Rethinking Routing and Peering in the Era of Vertical Integration of Network Functions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PEERING: an AS for Us
PEERING: An AS for Us Brandon Schlinker1, Kyriakos Zarifis1, Italo Cunha2, Nick Feamster3, and Ethan Katz-Bassett1 1University of Southern California — 2Universidade Federal de Minas Gerais — 3Georgia Institute of Technology {bschlink, kyriakos, ethan.kb}@usc.edu — [email protected] — [email protected] ABSTRACT 29, 45]. BGP, the Internet’s interdomain routing protocol, Internet routing suffers from persistent and transient failures, can experience slow convergence [30] and persistent route circuitous routes, oscillations, and prefix hijacks. A ma- oscillations [17,54]. It lacks mechanisms to prevent spoof- jor impediment to progress is the lack of ways to conduct ing [5,27] and prefix hijacks [24,32,58]. Despite known impactful interdomain research. Most research is based ei- problems, little has changed with interdomain routing, and ther on passive observation of existing routes, keeping re- there has been little impactful research in recent years. searchers from assessing how the Internet will respond to This stagnancy in the face of known problems is in stark route or policy changes; or simulations, which are restricted contrast to the rapid innovation in other areas of network- by limitations in our understanding of topology and policy. ing. We are in an era of remarkable changes in networking We propose a new class of interdomain research: re- and its role in our lives, as mobile connectivity and stream- searchers can instantiate an AS of their choice, including ing video change how we use the Internet, and advances in its intradomain topology and interdomain interconnectivity, software defined networking and data centers change how and connect it with the “live” Internet to exchange routes we run networks. -
LOYALTY PROGRAMS Source: Perkler.Com
LOYALTY PROGRAMS Source: Perkler.com Use CTRL+Click to follow these links to the web pages which describe each vendor’s loyalty program. 1-800-Contacts Member 1-800-Flowers Fresh Rewards 1-800-flowers.com Member 1-800-petmeds Member 99 Cents Only Email 99 Restaurants eClub A Pea In The Pod Email A&P Supermarket Bonus Savings Club A&P Supermarket Live Better Wellness Club A. T. Cross Email A.C. Moore Store Specials AAA - Show Your Card & Save AARP Membership ABC Shop Rewards Abercrombie & Fitch Email Abode eNewsletter Absolutely Gorgeous VIP Accor Advantage Plus Asia-Pacific Accor A|Club Accor A|Club Gold Accor A|Club Platinum Accor A|Club Silver Ace Hardware Email Ace Hardware Rewards ACLens.com Activa Email Active Skin Active Points Adairs Linen Lovers Club Adams Offers Adidas Email Adobe Email Adore Beauty Email Adorne Me Rewards ADT Premium Advance Auto Parts Email Aeropostale Email List Aerosoles Email Aesop Mailing List AETV Email AFL Rewards AirMiles Albertsons Preferred Savings Card Aldi eNewsletter Aldi eNewsletter USA Aldo Email Alex & Co Newsletter Alexander McQueen Email Alfresco Emporium Email Ali Baba Rewards Club Ali Baba VIP Customer Card Alloy Newsletter AllPhones Webclub Alpine Sports Store Card Amazon.com Daily Deals Amcal Club American Airlines - TRAAVEL Perks American Apparel Newsletter American Eagle AE REWARDS AMF Roller Anaconda Adventure Club Anchor Blue Email Angus and Robertson A&R Rewards Ann Harvey Offers Ann Taylor Email Ann Taylor LOFT Style Rewards Anna's Linens Email Signup Applebee's Email Aqua Shop Loyalty Membership Arby's Extras ARC - Show Your Card & Save Arden B Email Arden B. -

Hacking the Master Switch? the Role of Infrastructure in Google's
Hacking the Master Switch? The Role of Infrastructure in Google’s Network Neutrality Strategy in the 2000s by John Harris Stevenson A thesis submitteD in conformity with the requirements for the Degree of Doctor of Philosophy Faculty of Information University of Toronto © Copyright by John Harris Stevenson 2017 Hacking the Master Switch? The Role of Infrastructure in Google’s Network Neutrality Strategy in the 2000s John Harris Stevenson Doctor of Philosophy Faculty of Information University of Toronto 2017 Abstract During most of the decade of the 2000s, global Internet company Google Inc. was one of the most prominent public champions of the notion of network neutrality, the network design principle conceived by Tim Wu that all Internet traffic should be treated equally by network operators. However, in 2010, following a series of joint policy statements on network neutrality with telecommunications giant Verizon, Google fell nearly silent on the issue, despite Wu arguing that a neutral Internet was vital to Google’s survival. During this period, Google engaged in a massive expansion of its services and technical infrastructure. My research examines the influence of Google’s systems and service offerings on the company’s approach to network neutrality policy making. Drawing on documentary evidence and network analysis data, I identify Google’s global proprietary networks and server locations worldwide, including over 1500 Google edge caching servers located at Internet service providers. ii I argue that the affordances provided by its systems allowed Google to mitigate potential retail and transit ISP gatekeeping. Drawing on the work of Latour and Callon in Actor– network theory, I posit the existence of at least one actor-network formed among Google and ISPs, centred on an interest in the utility of Google’s edge caching servers and the success of the Android operating system. -

The Sanity of Art. the Sanity of Art: an Exposure of the Current Nonsense About Artists Being Degenerate
The Sanity of Art. The Sanity of Art: An Exposure of the Current Nonsense about Artists being Degenerate. By Ber. nard Shaw : : : : The New Age Press 140 Fleet St., London. 1908 Entered at Library of Congress, United States of America. All rights reserved. Preface. HE re-publication of this open letter to Mr. Benjamin Tucker places me, Tnot for the first time, in the difficulty of the journalist whose work survives the day on which it was written. What the journalist writes about is what everybody is thinking about (or ought to be thinking about) at themoment of writing. To revivehis utterances when everybodyis thinking aboutsomething else ; when the tide of public thought andimagination has turned ; when the front of the stage is filled with new actors ; when manylusty crowers have either survived their vogueor perished with it ; when the little men you patronized have become great, and the great men you attacked have been sanctified and pardoned by popularsentiment in the tomb : all these inevitables test the quality of your I journalismvery severely. Nevertheless, journalism can claim to be the highest formof literature ; for all the highest literature is journalism. The writer who aims atproducing the platitudes which are“not for an age, butfor all time ” has his reward in being unreadable in all ages ; whilst Platoand Aristophanes trying to knock some sense into the Athens oftheir day, Shakespearpeopling that same Athens with Elizabethan mechanics andWarwickshire hunts, Ibsen photo- graphing the local doctors- and vestrymen of a Norwegian parish, Carpaccio painting the life of St. Ursula exactly as if she were a lady living in the next street to him, are still alive and at home everywhere among the dust and ashes of many thousands of academic, punctilious, most archaeologically correct men of letters and art who spent their lives haughtily avoiding the journal- ist’s vulgar obsession with the ephemeral. -

Interconnection
Interconnection 101 As cloud usage takes off, data production grows exponentially, content pushes closer to the edge, and end users demand data and applications at all hours from all locations, the ability to connect with a wide variety of players becomes ever more important. This report introduces interconnection, its key players and busi- ness models, and trends that could affect interconnection going forward. KEY FINDINGS Network-dense, interconnection-oriented facilities are not easy to replicate and are typically able to charge higher prices for colocation, as well as charging for cross-connects and, in some cases, access to public Internet exchange platforms and cloud platforms. Competition is increasing, however, and competitors are starting the long process of creating network-dense sites. At the same time, these sites are valuable and are being acquired, so the sector is consolidating. Having facili- ties in multiple markets does seem to provide some competitive advantage, particularly if the facilities are similar in look and feel and customers can monitor them all from a single portal and have them on the same contract. Mobility, the Internet of Things, services such as SaaS and IaaS (cloud), and content delivery all depend on net- work performance. In many cases, a key way to improve network performance is to push content, processing and peering closer to the edge of the Internet. This is likely to drive demand for facilities in smaller markets that offer interconnection options. We also see these trends continuing to drive demand for interconnection facilities in the larger markets as well. © 2015 451 RESEARCH, LLC AND/OR ITS AFFILIATES. -
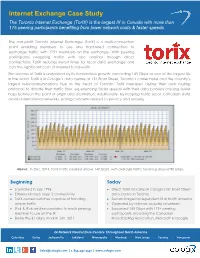
Cologix Torix Case Study
Internet Exchange Case Study The Toronto Internet Exchange (TorIX) is the largest IX in Canada with more than 175 peering participants benefiting from lower network costs & faster speeds The non-profit Toronto Internet Exchange (TorIX) is a multi-connection point enabling members to use one hardwired connection to exchange traffic with 175+ members on the exchange. With peering participants swapping traffic with one another through direct connections, TorIX reduces transit times for local data exchange and cuts the significant costs of Internet bandwidth. The success of TorIX is underlined by its tremendous growth, exceeding 145 Gbps as one of the largest IXs in the world. TorIX is in Cologix’s data centre at 151 Front Street, Toronto’s carrier hotel and the country’s largest telecommunications hub in the heart of Toronto. TorIX members define their own routing protocols to dictate their traffic flow, experiencing faster speeds with their data packets crossing fewer hops between the point of origin and destination. Additionally, by keeping traffic local, Canadian data avoids international networks, easing concerns related to privacy and security. Above: In Dec. 2014, TorIX traffic peaked above 140 Gbps, with average traffic hovering around 90 Gbps. Beginning Today Launched in July 1996 Direct TorIX on-ramp in Cologix’s151 Front Street Ethernet-based, layer 2 connectivity data centre in Toronto TorIX-owned switches capable of handling Second largest independent IX in North America ample traffic Operated by telecom industry volunteers IPv4 & IPv6 address provided to each peering Surpassed 145 Gbps with 175+ peering member to use on the IX participants, including the Canadian Broke the 61 Gbps mark in Jan. -

Peering Concepts and Definitions Terminology and Related Jargon
Peering Concepts and Definitions Terminology and Related Jargon Presentation Overview Brief On Peering Jargon Peering & Related Jargon BRIEF ON PEERING JARGON Brief On Peering Jargon A lot of terminologies used in the peering game. We shall look at the more common ones. Will be directly related to peering, as well as ancillary non-peering functions that support peering. PEERING & RELATED JARGON Peering & Related Jargon ASN (or AS - Autonomous System Number): . A unique number that identifies a collection/grouping of IP addresses or networks under the control of one entity on the Internet Bi-lateral (peering): . Peering relationships setup “directly” between two networks (see “Multi-lateral [peering]”). BGP (Border Gateway Protocol): . Routing protocol used on the Internet and at exchange points as the de-facto routing technique to share routing information (IPs and prefixes) between networks or between ASNs Peering & Related Jargon Carrier-neutral (data centre): . A facility where customers can purchase network services from “any” other networks within the facility. Cold-potato routing: . A situation where a network retains traffic on its network for as long as possible (see “Hot-potato routing”). Co-lo (co-location): . Typically a data centre where customers can house their network/service infrastructure. Peering & Related Jargon Dark fibre: . Fibre pairs offered by the owner, normally on a lease basis, without any equipment at each end of it to “activate” it (see “Lit fibre”). Data centre: . A purpose-built facility that provides space, power, cooling and network facilities to customers. Demarc (Demarcation): . Typically information about a co-lo customer, e.g., rack number, patch panel and port numbers, e.t.c. -

Peering Personals at TWNOG 4.0
Peering Personals at TWNOG 4.0 6 Dec. 2019 請注意, Peering Personal 場次將安排於下午時段的演講結束前進行, 請留意議程進行以 確保報告人當時在現場 Please note that Peering Personals will be done in the afternoon sessions so please check with Agenda and be on site. AS number 10133 (TPIX) and 17408 (Chief Telecom) Traffic profile Internet Exchange (Balanced) + ISP (Balanced) Traffic Volume TPIX: 160 Gbps ( https://www.tpix.net.tw/traffic.html ); Chief: 80 Gbps (2015- 10.7G; 2016- 25.9G; 2017- 58G; 2018- 96G) Peering Policy Open Peering Locations Taiwan: TPIX, Chief LY, Chief HD HK: HKIX, AMS-IX, EIE (HK1), Mega-i Europe: AMS-IX Message Biggest IX in Taiwan in both traffic and AS connected (59). Contact •[email protected] or •https://www.peeringdb.com/ix/823 •[email protected] or •https://www.peeringdb.com/net/8666 AS number 7527(JPIX) Traffic profile Internet Exchange (Balanced) Traffic Volume JPIX Tokyo 1.2T &JPIX Osaka 600G Peering Policy Open Peering Locations Tokyo: KDDI Otemachi, NTT Data Otemachi ,Comspace I, Equinix, Tokyo, AT Tokyo, COLT TDC1, NTT DATA Mitaka DC East, NTT COM Nexcenter DC, Meitetsucom DC (Nagoya),OCH DC (Okinawa), BBT New Otemachi DC Osaka: NTT Dojima Telepark, KDDI TELEHOUSE Osaka2, Equinix OS1,Meitetsucom DC (Nagoya), OBIS DC (Okayama) Site introduction: https://www.jpix.ad.jp/en/service_introduction.php Message Of connected ASN: Tokyo 211 Osaka 70 Remarks Our IX switch in Nagoya can offer both JPIX Tokyo vlan and Osaka one. Contact •[email protected] or [email protected] AS number 41095 Traffic profile 1:3 Balanced where content prevail Traffic Volume -

VAN Satellite 2019: Challenging the Status
VAN Satellite 2019 Keynote summary Session: Challenging the status quo – the Sanity story Speaker: Ray Itaoui Ray Itaoui is the son of Lebanese migrant factory workers. His parents wanted the best start for their children – so much so that Ray and his older brother were left with his grandparents in Lebanon for the first four years of his life while his parents established themselves in Australia. Ray had a strict upbringing, with a heavy focus on study. Sport was not an option. "We lived across from a park and going to play with our friends was a mission. Most times we were told no." He rebelled, started hanging out with the wrong crowd and was expelled from Sydney's Granville Boys High School in his final year. However, he was able to complete year 12 in Dubbo, where he had a long-distance relationship with a girl whose mother happened to be a teacher. Her family let Ray live with them while he attended school to complete his HSC. "That was a real pivotal point in my life,” recalls Ray. It took me out of my environment. I learnt so much about Australia, about family. It was a unique opportunity." After finishing school, he enrolled at university to study psychology but soon realised it wasn't for him. Instead, he returned to McDonald's, where he'd worked part-time when he was at school. For 13 years he stayed at McDonald's until he became a store manager. But when the promotions dried up, Ray began job hunting. In 2001, Ray joined Sanity as an area manager and worked his way up to Queensland state manager. -

The Anchor, Volume 52.06: December 7, 1938
Hope College Hope College Digital Commons The Anchor: 1938 The Anchor: 1930-1939 12-7-1938 The Anchor, Volume 52.06: December 7, 1938 Hope College Follow this and additional works at: https://digitalcommons.hope.edu/anchor_1938 Part of the Library and Information Science Commons Recommended Citation Repository citation: Hope College, "The Anchor, Volume 52.06: December 7, 1938" (1938). The Anchor: 1938. Paper 17. https://digitalcommons.hope.edu/anchor_1938/17 Published in: The Anchor, Volume 52, Issue 6, December 7, 1938. Copyright © 1938 Hope College, Holland, Michigan. This News Article is brought to you for free and open access by the The Anchor: 1930-1939 at Hope College Digital Commons. It has been accepted for inclusion in The Anchor: 1938 by an authorized administrator of Hope College Digital Commons. For more information, please contact [email protected]. Frosh in Charge of Page 3 Ijupc Calkpc Andior Frosh in Charge of Page 3 i -• Volume UI Fifty-second Year at Publication Hope College, Holland, Mich., December 7,1938 Number 6 1) Voorhees, Alcor, Jtorrjpt Student Council AS I SEE IT W.A.L. Begin • BY • Plan Announces Christmas Spirit Blase Levi! Commons Room Several Christmas parties have been planned by Women's organ- Although we have spent many Cooperating Organizations izations on campus to celebrate the a long hour of interesting "Bull holiday season. Meet To Complete Sessions" discussing that seemingly The annual Christmas party of inexhaustible riddle, "Hitlerism/' Ci Arrangements . Alcor, the senior girls' Honor Soci- we shall tackle it once again in a ety, will be celebrated tonight at slightly varied form. -

Mapping Peering Interconnections to a Facility
Mapping Peering Interconnections to a Facility Vasileios Giotsas Georgios Smaragdakis Bradley Huffaker CAIDA / UC San Diego MIT / TU Berlin CAIDA / UC San Diego [email protected] [email protected] bhuff[email protected] Matthew Luckie kc claffy University of Waikato CAIDA / UC San Diego [email protected] [email protected] ABSTRACT CCS Concepts Annotating Internet interconnections with robust phys- •Networks ! Network measurement; Physical topolo- ical coordinates at the level of a building facilitates net- gies; work management including interdomain troubleshoot- ing, but also has practical value for helping to locate Keywords points of attacks, congestion, or instability on the In- Interconnections; peering facilities; Internet mapping ternet. But, like most other aspects of Internet inter- connection, its geophysical locus is generally not pub- lic; the facility used for a given link must be inferred to 1. INTRODUCTION construct a macroscopic map of peering. We develop a Measuring and modeling the Internet topology at the methodology, called constrained facility search, to infer logical layer of network interconnection, i. e., autonomous the physical interconnection facility where an intercon- systems (AS) peering, has been an active area for nearly nection occurs among all possible candidates. We rely two decades. While AS-level mapping has been an im- on publicly available data about the presence of net- portant step to understanding the uncoordinated forma- works at different facilities, and execute traceroute mea- tion and resulting structure of the Internet, it abstracts surements from more than 8,500 available measurement a much richer Internet connectivity map. For example, servers scattered around the world to identify the tech- two networks may interconnect at multiple physical lo- nical approach used to establish an interconnection. -

Peering Tutorial APRICOT 2012 Peering Forum Jan 28, 2012 William B Norton, New Delhi, India Executive Director, Drpeering.Net
+ Peering Tutorial APRICOT 2012 Peering Forum Jan 28, 2012 William B Norton, New Delhi, India Executive Director, DrPeering.net http://DrPeering.net © 2012 DrPeering Press + Overview n Start assuming no knowledge of Internet Interconnection 1. Internet Transit 2. Internet Peering 3. The Business Case for Peering 4. The ISP Peering Playbook (selections) 5. The IX Playbook (if there is time, how IX builds critical mass) 6. The Peering Simulation Game n Finish with an understanding of how the core of the Internet is interconnected + Internet Transit – APRICOT 2012 Peering Forum Interconnection at the edge Jan 28, 2012 William B Norton, New Delhi, India Executive Director, DrPeering.net http://DrPeering.net © 2012 DrPeering Press + Overview of this section n Start assuming no knowledge n I know… many of you are very knowledgeable in this stuff n See how I explain things n These build effectively n Introduce the Global Internet Peering Ecosystem n In this context, metered Internet transit service n Measurement and pricing models n The Internet Transit Playbook + The Internet n Network of Networks n Organic from ARPANET, NSFNET n Commercialization 1994 n Planned economy n Corporate interests 1997 onward n Limited information sharing n Evolution: “Global Internet Peering Ecosystem” + The Global Internet Peering Ecosystem n Definition: The Global Internet Peering Ecosystem models the internal structure of the Internet as a set of Internet Regions (typically bound by country borders), each with its own Internet Peering Ecosystem. + The Global Internet Peering Ecosystem n Definition: An Internet Region is a portion of the Internet, usually defined by geographical boundaries (country or continent borders), in which an Internet Peering ecosystem is contained.