Ukrainian Participles Formation by the Generative Grammars Use
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Russian Grammar 1 Russian Grammar
Russian grammar 1 Russian grammar Russian grammar (Russian: грамматика русского языка, IPA: [ɡrɐˈmatʲɪkə ˈruskəvə jɪzɨˈka]; also русская грамматика; IPA: [ˈruskəjə ɡrɐˈmatʲɪkə]) encompasses: • a highly inflexional morphology • a syntax that, for the literary language, is the conscious fusion of three elements: • a Church Slavonic inheritance; • a Western European style; • a polished vernacular foundation. The Russian language has preserved an Indo-European inflexional structure, although considerable adaption has taken place. The spoken language has been influenced by the literary one, but it continues to preserve some characteristic forms. Russian dialects show various non-standard grammatical features, some of which are archaisms or descendants of old forms discarded by the literary language. NOTE: In the discussion below, various terms are used in the meaning they have in standard Russian discussions of historical grammar. In particular, aorist, imperfect, etc. are considered verbal tenses rather than aspects, because ancient examples of them are attested for both perfective and imperfective verbs. Nouns Nominal declension is subject to six cases – nominative, genitive, dative, accusative, instrumental, and prepositional – in two numbers (singular and plural), and absolutely obeying grammatical gender (masculine, feminine, and neuter). Up to ten additional cases are identified in linguistics textbooks,[1][2][3] although all of them are either incomplete (do not apply to all nouns) or degenerate (appear identical to one of the six simple cases). The most recognized additional cases are locative (в лесу, в крови, в слезах), partitive (чаю, сахару, коньяку), and several forms of vocative (Господи, Боже, отче). The adjectives, pronouns, and the first two cardinal numbers further vary by gender. -

Logical Semantics Approach for Data Modeling in XBRL Taxonomies
Logical Semantics Approach for Data Modeling in XBRL Taxonomies Olga Danilevitch [0000-0002-7444-0637] Belarusian State Economic University, Scientific and Research Laboratory for Tax Studies and Tax Policies, Partizanski Ave, 26, Minsk, 220070, Republic of Belarus Nonprofit information and research organization «Digital Standards of Data Transformation "XBRL BY", Belskogo str, 15, Minsk, 220092, Republic of Belarus [email protected] Abstract. The contemporary world of human beings is as connected as ever providing for the integration, interdependence and interoperability of various in- dustries and areas of expertise. The World Wide Web enabled by the Internet became a systematic means of communication by use of conventional symbols that represent a language tool. As any language tool, it has two major constructs - syntax and semantics. The syntax of a language defines its surface form. The well-developed, standardized and agreed upon Syntactic Web allows humans to seamlessly send and receive information in a digital form from virtually every- where in the world. The role of the Semantic Web is to make this information unambiguously understood by both humans and machines. It represents a chal- lenge. Despite the fact that the scientists are equipped with a plethora of methods the Semantic Web remains quite untamed. In this PhD proposal, we suggest the logical semantics approach to the Semantic Data modeling that would allow both analytic and synthetic native language users to build successful Semantic Data Models for an XBRL taxonomy. The perfect datasets to test this approach are generated at the cross-section of multidisciplinary areas of expertise: financial reporting, applied linguistics, natural language processing and computer science. -

A Language for Knowledge Representation
l�{ A Language for Knowledge Representation Yukio Nakamura, INFOSTA-NIPDOK, Japan Abstract: A language for the representation of pieces of knowledge is proposed as an extension of subject representation used in document retrieval scheme hitherto used. Main features are the use of case-representation and modifying symbols for noun descriptors as well as the intro-duction of verb-descriptors with tense and modifYing symbols. Beside usual AND and OR operators, some new operators are introduced to show ontological relations. Some examples afknowledge representation is appended. 1. Subject expression In documentation works we have dealed with a subject of a document, not withstanding the size of the document. A subject is a substitute or a re presentative of the document. In dealing with pieces of knowledge, however, a representative of the piece of knowledge must be treated differently from the "subject" of a document. The pieces of knowledge are simple and short comparing with a document. A piece of knowledge does not need a subject representation but a direct description of this piece itself is enough. Then, what is required for the description of knowledge? The subject was and is traditionally described by a noun phrase and without a verb. This was justified by the fact that verbs can be transformed into noun form by using mostly participles in Western languages. Is this applicable in the case of knowledge? In knowledge description, we need to describe some kind of change in matter or in state, that is to say an action, or a concept of change. To represent such changes, the use Qfverbs is very natural. -

Linguistic Competence of Five and Six Year Olds: Analysis
LINGUISTIC COMPETENCE OF FIVE AND SIX YEAR OLDS: ANALYSIS OF NARRATIVE SAMPLES OF RUSSIAN, ENGLISH AND RUSSIAN- ENGLISH BILINGUAL SPEAKERS by ELLINA D. CHERNOBILSKY A dissertation submitted to the Graduate School - New Brunswick Rutgers, The State University of New Jersey, in partial fulfillment of the requirements for the degree of Doctor of Philosophy Graduate program in Education written under the direction of Lorraine McCune and approved by ________________________________ ________________________________ ________________________________ ________________________________ New Brunswick, New Jersey May 2009 ABSTRACT OF THE DISSERTATION Linguistic competence of five and six year olds: analysis of narrative samples of Russian, English and Russian-English bilingual speakers by ELLINA D. CHERNOBILSKY Dissertation director Lorraine McCune To what extent do children developing bilingually show similar grammatical development to their monolingual peers? This study considers overall grammatical development in Russian and English for Russian and English monolingual children and bilingual children at entry to school. The Index of Productive Syntax (IPSyn) was revised and piloted in preparation for this cross- linguistic project. The study evaluates the utility of the revised IPSyn and its potential for studying larger samples of children. The main question of the study is whether bilingual speakers, exposed to both languages from an early age, are as competent users of their two languages as are their peers who speak a single language at the time they are entering school. The results indicated that statistically, there was no difference between the monolingual and bilingual speakers in their common language as measured by the IPSyn proportionate scores. When examining various categories in the IPSyn measure, the comparison results indicated that in general, bilingual children, as a group, perform as well, and in some categories, better that the monolingual ii children in either language. -
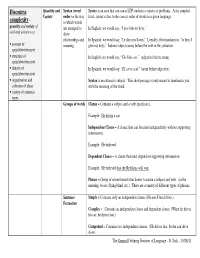
Discourse Complexity –
Discourse Quantity and Syntax (word Syntax is an area that can cause LEP students a variety of problems. At its simplest Variety order) = the way level, syntax refers to the correct order of words in a given language. complexity – in which words quantity and variety of are arranged to In English, we would say, “I give him my keys.” oral and written text. show relationships and In Spanish, we would say, “Le doy mis llaves.” Literally, this translates to, “to him, I • amount of meaning. give my keys.” Indirect object comes before the verb in this situation. speech/written text • structure of In English, we would say, “The blue car.” (adjective before noun). speech/written text • density of In Spanish, we would say, “El carro azul.” (noun before adjective). speech/written text • organization and Syntax is an extensive subject. This short passage is only meant to familiarize you cohesion of ideas with the meaning of the word. • variety of sentence types. Groups of words Clause = Contains a subject and a verb (predicate). Example: He drives a car. Independent Clause – A clause that can function independently without supporting information. Example: He believed. Dependent Clause – A clause that must depend on supporting information. Example: He believed that the Redskins will win. Phrase = Group of related words that doesn’t contain a subject and verb. (in the morning, to see, flying blind, etc.). There are a variety of different types of phrases. Sentence Simple = Contains only an independent clause. (He eats French fries.). Formation Complex = Contains an independent clause and dependent clause. (When he drives his car, he drives fast.) Compound = Contains two independent clauses. -

English-K'iche' Dictionary
ENGLISH-K'ICHE' DICTIONARY A reveral of the K'iche'-English Dictionary by Allen J. Christenson Bringham Young Univeristy available at: http://www.famsi.org/mayawriting/dictionary/christenson/quidic_complete.pdf Introduction Allen J. Christenson prepared the K'iche'-English Dictionary while conducting field work in highland Maya linguistics and ethnography from 1978-1985. He elicited his entries through collaboration with native K'iche' speakers in the communities of Momostenango (as well as its dependent aldeas of Canquixaja, Nimsitu, and Panca) and Totonicapan (and its dependent aldeas of Nimasak and Cerro de Oro). The dictionary is unpublished and is offered to FAMSI as a tool for research. It is available at: http://www.famsi.org/mayawriting/dictionary/christenson/quidic_complete.pdf In 2006, Richard Renner discovered the dictionary from the link at: http://en.wikipedia.org/wiki/K%27iche%27_language He reversed Christenson's K'iche'-English Dictionary, separating the English definitions into separate entries, and then recombining identical Engish entries that came from different K'iche' entries. It is also offered as a tool for research, and also for those Guatemalans and North Americans who want to better understand each other. Notes on usage: 1. As with any translation dictionary, it is best to check a word on both sides before using it. That is, if you look up an English word to find a K'iche' word with the same meaning, it is best to check that K'iche' word on Christenson's original K'iche'-Engish Dictionary. This is especially true for Engish homonyms (words with different unrelated meanings; or different words with the same spelling), such as duck, lead and spring. -

Action Planning Based on Open Knowledge Graphs and LOD
Action Planning based on Open Knowledge Graphs and LOD Seiji Koide1, Fumihiro Kato1, Hideaki Takeda12, Yuta Ochiai3, and Kenki Ueda3 1 National Institute of Informatics, 2-1-2 Hitotsubashi, Chiyoda-ku, Tokyo 101-8430, Japan, [email protected], WWW home page: http://www-kasm.nii.ac.jp/~takeda/index.html 2 SOKENDAI (The Graduate University for Advanced Studies) 3 Toyota Motor Corporation Abstract. In this preliminary report, we show how action planning is realized by using LOD datasets, e.g., Linked Geo Data, DBpedia, Word- Net, etc. To make a recommendation for car drivers and passengers, we combine these existing open datasets with newly constructed ontologies of facilities and services. We develop the inference procedure to translate user requests into SPARQL queries to obtain a recommendation on ap- propriate facilities for users. Common sense knowledge is also required in the reasoning process. Keywords: DBpedia, LinkedGeoData, Knowledge-based system 1 Introduction While Linked Data is now gradually growing to be the infrastructure of coming Knowledge Society, we are still struggling to show the potential of Linked Data to most people in the society including basic industries. To cope with this sit- uation and propel the deployment of Semantic Web technology, it is needed to demonstrate the performance of linking distinct datasets and show the usefulness of outbound and inbound linking data beyond enterprise data in diverse applica- tions. Yet there is no linking data among large linked datasets such as DBpedia, Freebase, and OpenCyc from the viewpoint of LOD applications, although each collection of them are a kind of isolated showcase of LOD with internally linked data within their own territories and objectives. -

Download Second Person Singular 1St Edition Free Ebook
SECOND PERSON SINGULAR 1ST EDITION DOWNLOAD FREE BOOK Sayed Kashua | --- | --- | --- | 9780802194640 | --- | --- 1st, 2nd, 3rd person plural Put in simple colloquial English, first person is that which includes the speaker, namely, "I", "we", "me", and "us", second person is the person or people spoken to, literally, "you", and third Second Person Singular 1st edition includes all that is not listed above. Works on all your favorite websites. However, the narrator is omniscient, which means that they know what the characters are thinking. These are also the terms used to distinguish the personal pronouns. You will also find second-person narration used in the "Choose Your Own Adventure" style of books popular with younger readers, in which readers determine where the story goes by which page they turn to next. Get real-time suggestions wherever you write. Jump to Navigation. Your writing, at its best. From Wikipedia, the free encyclopedia. Singular first-person pronouns include I, me, my, mine and myself. Rowling utilizes third-person limited narration in the Harry Potter novels. Is you second person? Finally a local, enervated by graffiti, shuffles into the station. Grammar from the Human Perspective: Case, space and person in Finnish. As Second Person Singular 1st edition Amazon Associate and a Bookshop. Writing an important email? This article needs additional citations for verification. But here you are, and you cannot say that the terrain is entirely unfamiliar, although the details are fuzzy. Update Required To play the media you will need to either update your browser to a recent version or update your Flash plugin. Third-person neuter and inanimate singular. -

K'iche'-English Dictionary Was Compiled by Allen J
K’ICHE’ - ENGLISH DICTIONARY and GUIDE TO PRONUNCIATION OF THE K’ICHE’-MAYA ALPHABET Allen J. Christenson Brigham Young University FORWARD The following K'iche'-English dictionary was compiled by Allen J. Christenson while conducting field work in highland Maya linguistics and ethnography from 1978-1985. All of the entries were elicited through collaboration with native K'iche' speakers in the communities of Momostenango (as well as its dependent aldeas of Canquixaja, Nimsitu, and Panca) and Totonicapan (and its dependent aldeas of Nimasak and Cerro de Oro). The dictionary is unpublished and is offered to FAMSI as a tool for research. GUIDE TO PRONUNCIATION OF THE K’ICHE’-MAYA ALPHABET In 1986 the Guatemalan Ministry of Public Education set up a commission to standardize alphabets for the twenty-one recognized highland Maya languages. This standardization effort had become particularly important due to the Guatemalan government’s proposed “Program of Bilingual Education” in Mayan communities, designed to improve literacy and promote native American cultures and languages. This program included the publication of bilingual dictionaries, school textbooks, and official translations of the Guatemalan Constitution in the various highland Maya languages. The results of this commission were officially endorsed by the Guatemalan government and signed into law as Governmental Decree Number 1046-87 by President Marco Vinicio Cerezo Arévalo on November 23, 1987. The following is a list of the modified Latin letters developed by Parra in the sixteenth century as used in the Popol Vuh text, along with the modern orthographic equivalents and a guide to pronunciation: Parra Modern a, aa a As in the a of “father.” a ä As in the o of “mother.” b b' Similar to the English b, but pronounced with the throat closed while air is forcefully expelled to produce a glottal stop. -

The Linguistic Integration of Adult Migrants / L’Intégration Linguistique Des Migrants Adultes
The Linguistic Integration of Adult Migrants / L’intégration linguistique des migrants adultes The Linguistic Integration of Adult Migrants L’intégration linguistique des migrants adultes Some Lessons from Research / Les enseignements de la recherche Edited by / édité par Jean-Claude Beacco, Hans-Jürgen Krumm, David Little, Philia Thalgott on behalf of / pour le compte du Council of Europe / Conseil de l’Europe ISBN 978-3-11-047747-4 e-ISBN (PDF) 978-3-11-047749-8 e-ISBN (EPUB) 978-3-11-047758-0 This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs 3.0 License. For details go to http://creativecommons.org/licenses/by-nc-nd/3.0/. Library of Congress Cataloging-in-Publication Data A CIP catalog record for this book has been applied for at the Library of Congress. Bibliographic information published by the Deutsche Nationalbibliothek The Deutsche Nationalbibliothek lists this publication in the Deutsche Nationalbibliografie; detailed bibliographic data are available on the Internet at http://dnb.dnb.de. © 2017 Jean-Claude Beacco, Hans-Jürgen Krumm, David Little, Philia Thalgott, Council of Europe, published by Walter de Gruyter GmbH, Berlin/Boston The book is published with open access at www.degruyter.com. Printing and binding: CPI books GmbH, Leck ♾ Printed on acid-free paper Printed in Germany www.degruyter.com Philia Thalgott Foreword The Council of Europe (47memberStates,based in Strasbourg) has been work- ing on migration-related issuesfor over four decades, and has affirmed the im- portance of education for migrants in nearly30recommendations and resolu- tions from its CommitteeofMinisters and its Parliamentary Assembly, includingConventions. The Council of Europe’snew project on the Linguistic Integration of Adult Migrants (LIAM) aims to support memberStatesinthe development of policy and practice basedonaclear recognition of adultmigrants’ human rights. -
English Usage(Vistamind)
Basic Learning Material English Usage BMM10304 www.vistamind.in Basic Learning Material English Usage BMM10304 www.vistamind.in Second Edition 2013 Copyright: All rights reserved. No part of this publication can be reproduced in any form or by any means without the prior written permission of the publishers. Published by VistaMind Education Pvt. Ltd., 2nd Floor, G. K. Shivaswami Copmlex, No. 861, 80 Feet Peripheral Road, 8th Block, Koramangala, Bangalore, Karnataka, India - 560095 Contact No.: 080-41239125 Email Address: [email protected] Web: www.vistamind.in Content Chapter 1 Introduction 1 Chapter 2 Subject Verb Agreement 8 Chapter 3 Verb Tense 16 Chapter 4 Pronouns 22 Chapter 5 Misplaced Modifiers 26 Chapter 6 Parallelism in Structure 32 Chapter 7 Symmetry in Two Part Sentences 35 Chapter 8 Comparing Apples and Oranges 41 Chapter 9 Appropriate Prepositions 44 Chapter 10 Correlative Conjunctions 48 Chapter 11 Choice of Words 51 Chapter 12 Word order 56 Chapter 13 Quantity Words 59 Chapter 14 Redundancy 62 Chapter 15 Subjunctive Mood 64 Chapter 16 Special Types of Sentences 67 Chapter 17 Miscellaneous Types 69 Chapter 18 Exercises 74 Introduction The Section of Verbal Ability in CAT tests your grasp of English grammar, English syntax and English diction through 15 questions featured in its English section. These questions do not occur as a single group in the CAT, but are interspersed among questions on Reading Comprehension and Logical Reasoning. The directions for this type of questions read as follows: “ In each of the following sentences, some part of the sentence or the entire sentence is underlined. -

Tense and Mood in Persian and English: a Contrastive and Error Analyses
TENSE AND MOOD IN PERSIAN AND ENGLISH: A CONTRASTIVE AND ERROR ANALYSES NEZAM EMADI THESIS SUBMITTED IN FULFILMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY FACULTY OF LANGUAGES AND LINGUISTICS UNIVERSITY OF MALAYA KUALA LUMPUR 2013 UNIVERSITI MALAYA ORIGINAL LITERARY WORK DECLARATION Name of Candidate: (I.C/Passport No: ) Registration/Matric No: Name of Degree: Title of Project Paper/Research Report/Dissertation/Thesis (“this Work”): Field of Study: I do solemnly and sincerely declare that: (1) I am the sole author/writer of this Work; (2) This Work is original; (3) Any use of any work in which copyright exists was done by way of fair dealing and for permitted purposes and any excerpt or extract from, or reference to or reproduction of any copyright work has been disclosed expressly and sufficiently and the title of the Work and its authorship have been acknowledged in this Work; (4) I do not have any actual knowledge nor do I ought reasonably to know that the making of this work constitutes an infringement of any copyright work; (5) I hereby assign all and every rights in the copyright to this Work to the University of Malaya (“UM”), who henceforth shall be owner of the copyright in this Work and that any reproduction or use in any form or by any means whatsoever is prohibited without the written consent of UM having been first had and obtained; (6) I am fully aware that if in the course of making this Work I have infringed any copyright whether intentionally or otherwise, I may be subject to legal action or any other action as may be determined by UM.