Article Reference
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
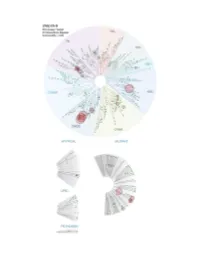
Profiling Data
Compound Name DiscoveRx Gene Symbol Entrez Gene Percent Compound Symbol Control Concentration (nM) JNK-IN-8 AAK1 AAK1 69 1000 JNK-IN-8 ABL1(E255K)-phosphorylated ABL1 100 1000 JNK-IN-8 ABL1(F317I)-nonphosphorylated ABL1 87 1000 JNK-IN-8 ABL1(F317I)-phosphorylated ABL1 100 1000 JNK-IN-8 ABL1(F317L)-nonphosphorylated ABL1 65 1000 JNK-IN-8 ABL1(F317L)-phosphorylated ABL1 61 1000 JNK-IN-8 ABL1(H396P)-nonphosphorylated ABL1 42 1000 JNK-IN-8 ABL1(H396P)-phosphorylated ABL1 60 1000 JNK-IN-8 ABL1(M351T)-phosphorylated ABL1 81 1000 JNK-IN-8 ABL1(Q252H)-nonphosphorylated ABL1 100 1000 JNK-IN-8 ABL1(Q252H)-phosphorylated ABL1 56 1000 JNK-IN-8 ABL1(T315I)-nonphosphorylated ABL1 100 1000 JNK-IN-8 ABL1(T315I)-phosphorylated ABL1 92 1000 JNK-IN-8 ABL1(Y253F)-phosphorylated ABL1 71 1000 JNK-IN-8 ABL1-nonphosphorylated ABL1 97 1000 JNK-IN-8 ABL1-phosphorylated ABL1 100 1000 JNK-IN-8 ABL2 ABL2 97 1000 JNK-IN-8 ACVR1 ACVR1 100 1000 JNK-IN-8 ACVR1B ACVR1B 88 1000 JNK-IN-8 ACVR2A ACVR2A 100 1000 JNK-IN-8 ACVR2B ACVR2B 100 1000 JNK-IN-8 ACVRL1 ACVRL1 96 1000 JNK-IN-8 ADCK3 CABC1 100 1000 JNK-IN-8 ADCK4 ADCK4 93 1000 JNK-IN-8 AKT1 AKT1 100 1000 JNK-IN-8 AKT2 AKT2 100 1000 JNK-IN-8 AKT3 AKT3 100 1000 JNK-IN-8 ALK ALK 85 1000 JNK-IN-8 AMPK-alpha1 PRKAA1 100 1000 JNK-IN-8 AMPK-alpha2 PRKAA2 84 1000 JNK-IN-8 ANKK1 ANKK1 75 1000 JNK-IN-8 ARK5 NUAK1 100 1000 JNK-IN-8 ASK1 MAP3K5 100 1000 JNK-IN-8 ASK2 MAP3K6 93 1000 JNK-IN-8 AURKA AURKA 100 1000 JNK-IN-8 AURKA AURKA 84 1000 JNK-IN-8 AURKB AURKB 83 1000 JNK-IN-8 AURKB AURKB 96 1000 JNK-IN-8 AURKC AURKC 95 1000 JNK-IN-8 -

Application of a MYC Degradation
SCIENCE SIGNALING | RESEARCH ARTICLE CANCER Copyright © 2019 The Authors, some rights reserved; Application of a MYC degradation screen identifies exclusive licensee American Association sensitivity to CDK9 inhibitors in KRAS-mutant for the Advancement of Science. No claim pancreatic cancer to original U.S. Devon R. Blake1, Angelina V. Vaseva2, Richard G. Hodge2, McKenzie P. Kline3, Thomas S. K. Gilbert1,4, Government Works Vikas Tyagi5, Daowei Huang5, Gabrielle C. Whiten5, Jacob E. Larson5, Xiaodong Wang2,5, Kenneth H. Pearce5, Laura E. Herring1,4, Lee M. Graves1,2,4, Stephen V. Frye2,5, Michael J. Emanuele1,2, Adrienne D. Cox1,2,6, Channing J. Der1,2* Stabilization of the MYC oncoprotein by KRAS signaling critically promotes the growth of pancreatic ductal adeno- carcinoma (PDAC). Thus, understanding how MYC protein stability is regulated may lead to effective therapies. Here, we used a previously developed, flow cytometry–based assay that screened a library of >800 protein kinase inhibitors and identified compounds that promoted either the stability or degradation of MYC in a KRAS-mutant PDAC cell line. We validated compounds that stabilized or destabilized MYC and then focused on one compound, Downloaded from UNC10112785, that induced the substantial loss of MYC protein in both two-dimensional (2D) and 3D cell cultures. We determined that this compound is a potent CDK9 inhibitor with a previously uncharacterized scaffold, caused MYC loss through both transcriptional and posttranslational mechanisms, and suppresses PDAC anchorage- dependent and anchorage-independent growth. We discovered that CDK9 enhanced MYC protein stability 62 through a previously unknown, KRAS-independent mechanism involving direct phosphorylation of MYC at Ser . -

Genome-Wide DNA Methylation Analysis of KRAS Mutant Cell Lines Ben Yi Tew1,5, Joel K
www.nature.com/scientificreports OPEN Genome-wide DNA methylation analysis of KRAS mutant cell lines Ben Yi Tew1,5, Joel K. Durand2,5, Kirsten L. Bryant2, Tikvah K. Hayes2, Sen Peng3, Nhan L. Tran4, Gerald C. Gooden1, David N. Buckley1, Channing J. Der2, Albert S. Baldwin2 ✉ & Bodour Salhia1 ✉ Oncogenic RAS mutations are associated with DNA methylation changes that alter gene expression to drive cancer. Recent studies suggest that DNA methylation changes may be stochastic in nature, while other groups propose distinct signaling pathways responsible for aberrant methylation. Better understanding of DNA methylation events associated with oncogenic KRAS expression could enhance therapeutic approaches. Here we analyzed the basal CpG methylation of 11 KRAS-mutant and dependent pancreatic cancer cell lines and observed strikingly similar methylation patterns. KRAS knockdown resulted in unique methylation changes with limited overlap between each cell line. In KRAS-mutant Pa16C pancreatic cancer cells, while KRAS knockdown resulted in over 8,000 diferentially methylated (DM) CpGs, treatment with the ERK1/2-selective inhibitor SCH772984 showed less than 40 DM CpGs, suggesting that ERK is not a broadly active driver of KRAS-associated DNA methylation. KRAS G12V overexpression in an isogenic lung model reveals >50,600 DM CpGs compared to non-transformed controls. In lung and pancreatic cells, gene ontology analyses of DM promoters show an enrichment for genes involved in diferentiation and development. Taken all together, KRAS-mediated DNA methylation are stochastic and independent of canonical downstream efector signaling. These epigenetically altered genes associated with KRAS expression could represent potential therapeutic targets in KRAS-driven cancer. Activating KRAS mutations can be found in nearly 25 percent of all cancers1. -

Detection of Genetic Variations of Five MMAF-Related Genes and Their
Detection of genetic variations of ve MMAF-related genes and their associations with litter size in goat Zhen Wang Northwest Agriculture and Forestry University Yun Pan Northwest Agriculture and Forestry University Libang He Northwest Agriculture and Forestry University Hong Chen Northwest Agriculture and Forestry University Chuanying Pan Northwest Agriculture and Forestry University Lei Qu Yulin University Xiaoyue Song Yulin University Xianyong Lan ( [email protected] ) https://orcid.org/0000-0003-2254-5805 Research article Keywords: goats; insertion/deletion (indel); MMAF; DNAH1; litter sizes; correlation analysis Posted Date: September 12th, 2019 DOI: https://doi.org/10.21203/rs.2.14419/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Page 1/13 Abstract Background: Multiple morphological abnormalities of the sperm agella (MMAF) makes an assignable contribution to male infertility, including QRICH2 , CFAP43 , CFAP44 , CFAP69 , CCDC39 , AKAP4 and DNAH1 gene. This work studied 28 putative indel mutations of MMAF related genes including QRICH2 , CFAP69 , CFAP43 , CCDC39 and DNAH1 gene and their correlation with the rst-born litter sizes of 769 Shaanbei white cashmere (SBWC) goats. Results: Electrophoresis and DNA sequencing analysis showed the 11-bp indel within QRICH2 ( QRICH2 -P4), the three indel variations in CFAP69 ( CFAP69 -P4, CFAP69 - P6 and CFAP69 -P7) and the 27-bp indel of DNAH1 ( DNAH1 -P1) were found to be polymorphic. The 27- bp indel variation within DNAH1 was not in consistent with HWE and the other four indel of QRICH2 and CFAP69 were in consistent with HWE. The linkage disequilibrium (LD) analysis showed the 8-bp indel ( CFAP69 -P4) and the 6-bp indel ( CFAP69- P6) within CFAP69 were in complete LD with each other (D'=0.99, r 2 =1.00). -

HEY1 Functions Are Regulated by Its Phosphorylation at Ser-68
Biosci. Rep. (2016) / 36 / art:e00343 / doi 10.1042/BSR20160123 HEY1 functions are regulated by its phosphorylation at Ser-68 Irene Lopez-Mateo*,´ Amaia Arruabarrena-Aristorena†, Cristina Artaza-Irigaray‡, Juan A. Lopez´ §, Enrique Calvo§ and Borja Belandia*1 *Department of Cancer Biology, Instituto de Investigaciones Biomedicas´ Alberto Sols, CSIC-UAM, Arturo Duperier 4, 28029 Madrid, Spain †Proteomics Unit, CIC bioGUNE, Bizkaia Technology Park, 48160 Derio, Spain ‡Division´ de Inmunolog´ıa, Centro de Investigacion´ Biomedica´ de Occidente – IMSS, Sierra Mojada 800, 44340 Guadalajara, Jalisco, Mexico §Unidad de Proteomica, Centro Nacional de Investigaciones Cardiovasculares, CNIC, 28029 Madrid, Spain Synopsis HEY1 (hairy/enhancer-of-split related with YRPW motif 1) is a member of the basic helix–loop–helix-orange (bHLH-O) family of transcription repressors that mediate Notch signalling. HEY1 acts as a positive regulator of the tumour suppressor p53 via still unknown mechanisms. A MALDI-TOF/TOF MS analysis has uncovered a novel HEY1 regulatory phosphorylation event at Ser-68. Strikingly, this single phosphorylation event controls HEY1 stability and function: simulation of HEY1 Ser-68 phosphorylation increases HEY1 protein stability but inhibits its ability to enhance p53 transcriptional activity. Unlike wild-type HEY1, expression of the phosphomimetic mutant HEY1-S68D failed to induce p53-dependent cell cycle arrest and it did not sensitize U2OS cells to p53-activating chemotherapeutic drugs. We have identified two related kinases, STK38 (serine/threonine kinase 38) and STK38L (serine/threonine kinase 38 like), which interact with and phosphorylate HEY1 at Ser-68. HEY1 is phosphorylated at Ser-68 during mitosis and it accumulates in the centrosomes of mitotic cells, suggesting a possible integration of HEY1-dependent signalling in centrosome function. -

Photoreceptor Proliferation and Dysregulation of Cell Cycle Genes in Early Onset Inherited Retinal Degenerations
University of Pennsylvania ScholarlyCommons Departmental Papers (Vet) School of Veterinary Medicine 3-11-2016 Photoreceptor Proliferation and Dysregulation of Cell Cycle Genes in Early Onset Inherited Retinal Degenerations Kristin L. Gardiner University of Pennsylvania Louise Downs University of Pennsylvania Agnes I. Berta-Antalics University of Pennsylvania Evelyn Santana University of Pennsylvania Gustavo D. Aguirre University of Pennsylvania, [email protected] See next page for additional authors Follow this and additional works at: https://repository.upenn.edu/vet_papers Part of the Veterinary Medicine Commons Recommended Citation Gardiner, K. L., Downs, L., Berta-Antalics, A. I., Santana, E., Aguirre, G. D., & Genini, S. (2016). Photoreceptor Proliferation and Dysregulation of Cell Cycle Genes in Early Onset Inherited Retinal Degenerations. BMC Genomics, 17 (221), http://dx.doi.org/10.1186/s12864-016-2477-9 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/vet_papers/152 For more information, please contact [email protected]. Photoreceptor Proliferation and Dysregulation of Cell Cycle Genes in Early Onset Inherited Retinal Degenerations Abstract Background Mitotic terminally differentiated photoreceptors (PRs) are observed in early retinal degeneration (erd), an inherited canine retinal disease driven by mutations in the NDR kinase STK38L (NDR2). Results We demonstrate that a similar proliferative response, but of lower magnitude, occurs in two other early onset disease models, X-linked progressive retinal atrophy 2 (xlpra2) and rod cone dysplasia 1 (rcd1). Proliferating cells are rod PRs, and not microglia or Müller cells. Expression of the cell cycle related genes RB1 and E2F1 as well as CDK2,4,6 was up-regulated, but changes were mutation-specific. -

Insights Into MYC Biology Through Investigation of Synthetic Lethal Interactions with MYC Deregulation
Insights into MYC biology through investigation of synthetic lethal interactions with MYC deregulation Mai Sato Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy under the Executive Committee of the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2014 © 2014 Mai Sato All Rights Reserved ABSTRACT Insights into MYC biology through investigation of synthetic lethal interactions with MYC deregulation Mai Sato MYC (or c-myc) is a bona fide “cancer driver” oncogene that is deregulated in up to 70% of human tumors. In addition to its well-characterized role as a transcription factor that can directly promote tumorigenic growth and proliferation, MYC has transcription-independent functions in vital cellular processes including DNA replication and protein synthesis, contributing to its complex biology. MYC expression, activity, and stability are highly regulated through multiple mechanisms. MYC deregulation triggers genome instability and oncogene-induced DNA replication stress, which are thought to be critical in promoting cancer via mechanisms that are still unclear. Because regulated MYC activity is essential for normal cell viability and MYC is a difficult protein to target pharmacologically, targeting genes or pathways that are essential to survive MYC deregulation offer an attractive alternative as a means to combat tumor cells with MYC deregulation. To this end, we conducted a genome-wide synthetic lethal shRNA screen in MCF10A breast epithelial cells stably expressing an inducible MYCER transgene. We identified and validated FBXW7 as a high-confidence synthetic lethal (MYC-SL) candidate gene. FBXW7 is a component of an E3 ubiquitin ligase complex that degrades MYC. FBXW7 knockdown in MCF10A cells selectively induced cell death in MYC-deregulated cells compared to control. -

A Yeast Bifc-Seq Method for Genome-Wide Interactome Mapping
bioRxiv preprint doi: https://doi.org/10.1101/2020.06.16.154146; this version posted June 17, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 A yeast BiFC-seq method for genome-wide interactome mapping 2 3 Limin Shang1,a, Yuehui Zhang1,b, Yuchen Liu1,c, Chaozhi Jin1,d, Yanzhi Yuan1,e, 4 Chunyan Tian1,f, Ming Ni2,g, Xiaochen Bo2,h, Li Zhang3,i, Dong Li1,j, Fuchu He1,*,k & 5 Jian Wang1,*,l 6 1State Key Laboratory of Proteomics, Beijing Proteome Research Center, National 7 Center for Protein Sciences (Beijing), Beijing Institute of Lifeomics, Beijing 102206, 8 China; 2Department of Biotechnology, Beijing Institute of Radiation Medicine, 9 Beijing 100850, China; 3Department of Rehabilitation Medicine, Nan Lou; 10 Department of Key Laboratory of Wound Repair and Regeneration of PLA, College 11 of Life Sciences, Chinese PLA General Hospital, Beijing 100853, China; 12 Correspondence should be addressed to F.H. ([email protected]) and J.W. 13 ([email protected]). 14 * Corresponding authors. 15 E-mail:[email protected] (Fuchu He),[email protected] (Jian Wang) 16 a ORCID: 0000-0002-6371-1956. 17 b ORCID: 0000-0001-5257-1671 18 c ORCID: 0000-0003-4691-4951 19 d ORCID: 0000-0002-1477-0255 20 e ORCID: 0000-0002-6576-8112 21 f ORCID: 0000-0003-1589-293X 22 g ORCID: 0000-0001-9465-2787 23 h ORCID: 0000-0003-3490-5812 24 i ORCID: 0000-0002-3477-8860 25 j ORCID: 0000-0002-8680-0468 26 k ORCID: 0000-0002-8571-2351 27 l ORCID: 0000-0002-8116-7691 28 Total word counts:4398 (from “Introduction” to “Conclusions”) 29 Total Keywords: 5 bioRxiv preprint doi: https://doi.org/10.1101/2020.06.16.154146; this version posted June 17, 2020. -

Characterization and Expression Profile of CMTM3/CKLFSF3
Journal of Biochemistry and Molecular Biology, Vol. 39, No. 5, September 2006, pp. 537-545 Characterization and Expression Profile of CMTM3/CKLFSF3 Ji Zhong, Yu Wang, Xiaoyan Qiu, Xiaoning Mo, Yanan Liu, Ting Li, Quansheng Song, Dalong Ma and Wenling Han* Peking University Center for Human Disease Genomics, 38 Xueyuan Road, Beijing 100083, China Received 22 February 2006, Accepted 10 May 2006 CMTM/CKLFSF is a novel family of proteins linking Introduction chemokines and TM4SF. In humans, these proteins are encoded by nine genes, CKLF and CMTM1-8/CKLFSF1-8. CKLFSF is a novel family of proteins linking chemokines and Here we report the characteristics and expression profile Transmembrane 4 Super Family (TM4SF), which are encoded of CMTM3/CKLFSF3. Human CMTM3/CKLFSF3 has a by nine genes, CKLF and CKLFSF1-8, in humans. CKLF, high sequence identity among various species and similar CKLFSF1, and CKLFSF2 are active during evolution, and characteristics as its mouse and rat homologues. Established CKLFSF2 has two orthologues in rat and mouse designated by results both of RT-PCR and Quantitative Real-time Cklfsf2a and Cklfsf2b. CKLFSF3-8 are evolutionarily conserved. PCR, the gene is highly transcribed in testis, leukocytes CKLFSF members form two gene clusters: CKLF and and spleen. For further verification, we generated a CKLFSF1-4 at chromosome 16q22.1, and CKLFSF6-8 at polyclonal antibody against human CMTM3/CKLFSF3 chromosome 3p23. Most CKLFSFs have different spliced and found that the protein is highly expressed in the testis forms, and the protein product of at least one spliced form of and some cells of PBMCs. -

RNA-Seq Transcriptome Analysis for the Study of Prostate Cancer Development and Evolution
MASTER THESIS RNA-Seq Transcriptome Analysis for the Study of Prostate Cancer Development and Evolution Esther Sauras Colón Tutors: María Jesús Álvarez Cubero, Eduardo Andrés León September 2019 MASTER IN TRANSLATIONAL RESEARCH AND PERSONALIZED MEDICINE Master Thesis RNA-Seq Transcriptome Analysis for the Study of Prostate Cancer Development and Evolution Esther Sauras Colón 1*, María Jesús Álvarez Cubero 2,3* and Eduardo Andrés León 4* 1 Master in Translational Research and Personalized Medicine. Faculty of Medicine, University of Granada. Granada, Spain. 2 GENYO. Centre for Genomics and Oncological Research. Pfizer / University of Granada / Andalusian Regional Government. Granada, Spain. 3 Department of Biochemistry and Molecular Biology III. Faculty of Medicine, University of Granada. Granada, Spain. 4 Bioinformatics Unit, Institute of Parasitology and Biomedicine “López-Neyra” (IPBLN). Spanish National Research Council (CSIC). Granada, Spain. * Correspondence: Esther Sauras Colón: [email protected]. María Jesús Álvarez Cubero: [email protected]. Eduardo Andrés León: [email protected]. September 2019 Abstract: Prostate cancer (PCa) is one of the most common cancers worldwide. Even though prostate specific antigen (PSA) test is the non-invasive routine blood test for the detection of asymptomatic disease, it can result in problems of diagnostic accuracy and overdiagnosis. Thus, it is necessary to continue investigating new efficient biomarkers for the prevention, diagnosis and prognosis of PCa. Here, we analyse the transcriptome of seven individuals by the use of next-generation sequencing (NGS) technique to identify differentially expressed genes, which can help to better understand PCa aggressiveness. Present analysis show that there are two upregulated genes in PCa regarding to controls: HP (Haptoglobin) and HLA-G (Human Leukocyte Antigen-G). -

Human Social Genomics in the Multi-Ethnic Study of Atherosclerosis
Getting “Under the Skin”: Human Social Genomics in the Multi-Ethnic Study of Atherosclerosis by Kristen Monét Brown A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Epidemiological Science) in the University of Michigan 2017 Doctoral Committee: Professor Ana V. Diez-Roux, Co-Chair, Drexel University Professor Sharon R. Kardia, Co-Chair Professor Bhramar Mukherjee Assistant Professor Belinda Needham Assistant Professor Jennifer A. Smith © Kristen Monét Brown, 2017 [email protected] ORCID iD: 0000-0002-9955-0568 Dedication I dedicate this dissertation to my grandmother, Gertrude Delores Hampton. Nanny, no one wanted to see me become “Dr. Brown” more than you. I know that you are standing over the bannister of heaven smiling and beaming with pride. I love you more than my words could ever fully express. ii Acknowledgements First, I give honor to God, who is the head of my life. Truly, without Him, none of this would be possible. Countless times throughout this doctoral journey I have relied my favorite scripture, “And we know that all things work together for good, to them that love God, to them who are called according to His purpose (Romans 8:28).” Secondly, I acknowledge my parents, James and Marilyn Brown. From an early age, you two instilled in me the value of education and have been my biggest cheerleaders throughout my entire life. I thank you for your unconditional love, encouragement, sacrifices, and support. I would not be here today without you. I truly thank God that out of the all of the people in the world that He could have chosen to be my parents, that He chose the two of you. -

PRODUCTS and SERVICES Target List
PRODUCTS AND SERVICES Target list Kinase Products P.1-11 Kinase Products Biochemical Assays P.12 "QuickScout Screening Assist™ Kits" Kinase Protein Assay Kits P.13 "QuickScout Custom Profiling & Panel Profiling Series" Targets P.14 "QuickScout Custom Profiling Series" Preincubation Targets Cell-Based Assays P.15 NanoBRET™ TE Intracellular Kinase Cell-Based Assay Service Targets P.16 Tyrosine Kinase Ba/F3 Cell-Based Assay Service Targets P.17 Kinase HEK293 Cell-Based Assay Service ~ClariCELL™ ~ Targets P.18 Detection of Protein-Protein Interactions ~ProbeX™~ Stable Cell Lines Crystallization Services P.19 FastLane™ Structures ~Premium~ P.20-21 FastLane™ Structures ~Standard~ Kinase Products For details of products, please see "PRODUCTS AND SERVICES" on page 1~3. Tyrosine Kinases Note: Please contact us for availability or further information. Information may be changed without notice. Expression Protein Kinase Tag Carna Product Name Catalog No. Construct Sequence Accession Number Tag Location System HIS ABL(ABL1) 08-001 Full-length 2-1130 NP_005148.2 N-terminal His Insect (sf21) ABL(ABL1) BTN BTN-ABL(ABL1) 08-401-20N Full-length 2-1130 NP_005148.2 N-terminal DYKDDDDK Insect (sf21) ABL(ABL1) [E255K] HIS ABL(ABL1)[E255K] 08-094 Full-length 2-1130 NP_005148.2 N-terminal His Insect (sf21) HIS ABL(ABL1)[T315I] 08-093 Full-length 2-1130 NP_005148.2 N-terminal His Insect (sf21) ABL(ABL1) [T315I] BTN BTN-ABL(ABL1)[T315I] 08-493-20N Full-length 2-1130 NP_005148.2 N-terminal DYKDDDDK Insect (sf21) ACK(TNK2) GST ACK(TNK2) 08-196 Catalytic domain