CORFU: a Shared Log Design for Flash Clusters
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Ghikas House on Hydra: from Artists’ Haven to Enchanted Ruins
The Ghikas House on Hydra: From Artists’ Haven to Enchanted Ruins HELLE VALBORG GOLDMAN Norwegian Polar Institute We sat on the terrace under the starry sky and talked about poetry, we drank wine, we swam, we rode donkeys, we played chess—it was like life in a novel. (Ghikas, quoted in Arapoglou 56) Introduction The Greek island of Hydra has become known for the colony of expatriate painters and writers that became established there in the 1950s and 60s (Genoni and Dalziell 2018; Goldman 2018). Two ‘literary houses,’ the homes of several of the island’s most well-known foreign residents during that era—the Australian couple, writers George Johnston and Charmian Clift, and Canadian singer-songwriter Leonard Cohen—have become places of pilgrimage for aficionados of Australian literature and popular music. Visitors wend through the maze of car- less, stone-paved lanes, asking for directions along the way, in order to stand outside the objects of their quests. Standing in the small public courtyard in front of the Johnstons’ house, or the tight laneway fronting the Cohen house, there is not much to see—the houses are quiet, the doors closed, the stone and white-washed walls surrounding the properties, which are typical of Hydra, are high. This doesn’t keep people from coming. They can picture in their minds’ eyes what is on the other side of the walls, having seen photographs of the writers at work and leisure inside the houses, and having read the books and listened to the songs that were written while the Johnstons and Cohen were in residence. -

In Focus: Corfu, Greece
OCTOBER 2019 IN FOCUS: CORFU, GREECE Manos Tavladorakis Analyst Pavlos Papadimitriou, MRICS Director www.hvs.com HVS ATHENS | 17 Posidonos Ave. 5th Floor, 17455 Alimos, Athens, GREECE Introduction The region of the Ionian Islands consists of the islands in the Ionian Sea on the western coast of Greece. Since they have long been subject to influences from Western Europe, the Ionian Islands form a separate historic and cultural unit than that of continental Greece. The region is divided administratively into four prefectures (Corfu, Lefkada, Kefallinia and Zakinthos) and comprises the islands of Kerkira (Corfu), Zakinthos, Cephalonia (Kefallinia), Lefkada, Ithaca (Ithaki), Paxi, and a number of smaller islands. The Ionian Islands are the sunniest part of Greece, but the southerly winds bring abundant rainfall. The region is noted for its natural beauty, its long history, and cultural tradition. It is also well placed geographically, since it is close to both mainland Greece and Western Europe and thus forms a convenient stepping-stone, particularly for passenger traffic between Greece and the West. These factors have favored the continuous development of tourism, which has become the most dynamic branch of the region’s economy. Island of Corfu CORFU MAP Corfu is located in the northwest part of Greece, with a size of 593 km2 and a costline, which spans for 217 km, is the largest of the Ionian Islands. The principal city of the island and seat of the municipality is also named Corfu, after the island’s name, with a population of 32,000 (2011 census) inhabitants. Currently, according to real estate agents, foreign nationals who permanently reside on Corfu are estimated at 18,000 individuals. -

Floating Adventure GR Islands of Corfu
Greece Active Journeys Escorted tour Cycling Tour descriptions and distances Day 1 Corfu Day 2 28 km Sivota - Parga - Lefkas Day 3 30 km Lefkas Day 4 45 km Islands of Corfu by Bike Cephalonia Day 5 20 km + On the Ionian Islands off the west coast of Greece, this is surely the most stunning- Ithaca & Meganisi 15 km ly beautiful side: the main attraction is the crystal clear blue shimmering Ionian Sea. Day 6 50 km Come and discover why centuries of Venetian influence dominate the archipelago Mitikas - Lefkas of the Ionian Islands. Day 7 24 km Paxos & Corfu From Corfu, which was the dream island of the unforgettable Austrian empress Day 8 Sissi, this journey will lead us to areas that are not very well known here. The Corfu Greeks themselves have been travelling to these islands for holidays for a welcome respite from the city. Discover the famous island of Ithaca, said to have been the home of Odysseus, you will never forget the green bird sanctuary island of Lefkas, the fantastic mountain Tour Details 2018 world of Kefallonia and the beautiful olive woods of the small island of Paxos. We Dates: April 14, 21, 28 enjoy our stay on board the wooden motor yacht and let us be pampered by the Oct 6, 13, 20, 27 excellent Greek cuisine and the coziness of the ship. Come enjoy this Floating Adventure with Active Journeys! Cost: $2495 per person Single Supplement: On request Fact Sheet Length: 8 days / 7 nights Includes : E-Bike Info : Bike rental: $175 • 7 nights accommodation, with 2 • E-bike rental: $350 Grade: Intermediate days all meals and 5 days break- fast & lunch or dinner on boat in- • Limited supplies on boat, so Starts/Ends Corfu reservations recommended cluded Above deck cabin: $185 p.p. -

Greek Cultures, Traditions and People
GREEK CULTURES, TRADITIONS AND PEOPLE Paschalis Nikolaou – Fulbright Fellow Greece ◦ What is ‘culture’? “Culture is the characteristics and knowledge of a particular group of people, encompassing language, religion, cuisine, social habits, music and arts […] The word "culture" derives from a French term, which in turn derives from the Latin "colere," which means to tend to the earth and Some grow, or cultivation and nurture. […] The term "Western culture" has come to define the culture of European countries as well as those that definitions have been heavily influenced by European immigration, such as the United States […] Western culture has its roots in the Classical Period of …when, to define, is to the Greco-Roman era and the rise of Christianity in the 14th century.” realise connections and significant overlap ◦ What do we mean by ‘tradition’? ◦ 1a: an inherited, established, or customary pattern of thought, action, or behavior (such as a religious practice or a social custom) ◦ b: a belief or story or a body of beliefs or stories relating to the past that are commonly accepted as historical though not verifiable … ◦ 2: the handing down of information, beliefs, and customs by word of mouth or by example from one generation to another without written instruction ◦ 3: cultural continuity in social attitudes, customs, and institutions ◦ 4: characteristic manner, method, or style in the best liberal tradition GREECE: ANCIENT AND MODERN What we consider ancient Greece was one of the main classical The Modern Greek State was founded in 1830, following the civilizations, making important contributions to philosophy, mathematics, revolutionary war against the Ottoman Turks, which started in astronomy, and medicine. -
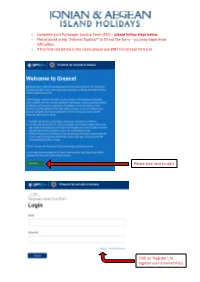
O Complete Your Passenger Locator Form (PLF) – Please Follow Steps Below
o Complete your Passenger Locator Form (PLF) – please follow steps below. o Please avoid using “Internet Explorer” to fill out the form – you may experience difficulties. o If the font size below is too small, please use ctrl+ to increase font size Please click here to start Click on ‘Register’, to register your email address Enter a valid email address Create your password Confirm your password Click “Submit” Please tick all boxes Click “Continue” As you will be flying to Greece, please select Aircraft Click “Continue” Type in the name of the airline e.g. “British Airways” Type in the flight number e.g. “BA0646” Ignore this box Select the date of your arrival Select the destination airport Please note: If you are flying to Preveza (PVK), please select “Aktio” as your point of entry Ignore this box Click “Continue” Type in your last name Type in your first name You can ignore this field Please select Enter your age Select “Passport” Add your number preceded by the country code e.g. “+447123456789” Ignore this box Ignore this box Ignore this box You should be able to see your email address here, if not, please enter it again. Click “Continue” Select country e.g. “United Kingdom” Select region e.g. “London” Type in your city e.g. “London” Type in your postcode Type in your street name Type in your street number Ignore this box Ignore if you have been in the UK for the 14-day period prior to your arrival in Greece. Otherwise, please select the country you visited. -

The Venice-Corfu Itinerary the Piraeus-Heraklion
Bitez, Konacık, Yalı and Mumcular. and Yalı Konacık, Bitez, Ortakent, Türkbükü, Yalıkavak, Gümüşlük, Gümüşlük, Yalıkavak, Türkbükü, Ortakent, the municipalities of Bodrum, Turgutreis, Turgutreis, Bodrum, of municipalities the the west coast of Turkey. The region includes includes region The Turkey. of coast west the located in the south-western Aegean, along along Aegean, south-western the in located Venetian citadel in Mylopotamus. in citadel Venetian province, province, Muğla the in city port a is Bodrum 4,000 inhabitants. There is an outstanding outstanding an is There inhabitants. 4,000 part fell into Turkish hands in 1715. in hands Turkish into fell part square km and a population of barely barely of population a and km square Long: 27°25’47.8”E Long: started in 1572 and the last Venetian-Cretan Venetian-Cretan last the and 1572 in started (Epidaurus, Corinth, Mycenea). Corinth, (Epidaurus, Cape Matapan. It has a total area of 300 300 of area total a has It Matapan. Cape In cooperion wi cooperion In Coordinor fortress stands out. The fortress construction construction fortress The out. stands fortress 37°02’06.4”N Lat: of the richest areas of classical Greek history history Greek classical of areas richest the of the Ionian and the Aegean sea close to to close sea Aegean the and Ionian the Suda, where, on a small island, the Venetian Venetian the island, small a on where, Suda, 27.429952 37.035105, WGS outer edges of the Peloponnese, behind one one behind Peloponnese, the of edges outer The island of Kythira is located between between located is Kythira of island The located some kilometre in the closest bay of of bay closest the in kilometre some located The city is located in a pretty bay, on the the on bay, pretty a in located is city The Bodrum Castle Castle Bodrum centrally, facing the Aegean sea. -

OECD Territorial Grids
BETTER POLICIES FOR BETTER LIVES DES POLITIQUES MEILLEURES POUR UNE VIE MEILLEURE OECD Territorial grids August 2021 OECD Centre for Entrepreneurship, SMEs, Regions and Cities Contact: [email protected] 1 TABLE OF CONTENTS Introduction .................................................................................................................................................. 3 Territorial level classification ...................................................................................................................... 3 Map sources ................................................................................................................................................. 3 Map symbols ................................................................................................................................................ 4 Disclaimers .................................................................................................................................................. 4 Australia / Australie ..................................................................................................................................... 6 Austria / Autriche ......................................................................................................................................... 7 Belgium / Belgique ...................................................................................................................................... 9 Canada ...................................................................................................................................................... -

Ancient Islands: Corfu
Ancient Islands: Corfu Plus Time in Athens and an Optional Extension to Crete October 10th - 18th 2019 Aside from Keeley Hawes, who plays a British widow who moved her family to Corfu in 1935, one of the biggest stars of ITV’s drama The Dur- rells is the island itself. In fact, it’s almost im- possible to watch the hit show or read Gerald Durrell’s wonderful books, on which it’s based, without thinking, “I wish my parents had moved our family to Corfu!” We have arranged first-class accommodation for your stay on the island and you’ll get the chance to take a cruise on the Ionian Sea to the Greek port of Parga and the tiny, unspoiled island of Paxos. We will visit many of the sires familiar from the TV Corfu Town series and there will also be plenty of time to relax by the pool or explore Corfu at your own pace. So instead of daydreaming about “The Durrells,” why don’t you come and discover this beautiful and beguiling Mediterranean island for yourself? The cost of this itinerary, per person, double occupancy is: We’ll end our trip with a short stay in Athens. Our Land Only $3390 hotel is ideally placed in the shadow of the Acrop- Single supplement $ 890 olis, for our adventures in the classical city center. And, if you still haven’t had enough, why not join Airfares are available from many U.S. departure cities. Please call for details. us for a few more days on the ancient island of The following services are included: Crete, cradle of the Minoan civilization. -

The Herpetofauna of the Island of Kythera (Attica, Greece) (Amphibia; Reptilia)
Broggi_Kythera April 2014_hErPEToZoA.qxd 08.08.2016 10:20 seite 1 hErPEToZoA 29 (1/2): 37 - 46 37 Wien, 30. Juli 2016 The herpetofauna of the Island of Kythera (Attica, Greece) (Amphibia; reptilia) die herpetofauna der Insel Kythira (Attika, Griechenland) (Amphibia; reptilia) MArIo F. B roGGI KUrZFAssUnG die Insel Kythira ist Teil des südägäischen Inselbogens, der sich vor mehreren Millionen von Jahren bilde - te und von der Peloponnes-halbinsel über Kreta, Karpathos und rhodos nach Anatolien erstreckt. In seiner Pflan - zen- und Tierwelt hat Kythira viel mit dem Peloponnes gemeinsam. Bislang wurden etwa sechzehn Amphibien- und reptilienarten von der Insel beschrieben, die sich durch ihren Wasserreichtum, besonders im norden, aus - zeichnet. die vorliegende Arbeit trägt die verstreute Information zur herpetofauna von Kythira zusammen und erweitert sie durch eigene Beobachtungen. ABsTrACT The Island of Kythera lies in the southern Aegean arc of islands, which formed millions of years ago and extends from the Peloponnese Peninsula, Crete, Karpathos and rhodes to Anatolia. With regard to its flora and fauna, Kythera has much in common with the Peloponnese. To date, about six teen species of amphibians and rep - tiles were reported to occur on the island, which has abundant water resources, in the north especially. In this paper, the scattered information on the island’s herpetofauna is compiled and enriched by author’s observations. KEy Words Amphibia; reptilia; Testudo marginata , Caretta caretta , Algyroides moreoticus , new island record, faunis - tics, Island of Kythera, Greece InTrodUCTIon The Ionian Island of Kythera forms a consists of acid metamorphosed rock, but bridge between the Peloponnese Peninsula for the most part, it is of calcareous origin. -

The Best of Greece
05_165386 ch01.qxp 1/3/08 10:57 AM Page 7 1 The Best of Greece Greece is, of course, the land of ancient sites and architectural treasures—the Acropo- lis in Athens, the amphitheater of Epidaurus, and the reconstructed palace at Knossos among the best known. But Greece is much more: It offers age-old spectacular natu- ral sights, for instance—from Santorini’s caldera to the gray pinnacles of rock of the Meteora—and modern diversions ranging from elegant museums to luxury resorts. It can be bewildering to plan your trip with so many options vying for your attention. Take us along and we’ll do the work for you. We’ve traveled the country extensively and chosen the very best that Greece has to offer. We’ve explored the archaeological sites, visited the museums, inspected the hotels, reviewed the tavernas and ouzeries, and scoped out the beaches. Here’s what we consider the best of the best. 1 The Best Travel Experiences • Making Haste Slowly: Give yourself island boat schedules! See chapter 10, time to sit in a seaside taverna and “The Cyclades.” watch the fishing boats come and go. • Leaving the Beaten Path: Persist If you visit Greece in the spring, take against your body’s and mind’s signals the time to smell the flowers; the that “this may be pushing too far,” fields are covered with poppies, leave the main routes and major daisies, and other blooms. Even in attractions behind, and make your Athens, you’ll see hardy species grow- own discoveries of landscape, villages, ing through the cracks in concrete or activities. -

Exploration Key to Growing Greek Industry Greece Is Opening Its Doors to Private Investment to Boost Domestic Industries
Greek mineral prospects A fisherman near Sarakiniko beach in Milos, Greece. The surrounding volcaniclastic rocks could be developed for their industrial mineral applications Exploration key to growing Greek industry Greece is opening its doors to private investment to boost domestic industries. Ananias Tsirambides and Anestis Filippidis discuss the country’s key exploration targets for industrial minerals development reece avoided bankruptcy with the to make the terms of the European Financial surplus above 5.5% and a programme of public agreement of the 17 leaders of the Stability Fund (EFSF) more flexible. property use and privatisations of €50bn for the Eurozone on 21 July 2011 for the Privatisation, imposition of new taxes and period 2011-2015. Therefore, the fiscal repair and second aid package of €158bn. Of spending cuts in the period 2011-15, totalling recovery of the national economy is not infeasible. this, €49bn will be from the €28.4bn, to hold the deficit to 7.5% of gross Despite the short-term costs, the reforms that Gparticipation of individuals. Many crucial details as national product (GNP), are foreseen. have been implemented or planned will benefit regards the new loan have not been clarified yet, In particular, the following reforms are expected: Greece for many years to come, as they will raise but it is obvious that Europe has given Greece a streamlining wage costs, operating cost reductions, growth, living standards and equity. A basic second chance, under the suffocating pressures of closures/mergers of bodies, decreased subsidies, prerequisite of success is that the burden and the markets and fears that the debt crisis may reorganisation of Public Enterprises and Entities benefits of reform broadly may be fairly shared. -

Visa & Residence Permit Guide for Students
Ministry of Interior & Administrative Reconstruction Ministry of Foreign Affairs Directorate General for Citizenship & C GEN. DIRECTORATE FOR EUROPEAN AFFAIRS Immigration Policy C4 Directorate Justice, Home Affairs & Directorate for Immigration Policy Schengen Email: [email protected] Email: [email protected] www.ypes.gr www.mfa.gr Visa & Residence Permit guide for students 1 Index 1. EU/EEA Nationals 2. Non EU/EEA Nationals 2.a Mobility of Non EU/EEA Students - Moving between EU countries during my short-term visit – less than three months - Moving between EU countries during my long-term stay – more than three months 2.b Short courses in Greek Universities, not exceeding three months. 2.c Admission for studies in Greek Universities or for participation in exchange programs, under bilateral agreements or in projects funded by the European Union i.e “ERASMUS + (placement)” program for long-term stay (more than three months). - Studies in Greek universities (undergraduate, master and doctoral level - Participation in exchange programs, under interstate agreements, in cooperation projects funded by the European Union including «ERASMUS+ placement program» 3. Refusal of a National Visa (type D)/Rights of the applicant. 4. Right to appeal against the decision of the Consular Authority 5. Annex I - Application form for National Visa (sample) Annex II - Application form for Residence Permit Annex III - Refusal Form Annex IV - Photo specifications for a national visa application Annex V - Aliens and Immigration Departments Contacts 2 1. Students EU/EEA Nationals You will not require a visa for studies to enter Greece if you possess a valid passport from an EU Member State, Iceland, Liechtenstein, Norway or Switzerland.