Download.Oracle.Com/Docs/Cd/B28359 01/Network.111/B28530/Asotr Ans.Htm
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Large but Finite
Department of Mathematics MathClub@WMU Michigan Epsilon Chapter of Pi Mu Epsilon Large but Finite Drake Olejniczak Department of Mathematics, WMU What is the biggest number you can imagine? Did you think of a million? a billion? a septillion? Perhaps you remembered back to the time you heard the term googol or its show-off of an older brother googolplex. Or maybe you thought of infinity. No. Surely, `infinity' is cheating. Large, finite numbers, truly monstrous numbers, arise in several areas of mathematics as well as in astronomy and computer science. For instance, Euclid defined perfect numbers as positive integers that are equal to the sum of their proper divisors. He is also credited with the discovery of the first four perfect numbers: 6, 28, 496, 8128. It may be surprising to hear that the ninth perfect number already has 37 digits, or that the thirteenth perfect number vastly exceeds the number of particles in the observable universe. However, the sequence of perfect numbers pales in comparison to some other sequences in terms of growth rate. In this talk, we will explore examples of large numbers such as Graham's number, Rayo's number, and the limits of the universe. As well, we will encounter some fast-growing sequences and functions such as the TREE sequence, the busy beaver function, and the Ackermann function. Through this, we will uncover a structure on which to compare these concepts and, hopefully, gain a sense of what it means for a number to be truly large. 4 p.m. Friday October 12 6625 Everett Tower, WMU Main Campus All are welcome! http://www.wmich.edu/mathclub/ Questions? Contact Patrick Bennett ([email protected]) . -

Velocity London 2018
Building Resilient Serverless Systems @johnchapin | symphonia.io John Chapin • Currently Partner, Symphonia • Former VP Engineering, Technical Lead • Data Engineering and Data Science teams • 20+ yrs experience in govt, healthcare, travel, and ad-tech • Intent Media, RoomKey, Meddius, SAIC, Booz Allen Agenda • What is Serverless? • Resiliency • Demo • Discussion and Questions What is Serverless? Serverless = FaaS + BaaS! • FaaS = Functions as a Service • AWS Lambda, Auth0 Webtask, Azure Functions, Google Cloud Functions, etc... • BaaS = Backend as a Service • Auth0, Amazon DynamoDB, Google Firebase, Parse, Amazon S3, etc... go.symphonia.io/what-is-serverless Serverless benefits • Cloud benefits ++ • Reduced cost • Scaling flexibility • Shorter lead time go.symphonia.io/what-is-serverless Serverless attributes • No managing of hosts or processes • Self auto-scaling and provisioning • Costs based on precise usage (down to zero!) • Performance specified in terms other than host size/count • Implicit high availability, but not disaster recovery go.symphonia.io/what-is-serverless Resiliency “Failures are a given and everything will eventually fail over time ...” –Werner Vogels (https://www.allthingsdistributed.com/2016/03/10-lessons-from-10-years-of-aws.html) K.C. Green, Gunshow #648 Werner on Embracing Failure • Systems will fail • At scale, systems will fail a lot • Embrace failure as a natural occurrence • Limit the blast radius of failures • Keep operating • Recover quickly (automate!) Failures in Serverless land • Serverless is all about using vendor-managed services. • Two classes of failures: • Application failures (your problem, your resolution) • All other failures (your problem, but not your resolution) • What happens when those vendor-managed services fail? • Or when the services used by those services fail? Mitigation through architecture • No control over resolving acute vendor failures. -

How Are the Leaders of the Most Digitally Savvy Companies
Executive Traits for Recognizing the Bountiful Opportunities Ahead CONCLUSION Author By Krishnan Ramanujam President, Business and Technology Services, Tata Consultancy Services Industries are being reordered today by the confluence of four technologies: cloud computing (which makes supercomputing power affordable even for startup firms), artificial intelligence (which ups the IQ of products, people and processes), big data and analytics (which turn operational chaos into coherency), and the internet of things (which lets us track products, people, customers, and premises around the clock/around the world). But why do so many companies ignore the transformation that is happening now around them? In their new book, MIT professors Andrew McAfee and Erik Brynjolfsson argue (as Kuhn did about scientific revolutions) that it is difficult to change long-accepted beliefs. “Existing processes, customers and suppliers, pools of expertise, and more general mindsets can all blind incumbents to things that should be obvious, such as the possibilities of new technologies that depart greatly from the status quo,” they write in Machine, Platform, Crowd: Harnessing Our Digital Future.70 It’s why “so many of the smartest and most experienced people and companies … [are] the least able to see” a transformation that they won’t escape. 70 Andrew McAfee and Erik Brynjolfsson, Machine, Platform, Crowd: Harnessing Our Digital Future (W.W. Norton & Company), published June 2017. http://books. wwnorton.com/books/Machine-Platform-Crowd/ Accessed July 28, 2017. 91 Is such blindness avoidable? I think so. To most successful companies of the last do so, senior executives need to sharpen 10 years—Apple, Amazon, and Netflix— or develop five traits that may have rapidly recognize the potential of AI and sat dormant in them, but which I think automation, cloud computing, IoT and reside in all of us. -

Grade 7/8 Math Circles the Scale of Numbers Introduction
Faculty of Mathematics Centre for Education in Waterloo, Ontario N2L 3G1 Mathematics and Computing Grade 7/8 Math Circles November 21/22/23, 2017 The Scale of Numbers Introduction Last week we quickly took a look at scientific notation, which is one way we can write down really big numbers. We can also use scientific notation to write very small numbers. 1 × 103 = 1; 000 1 × 102 = 100 1 × 101 = 10 1 × 100 = 1 1 × 10−1 = 0:1 1 × 10−2 = 0:01 1 × 10−3 = 0:001 As you can see above, every time the value of the exponent decreases, the number gets smaller by a factor of 10. This pattern continues even into negative exponent values! Another way of picturing negative exponents is as a division by a positive exponent. 1 10−6 = = 0:000001 106 In this lesson we will be looking at some famous, interesting, or important small numbers, and begin slowly working our way up to the biggest numbers ever used in mathematics! Obviously we can come up with any arbitrary number that is either extremely small or extremely large, but the purpose of this lesson is to only look at numbers with some kind of mathematical or scientific significance. 1 Extremely Small Numbers 1. Zero • Zero or `0' is the number that represents nothingness. It is the number with the smallest magnitude. • Zero only began being used as a number around the year 500. Before this, ancient mathematicians struggled with the concept of `nothing' being `something'. 2. Planck's Constant This is the smallest number that we will be looking at today other than zero. -

AWS with Corey Quinn
SED 745 Transcript EPISODE 745 [INTRODUCTION] [00:00:00] JM: Amazon Web Services changed how software engineers work. Before AWS, it was common for startups to purchase their own physical servers. AWS made server resources as accessible as an API request, and AWS has gone on to create higher-level abstractions for building applications. For the first few years of AWS, the abstractions were familiar. S3 provided distributed reliable objects storage. Elastic MapReduce provided a managed cloud Hadoop system. Kinesis provided a scalable queuing system. Amazon was providing developers with managed alternatives to complicated open source software. More recently, AWS has started to release products that are completely novel. They’re unlike anything else. A perfect example is AWS Lambda, the first function as a service platform. Other newer AWS products include Ground Station, which is a service for processing satellite data; and AWS DeepRacer, a miniature race car for developers to build and test machine learning algorithms on. As AWS has grown into new categories, the blog announcements for new services and features have started coming so frequently that is hard to keep track of it all. Corey Quinn is the author of Last Week in AWS, a popular newsletter about what is changing across Amazon Web Services. Corey joins the show today to give his perspective on the growing shifting behemoth that is Amazon Web Services as well as the other major cloud providers that have risen to prominence. Corey is the host of the Screaming in the Cloud podcast, which you should check out if you like this episode. -
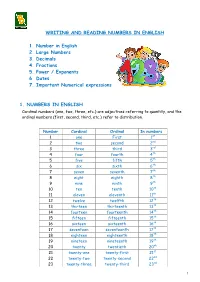
WRITING and READING NUMBERS in ENGLISH 1. Number in English 2
WRITING AND READING NUMBERS IN ENGLISH 1. Number in English 2. Large Numbers 3. Decimals 4. Fractions 5. Power / Exponents 6. Dates 7. Important Numerical expressions 1. NUMBERS IN ENGLISH Cardinal numbers (one, two, three, etc.) are adjectives referring to quantity, and the ordinal numbers (first, second, third, etc.) refer to distribution. Number Cardinal Ordinal In numbers 1 one First 1st 2 two second 2nd 3 three third 3rd 4 four fourth 4th 5 five fifth 5th 6 six sixth 6th 7 seven seventh 7th 8 eight eighth 8th 9 nine ninth 9th 10 ten tenth 10th 11 eleven eleventh 11th 12 twelve twelfth 12th 13 thirteen thirteenth 13th 14 fourteen fourteenth 14th 15 fifteen fifteenth 15th 16 sixteen sixteenth 16th 17 seventeen seventeenth 17th 18 eighteen eighteenth 18th 19 nineteen nineteenth 19th 20 twenty twentieth 20th 21 twenty-one twenty-first 21st 22 twenty-two twenty-second 22nd 23 twenty-three twenty-third 23rd 1 24 twenty-four twenty-fourth 24th 25 twenty-five twenty-fifth 25th 26 twenty-six twenty-sixth 26th 27 twenty-seven twenty-seventh 27th 28 twenty-eight twenty-eighth 28th 29 twenty-nine twenty-ninth 29th 30 thirty thirtieth 30th st 31 thirty-one thirty-first 31 40 forty fortieth 40th 50 fifty fiftieth 50th 60 sixty sixtieth 60th th 70 seventy seventieth 70 th 80 eighty eightieth 80 90 ninety ninetieth 90th 100 one hundred hundredth 100th 500 five hundred five hundredth 500th 1,000 One/ a thousandth 1000th thousand one thousand one thousand five 1500th 1,500 five hundred, hundredth or fifteen hundred 100,000 one hundred hundred thousandth 100,000th thousand 1,000,000 one million millionth 1,000,000 ◊◊ Click on the links below to practice your numbers: http://www.manythings.org/wbg/numbers-jw.html https://www.englisch-hilfen.de/en/exercises/numbers/index.php 2 We don't normally write numbers with words, but it's possible to do this. -

Simple Statements, Large Numbers
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln MAT Exam Expository Papers Math in the Middle Institute Partnership 7-2007 Simple Statements, Large Numbers Shana Streeks University of Nebraska-Lincoln Follow this and additional works at: https://digitalcommons.unl.edu/mathmidexppap Part of the Science and Mathematics Education Commons Streeks, Shana, "Simple Statements, Large Numbers" (2007). MAT Exam Expository Papers. 41. https://digitalcommons.unl.edu/mathmidexppap/41 This Article is brought to you for free and open access by the Math in the Middle Institute Partnership at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in MAT Exam Expository Papers by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Master of Arts in Teaching (MAT) Masters Exam Shana Streeks In partial fulfillment of the requirements for the Master of Arts in Teaching with a Specialization in the Teaching of Middle Level Mathematics in the Department of Mathematics. Gordon Woodward, Advisor July 2007 Simple Statements, Large Numbers Shana Streeks July 2007 Page 1 Streeks Simple Statements, Large Numbers Large numbers are numbers that are significantly larger than those ordinarily used in everyday life, as defined by Wikipedia (2007). Large numbers typically refer to large positive integers, or more generally, large positive real numbers, but may also be used in other contexts. Very large numbers often occur in fields such as mathematics, cosmology, and cryptography. Sometimes people refer to numbers as being “astronomically large”. However, it is easy to mathematically define numbers that are much larger than those even in astronomy. We are familiar with the large magnitudes, such as million or billion. -
K12 Education Leaders! on Behalf of AWS, We Are Excited for You to Join Us for AWS Re:Invent 2020!
© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved. Welcome K12 Education Leaders! On behalf of AWS, we are excited for you to join us for AWS re:Invent 2020! This year’s virtual conference is going to be the industry event of the year. It is free of charge and will offer 5 Keynotes, 18 Leadership Sessions, and unlimited access to hundreds of sessions. We are happy to have you along for the journey! To help you prepare and be ready for this 3-week event, we’ve created this guide of suggested sessions and keynotes for K12 education. This is only a starting point. There is much more content on the AWS re:Invent website. Step 1: Register for re:Invent Once you register you will be able to search all 500+ sessions. Step 2: Register for Edu Rewind AWS education has also created weekly re:Invent Rewind sessions for education organizations to discuss announcements and takeaways throughout the event. Step 3: Follow @AWS_EDU on Twitter to join the conversation. We look forward to seeing you there! Learn 500+ sessions covering core services and emerging technologies will be available at your fingertips over 3 weeks. With hours of content to comb through, our team recommends the following sessions for K12 education professionals. K12 Session Recommendations LEADERSHIP TALKS Reimagine business applications from the ground up BIZ291-L DEC 1, 2020 | 2:15 PM - 3:15 PM EST Harness the power of data with AWS Analytics ANT291-L DEC 9, 2020 | 12:15 PM - 1:15 PM EST AWS security: Where we’ve been, where we’re going SEC291-L DEC 8, 2020 -

1 Powers of Two
A. V. GERBESSIOTIS CS332-102 Spring 2020 Jan 24, 2020 Computer Science: Fundamentals Page 1 Handout 3 1 Powers of two Definition 1.1 (Powers of 2). The expression 2n means the multiplication of n twos. Therefore, 22 = 2 · 2 is a 4, 28 = 2 · 2 · 2 · 2 · 2 · 2 · 2 · 2 is 256, and 210 = 1024. Moreover, 21 = 2 and 20 = 1. Several times one might write 2 ∗ ∗n or 2ˆn for 2n (ˆ is the hat/caret symbol usually co-located with the numeric-6 keyboard key). Prefix Name Multiplier d deca 101 = 10 h hecto 102 = 100 3 Power Value k kilo 10 = 1000 6 0 M mega 10 2 1 9 1 G giga 10 2 2 12 4 T tera 10 2 16 P peta 1015 8 2 256 E exa 1018 210 1024 d deci 10−1 216 65536 c centi 10−2 Prefix Name Multiplier 220 1048576 m milli 10−3 Ki kibi or kilobinary 210 − 230 1073741824 m micro 10 6 Mi mebi or megabinary 220 40 n nano 10−9 Gi gibi or gigabinary 230 2 1099511627776 −12 40 250 1125899906842624 p pico 10 Ti tebi or terabinary 2 f femto 10−15 Pi pebi or petabinary 250 Figure 1: Powers of two Figure 2: SI system prefixes Figure 3: SI binary prefixes Definition 1.2 (Properties of powers). • (Multiplication.) 2m · 2n = 2m 2n = 2m+n. (Dot · optional.) • (Division.) 2m=2n = 2m−n. (The symbol = is the slash symbol) • (Exponentiation.) (2m)n = 2m·n. Example 1.1 (Approximations for 210 and 220 and 230). -

Big Numbers Tom Davis [email protected] September 21, 2011
Big Numbers Tom Davis [email protected] http://www.geometer.org/mathcircles September 21, 2011 1 Introduction The problem is that we tend to live among the set of puny integers and generally ignore the vast infinitude of larger ones. How trite and limiting our view! — P.D. Schumer It seems that most children at some age get interested in large numbers. “What comes after a thousand? After a million? After a billion?”, et cetera, are common questions. Obviously there is no limit; whatever number you name, a larger one can be obtained simply by adding one. But what is interesting is just how large a number can be expressed in a fairly compact way. Using the standard arithmetic operations (addition, subtraction, multiplication, division and exponentia- tion), what is the largest number you can make using three copies of the digit “9”? It’s pretty clear we should just stick to exponents, and given that, here are some possibilities: 999, 999, 9 999, and 99 . 9 9 Already we need to be a little careful with the final one: 99 . Does this mean: (99)9 or 9(9 )? Since (99)9 = 981 this interpretation would gain us very little. If this were the standard definition, then why c not write ab as abc? Because of this, a tower of exponents is always interpreted as being evaluated from d d c c c (c ) right to left. In other words, ab = a(b ), ab = a(b ), et cetera. 9 With this definition of towers of exponents, it is clear that 99 is the best we can do. -

World Happiness REPORT Edited by John Helliwell, Richard Layard and Jeffrey Sachs World Happiness Report Edited by John Helliwell, Richard Layard and Jeffrey Sachs
World Happiness REPORT Edited by John Helliwell, Richard Layard and Jeffrey Sachs World Happiness reporT edited by John Helliwell, richard layard and Jeffrey sachs Table of ConTenTs 1. Introduction ParT I 2. The state of World Happiness 3. The Causes of Happiness and Misery 4. some Policy Implications references to Chapters 1-4 ParT II 5. Case study: bhutan 6. Case study: ons 7. Case study: oeCd 65409_Earth_Chapter1v2.indd 1 4/30/12 3:46 PM Part I. Chapter 1. InTrodUCTIon JEFFREY SACHS 2 Jeffrey D. Sachs: director, The earth Institute, Columbia University 65409_Earth_Chapter1v2.indd 2 4/30/12 3:46 PM World Happiness reporT We live in an age of stark contradictions. The world enjoys technologies of unimaginable sophistication; yet has at least one billion people without enough to eat each day. The world economy is propelled to soaring new heights of productivity through ongoing technological and organizational advance; yet is relentlessly destroying the natural environment in the process. Countries achieve great progress in economic development as conventionally measured; yet along the way succumb to new crises of obesity, smoking, diabetes, depression, and other ills of modern life. 1 These contradictions would not come as a shock to the greatest sages of humanity, including Aristotle and the Buddha. The sages taught humanity, time and again, that material gain alone will not fulfi ll our deepest needs. Material life must be harnessed to meet these human needs, most importantly to promote the end of suffering, social justice, and the attainment of happiness. The challenge is real for all parts of the world. -
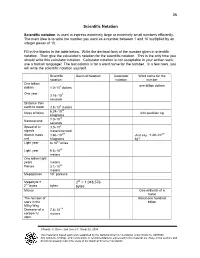
36 Scientific Notation
36 Scientific Notation Scientific notation is used to express extremely large or extremely small numbers efficiently. The main idea is to write the number you want as a number between 1 and 10 multiplied by an integer power of 10. Fill in the blanks in the table below. Write the decimal form of the number given in scientific notation. Then give the calculator’s notation for the scientific notation. This is the only time you should write this calculator notation. Calculator notation is not acceptable in your written work; use a human language! The last column is for a word name for the number. In a few rows, you will write the scientific notation yourself. Scientific Decimal Notation Calculator Word name for the notation notation number One billion one billion dollars dollars 1.0 ×10 9 dollars One year 3.16 ×10 7 seconds Distance from earth to moon 3.8 ×10 8 meters 6.24 ×10 23 Mass of Mars 624 sextillion kg kilograms 1.0 ×10 -9 Nanosecond seconds 8 Speed of tv 3.0 ×10 signals meters/second -27 -27 Atomic mass 1.66 ×10 Just say, “1.66 ×10 unit kilograms kg”! × 12 Light year 6 10 miles 15 Light year 9.5 ×10 meters One billion light years meters 16 Parsec 3.1 ×10 meters 6 Megaparsec 10 parsecs Megabyte = 220 = 1,048,576 20 2 bytes bytes bytes Micron One millionth of a meter The number of About one hundred stars in the billion Milky Way -14 Diameter of a 7.5 ×10 carbon-12 meters atom Rosalie A.