Statistical Forecast of Seasonal Discharge in Central Asia Using
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

O'zbekiston Respublikasi Xalq Ta'limi Vazirligi
O’ZBEKISTON RESPUBLIKASI XALQ TA’LIMI VAZIRLIGI A. QODIRIY NOMLI JIZZAX DAVLAT PEDAGOGIKA INTSITUTI TABIATSHUNOSLIK VA GEOGRAFIYA FAKULTETI GEOGRAFIYA VA UNI O’QITISH METODIKASI KAFEDRASI O’RTA OSIYO TABIIY GEOGRAFIYASI FANIDAN REFARAT MAVZU: TURON PASTTEKISLIGI. BAJARDI: 307 – GURUH TALABASI ABDULLAYEVA M QABUL QILDI: o’qituvchi: G. XOLDOROVA JIZZAX -2013 1 R E J A: Kirish I. Bob. Turon pasttekisligining tabiiy geografik tavsifi. 1.1. Geografik o’rni va rel’efi 1.2. Iqlimiy xususiyatlari. 1.3. Tuproqlari, o’simlik va hayvonot dunyosi. II. Bob. Turon pasttekisligining hududiy tavsifi. 2.1. Qizilqum va Qoraqum. 2.2. To’rg’ay Mug’ojar. 2.3. Mang’ishloq Ustyurt. Xulosa. Foydalanilgan adabiyotlar. 2 3 4 5 KIRISH. Tabiiy geografik rayonlashtirish deganda xududlarni ularni tabiiy geografik hususiyatlariga qarab turli katta-kichiklikdagi regional birliklarga ajratish tushuniladi. Tabiiy geografik rayonlashtirishda mavjud bo’lgan va taksonamik jihatdan bir-biri bilan bog’liq regional tabiiy geografik komplekislar ajratiladi, har-bir komplekis tabiatning o’ziga xos hususiyatlarini ochib beradi ular tabiatni tasvirlaydi hamda haritaga tushuriladi. Tabiiy geografik region nafaqat tabiiy sharoiti bilan balki o’ziga xos tabiiy resurslari bilan ham boshqalardan ajralib turadi. Shuning uchun tabiiy geografik rayonlashtirish har-bir hududning o’ziga xos sharoiti va reurslarini boxolashga imkon beradi. Uning ilmiy va amaliy ahamiyati, ayniqsa hozirgi vaqtda tabiatda ekologik muozanatni saqlash va ekologik muomolarni oldini olish dolzarb masala bo’lib turganda, juda kattadir. Tabiiy geografik rayonlashtirishni taksonamik birliklar sistemasi asosida amalgam oshirish mumkin. O’rta Osiyo hududini rayonlashtirish bilan ko’p olimlar shug’ulangan. Ular dastlab tarmoq tabiiy geografik; geomarfologik, iqlimiy, tuproqlar geografiyasi, geobatanik va zoogeografik rayonlashtirishga etibor berganlar. -

Water Resources Lifeblood of the Region
Water Resources Lifeblood of the Region 68 Central Asia Atlas of Natural Resources ater has long been the fundamental helped the region flourish; on the other, water, concern of Central Asia’s air, land, and biodiversity have been degraded. peoples. Few parts of the region are naturally water endowed, In this chapter, major river basins, inland seas, Wand it is unevenly distributed geographically. lakes, and reservoirs of Central Asia are presented. This scarcity has caused people to adapt in both The substantial economic and ecological benefits positive and negative ways. Vast power projects they provide are described, along with the threats and irrigation schemes have diverted most of facing them—and consequently the threats the water flow, transforming terrain, ecology, facing the economies and ecology of the country and even climate. On the one hand, powerful themselves—as a result of human activities. electrical grids and rich agricultural areas have The Amu Darya River in Karakalpakstan, Uzbekistan, with a canal (left) taking water to irrigate cotton fields.Upper right: Irrigation lifeline, Dostyk main canal in Makktaaral Rayon in South Kasakhstan Oblast, Kazakhstan. Lower right: The Charyn River in the Balkhash Lake basin, Kazakhstan. Water Resources 69 55°0'E 75°0'E 70 1:10 000 000 Central AsiaAtlas ofNaturalResources Major River Basins in Central Asia 200100 0 200 N Kilometers RUSSIAN FEDERATION 50°0'N Irty sh im 50°0'N Ish ASTANA N ura a b m Lake Zaisan E U r a KAZAKHSTAN l u s y r a S Lake Balkhash PEOPLE’S REPUBLIC Ili OF CHINA Chui Aral Sea National capital 1 International boundary S y r D a r Rivers and canals y a River basins Lake Caspian Sea BISHKEK Issyk-Kul Amu Darya UZBEKISTAN Balkhash-Alakol 40°0'N ryn KYRGYZ Na Ob-Irtysh TASHKENT REPUBLIC Syr Darya 40°0'N Ural 1 Chui-Talas AZERBAIJAN 2 Zarafshan TURKMENISTAN 2 Boundaries are not necessarily authoritative. -

Qaraqalpaq Tilinin Imla Sqzligi
QARAQALPAQ TILININ IMLA SQZLIGI Qaraqalpaqstan Respublikasi Xaliq bilimlendiriw ministrligi tarepinen tastiyiqlangan NOKIS «BILIM» 2017 Oaraaalpaq tiling imla sozlig.. Uliwma UOK: 811.512.121-35(076.3)------------- ■ S 4 bcrctug.n mektepoqiwshihn KBK: 81.2 Q ar b.um Nokis, «B.I.m» baSpaSl, Q 51 2017-jil- 348 bet. UOK: 8X1.512-121-35 (076.3) KBK: 81.2 Qar Q—51 Diiziwshiler: Madenbay Dawletov Shamshetdin Abdinazimov, Aruxan Dawletova Pikir bildiriwshiler: n.Sevdallaeva. - Filologiya ilimleriniP kandIdaiti Z. Ismaylova - Qaraqalpaqstan RespAlikasXaliq bilimlendmw ministrliginin jetekshi qanigesi. QARAQALPAQ TILININ IMLA SOZLIGI Nokis —«Bilim» — 2017 Redaktorlar S. Aytmuratova, S. Baynazarova Kork.redaktor I. Serjanov Tex. redakton B. Tunmbetov Operatorlar N. Saukieva, A. Begdullaeva Original-maketten basiwga ruqsat etilgen waqti 30.10.2017-j. Formati 60x90 '/]6. Tip «Tayms» garniturasi. Kegl 12. Ofset qagazi. Ofset baspa usilinda basildi. Kolemi 21,75 b.t. 22,6 esap b.t. Nusqasi 4000 dana. Buyirtpa № 17-677. «Bilim» baspasi. 230103. Nokis qalasi, Qaraqalpaqstan koshesi, 9. «0‘zbekiston» baspa-poligrafiyaliq doretiwshilik uyi. Tashkent, «Nawayi» koshesi, 30. © M.Dawletov ham t.b., 2017. ISBN 978-9943-4442-0-1 © «Bilim» baspasi, 2017. QARAQALPAQSTAN RESPUBLIKASI MINISTRLER KENESININ QARARl 224-san. 2016-jil 5-iyul Nokis qalasi QARAQALPAQ TILININ TIYKARGI IMLA QAGIYDALARIN TASTIYIQLAW HAQQINDA Qaraqalpaqstan Respublikasi Joqargi Kenesinin 2016-jil 10-iyunde qabil etilgen «Qaraqalpaqstan Respublikasimn ayinm nizamlanna ozgerisler ham qosimshalar kirgiziw haqqinda»gi 91/IX sanli qarann onnlaw maqsetinde Ministrler Kenesi qarar etedi: 1. Latin jaziwina tiykarlangan Qaraqalpaq tiliniri tiykargi imla qagiydalar jiynagi tastiyiqlansm. 2. Respublika ministrlikleri, vedomstvalari, jergilikli hakimiyat ham basqariw organlan, galaba xabar qurallari latin jaziwina tiykarlangan qaraqalpaq dipbesindegi barliq turdegi xat jazisiwlarda, baspasozde, is jiirgiziwde usi qagiydalardi engiziw boymsha tiyisli ilajlardi islep shiqsin ham amelge asirsm. -
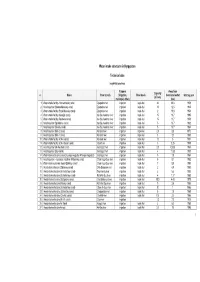
1 Water Intake Structures in Kyrgyzstan Technical Data
Water intake structures in Kyrgyzstan Technical data Issyk-Kul province Purpose Away from Capacity n Name River (canal) (irrigation, River basin river/canal outlet Start-up year (m3/sec) municipal, other) (km) 1 Water-intake facility - Komsomolsky canal Djergalan river irrigation Issyk-Kul 42 20,8 1958 2 Head regulator (Sredne-Maevsky canal) Djergalan river irrigation Issyk-Kul 10 12,5 1945 3 Water-intake facility (Staro-Maevsky canal) Djergalan river irrigation Issyk-Kul 2 19,8 1954 4 Water-intake facility (Karadjal canal) Ak-Suu-Arashan river irrigation Issyk-Kul 15 18,7 1995 5 Water-intake facility (Ppobeda canal) Ak-Suu-Arashan river irrigation Issyk-Kul 15 13,7 1959 6 Head regulator (Spiridonov canal) Ak-Suu-Arashan river irrigation Issyk-Kul 5 13,7 1932 7 Head regulator (Sovety canal) Ak-Suu-Arashan river irrigation Issyk-Kul 5 13,7 1934 8 Head regulator (M.K-2 canal) Karakol river irrigation Issyk-Kul 2,5 8,8 1970 9 Head regulator (M.K-1 canal) Karakol river irrigation Issyk-Kul 3 3,3 1965 10 Water-intake facility (M.K-6 canal) Karakol river irrigation Issyk-Kul 12 5 1957 11 Water-intake facility (M.K-4 feeder canal) Irdyk river irrigation Issyk-Kul 3 0,25 1959 12 Head regulator (Ak-Kochkor canal) Jeti-Oguz river irrigation Issyk-Kul 2,5 0,336 1954 13 Head regulator (Say canal) Jeti-Oguz river irrigation Issyk-Kul 4 11,35 1930 14 Water intake structure (canals: Levaya magistral, Pravaya magistral) Jeti-Oguz river irrigation Issyk-Kul 5 1,8 1964 15 Head regulator – automatic machine (Polyansky canal) Chon Kyzyl-Suu river irrigation -

Climate-Proofing Cooperation in the Chu and Talas River Basins
Climate-proofing cooperation in the Chu and Talas river basins Support for integrating the climate dimension into the management of the Chu and Talas River Basins as part of the Enhancing Climate Resilience and Adaptive Capacity in the Transboundary Chu-Talas Basin project, funded by the Finnish Ministry for Foreign Affairs under the FinWaterWei II Initiative Geneva 2018 The Chu and Talas river basins, shared by Kazakhstan and By way of an integrated consultative process, the Finnish the Kyrgyz Republic in Central Asia, are among the few project enabled a climate-change perspective in the design basins in Central Asia with a river basin organization, the and activities of the GEF project as a cross-cutting issue. Chu-Talas Water Commission. This Commission began to The review of climate impacts was elaborated as a thematic address emerging challenges such as climate change and, annex to the GEF Transboundary Diagnostic Analysis, to this end, in 2016 created the dedicated Working Group on which also included suggestions for adaptation measures, Adaptation to Climate Change and Long-term Programmes. many of which found their way into the Strategic Action Transboundary cooperation has been supported by the Programme resulting from the project. It has also provided United Nations Economic Commission for Europe (UNECE) the Commission and other stakeholders with cutting-edge and other partners since the early 2000s. The basins knowledge about climate scenarios, water and health in the are also part of the Global Network of Basins Working context of climate change, adaptation and its financing, as on Climate Change under the UNECE Convention on the well as modern tools for managing river basins and water Protection and Use of Transboundary Watercourses and scarcity at the national, transboundary and global levels. -

Desk-Study on Core Zone Karakoo Bioshere Reserve Issyk-Kul
Potential for strengthening the coverage of the core zone of Biosphere Reserve Issyk-Kul This project has been funded by the German Federal Ministry for the Environment, Nature Conservation, Building and Nuclear Safety with means of the Advisory Assistance Programme for Environmental Protection in the Countries of Central and Eastern Europe, the Caucasus and Central Asia. It was supervised by the Federal Agency for Nature Conservation (Bundesamt für Naturschutz, BfN) and the Federal Environment Agency (Umweltbundesamt, UBA). The content of this publication lies within the responsibility of the authors. Bishkek / Greifswald 2014 Potential for strengthening the coverage of the core zone of Biosphere Reserve Issyk-Kul prepared by: Jens Wunderlich Michael Succow Foundation for the protection of Nature Ellernholzstr. 1/3 D- 17489 Greifswald Germany Tel.: +49 3834 835414 E-Mail: [email protected] www.succow-stiftung.de/home.html Ilia Domashev, Kirilenko A.V., Shukurov E.E. BIOM 105 / 328 Abdymomunova Str. 6th Laboratory Building of Kyrgyz National University named J.Balasagyn Bishkek Kyrgyzstan E-Mail: [email protected] www.biom.kg/en Scientific consultant: Prof. Shukurov, E.Dj. front page picture: Prof. Michael Succow desert south-west of Issyk-Kul – summer 2013 Abbreviations and explanation of terms Aiyl Kyrgyz for village Akim Province governor BMZ Federal Ministry for Economic Cooperation and Development of Germany BMU Federal Ministry for the Environment, Nature Conservation, Building and Nuclear Safety of Germany BR Biosphere Reserve Court of Ak-sakal traditional way to solve conflicts. Court of Ak-sakal is elected among respected persons. It deals with small household disputes and conflicts, leading parties to agreement. -

Central Asian Rivers Under Climate Change: Impacts Assessment in Eight Representative Catchments
A Service of Leibniz-Informationszentrum econstor Wirtschaft Leibniz Information Centre Make Your Publications Visible. zbw for Economics Didovets, Iulii et al. Article — Published Version Central Asian rivers under climate change: Impacts assessment in eight representative catchments Journal of Hydrology: Regional Studies Provided in Cooperation with: Leibniz Institute of Agricultural Development in Transition Economies (IAMO), Halle (Saale) Suggested Citation: Didovets, Iulii et al. (2021) : Central Asian rivers under climate change: Impacts assessment in eight representative catchments, Journal of Hydrology: Regional Studies, ISSN 2214-5818, Elsevier, Amsterdam, Vol. 34, Iss. (Article No.:) 100779, http://dx.doi.org/10.1016/j.ejrh.2021.100779 This Version is available at: http://hdl.handle.net/10419/229441 Standard-Nutzungsbedingungen: Terms of use: Die Dokumente auf EconStor dürfen zu eigenen wissenschaftlichen Documents in EconStor may be saved and copied for your Zwecken und zum Privatgebrauch gespeichert und kopiert werden. personal and scholarly purposes. Sie dürfen die Dokumente nicht für öffentliche oder kommerzielle You are not to copy documents for public or commercial Zwecke vervielfältigen, öffentlich ausstellen, öffentlich zugänglich purposes, to exhibit the documents publicly, to make them machen, vertreiben oder anderweitig nutzen. publicly available on the internet, or to distribute or otherwise use the documents in public. Sofern die Verfasser die Dokumente unter Open-Content-Lizenzen (insbesondere CC-Lizenzen) zur -

Hydrochemical Composition and Potentially Toxic Elements in the Kyrgyzstan Portion of the Transboundary Chu-Talas River Basin, C
www.nature.com/scientificreports OPEN Hydrochemical composition and potentially toxic elements in the Kyrgyzstan portion of the transboundary Chu‑Talas river basin, Central Asia Long Ma1,2,3*, Yaoming Li1,2,3, Jilili Abuduwaili1,2,3, Salamat Abdyzhapar uulu2,4 & Wen Liu1,2,3 Water chemistry and the assessment of health risks of potentially toxic elements have important research signifcance for water resource utilization and human health. However, not enough attention has been paid to the study of surface water environments in many parts of Central Asia. Sixty water samples were collected from the transboundary river basin of Chu-Talas during periods of high and low river fow, and the hydrochemical composition, including major ions and potentially toxic elements (Zn, Pb, Cu, Cr, and As), was used to determine the status of irrigation suitability and risks to human health. The results suggest that major ions in river water throughout the entire basin are mainly afected by water–rock interactions, resulting in the dissolution and weathering of carbonate and silicate rocks. The concentrations of major ions change to some extent with diferent hydrological periods; however, the hydrochemical type of calcium carbonate remains unchanged. Based on the water-quality assessment, river water in the basin is classifed as excellent/good for irrigation. The relationship between potentially toxic elements (Zn, Pb, Cu, Cr, and As) and major ions is basically the same between periods of high and low river fow. There are signifcant diferences between the sources of potentially toxic elements (Zn, Pb, Cu, and As) and major ions; however, Cr may share the same rock source as major ions. -

Assessment of Snow, Glacier and Water Resources in Asia
IHP/HWRP-BERICHTE Heft 8 Koblenz 2009 Assessment of Snow, Glacier and Water Resources in Asia Assessment of Snow, Glacier and Water Resources in Asia Resources Water Glacier and of Snow, Assessment IHP/HWRP-Berichte • Heft 8/2009 IHP/HWRP-Berichte IHP – International Hydrological Programme of UNESCO ISSN 1614 -1180 HWRP – Hydrology and Water Resources Programme of WMO Assessment of Snow, Glacier and Water Resources in Asia Selected papers from the Workshop in Almaty, Kazakhstan, 2006 Joint Publication of UNESCO-IHP and the German IHP/HWRP National Committee edited by Ludwig N. Braun, Wilfried Hagg, Igor V. Severskiy and Gordon Young Koblenz, 2009 Deutsches IHP/HWRP - Nationalkomitee IHP – International Hydrological Programme of UNESCO HWRP – Hydrology and Water Resource Programme of WMO BfG – Bundesanstalt für Gewässerkunde, Koblenz German National Committee for the International Hydrological Programme (IHP) of UNESCO and the Hydrology and Water Resources Programme (HWRP) of WMO Koblenz 2009 © IHP/HWRP Secretariat Federal Institute of Hydrology Am Mainzer Tor 1 56068 Koblenz • Germany Telefon: +49 (0) 261/1306-5435 Telefax: +49 (0) 261/1306-5422 http://ihp.bafg.de FOREWORD III Foreword The topic of water availability and the possible effects The publication will serve as a contribution to the of climate change on water resources are of paramount 7th Phase of the International Hydrological Programme importance to the Central Asian countries. In the last (IHP 2008 – 2013) of UNESCO, which has endeavored decades, water supply security has turned out to be to address demands arising from a rapidly changing one of the major challenges for these countries. world. Several focal areas have been identified by the The supply initially ensured by snow and glaciers is IHP to address the impacts of global changes. -

Natural Recreation Potential of the West Kazakhstan Region of the Republic of Kazakhstan
GeoJournal of Tourism and Geosites Year XIII, vol. 32, no. 4, 2020, p.1355-1361 ISSN 2065-1198, E-ISSN 2065-0817 DOI 10.30892/gtg.32424-580 NATURAL RECREATION POTENTIAL OF THE WEST KAZAKHSTAN REGION OF THE REPUBLIC OF KAZAKHSTAN Bibigul CHASHINA L.N. Gumilyov Eurasian National University, Faculty of Natural Sciences, Satpayev Str., 2, 010008 Nur-Sultan, Republic of Kazakhstan, e-mail: [email protected] Nurgul RAMAZANOVA L.N. Gumilyov Eurasian National University, Faculty of Natural Sciences, Satpayev Str., 2, 010008 Nur-Sultan, Republic of Kazakhstan, e-mail: [email protected] Emin ATASOY Bursa Uludag University, 6059, Gorukle, Bursa, Turkye, e-mail: [email protected] Zharas BERDENOV* L.N. Gumilyov Eurasian National University, Faculty of Natural Sciences, Satpayev Str., 2, 010008 Nur-Sultan, Republic of Kazakhstan, e-mail: [email protected] Dorina Camelia ILIEȘ University of Oradea, Faculty of Geography, Tourism and Sport, Department of Geography, Tourism and Territorial Planning, Oradea, Romania, e-mail: [email protected] Citation: Chashina, B., Ramazanova, N., Atasoy, E., Berdenov, Zh., & Ilieș, D.C. (2020). NATURAL RECREATION POTENTIAL OF THE WEST KAZAKHSTAN REGION OF THE REPUBLIC OF KAZAKHSTAN. GeoJournal of Tourism and Geosites, 32(4), 1355–1361. https://doi.org/10.30892/gtg.32424-580 Abstract: This article is an attempt to assess the natural and recreational potential of the West Kazakhstan region. This technique consists of different stages: assessment of the territory concerning the recreational potential, according to the physical and geographi cal conditions; determination of administrative districts (units) within each of the recreational development zones; inventory of specially protected natural areas.The main criterion for the quantitative assessment was the presence of specially protected natural areas, their number and occupied area. -

The Caspian Sea Encyclopedia
Encyclopedia of Seas The Caspian Sea Encyclopedia Bearbeitet von Igor S. Zonn, Aleksey N Kosarev, Michael H. Glantz, Andrey G. Kostianoy 1. Auflage 2010. Buch. xi, 525 S. Hardcover ISBN 978 3 642 11523 3 Format (B x L): 17,8 x 25,4 cm Gewicht: 967 g Weitere Fachgebiete > Geologie, Geographie, Klima, Umwelt > Anthropogeographie > Regionalgeographie Zu Inhaltsverzeichnis schnell und portofrei erhältlich bei Die Online-Fachbuchhandlung beck-shop.de ist spezialisiert auf Fachbücher, insbesondere Recht, Steuern und Wirtschaft. Im Sortiment finden Sie alle Medien (Bücher, Zeitschriften, CDs, eBooks, etc.) aller Verlage. Ergänzt wird das Programm durch Services wie Neuerscheinungsdienst oder Zusammenstellungen von Büchern zu Sonderpreisen. Der Shop führt mehr als 8 Millionen Produkte. B Babol – a city located 25 km from the Caspian Sea on the east–west road connecting the coastal provinces of Gilan and Mazandaran. Founded in the sixteenth century, it was once a heavy-duty river port. Since the early nineteenth century, it has been one of the major cities in the province. Ruins of some ancient buildings are found here. Food and cotton ginning factories are also located here. The population is over 283 thou as of 2006. Babol – a river flowing into the Caspian Sea near Babolsar. It originates in the Savadhuk Mountains and is one of the major rivers in Iran. Its watershed is 1,630 km2, its length is 78 km, and its width is about 50–60 m at its mouth down to 100 m upstream. Its average discharge is 16 m3/s. The river receives abundant water from snowmelt and rainfall. -

Water Policy Reforms in Eastern Europe, the Caucasus and Central Asia Achievements of the European Union Water Initiative, 2006-16 September 2016
Water Policy Reforms in Eastern Europe, the Caucasus and Central Asia Achievements of the European Union Water Initiative, 2006-16 September 2016 EUWI EU WATER INITIATIVE EECCA Foreword People’s wellbeing and economic development are increasingly dependent “Ten years after the EUWI upon water. Water scarcity is already a matter of daily struggle for more than launch, we are glad to 40 percent of people around the world. Our vulnerability to water stress is and will be more and more exacerbated by climate change. Improved water see more robust national governance is therefore crucial for accommodating a growing demand policy frameworks, targeted for water in the context of important scarcities. Without efforts to rethink invesments and improved and adjust the way we manage waters, an eventual water crisis will have daunting effects, including conflicts and forced migration. water management practices in countries of Eastern Europe, The European Commission has made water governance one of the priorities of its work, including in the context of international co-operation. The Caucasus and Central Asia.” European Union’s Water Initiative (EUWI), launched in 2006, has been an important avenue for sharing experience, addressing common challenges, and identifying opportunities that would enable our partners to meet water use demands in an environmentally sustainable manner. As part of its Neighbourhood and Development policies, the EU has closely involved the countries of Eastern Europe, Caucasus and Central Asia in this initiative. The EUWI has been a political undertaking that has helped participating countries improve their legislation in the water sector through the design and the implementation of national policy reforms.