Voting with Rank Dependent Scoring Rules
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Influences in Voting and Growing Networks
UC Berkeley UC Berkeley Electronic Theses and Dissertations Title Influences in Voting and Growing Networks Permalink https://escholarship.org/uc/item/0fk1x7zx Author Racz, Miklos Zoltan Publication Date 2015 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California Influences in Voting and Growing Networks by Mikl´osZolt´anR´acz A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Statistics in the Graduate Division of the University of California, Berkeley Committee in charge: Professor Elchanan Mossel, Chair Professor James W. Pitman Professor Allan M. Sly Professor David S. Ahn Spring 2015 Influences in Voting and Growing Networks Copyright 2015 by Mikl´osZolt´anR´acz 1 Abstract Influences in Voting and Growing Networks by Mikl´osZolt´anR´acz Doctor of Philosophy in Statistics University of California, Berkeley Professor Elchanan Mossel, Chair This thesis studies problems in applied probability using combinatorial techniques. The first part of the thesis focuses on voting, and studies the average-case behavior of voting systems with respect to manipulation of their outcome by voters. Many results in the field of voting are negative; in particular, Gibbard and Satterthwaite showed that no reasonable voting system can be strategyproof (a.k.a. nonmanipulable). We prove a quantitative version of this result, showing that the probability of manipulation is nonnegligible, unless the voting system is close to being a dictatorship. We also study manipulation by a coalition of voters, and show that the transition from being powerless to having absolute power is smooth. These results suggest that manipulation is easy on average for reasonable voting systems, and thus computational complexity cannot hide manipulations completely. -

Are Condorcet and Minimax Voting Systems the Best?1
1 Are Condorcet and Minimax Voting Systems the Best?1 Richard B. Darlington Cornell University Abstract For decades, the minimax voting system was well known to experts on voting systems, but was not widely considered to be one of the best systems. But in recent years, two important experts, Nicolaus Tideman and Andrew Myers, have both recognized minimax as one of the best systems. I agree with that. This paper presents my own reasons for preferring minimax. The paper explicitly discusses about 20 systems. Comments invited. [email protected] Copyright Richard B. Darlington May be distributed free for non-commercial purposes Keywords Voting system Condorcet Minimax 1. Many thanks to Nicolaus Tideman, Andrew Myers, Sharon Weinberg, Eduardo Marchena, my wife Betsy Darlington, and my daughter Lois Darlington, all of whom contributed many valuable suggestions. 2 Table of Contents 1. Introduction and summary 3 2. The variety of voting systems 4 3. Some electoral criteria violated by minimax’s competitors 6 Monotonicity 7 Strategic voting 7 Completeness 7 Simplicity 8 Ease of voting 8 Resistance to vote-splitting and spoiling 8 Straddling 8 Condorcet consistency (CC) 8 4. Dismissing eight criteria violated by minimax 9 4.1 The absolute loser, Condorcet loser, and preference inversion criteria 9 4.2 Three anti-manipulation criteria 10 4.3 SCC/IIA 11 4.4 Multiple districts 12 5. Simulation studies on voting systems 13 5.1. Why our computer simulations use spatial models of voter behavior 13 5.2 Four computer simulations 15 5.2.1 Features and purposes of the studies 15 5.2.2 Further description of the studies 16 5.2.3 Results and discussion 18 6. -
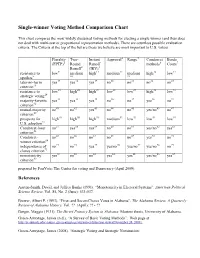
Single-Winner Voting Method Comparison Chart
Single-winner Voting Method Comparison Chart This chart compares the most widely discussed voting methods for electing a single winner (and thus does not deal with multi-seat or proportional representation methods). There are countless possible evaluation criteria. The Criteria at the top of the list are those we believe are most important to U.S. voters. Plurality Two- Instant Approval4 Range5 Condorcet Borda (FPTP)1 Round Runoff methods6 Count7 Runoff2 (IRV)3 resistance to low9 medium high11 medium12 medium high14 low15 spoilers8 10 13 later-no-harm yes17 yes18 yes19 no20 no21 no22 no23 criterion16 resistance to low25 high26 high27 low28 low29 high30 low31 strategic voting24 majority-favorite yes33 yes34 yes35 no36 no37 yes38 no39 criterion32 mutual-majority no41 no42 yes43 no44 no45 yes/no 46 no47 criterion40 prospects for high49 high50 high51 medium52 low53 low54 low55 U.S. adoption48 Condorcet-loser no57 yes58 yes59 no60 no61 yes/no 62 yes63 criterion56 Condorcet- no65 no66 no67 no68 no69 yes70 no71 winner criterion64 independence of no73 no74 yes75 yes/no 76 yes/no 77 yes/no 78 no79 clones criterion72 81 82 83 84 85 86 87 monotonicity yes no no yes yes yes/no yes criterion80 prepared by FairVote: The Center for voting and Democracy (April 2009). References Austen-Smith, David, and Jeffrey Banks (1991). “Monotonicity in Electoral Systems”. American Political Science Review, Vol. 85, No. 2 (June): 531-537. Brewer, Albert P. (1993). “First- and Secon-Choice Votes in Alabama”. The Alabama Review, A Quarterly Review of Alabama History, Vol. ?? (April): ?? - ?? Burgin, Maggie (1931). The Direct Primary System in Alabama. -

Majority Judgment: a New Voting Method
Paradoxes Impossbilities Majority Judgment Theory Applications of MJ Logiciels JM Experimental Evidences Conclusion Majority Judgment: A New Voting Method Rida Laraki CNRS (Lamsade, Dauphine) and University of Liverpool Colloquium J. Morgenstern, INRIA, Sophia-Antipolis December 11, 2018 (Joint work with Michel Balinski) R. Laraki Majority Judgment: A New Voting Method Paradoxes Impossbilities Majority Judgment Theory ApplicationsMethods of MJ Logiciels of Voting JM Paradoxes Experimental in Theory Evidences Paradoxes Conclusion in Practice 1 Paradoxes Methods of Voting Paradoxes in Theory Paradoxes in Practice 2 Impossbilities May’s Axioms for Two Candidates Arrow’s Impossibility Theorem 3 Majority Judgment From Practice Small Jury Large Electorate 4 Theory Domination Paradox Possibility Manipulation 5 Applications of MJ Trump 2016 Gillets Jaunes Délé´gué CM1 6 Logiciels JM 7 Experimental Evidences 8 Conclusion R. Laraki Majority Judgment: A New Voting Method First-past-the-post: also called plurality voting, used in UK, US and Canada to elect members of house of representatives. A voter designate one candidate. The most designated wins. Two-past-the-post: used in France and several countries (Finland, Austria, Russia, Portugal, Ukraine, etc) to elect the president. A voter designates one candidate. If a candidate is designated by a majority, he is elected. Otherwise, there is a run-off between the two first candidates. Paradoxes Impossbilities Majority Judgment Theory ApplicationsMethods of MJ Logiciels of Voting JM Paradoxes Experimental in Theory Evidences Paradoxes Conclusion in Practice Voting methods most used in elections R. Laraki Majority Judgment: A New Voting Method A voter designate one candidate. The most designated wins. Two-past-the-post: used in France and several countries (Finland, Austria, Russia, Portugal, Ukraine, etc) to elect the president. -

Majority Judgment Vs. Majority Rule ∗
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by University of Liverpool Repository Majority Judgment vs. Majority Rule ∗ Michel Balinski CNRS, CREST, Ecole´ Polytechnique, France, [email protected] and Rida Laraki* CNRS, University of Paris Dauphine-PSL, France, [email protected] and University of Liverpool, United Kingdom June 6, 2019 Abstract The validity of majority rule in an election with but two candidates|and so also of Condorcet consistency| is challenged. Axioms based on evaluating candidates|paralleling those of K. O. May characterizing ma- jority rule for two candidates based on comparing candidates|lead to another method, majority judgment, that is unique in agreeing with the majority rule on pairs of \polarized" candidates. It is a practical method that accommodates any number of candidates, avoids both the Condorcet and Arrow paradoxes, and best resists strategic manipulation. Key words: majority, measuring, ranking, electing, Condorcet consistency, domination paradox, tyranny of majority, intensity problem, majority-gauge, strategy-proofness, polarization. 1 Introduction Elections measure. Voters express themselves, a rule amalgamates them, the candidates' scores|measures of support|determine their order of finish, and the winner. Traditional methods ask voters to express themselves by comparing them: • ticking one candidate at most (majority rule, first-past-the-post) or several candidates (approval voting), candidates' total ticks ranking them; • rank-ordering the candidates (Borda rule, alternative vote or preferential voting, Llull's rule, Dasgupta- Maskin method, . ), differently derived numerical scores ranking them. However, no traditional method measures the support of one candidate.1 Instead, the theory of voting (or of social choice) elevates to a basic distinguishing axiom the faith that in an election between two candidates majority rule is the only proper rule. -

Ranked-Choice Voting from a Partisan Perspective
Ranked-Choice Voting From a Partisan Perspective Jack Santucci December 21, 2020 Revised December 22, 2020 Abstract Ranked-choice voting (RCV) has come to mean a range of electoral systems. Broadly, they can facilitate (a) majority winners in single-seat districts, (b) majority rule with minority representation in multi-seat districts, or (c) majority sweeps in multi-seat districts. Such systems can be combined with other rules that encourage/discourage slate voting. This paper describes five major versions used in U.S. public elections: Al- ternative Vote (AV), single transferable vote (STV), block-preferential voting (BPV), the bottoms-up system, and AV with numbered posts. It then considers each from the perspective of a `political operative.' Simple models of voting (one with two parties, another with three) draw attention to real-world strategic issues: effects on minority representation, importance of party cues, and reasons for the political operative to care about how voters rank choices. Unsurprisingly, different rules produce different outcomes with the same votes. Specific problems from the operative's perspective are: majority reversal, serving two masters, and undisciplined third-party voters (e.g., `pure' independents). Some of these stem from well-known phenomena, e.g., ballot exhaus- tion/ranking truncation and inter-coalition \vote leakage." The paper also alludes to vote-management tactics, i.e., rationing nominations and ensuring even distributions of first-choice votes. Illustrative examples come from American history and comparative politics. (209 words.) Keywords: Alternative Vote, ballot exhaustion, block-preferential voting, bottoms- up system, exhaustive-preferential system, instant runoff voting, ranked-choice voting, sequential ranked-choice voting, single transferable vote, strategic coordination (10 keywords). -

Präferenzaggregation Durch Wählen: Algorithmik Und Komplexität
Pr¨aferenzaggregationdurch W¨ahlen: Algorithmik und Komplexit¨at Folien zur Vorlesung Wintersemester 2017/2018 Dozent: Prof. Dr. J. Rothe J. Rothe (HHU D¨usseldorf) Pr¨aferenzaggregation durch W¨ahlen 1 / 57 Preliminary Remarks Websites Websites Vorlesungswebsite: http:==ccc:cs:uni-duesseldorf:de=~rothe=wahlen Anmeldung im LSF J. Rothe (HHU D¨usseldorf) Pr¨aferenzaggregation durch W¨ahlen 2 / 57 Preliminary Remarks Literature Literature J. Rothe (Herausgeber): Economics and Computation: An Introduction to Algorithmic Game Theory, Computational Social Choice, and Fair Division. Springer-Verlag, 2015 with a preface by Matt O. Jackson und Yoav Shoham (Stanford) Buchblock 155 x 235 mm Abstand 6 mm Springer Texts in Business and Economics Rothe Springer Texts in Business and Economics Jörg Rothe Editor Economics and Computation Ed. An Introduction to Algorithmic Game Theory, Computational Social Choice, and Fair Division J. Rothe D. Baumeister C. Lindner I. Rothe This textbook connects three vibrant areas at the interface between economics and computer science: algorithmic game theory, computational social choice, and fair divi- sion. It thus offers an interdisciplinary treatment of collective decision making from an economic and computational perspective. Part I introduces to algorithmic game theory, focusing on both noncooperative and cooperative game theory. Part II introduces to Jörg Rothe Einführung in computational social choice, focusing on both preference aggregation (voting) and judgment aggregation. Part III introduces to fair division, focusing on the division of Editor Computational Social Choice both a single divisible resource ("cake-cutting") and multiple indivisible and unshare- able resources ("multiagent resource allocation"). In all these parts, much weight is Individuelle Strategien und kollektive given to the algorithmic and complexity-theoretic aspects of problems arising in these areas, and the interconnections between the three parts are of central interest. -

Democracy Without Elections Mainz
Democracy without Elections: Is electoral accountability essential for democracy? Felix Gerlsbeck [email protected] Paper prepared for the workshop “Democratic Anxiety. Democratic Resilience.” Mainz, 15-17 June 2017 DRAFT VERSION, PLEASE DO NOT CITE WITHOUT AUTHOR’S PERMISSION 1. Introduction The idea of choosing political decision-makers by sortition, that is, choosing them randomly from a pool of the entire population or from some qualified subset, through some form of lottery or other randomizing procedure, is familiar to democrats at least since ancient Athens. Apart from the selection of trial juries, however, sortition has all but disappeared from official decision-making procedures within contemporary democratic systems, and free, equal, and regular election through voting by the entire qualified population of candidates who put themselves forward for political office, has taken its place. Nevertheless, there has been renewed interest in the idea of reviving sortition-based elements within modern democratic systems over the last years: a number of democratic theorists see great promise in complementing elected decision-making institutions with those selected randomly. These proposals variously go under the names mini-publics, citizen juries, citizen assemblies, lottocracy, enfranchisement lottery, and even Machiavellian Democracy.1 The roots of this practice go back to ancient Athens. During the 5th century Athenian democracy, the equivalent of the parliamentary body tasked with deliberating 1 See for instance, Guerrero 2014; Fishkin 2009; Warren & Gastil 2015; Ryan & Smith 2014; Saunders 2012; López-Guerra 2014; López-Guerra 2011; McCormick 2011. 1 and drafting policy proposals, the boule, was chosen by lot from the citizens of Athens through a complex system of randomization. -

Election by Majority Judgment: Experimental Evidence
Chapter 2 Election by Majority Judgment: Experimental Evidence Michel Balinski and Rida Laraki Introduction Throughout the world, the choice of one from among a set of candidates is accomplished by elections. Elections are mechanisms for amalgamating the wishes of individuals into a decision of society. Many have been proposed and used. Most rely on the idea that voters compare candidates – one is better than another – so have lists of “preferences” in their minds. These include first-past-the-post (in at least two avatars), Condorcet’s method (1785), Borda’s method (1784) (and similar methods that assign scores to places in the lists of preferences and then add them), convolutions of Condorcet’s and/or Borda’s, the single transferable vote (also in at least two versions), and approval voting (in one interpretation). Electoral mechanisms are also used in a host of other circumstances where win- ners and orders-of-finish must be determined by a jury of judges, including figure skaters, divers, gymnasts, pianists, and wines. Invariably, as the great mathemati- cian Laplace (1820) was the first to propose two centuries ago they asked voters (or judges) not to compare but to evaluate the competitors by assigning points from some range, points expressing an absolute measure of the competitors’ mer- its. Laplace suggested the range Œ0; R for some arbitrary positive real number R, whereas practical systems usually fix R at some positive integer. These mechanisms rank the candidates according to the sums or the averages of their points1 (some- times after dropping highest and lowest scores). They have been emulated in various schemes proposed for voting with ranges taken to be integers in Œ0; 100, Œ0; 5, Œ0; 2, or Œ0; 1 (the last approval voting). -

And the Loser Is... Plurality Voting Jean-François Laslier
And the loser is... Plurality Voting Jean-François Laslier To cite this version: Jean-François Laslier. And the loser is... Plurality Voting. 2011. hal-00609810 HAL Id: hal-00609810 https://hal.archives-ouvertes.fr/hal-00609810 Preprint submitted on 20 Jul 2011 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. ECOLE POLYTECHNIQUE CENTRE NATIONAL DE LA RECHERCHE SCIENTIFIQUE AND THE LOSER IS... PLURALITY VOTING Jean-François LASLIER Cahier n° 2011-13 DEPARTEMENT D'ECONOMIE Route de Saclay 91128 PALAISEAU CEDEX (33) 1 69333033 http://www.economie.polytechnique.edu/ mailto:[email protected] And the loser is... Plurality Voting Jean-Franc¸ois Laslier Abstract This paper reports on a vote for choosing the best voting rules that was organized among the participants of the Voting Procedures workshop in July, 2010. Among 18 voting rules, Approval Voting won the contest, and Plurality Voting re- ceived no support at all. 1 Introduction Experts have different opinions as to which is the best voting procedure. The Lever- hulme Trust sponsored 2010 Voting Power in Practice workshop, held at the Chateau du Baffy, Normandy, from 30 July to 2 August 2010, was organized for the purpose of discussing this matter. -

Group Decision Making with Partial Preferences
Group Decision Making with Partial Preferences by Tyler Lu A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Graduate Department of Computer Science University of Toronto c Copyright 2015 by Tyler Lu Abstract Group Decision Making with Partial Preferences Tyler Lu Doctor of Philosophy Graduate Department of Computer Science University of Toronto 2015 Group decision making is of fundamental importance in all aspects of a modern society. Many commonly studied decision procedures require that agents provide full preference information. This requirement imposes significant cognitive and time burdens on agents, increases communication overhead, and infringes agent privacy. As a result, specifying full preferences is one of the contributing factors for the limited real-world adoption of some commonly studied voting rules. In this dissertation, we introduce a framework consisting of new concepts, algorithms, and theoretical results to provide a sound foundation on which we can address these problems by being able to make group decisions with only partial preference information. In particular, we focus on single and multi-winner voting. We introduce minimax regret (MMR), a group decision-criterion for partial preferences, which quantifies the loss in social welfare of chosen alternative(s) compared to the unknown, but true winning alternative(s). We develop polynomial-time algorithms for the computation of MMR for a number of common of voting rules, and prove intractability results for other rules. We address preference elicitation, the second part of our framework, which concerns the extraction of only the relevant agent preferences that reduce MMR. We develop a few elicitation strategies, based on common ideas, for different voting rules and query types. -

Math 105 Workbook Exploring Mathematics
Math 105 Workbook Exploring Mathematics Douglas R. Anderson, Professor Fall 2018: MWF 11:50-1:00, ISC 101 Acknowledgment First we would like to thank all of our former Math 105 students. Their successes, struggles, and suggestions have shaped how we teach this course in many important ways. We also want to thank our departmental colleagues and several Concordia math- ematics majors for many fruitful discussions and resources on the content of this course and the makeup of this workbook. Some of the topics, examples, and exercises in this workbook are drawn from other works. Most significantly, we thank Samantha Briggs, Ellen Kramer, and Dr. Jessie Lenarz for their work in Exploring Mathematics, as well as other Cobber mathemat- ics professors. We have also used: • Taxicab Geometry: An Adventure in Non-Euclidean Geometry by Eugene F. Krause, • Excursions in Modern Mathematics, Sixth Edition, by Peter Tannenbaum. • Introductory Graph Theory by Gary Chartrand, • The Heart of Mathematics: An invitation to effective thinking by Edward B. Burger and Michael Starbird, • Applied Finite Mathematics by Edmond C. Tomastik. Finally, we want to thank (in advance) you, our current students. Your suggestions for this course and this workbook are always encouraged, either in person or over e-mail. Both the course and workbook are works in progress that will continue to improve each semester with your help. Let's have a great semester this fall exploring mathematics together and fulfilling Concordia's math requirement in 2018. Skol Cobbs! i ii Contents 1 Taxicab Geometry 3 1.1 Taxicab Distance . .3 Homework . .8 1.2 Taxicab Circles .