problems that can be solved time-efficiently with a deterministic algorithm exactly the same as the class that can be solved time-efficiently with a randomized algorithm? • For a given class of problems, is there a “complete” problem for the class such that solving that one problem efficiently implies solving all problems in the class efficiently? • Can every problem with a time-efficient algorithmic solution also be solved with extremely little additional memory (beyond the memory required to store the problem input)? 1.1 Algorithms: arithmetic Some algorithms very familiar to us all are those those for adding and multiplying integers. We all know the grade school algorithm for addition from kindergarten: write the two numbers on top of each other, then add digits right 1-1 1-2 1 7 8 × 2 1 3 5 3 4 1 7 8 +3 5 6 3 7 914 Figure 1.1: Grade school multiplication. -

The Role of the Interval Domain in Modern Exact Real Airthmetic
The Role of the Interval Domain in Modern Exact Real Airthmetic Andrej Bauer Iztok Kavkler Faculty of Mathematics and Physics University of Ljubljana, Slovenia Domains VIII & Computability over Continuous Data Types Novosibirsk, September 2007 Teaching theoreticians a lesson Recently I have been told by an anonymous referee that “Theoreticians do not like to be taught lessons.” and by a friend that “You should stop competing with programmers.” In defiance of this advice, I shall talk about the lessons I learned, as a theoretician, in programming exact real arithmetic. The spectrum of real number computation slow fast Formally verified, Cauchy sequences iRRAM extracted from streams of signed digits RealLib proofs floating point Moebius transformtions continued fractions Mathematica "theoretical" "practical" I Common features: I Reals are represented by successive approximations. I Approximations may be computed to any desired accuracy. I State of the art, as far as speed is concerned: I iRRAM by Norbert Muller,¨ I RealLib by Branimir Lambov. What makes iRRAM and ReaLib fast? I Reals are represented by sequences of dyadic intervals (endpoints are rationals of the form m/2k). I The approximating sequences need not be nested chains of intervals. I No guarantee on speed of converge, but arbitrarily fast convergence is possible. I Previous approximations are not stored and not reused when the next approximation is computed. I Each next approximation roughly doubles the amount of work done. The theory behind iRRAM and RealLib I Theoretical models used to design iRRAM and RealLib: I Type Two Effectivity I a version of Real RAM machines I Type I representations I The authors explicitly reject domain theory as a suitable computational model. -

Division by Fractions 6.1.1 - 6.1.4
DIVISION BY FRACTIONS 6.1.1 - 6.1.4 Division by fractions introduces three methods to help students understand how dividing by fractions works. In general, think of division for a problem like 8..,.. 2 as, "In 8, how many groups of 2 are there?" Similarly, ½ + ¼ means, "In ½ , how many fourths are there?" For more information, see the Math Notes boxes in Lessons 7.2 .2 and 7 .2 .4 of the Core Connections, Course 1 text. For additional examples and practice, see the Core Connections, Course 1 Checkpoint 8B materials. The first two examples show how to divide fractions using a diagram. Example 1 Use the rectangular model to divide: ½ + ¼ . Step 1: Using the rectangle, we first divide it into 2 equal pieces. Each piece represents ½. Shade ½ of it. - Step 2: Then divide the original rectangle into four equal pieces. Each section represents ¼ . In the shaded section, ½ , there are 2 fourths. 2 Step 3: Write the equation. Example 2 In ¾ , how many ½ s are there? In ¾ there is one full ½ 2 2 I shaded and half of another Thatis,¾+½=? one (that is half of one half). ]_ ..,_ .l 1 .l So. 4 . 2 = 2 Start with ¾ . 3 4 (one and one-half halves) Parent Guide with Extra Practice © 2011, 2013 CPM Educational Program. All rights reserved. 49 Problems Use the rectangular model to divide. .l ...:... J_ 1 ...:... .l 1. ..,_ l 1 . 1 3 . 6 2. 3. 4. 1 4 . 2 5. 2 3 . 9 Answers l. 8 2. 2 3. 4 one thirds rm I I halves - ~I sixths fourths fourths ~I 11 ~'.¿;¡~:;¿~ ffk] 8 sixths 2 three fourths 4. -
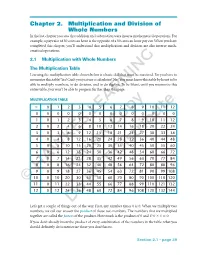
Chapter 2. Multiplication and Division of Whole Numbers in the Last Chapter You Saw That Addition and Subtraction Were Inverse Mathematical Operations
Chapter 2. Multiplication and Division of Whole Numbers In the last chapter you saw that addition and subtraction were inverse mathematical operations. For example, a pay raise of 50 cents an hour is the opposite of a 50 cents an hour pay cut. When you have completed this chapter, you’ll understand that multiplication and division are also inverse math- ematical operations. 2.1 Multiplication with Whole Numbers The Multiplication Table Learning the multiplication table shown below is a basic skill that must be mastered. Do you have to memorize this table? Yes! Can’t you just use a calculator? No! You must know this table by heart to be able to multiply numbers, to do division, and to do algebra. To be blunt, until you memorize this entire table, you won’t be able to progress further than this page. MULTIPLICATION TABLE ϫ 012 345 67 89101112 0 000 000LEARNING 00 000 00 1 012 345 67 89101112 2 024 681012Copy14 16 18 20 22 24 3 036 9121518212427303336 4 0481216 20 24 28 32 36 40 44 48 5051015202530354045505560 6061218243036424854606672Distribute 7071421283542495663707784 8081624324048566472808896 90918273HAWKESReview645546372819099108 10 0 10 20 30 40 50 60 70 80 90 100 110 120 ©11 0 11 22 33 44NOT 55 66 77 88 99 110 121 132 12 0 12 24 36 48 60 72 84 96 108 120 132 144 Do Let’s get a couple of things out of the way. First, any number times 0 is 0. When we multiply two numbers, we call our answer the product of those two numbers. -

A Scalable System-On-A-Chip Architecture for Prime Number Validation
A SCALABLE SYSTEM-ON-A-CHIP ARCHITECTURE FOR PRIME NUMBER VALIDATION Ray C.C. Cheung and Ashley Brown Department of Computing, Imperial College London, United Kingdom Abstract This paper presents a scalable SoC architecture for prime number validation which targets reconfigurable hardware This paper presents a scalable SoC architecture for prime such as FPGAs. In particular, users are allowed to se- number validation which targets reconfigurable hardware. lect predefined scalable or non-scalable modular opera- The primality test is crucial for security systems, especially tors for their designs [4]. Our main contributions in- for most public-key schemes. The Rabin-Miller Strong clude: (1) Parallel designs for Montgomery modular arith- Pseudoprime Test has been mapped into hardware, which metic operations (Section 3). (2) A scalable design method makes use of a circuit for computing Montgomery modu- for mapping the Rabin-Miller Strong Pseudoprime Test lar exponentiation to further speed up the validation and to into hardware (Section 4). (3) An architecture of RAM- reduce the hardware cost. A design generator has been de- based Radix-2 Scalable Montgomery multiplier (Section veloped to generate a variety of scalable and non-scalable 4). (4) A design generator for producing hardware prime Montgomery multipliers based on user-defined parameters. number validators based on user-specified parameters (Sec- The performance and resource usage of our designs, im- tion 5). (5) Implementation of the proposed hardware ar- plemented in Xilinx reconfigurable devices, have been ex- chitectures in FPGAs, with an evaluation of its effective- plored using the embedded PowerPC processor and the soft ness compared with different size and speed tradeoffs (Sec- MicroBlaze processor. -

The Division Algorithm We All Learned Division with Remainder At
The Division Algorithm We all learned division with remainder at elementary school. Like 14 divided by 3 has reainder 2:14 3 4 2. In general we have the following Division Algorithm. Let n be any integer and d 0 be a positive integer. Then you can divide n by d with remainder. That is n q d r,0 ≤ r d where q and r are uniquely determined. Given n we determine how often d goes evenly into n. Say, if n 16 and d 3 then 3 goes 5 times into 16 but there is a remainder 1 : 16 5 3 1. This works for non-negative numbers. If n −16 then in order to get a positive remainder, we have to go beyond −16 : −16 −63 2. Let a and b be integers. Then we say that b divides a if there is an integer c such that a b c. We write b|a for b divides a Examples: n|0 for every n :0 n 0; in particular 0|0. 1|n for every n : n 1 n Theorem. Let a,b,c be any integers. (a) If a|b, and a|cthena|b c (b) If a|b then a|b c for any c. (c) If a|b and b|c then a|c. (d) If a|b and a|c then a|m b n c for any integers m and n. Proof. For (a) we note that b a s and c a t therefore b c a s a t a s t.Thus a b c. -

Version 0.5.1 of 5 March 2010
Modern Computer Arithmetic Richard P. Brent and Paul Zimmermann Version 0.5.1 of 5 March 2010 iii Copyright c 2003-2010 Richard P. Brent and Paul Zimmermann ° This electronic version is distributed under the terms and conditions of the Creative Commons license “Attribution-Noncommercial-No Derivative Works 3.0”. You are free to copy, distribute and transmit this book under the following conditions: Attribution. You must attribute the work in the manner specified by the • author or licensor (but not in any way that suggests that they endorse you or your use of the work). Noncommercial. You may not use this work for commercial purposes. • No Derivative Works. You may not alter, transform, or build upon this • work. For any reuse or distribution, you must make clear to others the license terms of this work. The best way to do this is with a link to the web page below. Any of the above conditions can be waived if you get permission from the copyright holder. Nothing in this license impairs or restricts the author’s moral rights. For more information about the license, visit http://creativecommons.org/licenses/by-nc-nd/3.0/ Contents Preface page ix Acknowledgements xi Notation xiii 1 Integer Arithmetic 1 1.1 Representation and Notations 1 1.2 Addition and Subtraction 2 1.3 Multiplication 3 1.3.1 Naive Multiplication 4 1.3.2 Karatsuba’s Algorithm 5 1.3.3 Toom-Cook Multiplication 6 1.3.4 Use of the Fast Fourier Transform (FFT) 8 1.3.5 Unbalanced Multiplication 8 1.3.6 Squaring 11 1.3.7 Multiplication by a Constant 13 1.4 Division 14 1.4.1 Naive -

Primality Testing for Beginners
STUDENT MATHEMATICAL LIBRARY Volume 70 Primality Testing for Beginners Lasse Rempe-Gillen Rebecca Waldecker http://dx.doi.org/10.1090/stml/070 Primality Testing for Beginners STUDENT MATHEMATICAL LIBRARY Volume 70 Primality Testing for Beginners Lasse Rempe-Gillen Rebecca Waldecker American Mathematical Society Providence, Rhode Island Editorial Board Satyan L. Devadoss John Stillwell Gerald B. Folland (Chair) Serge Tabachnikov The cover illustration is a variant of the Sieve of Eratosthenes (Sec- tion 1.5), showing the integers from 1 to 2704 colored by the number of their prime factors, including repeats. The illustration was created us- ing MATLAB. The back cover shows a phase plot of the Riemann zeta function (see Appendix A), which appears courtesy of Elias Wegert (www.visual.wegert.com). 2010 Mathematics Subject Classification. Primary 11-01, 11-02, 11Axx, 11Y11, 11Y16. For additional information and updates on this book, visit www.ams.org/bookpages/stml-70 Library of Congress Cataloging-in-Publication Data Rempe-Gillen, Lasse, 1978– author. [Primzahltests f¨ur Einsteiger. English] Primality testing for beginners / Lasse Rempe-Gillen, Rebecca Waldecker. pages cm. — (Student mathematical library ; volume 70) Translation of: Primzahltests f¨ur Einsteiger : Zahlentheorie - Algorithmik - Kryptographie. Includes bibliographical references and index. ISBN 978-0-8218-9883-3 (alk. paper) 1. Number theory. I. Waldecker, Rebecca, 1979– author. II. Title. QA241.R45813 2014 512.72—dc23 2013032423 Copying and reprinting. Individual readers of this publication, and nonprofit libraries acting for them, are permitted to make fair use of the material, such as to copy a chapter for use in teaching or research. Permission is granted to quote brief passages from this publication in reviews, provided the customary acknowledgment of the source is given. -

Fast Integer Division – a Differentiated Offering from C2000 Product Family
Application Report SPRACN6–July 2019 Fast Integer Division – A Differentiated Offering From C2000™ Product Family Prasanth Viswanathan Pillai, Himanshu Chaudhary, Aravindhan Karuppiah, Alex Tessarolo ABSTRACT This application report provides an overview of the different division and modulo (remainder) functions and its associated properties. Later, the document describes how the different division functions can be implemented using the C28x ISA and intrinsics supported by the compiler. Contents 1 Introduction ................................................................................................................... 2 2 Different Division Functions ................................................................................................ 2 3 Intrinsic Support Through TI C2000 Compiler ........................................................................... 4 4 Cycle Count................................................................................................................... 6 5 Summary...................................................................................................................... 6 6 References ................................................................................................................... 6 List of Figures 1 Truncated Division Function................................................................................................ 2 2 Floored Division Function................................................................................................... 3 3 Euclidean -

Multiplication and Divisions
Third Grade Math nd 2 Grading Period Power Objectives: Academic Vocabulary: multiplication array Represent and solve problems involving multiplication and divisor commutative division. (P.O. #1) property Understand properties of multiplication and the distributive property relationship between multiplication and divisions. estimation division factor column (P.O. #2) Multiply and divide with 100. (P.O. #3) repeated addition multiple Solve problems involving the four operations, and identify associative property quotient and explain the patterns in arithmetic. (P.O. #4) rounding row product equation Multiplication and Division Enduring Understandings: Essential Questions: Mathematical operations are used in solving problems In what ways can operations affect numbers? in which a new value is produced from one or more How can different strategies be helpful when solving a values. problem? Algebraic thinking involves choosing, combining, and How does knowing and using algorithms help us to be applying effective strategies for answering questions. Numbers enable us to use the four operations to efficient problem solvers? combine and separate quantities. How are multiplication and addition alike? See below for additional enduring understandings. How are subtraction and division related? See below for additional essential questions. Enduring Understandings: Multiplication is repeated addition, related to division, and can be used to solve story problems. For a given set of numbers, there are relationships that -

AUTHOR Multiplication and Division. Mathematics-Methods
DOCUMENT RESUME ED 221 338 SE 035 008, AUTHOR ,LeBlanc, John F.; And Others TITLE Multiplication and Division. Mathematics-Methods 12rogram Unipt. INSTITUTION Indiana ,Univ., Bloomington. Mathematics Education !Development Center. , SPONS AGENCY ,National Science Foundation, Washington, D.C. REPORT NO :ISBN-0-201-14610-x PUB DATE 76 . GRANT. NSF-GY-9293 i 153p.; For related documents, see SE 035 006-018. NOTE . ,. EDRS PRICE 'MF01 Plus Postage. PC Not Available from EDRS. DESCRIPTORS iAlgorithms; College Mathematics; *Division; Elementary Education; *Elementary School Mathematics; 'Elementary School Teachers; Higher Education; 'Instructional1 Materials; Learning Activities; :*Mathematics Instruction; *Multiplication; *Preservice Teacher Education; Problem Solving; :Supplementary Reading Materials; Textbooks; ;Undergraduate Study; Workbooks IDENTIFIERS i*Mathematics Methods Program ABSTRACT This unit is 1 of 12 developed for the university classroom portign_of the Mathematics-Methods Program(MMP), created by the Indiana pniversity Mathematics EducationDevelopment Center (MEDC) as an innovative program for the mathematics training of prospective elenientary school teachers (PSTs). Each unit iswritten in an activity format that involves the PST in doing mathematicswith an eye towardaiplication of that mathematics in the elementary school. This do ument is one of four units that are devoted tothe basic number wo k in the elementary school. In addition to an introduction to the unit, the text has sections on the conceptual development of nultiplication