Technical Report on Survey Design and Implementation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cambodia High Frequency Phone Survey - Idpoor - Round1
Generated by Vanny_Pong, Nov 21, 2020 03:43 Sections: 9, Sub-sections: 1, Questionnaire created by Vanny_Pong, Nov 21, 2020 03:43 Questions: 205. Last modified by Vanny_Pong, Nov 21, 2020 03:43 Questions with enabling conditions: 126 Questions with validation conditions:35 Not shared with anyone Rosters: 5 Variables: 12 Cambodia High Frequency Phone Survey - IDPoor - Round1 SURVEY IDENTIFICATION INFORMATION QUESTIONNAIRE DESCRIPTION [1] INTERVIEW INFORMATION Sub-sections: 1, Rosters: 2, Questions: 38, Static texts: 5, Variables: 7. [2B] BASIC INFORMATION RDD No sub-sections, No rosters, Questions: 18. [2C] SOCIAL ECONOMIC STATUS No sub-sections, No rosters, Questions: 3. [3] KNOWLEDGE, [4] BEHAVIOUR, [5] ACCESS, [6] EMPLOYMENT AND [8] FIES No sub-sections, No rosters, Questions: 91, Static texts: 11, Variables: 3. [7] INCOME LOSS No sub-sections, Rosters: 1, Questions: 8. [10] SHOCKS AND COPING No sub-sections, No rosters, Questions: 5, Static texts: 1. [11] SAFETY NETS No sub-sections, Rosters: 1, Questions: 11. [12] RESULT OF INTERVIEW No sub-sections, No rosters, Questions: 26, Static texts: 2. [CB] CALL BACK No sub-sections, Rosters: 1, Questions: 5, Static texts: 4, Variables: 2. APPENDIX A — CATEGORIES APPENDIX B — VARIABLES APPENDIX C — CATEGORIES FILTERS LEGEND 1 / 42 SURVEY IDENTIFICATION INFORMATION QUESTIONNAIRE DESCRIPTION Basic information Title Cambodia High Frequency Phone Survey - IDPoor - Round1 SURVEY IDENTIFICATION INFORMATION QUESTIONNAIRE DESCRIPTION 2 / 42 [1] INTERVIEW INFORMATION Zone SINGLE-SELECT zone SCOPE: IDENTIFYING -

C.M.A.A Request for Proposal
C.M.A.A REQUEST FOR PROPOSAL RFP No: 001/CMAA/BTB/CFR/2015 For Battambang Land Release Project Annex I Instructions to Offerors A. Introduction 1. General The CMAA is seeking suitably qualified CMAA‐accredited operators to conduct Battambang Land Release Project as per Statement of Work (SOW) attached in Annex‐III. 2. Cost of proposal The Offeror shall bear all costs associated with the preparation and submission of the Proposal, the CMAA will in no case be responsible or liable for those costs, regardless of the conduct or outcome of the solicitation. B. Solicitation Documents 3. Contents of solicitation documents Proposals must offer services for the total requirement. Proposals offering only part of the requirement will be rejected. The Offeror is expected to examine all corresponding instructions, forms, terms and specifications contained in the Solicitation Documents. Failure to comply with these documents will be at the Offeror’s risk and may affect the evaluation of the Proposal. 4. Clarification of solicitation documents A prospective Offeror requiring any clarification of the Solicitation Documents may notify the CMAA in writing to [email protected]. The CMAA will respond in writing to any request for clarification of the Solicitation Documents that it receives earlier than 20 November 2014. Written copies of the CMAA’s response (including an explanation of the query but without identifying the source of inquiry) will be sent by email to all prospective Offerors that has received the Solicitation Documents. 5. Amendments of solicitation documents At any time prior to the deadline for submission of Proposals, the CMAA may, for any reason, whether at its own initiative or in response to a clarification requested by a prospective Offeror, modify the Solicitation Documents by amendment. -
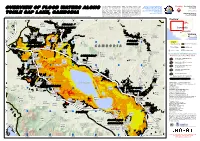
!I !I !I !I !I !I !I
This map presents potential standing waters is uncertain because of the Disaster coverage by the International Flooding Production Date: flood waters/ flood affected land over relatively low spatial resolution of the Charter 'Space and Major Disasters'. For 10/11/2011 the affected area surrounding Tonle satellite sensors used for this analysis, more information on the Charter, which is Sap Lake, Cambodia following recent Detected water bodies likely reflect an about assisting the disaster relief heavy rainy season. This analysis underestimation of all flood-affected organizations with multi-satellite data and Version 2.0 information, visit !, indicates that flood waters have areas within the map extent. This www.disasterscharter.org ! expanded in the lake area between 28 analysis has not yet been validated in UNOSAT Activation: August and 27th October 2011. Please the field. Please send ground feedback FL20111012KHM Flood Analysis with ENVISAT ASAR WSM imagery recorded on 28 August, 27 & 30 September, 27 October 2011 over Tonle Sap Lake, Cambodia note that the exact limit of the flood!( to UNITAR / UNOSAT. !( !( 102°55'0"E 103°20'0"E 103°45'0"E !( 104°10'0"E 104°35'0"E 105°0'0"E Thailand !( !( ¤£348 !( Map !( !( Prasat Phumi Extent !( !( Banteay Char !( Chhmar !( Phumi !( Cambodia Phumi Thnong !(Skov !( Khang Cheung PHNOM PENH !( !( ¥¦¬ Phumi!( 68 !( ¤£ Treas !( Phumi Vietnam !( !( !( !( !( Svay !( Pou PHUMI !( Roessei Ho Chi Minh City !( Phumi Phumi !(Kulen !( !( Chek 68 Sre Noy MLU PREY!( !(!( ¤£ !(Thum !( Bahal !( Pheas Phumi !( !( -

Activity Report
Kingdom of Cambodia The Project for Strengthening Capacity for Maintenance of Roads and Bridges Activity Report February 2018 MINISTRY OF PUBLIC WORKS AND TRANSPORTS JAPAN INTERNATIONAL COOPERATION AGENCY Location Map List of Abbreviation AC Asphalt Concrete ADB Asian Development Bank AusAID Australian Agency for International Development BOQ Bill of Quantities C/P Counter Part CAMRA Cambodia Road Association CAMTA Cambodia Truck Association CD Critical Damage CDC Council for the Development of Cambodia CFC Carbon Fiber Cloth CTIE CTI Engineering Co.Ltd., CTII CTI Engineering International Co.Ltd., D Damaged DB Database DBST Double Bituminous Surface Treatment DPWT Provincial Department of Public Works and Transport DRIMS Dynamic Response Intelligent Monitoring System DTC Department of Technical and Transport EC Executing Committee EOJ Embassy of Japan EXMID Expressway and Mega Bridge and Investment Department FWD Falling Weight Defelectometer FY Fiscal Year GDI General Department of Inspection GDPW General Department of Public Works GIS Geological Information System GMS Greater Mekong Subregion GOC Government of Cambodia GPS Global Positioning System HDM4 Highway Development and Maintenance. Management System 4 HEC Heavy Equipment Center HERCD Heavy Equipment and Road Construction Department HSWIM High Speed Weigh in Motion, Fast WIM HV Heavy Vehicle IDA International Development Association IRI International Roughness Index ITC Institute of Technology of Cambodia JCC Joint Coordination Committee JCI Japan Concrete Institute JICA Japan -

Location Map of Flood Damaged Rural Roads in Kampong Cham Province
Project Number: 46009-001 October 2012 Cambodia: Flood Damage Emergency Reconstruction Project Location Map of Flood Damaged Rural Roads in Kampong Cham Province Prepared by: Ministry of Rural Development By making any designation of or reference to a particular territory or geographical area, or by using the term "country" in the website, ADB does not intend to make any judgment as to the legal or other status of any territory or area. Boundaries, colors, denominations or any other information shown on maps do not imply, on the part of ADB, any judgment on the legal status of any territory, or any endorsement or acceptance of such boundaries, colors, denominations, or information. Location Map of Flood Damaged Rural Roads in Kampong Cham Province 480000 487500 495000 502500 510000 517500 525000 532500 540000 547500 555000 562500 570000 577500 585000 592500 600000 607500 615000 622500 630000 637500 645000 652500 660000 m Tho 1375000 g 1375000 pon #0 Legend Kam #0 Tuol Sambuor #0 Ou Mlu Ta Prok #0 #0 Flood Damaged Rural Road 1367500 1367500 Dang Kdar Areaks Tnaot #0 #0 Cheyyou National Roads Chamkar Andoung Lvea Leu #0#0 2 1$ Spueu 2 2 tu K #0 #0 Krouch#0 Chhmar#0 Preah Andoung ra Ckhum 1360000 Chamkar#0 Leu t 1360000 Me Sar Chrey #0 1$Peam Kaoh#0 Sna #0 ie Svay Teab Krouch Chhmar #0 Preaek Kak #0 Khpob Ta Nguon Roka Khnaor 1$ Csrok Soupheas 1$ Svay Khleang#0 2 #0 #0 #0C #0 1 K tu7#0 Stueng TrangTrea Peus Pir UV Chumnik Peus Muoy .! Ckhet 1352500 1352500 Ta Ong #0 Tuol Preah Khleang #0 #0 Water way #0 Preaek Bak #0 #0 Preaek a Chi Sampong -

General Population Census of Cambodia 1998 Final Census Results
KINGDOM OF CAMBODIA Nation - Religion - King General Population Census of Cambodia 1998 Final Census Results (2nd Edition) National Institute of Statistics, Ministry of Planning Phnom Penh, Cambodia Funded by: United Nations Population Fund August, 2002 CONTENTS Page Foreword by HE Minister of Planning 3 Foreword by UNFPA Representative, Cambodia 5 Cambodia-Province Map 6 Figures at a Glance 7 SECTION 1- Introduction 10 SECTION 2- Brief Analysis of Final Census Results of Cambodia 17 GLOSSARY 37 SECTION 3- Census Tables 41 Cambodia 42 Provinces / Municipalities (with Analytical Notes) 45 01. Banteay Mean Chey 46 02. Bat Dambang 56 03. Kampong Cham 67 04. Kampong Chhnang 80 05. Kampong Spueu 91 06. Kampong Thum 102 07. Kampot 113 08. Kandal 124 09. Kaoh Kong 136 10. Kracheh 146 11. Mondol Kiri 156 12. Phnom Penh Municipality 165 13. Preah Vihear 176 14. Prey Veaeng 186 15. Pousat 198 16. Rotanak Kiri 208 17. Siem Reab 218 1 18. Krong Preah Sihanouk 229 19. Stueng Traeng 238 20. Svay Rieng 248 21. Takaev 259 22. Otdar Mean Chey 270 23. Krong Kaeb 279 24. Krong Pailin 288 Annexes Annex 1- Form A - Houselisting and 297 Form B - Households Questionnaires 298 Annex 2- List of Priority Tables 302 Annex 3- Publication Programme 304 2 TOC FOREWORD By HE Minister of Planning, Cambodia It is with great pleasure that I present this report containing the final population figures and some important results of the 1998 Census of Cambodia. Earlier, in August 1998, the provisional population figures were released based on a quick tabulation of summary figures provided by the enumerators. -

Quarterly Report #21 Helping Address Rural Vulnerabilities and Ecosystem Stability (Harvest) Program
Prepared by Fintrac Inc. QUARTERLY REPORT #21 HELPING ADDRESS RURAL VULNERABILITIES AND ECOSYSTEM STABILITY (HARVEST) PROGRAM January – March 2016 This publication was produced for review by the United States Agency for International Development. It was prepared by Fintrac Inc. under contract # AID-442-C-11-00001 with USAID/Cambodia. HARVEST ANNUAL REPORT #1, DECEMBER 2010 – SEPTEMBER 2011 1 Fintrac Inc. www.fintrac.com [email protected] US Virgin Islands 3077 Kronprindsens Gade 72 St. Thomas, USVI 00802 Tel: (340) 776-7600 Fax: (340) 776-7601 Washington, D.C. 1400 16th St. NW, Suite 400 Washington, D.C. 20036 USA Tel: (202) 462-8475 Fax: (202) 462-8478 Cambodia HARVEST No. 34 Street 310 Sangkat Beong Keng Kang 1 Khan Chamkamorn, Phnom Penh, Cambodia Tel: 855 (0) 23 996 419 Fax: 855 (0) 23 996 418 QUARTERLY REPORT #21 HELPING ADDRESS RURAL VULNERABILITIES AND ECOSYSTEM STABILITY (HARVEST) PROGRAM January – March 2016 The author’s views expressed in this publication do not necessarily reflect the views of the United States Agency for International Development or the United States government. CONTENTS EXECUTIVE SUMMARY......................................................................................................... 1 1. INTRODUCTION ................................................................................................................ 2 1.1 Program Description ...................................................................................................................................... 3 1.2 Geographic Focus ........................................................................................................................................... -

Environment Categorization Report
KINGDOM OF CAMBODIA Nation Religion King MINISTRY OF WATER RESOURCE AND METHODOLOGY ASIAN DEVELOPMENT BANK ADB Loan No 3289-CAM CAMBODIA: UPLANDS IRRIGATION AND WATER RESOURCES MANAGEMENT SECTOR PROJECT, CAMBODIA For (MOWRAM – CW07) – Upgrading, modernizing and extending the secondary and tertiary canals of Prek Chik Irrigation System (PC) in Battambang Province – Package 1 ENVIRONMENT CATEGORIZATION REPORT Phnom Penh, October 2016 Table of Content Table of Content ........................................................................................................................................................... 1 List of Tables ................................................................................................................................................................ 1 List of Figures ............................................................................................................................................................... 1 ABBREVIATION ........................................................................................................................................................... 2 A. Background ..................................................................................................................................................... 3 B. Sub-project Description ................................................................................................................................... 3 C. Rapid Environmental Assessment .................................................................................................................. -
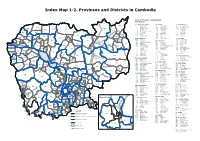
Index Map 1-2. Provinces and Districts in Cambodia
Index Map 1-2. Provinces and Districts in Cambodia Code of Province / Municipality and District 01 BANTEAY MEANCHEY 08 KANDAL 16 RATANAK KIRI 1608 0102 Mongkol Borei 0801 Kandal Stueng 1601 Andoung Meas 2204 0103 Phnum Srok 0802 Kien Svay 1602 Krong Ban Lung 1903 0104 Preah Netr Preah 0803 Khsach Kandal 1603 Bar Kaev 2202 2205 1303 2201 0105 Ou Chrov 0804 Kaoh Thum 1604 Koun Mom 1609 0106 Krong Serei Saophoan 0805 Leuk Daek 1605 Lumphat 0107 2203 0107 Thma Puok 0806 Lvea Aem 1606 Ou Chum 0108 Svay Chek 0807 Mukh Kampul 1607 Ou Ya Dav 1302 1601 0109 Malai 0808 Angk Snuol 1608 Ta Veaeng 1307 0110 Krong Paoy Paet 0809 Ponhea Lueu 1609 Veun Sai 0103 1714 1606 0108 1712 0810 S'ang 1304 1904 02 BATTAMBANG 0811 Krong Ta Khmau 17 SIEM REAP 1308 0201 Banan 1701 Angkor Chum 1701 1602 1603 1713 1905 0202 Thma Koul 09 KOH KONG 1702 Angkor Thum 0110 0105 1901 0203 Krong Battambang 0901 Botum Sakor 1703 Banteay Srei 0106 0104 1706 1702 1703 1301 1607 0204 Bavel 0902 Kiri Sakor 1704 Chi Kraeng 0109 1604 0205 Aek Phnum 0903 Kaoh Kong 1706 Kralanh 0102 1707 1306 1605 0206 Moung Ruessei 0904 Krong Khemarak Phoumin 1707 Puok 0210 0207 Rotonak Mondol 0905 Mondol Seima 1709 Prasat Bakong 1710 1305 0208 Sangkae 0906 Srae Ambel 1710 Krong Siem Reab 0211 1709 0209 Samlout 0907 Thma Bang 1711 Soutr Nikom 0202 0205 0204 1711 1902 0210 Sampov Lun 1712 Srei Snam 1704 0211 Phnom Proek 10 KRATIE 1713 Svay Leu 0212 0203 0212 Kamrieng 1001 Chhloung 1714 Varin 0213 Koas Krala 1002 Krong Kracheh 0208 0604 0606 1102 0214 Rukhak Kiri 1003 Preaek Prasab 18 PREAH SIHANOUK -

Poverty and Socioeconomic Condition
Uplands Irrigation and Water Resources Management Sector Project (RRP CAM 44328) POVERTY AND SOCIOECONOMIC CONDITION A. Introduction 1. This report presents the socioeconomic and poverty situation in the project areas of the Uplands Irrigation and Water Resources Management Sector Project in Cambodia. The project areas are located in the provinces of Battambang and Kampong Thom. The proposed project is planned to enhance agricultural and rural economic productivity through increased efficiency of irrigation systems and improved management of water resources. It will be implemented in two irrigation schemes, namely, Prek Chik Irrigation Scheme located in Battambang Province and Taing Krasaing Irrigation Scheme located in Kampong Thom Province. The social and poverty assessment of the project examines the socioeconomic conditions in the project areas and identifies the population that will be impacted. It identifies the existing irrigation and agriculture situation in relation to poverty condition of the existing population within the proposed irrigation schemes. It presents the poverty situation in terms of the poverty rate and identifies the vulnerable population which may be impacted by the project. B. Development Scenario and Socioeconomic Development Policies and Plans 2. Over the last decade, Cambodia has been experiencing economic development with a growth rate of 10.2% for the period of 2004–2008. Though the gross domestic product (GDP) decreased to 0.1 in 2009, it recovered in 2010 and 2011 with a growth rate of 6.0%. Agriculture, fisheries and forestry have shown tremendous growth in 2005 with 15.7% compared to other sectors such as industry with 12.7% and services with 13.1%. -

Project Fact Sheet 2013
PROJECT FACT SHEET 2013 CLIMATE ADAPTIVE LIVELIHOODS OF AGRICULTURE COMMUNITY Provincial Department of Agriculture, Battambang Province Photo: CEDAC PURPOSE OF PROJECT The project aims to improve sustainable livelihood options of target farmers by enhancing adaptation and resilience to drought and flood in vulnerable villages in Thma Koul, Moung Russei, and Koas Krala districts, Battambang province. KEY RESULTS Target farmers have increased farming activities, particularly on subsistence and cash crops growing and livestock production through improved small irrigation systems withadequate water supply and sustainable management farmers have adaptable skills to drought and flood on agriculture activities to sustain their regular income as a result of improved resistant crops growing techniques and increased awareness on adaptation measures Competent community based mechanism (AC) is in place to develop mitigation and adaptation measures to climate change Coping mechanism at provincial level is in place as evidenced by an integration of adaptation to climate change into district, commune, and provincial level planning BACKGROUND Battambang province has been identified by NAPA as the area most prone to droughts and floods. The poverty rate is higher in Thma Koul, Moung Ruessei, and Koash Krala amongst all 14 districts which ranged between 29.3% and 82.5% according to ID Poor 2010. These areas are most prone to floods and droughts. As revealed by the field assessment, existing irrigation systems in some PROJECT FACT SHEET 2013 communes in these districts have been deteriorated and most of them are idle. Generally, villagers have limited awareness on climate change adaptation and limited skills on climate resilient agriculture activities. This has an impact on livelihoods and rural employment opportunities of farmers who are highly dependent on agriculture activities. -

Confidential Introductory Submission
INTRODUCTION 1. We, the Co-Prosecutors of the Extraordinary Chambers in the Courts of Cambodia (ECCC): (1) Having considered the Law on the Establishment of the ECCC; (2) Having considered the Internal Rules of the ECCC; (3) Having seen the Criminal Case File No. 004 dated 15 November 2008; and (4) Having conducted a preliminary investigation submit the following: 2. Beginning in early 1977, T A An led a group of cadre from the Southwest Zone who purged and replaced the existing cadre of the Central (old North) Zone. As a result of this purge, T A An became the Deputy Secretary of the Central Zone and the Secretary of Sector 41. Prior to leading the Central Zone purge, T A An had been a Member of the Sector 35 Standing Committee in the Southwest Zone and an elected representative RIWKH3HRSOH¶V5HSUHVHQWDWLYH$VVHPEO\ 3. In 1977 and 1978, another group of Southwest Zone cadre led by Ta Mok and T A Tith purged and replaced the existing cadre of the Northwest Zone. As a result of this purge, T A Tith became the Acting Secretary of the Northwest Zone and Secretary of Sector 1. Prior to leading the Northwest Zone purge, T A Tith had been the Secretary of the Kirivong District of the Southwest Zone in 1976 and 1977. 4. In June 1977, as part of the broader Northwest Zone purge led by Ta Mok and T A Tith, I M Chaem led a purge of Preah Net Preah District of Sector 5 of the Northwest Zone and became the Secretary of Preah Net Preah District.