Transcription-Factor Polymorphism Associated with Tissue-Specific Gene
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Functionally Diverse Dendritic Mrnas Rapidly Associate with Ribosomes Following a Novel Experience
ARTICLE Received 19 Feb 2014 | Accepted 24 Jun 2014 | Published 29 Jul 2014 DOI: 10.1038/ncomms5510 Functionally diverse dendritic mRNAs rapidly associate with ribosomes following a novel experience Joshua A. Ainsley1, Laurel Drane1, Jonathan Jacobs1, Kara A. Kittelberger1,w & Leon G. Reijmers1 The subcellular localization and translation of messenger RNA (mRNA) supports functional differentiation between cellular compartments. In neuronal dendrites, local translation of mRNA provides a rapid and specific mechanism for synaptic plasticity and memory forma- tion, and might be involved in the pathophysiology of certain brain disorders. Despite the importance of dendritic mRNA translation, little is known about which mRNAs can be translated in dendrites in vivo and when their translation occurs. Here we collect ribosome- bound mRNA from the dendrites of CA1 pyramidal neurons in the adult mouse hippocampus. We find that dendritic mRNA rapidly associates with ribosomes following a novel experience consisting of a contextual fear conditioning trial. High throughput RNA sequencing followed by machine learning classification reveals an unexpected breadth of ribosome-bound den- dritic mRNAs, including mRNAs expected to be entirely somatic. Our findings are in agree- ment with a mechanism of synaptic plasticity that engages the acute local translation of functionally diverse dendritic mRNAs. 1 Department of Neuroscience, Tufts University, Boston, Massachusetts 02111, USA. w Present address: Center for Translational Social Neuroscience, Yerkes National Primate Research Center, Emory University, Atlanta, Georgia 30322, USA. Correspondence and requests for materials should be addressed to L.R. (email: [email protected]). NATURE COMMUNICATIONS | 5:4510 | DOI: 10.1038/ncomms5510 | www.nature.com/naturecommunications 1 & 2014 Macmillan Publishers Limited. -

Histone-Related Genes Are Hypermethylated in Lung Cancer
Published OnlineFirst October 1, 2019; DOI: 10.1158/0008-5472.CAN-19-1019 Cancer Genome and Epigenome Research Histone-Related Genes Are Hypermethylated in Lung Cancer and Hypermethylated HIST1H4F Could Serve as a Pan-Cancer Biomarker Shihua Dong1,Wei Li1, Lin Wang2, Jie Hu3,Yuanlin Song3, Baolong Zhang1, Xiaoguang Ren1, Shimeng Ji3, Jin Li1, Peng Xu1, Ying Liang1, Gang Chen4, Jia-Tao Lou2, and Wenqiang Yu1 Abstract Lung cancer is the leading cause of cancer-related deaths lated in all 17 tumor types from TCGA datasets (n ¼ 7,344), worldwide. Cytologic examination is the current "gold stan- which was further validated in nine different types of cancer dard" for lung cancer diagnosis, however, this has low sensi- (n ¼ 243). These results demonstrate that HIST1H4F can tivity. Here, we identified a typical methylation signature of function as a universal-cancer-only methylation (UCOM) histone genes in lung cancer by whole-genome DNA methyl- marker, which may aid in understanding general tumorigen- ation analysis, which was validated by The Cancer Genome esis and improve screening for early cancer diagnosis. Atlas (TCGA) lung cancer cohort (n ¼ 907) and was further confirmed in 265 bronchoalveolar lavage fluid samples with Significance: These findings identify a new biomarker for specificity and sensitivity of 96.7% and 87.0%, respectively. cancer detection and show that hypermethylation of histone- More importantly, HIST1H4F was universally hypermethy- related genes seems to persist across cancers. Introduction to its low specificity, LDCT is far from satisfactory as a screening tool for clinical application, similar to other currently used cancer Lung cancer is one of the most common malignant tumors and biomarkers, such as carcinoembryonic antigen (CEA), neuron- the leading cause of cancer-related deaths worldwide (1, 2). -

Functional Annotation of Human Long Noncoding Rnas Using Chromatin
bioRxiv preprint doi: https://doi.org/10.1101/2021.01.13.426305; this version posted January 14, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Funconal annotaon of human long noncoding RNAs using chroman conformaon data Saumya Agrawal1, Tanvir Alam2, Masaru Koido1,3, Ivan V. Kulakovskiy4,5, Jessica Severin1, Imad ABugessaisa1, Andrey Buyan5,6, Josee Dos&e7, Masayoshi Itoh1,8, Naoto Kondo9, Yunjing Li10, Mickaël Mendez11, Jordan A. Ramilowski1,12, Ken Yagi1, Kayoko Yasuzawa1, CHi Wai Yip1, Yasushi Okazaki1, MicHael M. Ho9man11,13,14,15, Lisa Strug10, CHung CHau Hon1, CHikashi Terao1, Takeya Kasukawa1, Vsevolod J. Makeev4,16, Jay W. SHin1, Piero Carninci1, MicHiel JL de Hoon1 1RIKEN Center for Integra&ve Medical Sciences, YokoHama, Japan. 2College of Science and Engineering, Hamad Bin KHalifa University, DoHa, Qatar. 3Ins&tute of Medical Science, THe University of Tokyo, Tokyo, Japan. 4Vavilov Ins&tute of General Gene&cs, Russian Academy of Sciences, Moscow, Russia. 5Ins&tute of Protein ResearcH, Russian Academy of Sciences, PusHcHino, Russia. 6Faculty of Bioengineering and Bioinforma&cs, Lomonosov Moscow State University, Moscow, Russia. 7Department of BiocHemistry, Rosalind and Morris Goodman Cancer ResearcH Center, McGill University, Montréal, QuéBec, Canada. 8RIKEN Preven&ve Medicine and Diagnosis Innova&on Program, Wako, Japan. 9RIKEN Center for Life Science TecHnologies, YokoHama, Japan. 10Division of Biosta&s&cs, Dalla Lana ScHool of PuBlic HealtH, University of Toronto, Toronto, Ontario, Canada. 11Department of Computer Science, University of Toronto, Toronto, Ontario, Canada. 12Advanced Medical ResearcH Center, YokoHama City University, YokoHama, Japan. -

2020 UTGCP Research Newsletter
O C T O B E R 2 0 2 0 | I S S U E N O . 2 UTGCP ANNUAL RESEARCH NEWSLETTER Celebrating Excellence in Genetic Counseling Research shout-out to our students completing their M.S. research during a pandemic what's inside: Hyperlinks to the complete abstracts and conferences are Research from our students included when available. (classes of 2020 & 2021) Please consider supporting our Research submitted by alumni students' research efforts & faculty (Jan-Dec 2019) through the UTGCP Research & Education Fund at launch.uth.edu/utgcp O C T O B E R 2 0 2 0 | I S S U E N O . 2 CONGRATS CLASS OF 2020! Thesis defense looked a little different this year... Sarah Burke - “Understanding genetic counselors' approaches to direct-to- consumer testing for hereditary Emily Stiglich - “Genetic counselors' experiences with breast cancer" and approaches to discordant genotypic and phenotypic Advisor: Maureen sex" Mork, MS, CGC Advisor: Victoria Wagner, MS, CGC Wendi Betting - “Factors that impact uptake of carrier screening by male Autumn Vara - reproductive partners of female “Frequency of prenatal patients" copy number variants involving Advisor: Meagan Choates, MS, CGC the sex chromosomes in a clinical setting" Advisor: David F. Rodriguez- Buritica, MD Addison Johnson - “Assessing patient attitudes toward genetic testing for hereditary hematologic malignancies" Advisor: Sarah Bannon, MS, CGC Aranza Gonzalez- Caroline Bertsch - “The course Cendejas - of acute stress disorder and “Implementation of post traumatic stress disorder genetic carrier in patients and infants in the screening in the OB population: healthcare neonatal intensive care unit cost impact and Bradley Power - “Investigating medical with or without genetic recommendation examiner's practices: genetic evaluation for anomalies" adherence" fatal acute aortic dissection" Advisor: Jennifer Czerwinski, Advisor: Rebecca Carter, MS, CGC Advisor: Krista Qualmann, MS, CGC MS, CGC O C T O B E R 2 0 2 0 | I S S U E N O . -

University of California, San Diego
UC San Diego UC San Diego Electronic Theses and Dissertations Title The post-terminal differentiation fate of RNAs revealed by next-generation sequencing Permalink https://escholarship.org/uc/item/7324r1rj Author Lefkowitz, Gloria Kuo Publication Date 2012 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA, SAN DIEGO The post-terminal differentiation fate of RNAs revealed by next-generation sequencing A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Biomedical Sciences by Gloria Kuo Lefkowitz Committee in Charge: Professor Benjamin D. Yu, Chair Professor Richard Gallo Professor Bruce A. Hamilton Professor Miles F. Wilkinson Professor Eugene Yeo 2012 Copyright Gloria Kuo Lefkowitz, 2012 All rights reserved. The Dissertation of Gloria Kuo Lefkowitz is approved, and it is acceptable in quality and form for publication on microfilm and electronically: __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ Chair University of California, San Diego 2012 iii DEDICATION Ma and Ba, for your early indulgence and support. Matt and James, for choosing more practical callings. Roy, my love, for patiently sharing the ups and downs -

A Multiprotein Occupancy Map of the Mrnp on the 3 End of Histone
Downloaded from rnajournal.cshlp.org on October 6, 2021 - Published by Cold Spring Harbor Laboratory Press A multiprotein occupancy map of the mRNP on the 3′ end of histone mRNAs LIONEL BROOKS III,1 SHAWN M. LYONS,2 J. MATTHEW MAHONEY,1 JOSHUA D. WELCH,3 ZHONGLE LIU,1 WILLIAM F. MARZLUFF,2 and MICHAEL L. WHITFIELD1 1Department of Genetics, Dartmouth Geisel School of Medicine, Hanover, New Hampshire 03755, USA 2Integrative Program for Biological and Genome Sciences, University of North Carolina, Chapel Hill, North Carolina 27599, USA 3Department of Computer Science, University of North Carolina, Chapel Hill, North Carolina 27599, USA ABSTRACT The animal replication-dependent (RD) histone mRNAs are coordinately regulated with chromosome replication. The RD-histone mRNAs are the only known cellular mRNAs that are not polyadenylated. Instead, the mature transcripts end in a conserved stem– loop (SL) structure. This SL structure interacts with the stem–loop binding protein (SLBP), which is involved in all aspects of RD- histone mRNA metabolism. We used several genomic methods, including high-throughput sequencing of cross-linked immunoprecipitate (HITS-CLIP) to analyze the RNA-binding landscape of SLBP. SLBP was not bound to any RNAs other than histone mRNAs. We performed bioinformatic analyses of the HITS-CLIP data that included (i) clustering genes by sequencing read coverage using CVCA, (ii) mapping the bound RNA fragment termini, and (iii) mapping cross-linking induced mutation sites (CIMS) using CLIP-PyL software. These analyses allowed us to identify specific sites of molecular contact between SLBP and its RD-histone mRNA ligands. We performed in vitro crosslinking assays to refine the CIMS mapping and found that uracils one and three in the loop of the histone mRNA SL preferentially crosslink to SLBP, whereas uracil two in the loop preferentially crosslinks to a separate component, likely the 3′hExo. -

Acetyl-Histone H4-K12 Pab Cat
Acetyl-Histone H4-K12 pAb Cat. No.: 15-437 Acetyl-Histone H4-K12 pAb Immunohistochemistry of paraffin- embedded rat ovary using Acetyl-Histone Immunohistochemistry of paraffin-embedded mouse testis using H4-K12 antibody (15-437) at dilution of 1:200 Acetyl-Histone H4-K12 antibody (15-437) at dilution of 1:200 (40x lens). (40x lens). Immunohistochemistry of paraffin- Immunofluorescence analysis of C6 cells using Acetyl-Histone H4-K12 embedded mouse spinal cord using Acetyl- antibody (15-437) at dilution of 1:100.C6 cells were treated by TSA (1 Histone H4-K12 antibody (15-437) at dilution uM) at 37? for 18 hours. Blue: DAPI for nuclear staining. of 1:200 (40x lens). September 27, 2021 1 https://www.prosci-inc.com/acetyl-histone-h4-k12-pab-15-437.html Immunofluorescence analysis of NIH/3T3 cells using Acetyl-Histone H4-K12 antibody (15-437) at dilution of 1:100.NIH/3T3 cells were treated by TSA (1 uM) at 37? for 18 hours. Blue: DAPI for nuclear staining. Specifications HOST SPECIES: Rabbit SPECIES REACTIVITY: Human, Mouse IMMUNOGEN: A synthetic acetylated peptide around K12 of human Histone H4 (NP_001029249.1). TESTED APPLICATIONS: IF, IHC, WB WB: ,1:500 - 1:2000 APPLICATIONS: IHC: ,1:50 - 1:200 IF: ,1:50 - 1:200 Properties PURIFICATION: Affinity purification CLONALITY: Polyclonal ISOTYPE: IgG CONJUGATE: Unconjugated PHYSICAL STATE: Liquid BUFFER: PBS with 0.02% sodium azide, 50% glycerol, pH7.3. STORAGE CONDITIONS: Store at -20˚C. Avoid freeze / thaw cycles. Additional Info OFFICIAL SYMBOL: H4K12ac September 27, 2021 2 https://www.prosci-inc.com/acetyl-histone-h4-k12-pab-15-437.html H4/A, H4FA, HIST1H4B, H4/I, H4FI, HIST1H4C, H4/G, H4FG, HIST1H4D, H4/B, H4FB, HIST1H4E, H4/J, H4FJ, HIST1H4F, H4/C, H4FC, HIST1H4H, H4/H, H4FH, HIST1H4I, H4/M, ALTERNATE NAMES: H4FM, HIST1H4J, H4/E, H4FE, HIST1H4K, H4/D, H4FD, HIST1H4L, H4/K, H4FK, HIST2H4A, H4/N, H4F2, H4FN, HIST2H4, HIST2H4B, H4/O, H4FO, HIST4H4, Histone H4H4FA GENE ID: 8366 USER NOTE: Optimal dilutions for each application to be determined by the researcher. -

Supplemental Data.Pdf
Supplementary material -Table of content Supplementary Figures (Fig 1- Fig 6) Supplementary Tables (1-13) Lists of genes belonging to distinct biological processes identified by GREAT analyses to be significantly enriched with UBTF1/2-bound genes Supplementary Table 14 List of the common UBTF1/2 bound genes within +/- 2kb of their TSSs in NIH3T3 and HMECs. Supplementary Table 15 List of gene identified by microarray expression analysis to be differentially regulated following UBTF1/2 knockdown by siRNA Supplementary Table 16 List of UBTF1/2 binding regions overlapping with histone genes in NIH3T3 cells Supplementary Table 17 List of UBTF1/2 binding regions overlapping with histone genes in HMEC Supplementary Table 18 Sequences of short interfering RNA oligonucleotides Supplementary Table 19 qPCR primer sequences for qChIP experiments Supplementary Table 20 qPCR primer sequences for reverse transcription-qPCR Supplementary Table 21 Sequences of primers used in CHART-PCR Supplementary Methods Supplementary Fig 1. (A) ChIP-seq analysis of UBTF1/2 and Pol I (POLR1A) binding across mouse rDNA. UBTF1/2 is enriched at the enhancer and promoter regions and along the entire transcribed portions of rDNA with little if any enrichment in the intergenic spacer (IGS), which separates the rDNA repeats. This enrichment coincides with the distribution of the largest subunit of Pol I (POLR1A) across the rDNA. All sequencing reads were mapped to the published complete sequence of the mouse rDNA repeat (Gene bank accession number: BK000964). The graph represents the frequency of ribosomal sequences enriched in UBTF1/2 and Pol I-ChIPed DNA expressed as fold change over those of input genomic DNA. -

MAFB Determines Human Macrophage Anti-Inflammatory
MAFB Determines Human Macrophage Anti-Inflammatory Polarization: Relevance for the Pathogenic Mechanisms Operating in Multicentric Carpotarsal Osteolysis This information is current as of October 4, 2021. Víctor D. Cuevas, Laura Anta, Rafael Samaniego, Emmanuel Orta-Zavalza, Juan Vladimir de la Rosa, Geneviève Baujat, Ángeles Domínguez-Soto, Paloma Sánchez-Mateos, María M. Escribese, Antonio Castrillo, Valérie Cormier-Daire, Miguel A. Vega and Ángel L. Corbí Downloaded from J Immunol 2017; 198:2070-2081; Prepublished online 16 January 2017; doi: 10.4049/jimmunol.1601667 http://www.jimmunol.org/content/198/5/2070 http://www.jimmunol.org/ Supplementary http://www.jimmunol.org/content/suppl/2017/01/15/jimmunol.160166 Material 7.DCSupplemental References This article cites 69 articles, 22 of which you can access for free at: http://www.jimmunol.org/content/198/5/2070.full#ref-list-1 by guest on October 4, 2021 Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2017 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. -

Whole-Genome Sequencing Identifies New Genetic Alterations in Meningiomas
www.impactjournals.com/oncotarget/ Oncotarget, 2017, Vol. 8, (No. 10), pp: 17070-17080 Research Paper Whole-genome sequencing identifies new genetic alterations in meningiomas Mei Tang1,*, Heng Wei2,*, Lu Han1,*, Jiaojiao Deng3, Yuelong Wang3, Meijia Yang1, Yani Tang1, Gang Guo1, Liangxue Zhou3, Aiping Tong1 1The State Key Laboratory of Biotherapy and Cancer Center/Collaborative Innovation Center of Biotherapy, West China Hospital, West China Medical School, Sichuan University, Chengdu 610041, China 2College of Life Science, Sichuan University, Chengdu 610064, China 3Department of Neurosurgery, West China Hospital, West China Medical School, Sichuan University, Chengdu 610041, China *These authors have contributed equally to the work Correspondence to: Aiping Tong, email: [email protected] Liangxue Zhou, email: [email protected] Keywords: whole-genome sequencing, meningioma, chromosome instability, copy number alteration, mutation Received: October 24, 2016 Accepted: January 13, 2017 Published: February 03, 2017 ABSTRACT The major known genetic contributor to meningioma formation was NF2, which is disrupted by mutation or loss in about 50% of tumors. Besides NF2, several recurrent driver mutations were recently uncovered through next-generation sequencing. Here, we performed whole-genome sequencing across 7 tumor-normal pairs to identify somatic genetic alterations in meningioma. As a result, Chromatin regulators, including multiple histone members, histone-modifying enzymes and several epigenetic regulators, are the major category among all of the identified copy number variants and single nucleotide variants. Notably, all samples contained copy number variants in histone members. Recurrent chromosomal rearrangements were detected on chromosome 22q, 6p21-p22 and 1q21, and most of the histone copy number variants occurred in these regions. -

The Pdx1 Bound Swi/Snf Chromatin Remodeling Complex Regulates Pancreatic Progenitor Cell Proliferation and Mature Islet Β Cell
Page 1 of 125 Diabetes The Pdx1 bound Swi/Snf chromatin remodeling complex regulates pancreatic progenitor cell proliferation and mature islet β cell function Jason M. Spaeth1,2, Jin-Hua Liu1, Daniel Peters3, Min Guo1, Anna B. Osipovich1, Fardin Mohammadi3, Nilotpal Roy4, Anil Bhushan4, Mark A. Magnuson1, Matthias Hebrok4, Christopher V. E. Wright3, Roland Stein1,5 1 Department of Molecular Physiology and Biophysics, Vanderbilt University, Nashville, TN 2 Present address: Department of Pediatrics, Indiana University School of Medicine, Indianapolis, IN 3 Department of Cell and Developmental Biology, Vanderbilt University, Nashville, TN 4 Diabetes Center, Department of Medicine, UCSF, San Francisco, California 5 Corresponding author: [email protected]; (615)322-7026 1 Diabetes Publish Ahead of Print, published online June 14, 2019 Diabetes Page 2 of 125 Abstract Transcription factors positively and/or negatively impact gene expression by recruiting coregulatory factors, which interact through protein-protein binding. Here we demonstrate that mouse pancreas size and islet β cell function are controlled by the ATP-dependent Swi/Snf chromatin remodeling coregulatory complex that physically associates with Pdx1, a diabetes- linked transcription factor essential to pancreatic morphogenesis and adult islet-cell function and maintenance. Early embryonic deletion of just the Swi/Snf Brg1 ATPase subunit reduced multipotent pancreatic progenitor cell proliferation and resulted in pancreas hypoplasia. In contrast, removal of both Swi/Snf ATPase subunits, Brg1 and Brm, was necessary to compromise adult islet β cell activity, which included whole animal glucose intolerance, hyperglycemia and impaired insulin secretion. Notably, lineage-tracing analysis revealed Swi/Snf-deficient β cells lost the ability to produce the mRNAs for insulin and other key metabolic genes without effecting the expression of many essential islet-enriched transcription factors. -
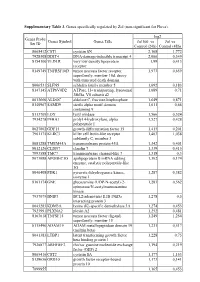
Supplementary Table 3. Genes Specifically Regulated by Zol (Non-Significant for Fluva)
Supplementary Table 3. Genes specifically regulated by Zol (non-significant for Fluva). log2 Genes Probe Genes Symbol Genes Title Zol100 vs Zol vs Set ID Control (24h) Control (48h) 8065412 CST1 cystatin SN 2,168 1,772 7928308 DDIT4 DNA-damage-inducible transcript 4 2,066 0,349 8154100 VLDLR very low density lipoprotein 1,99 0,413 receptor 8149749 TNFRSF10D tumor necrosis factor receptor 1,973 0,659 superfamily, member 10d, decoy with truncated death domain 8006531 SLFN5 schlafen family member 5 1,692 0,183 8147145 ATP6V0D2 ATPase, H+ transporting, lysosomal 1,689 0,71 38kDa, V0 subunit d2 8013660 ALDOC aldolase C, fructose-bisphosphate 1,649 0,871 8140967 SAMD9 sterile alpha motif domain 1,611 0,66 containing 9 8113709 LOX lysyl oxidase 1,566 0,524 7934278 P4HA1 prolyl 4-hydroxylase, alpha 1,527 0,428 polypeptide I 8027002 GDF15 growth differentiation factor 15 1,415 0,201 7961175 KLRC3 killer cell lectin-like receptor 1,403 1,038 subfamily C, member 3 8081288 TMEM45A transmembrane protein 45A 1,342 0,401 8012126 CLDN7 claudin 7 1,339 0,415 7993588 TMC7 transmembrane channel-like 7 1,318 0,3 8073088 APOBEC3G apolipoprotein B mRNA editing 1,302 0,174 enzyme, catalytic polypeptide-like 3G 8046408 PDK1 pyruvate dehydrogenase kinase, 1,287 0,382 isozyme 1 8161174 GNE glucosamine (UDP-N-acetyl)-2- 1,283 0,562 epimerase/N-acetylmannosamine kinase 7937079 BNIP3 BCL2/adenovirus E1B 19kDa 1,278 0,5 interacting protein 3 8043283 KDM3A lysine (K)-specific demethylase 3A 1,274 0,453 7923991 PLXNA2 plexin A2 1,252 0,481 8163618 TNFSF15 tumor necrosis