Colocated with ACM Recsys 2011 Chicago, IL, USA October 23, 2011 Copyright C
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Islam, Law, and the State
POLITICAL ISLAM PRESENT AND PAST 508:110 Spring 2018 Monday & Wednesday 2:50pm - 4:10pm Hardenbergh Hall A7 Instructor: Julia Stephens ([email protected]) Office Hours: TBA This course is an introduction to Islamic political thought and practice, which focuses on how history can inform our understanding of contemporary Political Islam. Since the attack on the Twin Towers on September 11, 2001, political debates about the role of Islam in the modern world have arguably been the single defining issue of the twenty-first century. The manifestations of Political Islam are diverse: they range from al-Qaeda and ISIS, to Muslim political parties who participate in electoral politics in Turkey and Indonesia. Nor is Political Islam limited to Muslim- majority countries. Debates about Islam have also emerged as key political questions in the United States and Europe, influencing policies in areas ranging from surveillance to immigration and education. The course traces the longer history of a range of flashpoints in these debates, including the relationship between sharia and the state, the role of new media technologies in shaping Muslim politics, veiling, and censorship of religiously offensive materials. In the process the course surveys the life of the Prophet, the early Caliphates, early-modern Muslim empires, European colonialism, and nationalist movements. But a focus on themes of contemporary relevance provides the guiding thread through this whirl-wind tour of Islamic history. The course assumes no prior knowledge of the subject. Lectures and discussions will guide students through the analysis of a variety of historical and contemporary sources, including Ottoman fatwas on drinking coffee, nineteenth-century debates about the compatibility of Islam and modern science, Sufi rock videos, and Twitter feeds. -

Fizzy Drinks and Sufi Music: Abida Parveen in Coke Studio Pakistan
Fizzy Drinks and Sufi Music: Abida Parveen in Coke Studio Pakistan By Zainub Beg A Thesis Submitted to Saint Mary’s University, K’jipuktuk/Halifax, Nova Scotia in Partial Fulfillment of the Requirements for the Degree of Master of Arts in Theology and Religious Studies. December 2020, Halifax, Nova Scotia Copyright Zainub Beg, 2020 Approved: Dr. Syed Adnan Hussain Supervisor Approved: Dr. Reem Meshal Examiner Approved: Dr. Sailaja Krishnamurti Reader Date: December 21, 2020 1 Fizzy Drinks and Sufi Music: Abida Parveen in Coke Studio Pakistan by Zainub Beg Abstract Abida Parveen, often referred to as the Queen of Sufi music, is one of the only female qawwals in a male-dominated genre. This thesis will explore her performances for Coke Studio Pakistan through the lens of gender theory. I seek to examine Parveen’s blurring of gender, Sufism’s disruptive nature, and how Coke Studio plays into the two. I think through the categories of Islam, Sufism, Pakistan, and their relationship to each other to lead into my analysis on Parveen’s disruption in each category. I argue that Parveen holds a unique position in Pakistan and Sufism that cannot be explained in binary terms. December 21, 2020 2 Table of Contents Abstract ................................................................................................................... 1 Acknowledgements ................................................................................................ 3 Chapter One: Introduction .................................................................................. -

Psaudio Copper
Issue 128 JANUARY 11TH, 2021 Things change with time, as my very close friend likes to say. Here’s my New Year’s wish: that things change for the better in 2021. A new year brings new possibilities. We’re saddened by the loss of Gerry Marsden (78) of British Invasion legends Gerry and the Pacemakers. Their first single, “How Do You Do It,” hit number one on the British charts in 1963 – before the Beatles ever accomplished that feat – and they went on to have other smash records like “Don’t Let the Sun Catch You Crying,” You’ll Never Walk Alone,” “I Like It” and “Ferry Cross the Mersey.” These songs are woven not just into the fabric of the 1960s, but our lives. In this issue: Anne E. Johnson covers the career of John Legend and rediscovers 17th century composer Marc-Antoine Charpentier. Larry Schenbeck gets soul and takes on “what if?” Ken Sander goes Stateside with The Stranglers. J.I. Agnew locks in his lockdown music system. Tom Gibbs looks at new releases from Kraftwerk, Julia Stone and Max Richter. Adrian Wu continues his series on testing in audio. John Seetoo mines a mind-boggling mic collection. Jay Jay French remembers Mountain’s Leslie West. Dan Schwartz contemplates his streaming royalties. Steven Bryan Bieler ponders the new year. Ray Chelstowski notes that January’s a slow month for concerts – with a few monumental exceptions. Stuart Marvin examines how musicians and their audiences are adapting to the pandemic. I reminisce about hanging out with Les Paul. We round out the issue with single-minded listening, the world’s coolest multi-room audio system, mixed media, and a girl on a mission. -

States of Affect: Trauma in Partition/Post-Partition South Asia
STATES OF AFFECT: TRAUMA IN PARTITION/POST-PARTITION SOUTH ASIA By Rituparna Mitra A DISSERTATION Submitted to Michigan State University in partial fulfillment of the requirements for the degree of English – Doctor of Philosophy 2015 ABSTRACT STATES OF AFFECT: TRAUMA IN PARTITION/POST-PARTITION SOUTH ASIA By Rituparna Mitra The Partition of the Indian subcontinent – into India and Pakistan in 1947 – was one of the crucial moments marking the break between the colonial and postcolonial era. My project is invested in exploring the Partition not merely in terms of the events of August 1947, but as an ongoing process that continues to splinter political, cultural, emotional and sexual life-worlds in South Asia. My dissertation seeks to map analytical pathways to locate the Partition and the attendant formations of minoritization and sectarian violence as continuing, unfolding processes that constitute postcolonial nation-building. It examines the far-reaching presence of these formations in current configurations of politics, culture and subjectivity by mobilizing the interdisciplinary scope of affect-mediated Trauma and Memory Studies and Postcolonial Studies, in conjunction with literary analysis. My project draws on a wide range of cultural artifacts such as poetry, cantillatory performance, mourning rituals, testimonials, archaeological ruins, short stories and novels to develop a heuristic and affective re-organization of post-Partition South Asia. It seeks to illuminate through frameworks of memory, melancholia, trauma, affect and postcoloniality how the ongoing effects of the past shape the present, which in turn, offers us ways to reimagine the future. This dissertation reaches out to recent work developing a vernacular framework to analyze violence, trauma and loss in South Asia. -

Towards Semantic Music Information Extraction from the Web Using Rule Patterns and Supervised Learning
Towards Semantic Music Information Extraction from the Web Using Rule Patterns and Supervised Learning Peter Knees and Markus Schedl Department of Computational Perception, Johannes Kepler University, Linz, Austria [email protected], [email protected] ABSTRACT potential relations between two entities is large. Such re- We present first steps towards automatic Music Information lations comprise, e.g., cover versions of songs, live versions, Extraction, i.e., methods to automatically extract seman- re-recordings, remixes, or mash-ups. Semantic high-level tic information and relations about musical entities from concepts such as \song X was inspired by artist A" or \band arbitrary textual sources. The corresponding approaches al- B is the new band of artist A" are very prominent in many low us to derive structured meta-data from unstructured or users' conception and perception of music and should there- semi-structured sources and can be used to build advanced fore be given attention in similarity estimation approaches. recommendation systems and browsing interfaces. In this By focusing solely on acoustic properties, such relations are paper, several approaches to identify and extract two spe- hard to detect (as can be seen, e.g., from research on cover cific semantic relations from related Web documents are pre- version detection [7]). sented and evaluated. The addressed relations are members A promising approach to deal with the limitations of signal- of a music band (band−members) and artists' discographies based methods is to exploit contextual information (for an (artist − albums; EP s; singles). In addition, the proposed overview see, e.g., [16]). Recent work in music information methods are shown to be useful to relate (Web-)documents retrieval has shown that at least some cultural aspects can to musical artists. -

Open Content Licensing
Open Content Licensing Open Content Licensing From Theory to Practice Edited by Lucie Guibault & Christina Angelopoulos Amsterdam University Press Cover design: Kok Korpershoek bno, Amsterdam Lay-out: JAPES, Amsterdam ISBN 978 90 8964 307 0 e-ISBN 978 90 4851 408 3 NUR 820 Creative Commons License CC BY NC (http://creativecommons.org/licenses/by-nc/3.0) L. Guibault & C. Angelopoulos / Amsterdam University Press, Amsterdam, 2011 Some rights reversed. Without limiting the rights under copyright reserved above, any part of this book may be reproduced, stored in or introduced into a retrieval system, or transmitted, in any form or by any means (electronic, mechanical, photocopying, recording or otherwise). Contents 1. Open Content Licensing: From Theory to Practice – An Introduction 7 Lucie Guibault, Institute for Information Law, University of Amsterdam 2. Towards a New Social Contract: Free-Licensing into the Knowledge Commons 21 Volker Grassmuck, Humboldt University Berlin and University of Sao Paulo 3. Is Open Content a Victim of its Own Success? Some Economic Thoughts on the Standardization of Licenses 51 Gerald Spindler and Philipp Zimbehl, University of Göttingen 4. (Re)introducing Formalities in Copyright as a Strategy for the Public Domain 75 Séverine Dusollier, Centre de Recherche Informatique et Droit, Université Notre- Dame de la Paix (Namur) 5. User-Related Assets and Drawbacks of Open Content Licensing 107 Till Kreutzer, Institute for legal questions on Free and Open Source Software (ifrOSS) 6. Owning the Right to Open Up Access to Scientific Publications 137 Lucie Guibault, Institute for Information Law, University of Amsterdam 7. Friends or Foes? Creative Commons, Freedom of Information Law and the European Union Framework for Reuse of Public Sector Information 169 Mireille van Eechoud, Institute for Information Law, University of Amsterdam 8. -

Defending Sufism, Defining Islam: Asserting Islamic Identity in India
DEFENDING SUFISM, DEFINING ISLAM: ASSERTING ISLAMIC IDENTITY IN INDIA Rachana Rao Umashankar A dissertation submitted to the faculty of the University of North Carolina at Chapel Hill in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Anthropology. Chapel Hill 2012 Approved by: Dr. James L. Peacock Dr. Carl W. Ernst Dr. Margaret J. Wiener Dr. Lauren G. Leve Dr. Lorraine V. Aragon Dr. Katherine Pratt Ewing © 2012 Rachana Rao Umashankar ALL RIGHTS RESERVED ii ABSTRACT RACHANA RAO UMASHANKAR: Defending Sufism, Defining Islam: Asserting Islamic identity in India (Under the direction of Dr. James L. Peacock and Dr. Lauren G. Leve) Based on thirteen months of intensive fieldwork at two primary sites in India, this dissertation describes how adherents of shrine-based Sufism assert their identity as Indian Muslims in the contexts of public debates over religion and belonging in India, and of reformist critiques of their Islamic beliefs and practices. Faced with opposition to their mode of Islam from reformist Muslim groups, and the challenges to their sense of national identity as members of a religious minority in India, I argue that adherents of shrine-based Sufism claim the sacred space of the Sufi shrine as a venue where both the core values of Islam and of India are given form and reproduced. For these adherents, contemporary shrine-based Sufism is a dynamic and creative force that manifests essential aspects of Islam that are also fundamental Indian values, and which are critical to the health of the nation today. The dissertation reveals that contested identities and internal religious debates can only be understood and interpreted within the broader framework of national and global debates over Islam and over the place of Islam in the Indian polity that shape them. -

Coke Studio Pakistan: an Ode to Eastern Music with a Western Touch
ISSN (Online) - 2349-8846 Coke Studio Pakistan: An Ode to Eastern Music with a Western Touch SHAHWAR KIBRIA Shahwar Kibria ([email protected]) is a research scholar at the School of Arts and Aesthetics at the Jawaharlal Nehru University, New Delhi. Vol. 55, Issue No. 12, 21 Mar, 2020 Since it was first aired in 2008, Coke Studio Pakistan has emerged as an unprecedented musical movement in South Asia. It has revitalised traditional and Eastern classical music of South Asia by incorporating contemporary Western music instrumentation and new-age production elements. Under the religious nationalism of military dictator Muhammad Zia-ul-Haq, the production and dissemination of creative arts were curtailed in Pakistan between 1977 and 1988. Incidentally, the censure against artistic and creative practice also coincided with the transnational movement of qawwali art form as prominent qawwals began carrying it outside Pakistan. American audiences were first exposed to qawwali in 1978 when Gulam Farid Sabri and Maqbool Ahmed Sabri performed at New York’s iconic Carnegie Hall. The performance was referred to as the “aural equivalent of the dancing dervishes” in the New York Times (Rockwell 1979). However, it was not until Nusrat Fateh Ali Khan’s performance at the popular World of Music, Arts and Dance (WOMAD) festival in 1985 in Colchester, England, following his collaboration with Peter Gabriel, that qawwali became evident in the global music cultures. Khan pioneered the fusion of Eastern vocals and Western instrumentation, and such a coming together of different musical elements was witnessed in several albums he worked for subsequently. Some of them include "Mustt Mustt" in 1990 ISSN (Online) - 2349-8846 and "Night Song" in 1996 with Canadian musician Michael Brook, the music score for the film The Last Temptation of Christ (1988) and a soundtrack album for the film Dead Man Walking (1996) with Peter Gabriel, and a collaborative project with Eddie Vedder of the rock band Pearl Jam. -

Shotguns and Munaqqabes Along the Arabian Sea | Norient.Com 5 Oct 2021 01:51:14
Shotguns and Munaqqabes along the Arabian Sea | norient.com 5 Oct 2021 01:51:14 Shotguns and Munaqqabes along the Arabian Sea by Mark LeVine Maybe it was the 13-hour time difference. Maybe it was arriving at 6 a.m., after two nearly sleepless nights in coach, at an airport that had recently been attacked by terrorists, where – at least at the arrival lounge – it seemed that hardly anyone spoke a language I could understand. Or the fact that from all the news reports, conversations with friends, and even the tension on the plane, it was clear that Pakistan was entering another one of those violent periods that have defined its short history. Landing in Islamabad, I was literally on the opposite side of the Earth, as my five year old son Alessandro pointed out to me a few days before I left when he traced the longitudinal line from California over the North Pole and down (roughly) to Pakistan. Even Iraq, a far more violent and depressing place today than Pakistan – as of early 2008 – somehow felt more familiar to me. At least I could speak Arabic. Pakistan was definitely not in my cultural and historical comfort zone. Yet the Himalayas were only a couple of hours away; for all I knew, the Buddha had walked not too far from where I was standing. And quite probably, so had Osama bin Laden. https://norient.com/stories/pakistanrock Page 1 of 25 Shotguns and Munaqqabes along the Arabian Sea | norient.com 5 Oct 2021 01:51:14 I had come to Pakistan on the trail of a friend and kindred spirit, Salman Ahmed of the Pakistani supergroup Junoon. -
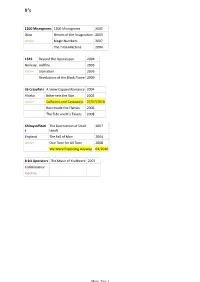
1200 Micrograms 1200 Micrograms 2002 Ibiza Heroes of the Imagination 2003 Active Magic Numbers 2007 the Time Machine 2004
#'s 1200 Micrograms 1200 Micrograms 2002 Ibiza Heroes of the Imagination 2003 Active Magic Numbers 2007 The Time Machine 2004 1349 Beyond the Apocalypse 2004 Norway Hellfire 2005 Active Liberation 2003 Revelations of the Black Flame 2009 36 Crazyfists A Snow Capped Romance 2004 Alaska Bitterness the Star 2002 Active Collisions and Castaways 27/07/2010 Rest Inside the Flames 2006 The Tide and It's Takers 2008 65DaysofStati The Destruction of Small 2007 c Ideals England The Fall of Man 2004 Active One Time for All Time 2008 We Were Exploding Anyway 04/2010 8-bit Operators The Music of Kraftwerk 2007 Collaborative Inactive Music Page 1 A A Forest of Stars The Corpse of Rebirth 2008 United Kingdom Opportunistic Thieves of Spring 2010 Active A Life Once Lost A Great Artist 2003 U.S.A Hunter 2005 Active Iron Gag 2007 Open Your Mouth For the Speechless...In Case of Those 2000 Appointed to Die A Perfect Circle eMOTIVe 2004 U.S.A Mer De Noms 2000 Active Thirteenth Step 2003 Abigail Williams In the Absence of Light 28/09/2010 U.S.A In the Shadow of A Thousand Suns 2008 Active Abigor Channeling the Quintessence of Satan 1999 Austria Fractal Possession 2007 Active Nachthymnen (From the Twilight Kingdom) 1995 Opus IV 1996 Satanized 2001 Supreme Immortal Art 1998 Time Is the Sulphur in the Veins of the Saint... Jan 2010 Verwüstung/Invoke the Dark Age 1994 Aborted The Archaic Abattoir 2005 Belgium Engineering the Dead 2001 Active Goremageddon 2003 The Purity of Perversion 1999 Slaughter & Apparatus: A Methodical Overture 2007 Strychnine.213 2008 Aborym -

1 MUSIC an Introduction to the Music of India I. INTRODUCTION TO
MUSIC An Introduction to the Music of India I. INTRODUCTION TO MUSIC THEORY AND THE MUSIC OF INDIA 20% A. Basic Elements of Music Theory 1. Sound and Music a. Music Is Sound Organized in Time b. Sound Waves c. Instruments as Sound Sources 2. Pitch a. Properties of Musical Sound b. Pitch on a Keyboard c. Generating the Twelve Pitches by Dividing the Octave d. Melody Defined with an Example Using Scale Degrees 3. Rhythm a. Beat and Tempo b. Grouping and Downbeat c. Syncopation 4. Harmony a. Chords and Harmony 5. Other Aspects of Musical Sound a. Texture, Timbre, and Instrumentation 6. Form, Genre, Style 7. Musical Form a. Perceiving Musical Form b. Elements of Form c. Composed and Non-Composed Music d. Repetition and Variation e. Improvisation f. Verse-Chorus Form 8. Which Is the Real Music? B. The Region, Languages, Contexts 1. South Asia 2. North and South India 3. The Indo-Aryan and Dravidian Language Families 4. Hinduism and Music 5. Islam and Music in India 6. Other Religious Settings 7. Formal Music of the Courts 8. The Modern City: Urban Audiences and the Concert Hall 9. Media a. Recording 1 b. Radio c. Television d. Internet e. India’s Film Industry II. INDIA’S REGIONAL MUSIC TRADITIONS AND DEVOTIONAL MUSIC 25% A. Regional Music Traditions 1. Regional and Pan-regional 2. Introduction to Instruments in Rural India 3. Songs of Village Life a. LISTENING EXAMPLE 1: HYMNS FOR THE CHATHI FAST, “CHATHI MATA” 4. Rural Professional Music: Three Case Studies a. Hereditary Musicians of Rajasthan i. -

Chants Sacrés
Chants sacrés : Voix de femmes 000 A CHA Chants sacrés : Voix d'hommes 000 A CHA Chants juifs 000 A CHA Raman, Susheela Divas du monde 000 A DIV Drop the debt 000 A DRO Brassens, Echos D'aujourd'hui 000 A ECH Dournon, Geneviève Instruments de musique du monde 000 A INS Je n'aime pas la world, mais ça j'aime bien ! 000 A JEN Konono n°1 Planet Rock 000 A PLA Tziganes 000 A TZI World Music 000 A WOR Bratsch L'Epopée tzigane 000 A.EPO Gotan Project Les Musiques qui ont inspiré leur album 000 A.GOT Waro, Danyel Island blues 000 A.ISL Mondomix Experience 000 A.MON Music from the Wine Lands 000 A.MUS Afonso, José Out of this world 000 A.OUT Sélection musiques du monde 000 A.SEL Son du monde 000 A.SON Voyage en Tziganie 000 A.VOY Bratsch Notes de voyage 000 BRA Bratsch Ca s' fête ! 000 BRA Bratsch Plein du monde 000 BRA Bratsch Urban Bratsch 000 BRA Chemirani, Keyvan Le Rythme de la parole 000 CHE Frères Nardàn (Les) Nardanie Autonome 000 FRE Gurrumul Yunupingu, Geoffrey Rrakala 000 GUR Haïdouti Orkestar Balkan heroes 000 HAI Levy, Hezy Singing like the Jordan river 000 LEV Nu Juwish Music 01 000 NUJ Robin, Thierry Gitans 000 ROB Robin, Thierry Rakhi 000 ROB Robin, Thierry Alezane 000 ROB Robin, Thierry Ces vagues que l'amour soulève 000 ROB Robin, Thierry Anita ! 000 ROB Robin, Thierry Kali Sultana 000 ROB Robin, Thierry Les Rives 000 ROB Robin, Thierry Jaadu 000 ROB Romanès, Délia J'aimerai perdre la tête 000 ROM Socalled Ghetto blaster 000 SOC Taraf de haïdouks Maskarada 000 TAR Tchanelas Les Fils du vent 000 TCH Urs Karpatz Autour de Sarah