Finite-State Automata and Algorithms
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Simulating Quantum Field Theory with a Quantum Computer
Simulating quantum field theory with a quantum computer John Preskill Lattice 2018 28 July 2018 This talk has two parts (1) Near-term prospects for quantum computing. (2) Opportunities in quantum simulation of quantum field theory. Exascale digital computers will advance our knowledge of QCD, but some challenges will remain, especially concerning real-time evolution and properties of nuclear matter and quark-gluon plasma at nonzero temperature and chemical potential. Digital computers may never be able to address these (and other) problems; quantum computers will solve them eventually, though I’m not sure when. The physics payoff may still be far away, but today’s research can hasten the arrival of a new era in which quantum simulation fuels progress in fundamental physics. Frontiers of Physics short distance long distance complexity Higgs boson Large scale structure “More is different” Neutrino masses Cosmic microwave Many-body entanglement background Supersymmetry Phases of quantum Dark matter matter Quantum gravity Dark energy Quantum computing String theory Gravitational waves Quantum spacetime particle collision molecular chemistry entangled electrons A quantum computer can simulate efficiently any physical process that occurs in Nature. (Maybe. We don’t actually know for sure.) superconductor black hole early universe Two fundamental ideas (1) Quantum complexity Why we think quantum computing is powerful. (2) Quantum error correction Why we think quantum computing is scalable. A complete description of a typical quantum state of just 300 qubits requires more bits than the number of atoms in the visible universe. Why we think quantum computing is powerful We know examples of problems that can be solved efficiently by a quantum computer, where we believe the problems are hard for classical computers. -

Geometric Algorithms
Geometric Algorithms primitive operations convex hull closest pair voronoi diagram References: Algorithms in C (2nd edition), Chapters 24-25 http://www.cs.princeton.edu/introalgsds/71primitives http://www.cs.princeton.edu/introalgsds/72hull 1 Geometric Algorithms Applications. • Data mining. • VLSI design. • Computer vision. • Mathematical models. • Astronomical simulation. • Geographic information systems. airflow around an aircraft wing • Computer graphics (movies, games, virtual reality). • Models of physical world (maps, architecture, medical imaging). Reference: http://www.ics.uci.edu/~eppstein/geom.html History. • Ancient mathematical foundations. • Most geometric algorithms less than 25 years old. 2 primitive operations convex hull closest pair voronoi diagram 3 Geometric Primitives Point: two numbers (x, y). any line not through origin Line: two numbers a and b [ax + by = 1] Line segment: two points. Polygon: sequence of points. Primitive operations. • Is a point inside a polygon? • Compare slopes of two lines. • Distance between two points. • Do two line segments intersect? Given three points p , p , p , is p -p -p a counterclockwise turn? • 1 2 3 1 2 3 Other geometric shapes. • Triangle, rectangle, circle, sphere, cone, … • 3D and higher dimensions sometimes more complicated. 4 Intuition Warning: intuition may be misleading. • Humans have spatial intuition in 2D and 3D. • Computers do not. • Neither has good intuition in higher dimensions! Is a given polygon simple? no crossings 1 6 5 8 7 2 7 8 6 4 2 1 1 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 2 18 4 18 4 19 4 19 4 20 3 20 3 20 1 10 3 7 2 8 8 3 4 6 5 15 1 11 3 14 2 16 we think of this algorithm sees this 5 Polygon Inside, Outside Jordan curve theorem. -

Introduction to Computational Social Choice
1 Introduction to Computational Social Choice Felix Brandta, Vincent Conitzerb, Ulle Endrissc, J´er^omeLangd, and Ariel D. Procacciae 1.1 Computational Social Choice at a Glance Social choice theory is the field of scientific inquiry that studies the aggregation of individual preferences towards a collective choice. For example, social choice theorists|who hail from a range of different disciplines, including mathematics, economics, and political science|are interested in the design and theoretical evalu- ation of voting rules. Questions of social choice have stimulated intellectual thought for centuries. Over time the topic has fascinated many a great mind, from the Mar- quis de Condorcet and Pierre-Simon de Laplace, through Charles Dodgson (better known as Lewis Carroll, the author of Alice in Wonderland), to Nobel Laureates such as Kenneth Arrow, Amartya Sen, and Lloyd Shapley. Computational social choice (COMSOC), by comparison, is a very young field that formed only in the early 2000s. There were, however, a few precursors. For instance, David Gale and Lloyd Shapley's algorithm for finding stable matchings between two groups of people with preferences over each other, dating back to 1962, truly had a computational flavor. And in the late 1980s, a series of papers by John Bartholdi, Craig Tovey, and Michael Trick showed that, on the one hand, computational complexity, as studied in theoretical computer science, can serve as a barrier against strategic manipulation in elections, but on the other hand, it can also prevent the efficient use of some voting rules altogether. Around the same time, a research group around Bernard Monjardet and Olivier Hudry also started to study the computational complexity of preference aggregation procedures. -
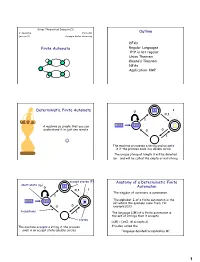
Deterministic Finite Automata 0 0,1 1
Great Theoretical Ideas in CS V. Adamchik CS 15-251 Outline Lecture 21 Carnegie Mellon University DFAs Finite Automata Regular Languages 0n1n is not regular Union Theorem Kleene’s Theorem NFAs Application: KMP 11 1 Deterministic Finite Automata 0 0,1 1 A machine so simple that you can 0111 111 1 ϵ understand it in just one minute 0 0 1 The machine processes a string and accepts it if the process ends in a double circle The unique string of length 0 will be denoted by ε and will be called the empty or null string accept states (F) Anatomy of a Deterministic Finite start state (q0) 11 0 Automaton 0,1 1 The singular of automata is automaton. 1 The alphabet Σ of a finite automaton is the 0111 111 1 ϵ set where the symbols come from, for 0 0 example {0,1} transitions 1 The language L(M) of a finite automaton is the set of strings that it accepts states L(M) = {x∈Σ: M accepts x} The machine accepts a string if the process It’s also called the ends in an accept state (double circle) “language decided/accepted by M”. 1 The Language L(M) of Machine M The Language L(M) of Machine M 0 0 0 0,1 1 q 0 q1 q0 1 1 What language does this DFA decide/accept? L(M) = All strings of 0s and 1s The language of a finite automaton is the set of strings that it accepts L(M) = { w | w has an even number of 1s} M = (Q, Σ, , q0, F) Q = {q0, q1, q2, q3} Formal definition of DFAs where Σ = {0,1} A finite automaton is a 5-tuple M = (Q, Σ, , q0, F) q0 Q is start state Q is the finite set of states F = {q1, q2} Q accept states : Q Σ → Q transition function Σ is the alphabet : Q Σ → Q is the transition function q 1 0 1 0 1 0,1 q0 Q is the start state q0 q0 q1 1 q q1 q2 q2 F Q is the set of accept states 0 M q2 0 0 q2 q3 q2 q q q 1 3 0 2 L(M) = the language of machine M q3 = set of all strings machine M accepts EXAMPLE Determine the language An automaton that accepts all recognized by and only those strings that contain 001 1 0,1 0,1 0 1 0 0 0 1 {0} {00} {001} 1 L(M)={1,11,111, …} 2 Membership problem Determine the language decided by Determine whether some word belongs to the language. -

Randnla: Randomized Numerical Linear Algebra
review articles DOI:10.1145/2842602 generation mechanisms—as an algo- Randomization offers new benefits rithmic or computational resource for the develop ment of improved algo- for large-scale linear algebra computations. rithms for fundamental matrix prob- lems such as matrix multiplication, BY PETROS DRINEAS AND MICHAEL W. MAHONEY least-squares (LS) approximation, low- rank matrix approxi mation, and Lapla- cian-based linear equ ation solvers. Randomized Numerical Linear Algebra (RandNLA) is an interdisci- RandNLA: plinary research area that exploits randomization as a computational resource to develop improved algo- rithms for large-scale linear algebra Randomized problems.32 From a foundational per- spective, RandNLA has its roots in theoretical computer science (TCS), with deep connections to mathemat- Numerical ics (convex analysis, probability theory, metric embedding theory) and applied mathematics (scientific computing, signal processing, numerical linear Linear algebra). From an applied perspec- tive, RandNLA is a vital new tool for machine learning, statistics, and data analysis. Well-engineered implemen- Algebra tations have already outperformed highly optimized software libraries for ubiquitous problems such as least- squares,4,35 with good scalability in par- allel and distributed environments. 52 Moreover, RandNLA promises a sound algorithmic and statistical foundation for modern large-scale data analysis. MATRICES ARE UBIQUITOUS in computer science, statistics, and applied mathematics. An m × n key insights matrix can encode information about m objects ˽ Randomization isn’t just used to model noise in data; it can be a powerful (each described by n features), or the behavior of a computational resource to develop discretized differential operator on a finite element algorithms with improved running times and stability properties as well as mesh; an n × n positive-definite matrix can encode algorithms that are more interpretable in the correlations between all pairs of n objects, or the downstream data science applications. -

Mechanism, Mentalism, and Metamathematics Synthese Library
MECHANISM, MENTALISM, AND METAMATHEMATICS SYNTHESE LIBRARY STUDIES IN EPISTEMOLOGY, LOGIC, METHODOLOGY, AND PHILOSOPHY OF SCIENCE Managing Editor: JAAKKO HINTIKKA, Florida State University Editors: ROBER T S. COHEN, Boston University DONALD DAVIDSON, University o/Chicago GABRIEL NUCHELMANS, University 0/ Leyden WESLEY C. SALMON, University 0/ Arizona VOLUME 137 JUDSON CHAMBERS WEBB Boston University. Dept. 0/ Philosophy. Boston. Mass .• U.S.A. MECHANISM, MENT ALISM, AND MET AMA THEMA TICS An Essay on Finitism i Springer-Science+Business Media, B.V. Library of Congress Cataloging in Publication Data Webb, Judson Chambers, 1936- CII:J Mechanism, mentalism, and metamathematics. (Synthese library; v. 137) Bibliography: p. Includes indexes. 1. Metamathematics. I. Title. QA9.8.w4 510: 1 79-27819 ISBN 978-90-481-8357-9 ISBN 978-94-015-7653-6 (eBook) DOl 10.1007/978-94-015-7653-6 All Rights Reserved Copyright © 1980 by Springer Science+Business Media Dordrecht Originally published by D. Reidel Publishing Company, Dordrecht, Holland in 1980. Softcover reprint of the hardcover 1st edition 1980 No part of the material protected by this copyright notice may be reproduced or utilized in any form or by any means, electronic or mechanical, including photocopying, recording or by any informational storage and retrieval system, without written permission from the copyright owner TABLE OF CONTENTS PREFACE vii INTRODUCTION ix CHAPTER I / MECHANISM: SOME HISTORICAL NOTES I. Machines and Demons 2. Machines and Men 17 3. Machines, Arithmetic, and Logic 22 CHAPTER II / MIND, NUMBER, AND THE INFINITE 33 I. The Obligations of Infinity 33 2. Mind and Philosophy of Number 40 3. Dedekind's Theory of Arithmetic 46 4. -

1 Alphabets and Languages
1 Alphabets and Languages Look at handout 1 (inference rules for sets) and use the rules on some exam- ples like fag ⊆ ffagg fag 2 fa; bg, fag 2 ffagg, fag ⊆ ffagg, fag ⊆ fa; bg, a ⊆ ffagg, a 2 fa; bg, a 2 ffagg, a ⊆ fa; bg Example: To show fag ⊆ fa; bg, use inference rule L1 (first one on the left). This asks us to show a 2 fa; bg. To show this, use rule L5, which succeeds. To show fag 2 fa; bg, which rule applies? • The only one is rule L4. So now we have to either show fag = a or fag = b. Neither one works. • To show fag = a we have to show fag ⊆ a and a ⊆ fag by rule L8. The only rules that might work to show a ⊆ fag are L1, L2, and L3 but none of them match, so we fail. • There is another rule for this at the very end, but it also fails. • To show fag = b, we try the rules in a similar way, but they also fail. Therefore we cannot show that fag 2 fa; bg. This suggests that the state- ment fag 2 fa; bg is false. Suppose we have two set expressions only involving brackets, commas, the empty set, and variables, like fa; fb; cgg and fa; fc; bgg. Then there is an easy way to test if they are equal. If they can be made the same by • permuting elements of a set, and • deleting duplicate items of a set then they are equal, otherwise they are not equal. -

A Mathematical Analysis of Student-Generated Sorting Algorithms Audrey Nasar
The Mathematics Enthusiast Volume 16 Article 15 Number 1 Numbers 1, 2, & 3 2-2019 A Mathematical Analysis of Student-Generated Sorting Algorithms Audrey Nasar Let us know how access to this document benefits ouy . Follow this and additional works at: https://scholarworks.umt.edu/tme Recommended Citation Nasar, Audrey (2019) "A Mathematical Analysis of Student-Generated Sorting Algorithms," The Mathematics Enthusiast: Vol. 16 : No. 1 , Article 15. Available at: https://scholarworks.umt.edu/tme/vol16/iss1/15 This Article is brought to you for free and open access by ScholarWorks at University of Montana. It has been accepted for inclusion in The Mathematics Enthusiast by an authorized editor of ScholarWorks at University of Montana. For more information, please contact [email protected]. TME, vol. 16, nos.1, 2&3, p. 315 A Mathematical Analysis of student-generated sorting algorithms Audrey A. Nasar1 Borough of Manhattan Community College at the City University of New York Abstract: Sorting is a process we encounter very often in everyday life. Additionally it is a fundamental operation in computer science. Having been one of the first intensely studied problems in computer science, many different sorting algorithms have been developed and analyzed. Although algorithms are often taught as part of the computer science curriculum in the context of a programming language, the study of algorithms and algorithmic thinking, including the design, construction and analysis of algorithms, has pedagogical value in mathematics education. This paper will provide an introduction to computational complexity and efficiency, without the use of a programming language. It will also describe how these concepts can be incorporated into the existing high school or undergraduate mathematics curriculum through a mathematical analysis of student- generated sorting algorithms. -

Context Free Languages II Announcement Announcement
Announcement • About homework #4 Context Free Languages II – The FA corresponding to the RE given in class may indeed already be minimal. – Non-regular language proofs CFLs and Regular Languages • Use Pumping Lemma • Homework session after lecture Announcement Before we begin • Note about homework #2 • Questions from last time? – For a deterministic FA, there must be a transition for every character from every state. Languages CFLs and Regular Languages • Recall. • Venn diagram of languages – What is a language? Is there – What is a class of languages? something Regular Languages out here? CFLs Finite Languages 1 Context Free Languages Context Free Grammars • Context Free Languages(CFL) is the next • Let’s formalize this a bit: class of languages outside of Regular – A context free grammar (CFG) is a 4-tuple: (V, Languages: Σ, S, P) where – Means for defining: Context Free Grammar • V is a set of variables Σ – Machine for accepting: Pushdown Automata • is a set of terminals • V and Σ are disjoint (I.e. V ∩Σ= ∅) •S ∈V, is your start symbol Context Free Grammars Context Free Grammars • Let’s formalize this a bit: • Let’s formalize this a bit: – Production rules – Production rules →β •Of the form A where • We say that the grammar is context-free since this ∈ –A V substitution can take place regardless of where A is. – β∈(V ∪∑)* string with symbols from V and ∑ α⇒* γ γ α • We say that γ can be derived from α in one step: • We write if can be derived from in zero –A →βis a rule or more steps. -

Regular Expressions with a Brief Intro to FSM
Regular Expressions with a brief intro to FSM 15-123 Systems Skills in C and Unix Case for regular expressions • Many web applications require pattern matching – look for <a href> tag for links – Token search • A regular expression – A pattern that defines a class of strings – Special syntax used to represent the class • Eg; *.c - any pattern that ends with .c Formal Languages • Formal language consists of – An alphabet – Formal grammar • Formal grammar defines – Strings that belong to language • Formal languages with formal semantics generates rules for semantic specifications of programming languages Automaton • An automaton ( or automata in plural) is a machine that can recognize valid strings generated by a formal language . • A finite automata is a mathematical model of a finite state machine (FSM), an abstract model under which all modern computers are built. Automaton • A FSM is a machine that consists of a set of finite states and a transition table. • The FSM can be in any one of the states and can transit from one state to another based on a series of rules given by a transition function. Example What does this machine represents? Describe the kind of strings it will accept. Exercise • Draw a FSM that accepts any string with even number of A’s. Assume the alphabet is {A,B} Build a FSM • Stream: “I love cats and more cats and big cats ” • Pattern: “cat” Regular Expressions Regex versus FSM • A regular expressions and FSM’s are equivalent concepts. • Regular expression is a pattern that can be recognized by a FSM. • Regex is an example of how good theory leads to good programs Regular Expression • regex defines a class of patterns – Patterns that ends with a “*” • Regex utilities in unix – grep , awk , sed • Applications – Pattern matching (DNA) – Web searches Regex Engine • A software that can process a string to find regex matches. -

Generating Context-Free Grammars Using Classical Planning
Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17) Generating Context-Free Grammars using Classical Planning Javier Segovia-Aguas1, Sergio Jimenez´ 2, Anders Jonsson 1 1 Universitat Pompeu Fabra, Barcelona, Spain 2 University of Melbourne, Parkville, Australia [email protected], [email protected], [email protected] Abstract S ! aSa S This paper presents a novel approach for generating S ! bSb /|\ Context-Free Grammars (CFGs) from small sets of S ! a S a /|\ input strings (a single input string in some cases). a S a Our approach is to compile this task into a classical /|\ planning problem whose solutions are sequences b S b of actions that build and validate a CFG compli- | ant with the input strings. In addition, we show that our compilation is suitable for implementing the two canonical tasks for CFGs, string produc- (a) (b) tion and string recognition. Figure 1: (a) Example of a context-free grammar; (b) the corre- sponding parse tree for the string aabbaa. 1 Introduction A formal grammar is a set of symbols and rules that describe symbols in the grammar and (2), a bounded maximum size of how to form the strings of certain formal language. Usually the rules in the grammar (i.e. a maximum number of symbols two tasks are defined over formal grammars: in the right-hand side of the grammar rules). Our approach is compiling this inductive learning task into • Production : Given a formal grammar, generate strings a classical planning task whose solutions are sequences of ac- that belong to the language represented by the grammar. -

Kleene Algebra with Tests and Coq Tools for While Programs Damien Pous
Kleene Algebra with Tests and Coq Tools for While Programs Damien Pous To cite this version: Damien Pous. Kleene Algebra with Tests and Coq Tools for While Programs. Interactive Theorem Proving 2013, Jul 2013, Rennes, France. pp.180-196, 10.1007/978-3-642-39634-2_15. hal-00785969 HAL Id: hal-00785969 https://hal.archives-ouvertes.fr/hal-00785969 Submitted on 7 Feb 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Kleene Algebra with Tests and Coq Tools for While Programs Damien Pous CNRS { LIP, ENS Lyon, UMR 5668 Abstract. We present a Coq library about Kleene algebra with tests, including a proof of their completeness over the appropriate notion of languages, a decision procedure for their equational theory, and tools for exploiting hypotheses of a certain kind in such a theory. Kleene algebra with tests make it possible to represent if-then-else state- ments and while loops in most imperative programming languages. They were actually introduced by Kozen as an alternative to propositional Hoare logic. We show how to exploit the corresponding Coq tools in the context of program verification by proving equivalences of while programs, correct- ness of some standard compiler optimisations, Hoare rules for partial cor- rectness, and a particularly challenging equivalence of flowchart schemes.