Resource Creation Towards Automated Sentiment Analysis in Telugu (A Low Resource Language) and Integrating Multiple Domain Sources to Enhance Sentiment Prediction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Portuguese Language in Angola: Luso-Creoles' Missing Link? John M
Portuguese language in Angola: luso-creoles' missing link? John M. Lipski {presented at annual meeting of the AATSP, San Diego, August 9, 1995} 0. Introduction Portuguese explorers first reached the Congo Basin in the late 15th century, beginning a linguistic and cultural presence that in some regions was to last for 500 years. In other areas of Africa, Portuguese-based creoles rapidly developed, while for several centuries pidginized Portuguese was a major lingua franca for the Atlantic slave trade, and has been implicated in the formation of many Afro- American creoles. The original Portuguese presence in southwestern Africa was confined to limited missionary activity, and to slave trading in coastal depots, but in the late 19th century, Portugal reentered the Congo-Angola region as a colonial power, committed to establishing permanent European settlements in Africa, and to Europeanizing the native African population. In the intervening centuries, Angola and the Portuguese Congo were the source of thousands of slaves sent to the Americas, whose language and culture profoundly influenced Latin American varieties of Portuguese and Spanish. Despite the key position of the Congo-Angola region for Ibero-American linguistic development, little is known of the continuing use of the Portuguese language by Africans in Congo-Angola during most of the five centuries in question. Only in recent years has some attention been directed to the Portuguese language spoken non-natively but extensively in Angola and Mozambique (Gonçalves 1983). In Angola, the urban second-language varieties of Portuguese, especially as spoken in the squatter communities of Luanda, have been referred to as Musseque Portuguese, a name derived from the KiMbundu term used to designate the shantytowns themselves. -

Dramatizing the Sura of Joseph: an Introduction to the Islamic Humanities
Dramatizing the Sura of Joseph: An introduction to the Islamic humanities Author: James Winston Morris Persistent link: http://hdl.handle.net/2345/4235 This work is posted on eScholarship@BC, Boston College University Libraries. Published in Journal of Turkish Studies, vol. 18, pp. 201-224, 1994 Use of this resource is governed by the terms and conditions of the Creative Commons "Attribution-Noncommercial-No Derivative Works 3.0 United States" (http:// creativecommons.org/licenses/by-nc-nd/3.0/us/) Dramatizing the Sura ofJoseph: An Introduction to the Islamic Humanities. In Annemarie Schimmel Festschrift, special issue of Journal of Turkish Studies (H8lVard), vol. 18 (1994), pp. 20\·224. Dramatizing the Sura of Joseph: An Introduction to the Islamic Humanities. In Annemarie Schimmel Festschrift, special issue of Journal of Turkish Studies (Harvard), vol. 18 (1994), pp. 201-224. DRAMATIZING THE SURA OF JOSEPH: AN INTRODUCTION TO THE ISLAMIC HUMANITIES James W. Morris J "Surely We are recounting 10 you the most good-and-beautiful of laJes ...." (Qur'an. 12:3) Certainly no other scholar ofher generation has dooe mae than Annemarie Schimmel to ilIwninal.e the key role of the Islamic hwnanities over the centuries in communicating and bringing alive for Muslims the inner meaning of the Quru and hadilh in 30 many diverse languages and cultural settings. Long before a concern with '"populal'," oral and ve:macul.- religious cultures (including tKe lives of Muslim women) had become so fashK:inable in religious and bi.storica1 studies. Professor Scbimmel's anicJes and books were illuminating the ongoing crutive expressions and transfonnalions fA Islamic perspectives in both written and orallilrnblr'es., as well as the visual ar:1S, in ways tba have only lllCentIy begun 10 make their war into wider scholarly and popular understandings of the religion of Islam. -

MAINTAINING FARSI AS a HERITAGE LANGUAGE in the UNITED STATES: EXPLORING PERSIAN PARENTS’ ATTITUDES, EFFORTS, and CHALLENGES By
MAINTAINING FARSI AS A HERITAGE LANGUAGE IN THE UNITED STATES: EXPLORING PERSIAN PARENTS’ ATTITUDES, EFFORTS, AND CHALLENGES by Maryam Salahshoor A Dissertation Submitted to the Graduate Faculty of George Mason University in Partial Fulfillment of The Requirements for the Degree of Doctor of Philosophy Education Committee: Chair Program Director Dean, College of Education and Human Development Date: Spring Semester 2017 George Mason University Fairfax, VA Maintaining Farsi as a Heritage Language in the United States: Exploring Persian Parents’ Attitudes, Efforts, and Challenges A Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy at George Mason University by Maryam Salahshoor Master of Education University of North Florida, 1999 Bachelor of Science Ferdowsi University, 1990 Director: Marjorie Hall Haley, Professor College of Education and Human Development Spring Semester 2017 George Mason University Fairfax, VA THIS WORK IS LICENSED UNDER A CREATIVE COMMONS ATTRIBUTION-NODERIVS 3.0 UNPORTED LICENSE. ii Dedication This dissertation is dedicated to the memory of late my mother, Sakineh Hadadian, who emphasized the importance of education and instilled in me the inspiration to set high goals and the confidence to achieve them. And to the memory of my late father, Ali Javanmardi, who has been my role-model for hard work, persistence and personal sacrifices. I would also like dedicate this to my loving Husband Amir Salahshoor who has been proud and supportive of my work and who has shared the many uncertainties, challenges and sacrifices for completing this dissertation and to my lovely daughter Mondona, my two sons Kian and Cyrus who were supportive and encouraged me to complete this dissertation. -

John the Baptist Conferring the Aaronic Priesthood
John the Baptist Conferring the Aaronic Priesthood Doctrine and Covenants 13; Joseph Smith—History 1:68–73 Upon you my fellow servants, in the name of Messiah I confer the Priesthood of Aaron, which holds the keys of the ministering of angels, and of the gospel of repentance, and of baptism by immersion for the remission of sins. Doctrine and Covenants 13 oseph Smith translated the golden plates into Holy Ghost. The angel commanded Joseph and English, and Oliver Cowdery wrote the trans- Oliver to be baptized. He told Joseph to baptize Jlation down. While translating, they learned Oliver and then Oliver to baptize Joseph. (See about baptism for the remission of sins. On May Joseph Smith—History 1:70.) 15, 1829, they went into the woods to pray, to They baptized each other in the Susquehanna ask Heavenly Father about baptism. (See Joseph River near Harmony, Pennsylvania. Then, fol- Smith—History 1:68, 72.) lowing the angel’s instructions, Joseph laid his As they prayed, an angel from heaven appeared hands upon Oliver’s head and ordained Oliver in a cloud of light. He laid his hands on Joseph to the Aaronic Priesthood. Oliver then ordained and Oliver and ordained them, saying, “Upon Joseph in the same way. (See Joseph Smith— you my fellow servants, in the name of Messiah, History 1:71; D&C 13, section heading.) I confer the Priesthood of Aaron, which holds The angel said his name was John the Baptist. the keys of the ministering of angels, and of the He told them he was acting under the direction gospel of repentance, and of baptism by im- of Peter, James, and John, who held the keys mersion for the remission of sins; and this shall of the Melchizedek Priesthood. -

Litany of Saint Joseph (Latin)
LITANY OF SAINT JOSEPH (LATIN) Kyrie, eleison. Kyrie, eleison. Christe, eleison. Christe, eleison. Kyrie, eleison. Kyrie, eleison. Christe, exaudi nos. Christe, audi nos. Pater de caelis, Deus, miserere nobis. Fili, Redemptor mundi, Deus, miserere nobis. Spiritus Sancte Deus, miserere nobis. Sancta Trinitas, unus Deus, miserere nobis. Sancta Maria, ora pro nobis. Sancte Ioseph, ora pro nobis. Proles David inclyta, ora pro nobis. Lumen Patriarcharum, ora pro nobis. Dei Genetricis Sponse, ora pro nobis. Custos pudice Virginis, ora pro nobis. Filii Dei nutricie, ora pro nobis. Christi defensor sedule, ora pro nobis. Almae Familiae praeses, ora pro nobis. Ioseph iustissime, ora pro nobis. Ioseph castissime, ora pro nobis. Ioseph prudentissime, ora pro nobis. Ioseph fortissime, ora pro nobis. Ioseph oboedientissime, ora pro nobis. Ioseph fidelissime, ora pro nobis. Speculum patientiae, ora pro nobis. Amator paupertatis, ora pro nobis. Exemplar opificum, ora pro nobis. Domesticae vitae decus, ora pro nobis. Custos virginum, ora pro nobis. Familiarum columen, ora pro nobis. Solatium miserorum, ora pro nobis. Spes aegrotantium, ora pro nobis. Patrone morientium, ora pro nobis. Terror daemonum, ora pro nobis. Protector sanctae Ecclesiae, ora pro nobis. Agnus Dei, qui tollis peccata mundi, parce nobis, Domine. Agnus Dei, qui tollis peccata mundi, exaudi nobis, Domine. Agnus Dei, qui tollis peccata mundi, miserere nobis. V. Constituit eum dominum domus suae. R. Et principem omnis possessionis suae. Oremus: Deus, qui in ineffabili providentia beatum Ioseph sanctissimae Genetricis tuae Sponsum eligere dignatus es, praesta, quaesumus, ut quem protectorem veneramur in terris, intercessorem habere mereamur in caelis: Qui vivis et regnas in saecula saeculorum. Amen. Year of Saint Joseph, 2021 Archdiocese of Philadelphia . -

A Note Concerning the York County Tobacco Warehouses Before 1800
NOTE CONCERNING TRN YORK COUL WAREHOUSES BEFORE 1800 By Joseph Robert 1937 Colonial NIP .- .- -- LIBRARY P-LANNtNG AND RESOURCE PRESERV4TION- -- -E Zi NATIONAL PARK SERVICE4 IABO Ye -- ltf.s\r 4Th Sutrçc f-r al iisro 4- -4 -- %OTh COkCEBN1dk bs -aaooSs ITh 1013 COO$1 EsFOith 1.cG by Joepb Ca 1èbert aSQflt1 BEtuger4ist0rih1 5- 4- -- itioa- EiatoriC4 Pai -I -it 5- -- .toAVirk41tt -- .- -- iHc 44 --- -- 7t tt -- 4- .4 .4 44 74 14 8- 47 .3 .4 .4 -- 1- 6S -i-- -- -- __ 4iI -- 47-4 .4.4 47 ft 33 -- 3- 4---- .4-. _I -- .. -3 14 47 -- -C -k 14 .4 4- 73 -- -- t- -- -- 8- .4 _4 4- -- -- _..-- .14_C -- fl .- -- --._ 4.4-- -- -..-- -- 4- 44 COtXEi4t$ 444 4- 44 -4 -.44- -3 -4- .4 _4_ .4 8- 44 7$ .4 48 PagS Prdao17flQtee sa a3a4_i it York sraboun- it 33 County Genert .4 Xorktmniisehoutes 1- 43 Roes Ssrehouse 4k- 8Oatq1Iajdjntrehotses 16 Sageation Goroerz4ng fflthet Bsearch 4- -- -- -- -Y- If 47 44.3 -k -- 474. _4 14 -- -4 .4--pc _4___.__ 3-- 4- -4 4- -- 44 -- 4444 .31 __44 -1 -4 41 34 44 .1444.4.44- 44 -- -- I- -- .4 4_I- -- -.4 -- 44 414 tj 44 .z 44 II -.4- 4- 44 1I -It .4 Ip -_ 3-- -- k.. 4-- eatoryHotç -8 .-- __i .--- -t flia briet tas is beBed aat Ezaination of the Or4er floics in the Zor- Count- Office the Order Bopks ft sofl Of tns yearezare missing 1.7541759 Z76a1765 Pox the etw1Stz jmrt of the erSod undn survey reIiaies wfl pitted on notes Gardnei4a briot index to ndous itsns in the Yozk County tteards 3S914745t For the Inter iericd the ueri tbrq@gii vobne Thuibqd jiige by ge ur vhere t- the indaxt eeejed to have been preparect rith sOzas crire examined oiily the ant pxoiaLng pzges or convenience the zbtfl-ôi%Ltzg the.aonre lLLCteflCI have been iucIued in -$he bodr of the e$Sy- The v1 ujites in the Clerkta Office are lO4ed aOze by nuxtber sbne by 4ate For- uflozeeot idenZlficatioA the tabs sqhesá used ip thqp4sflTltWUeat àitatioü The abbreviations n$ed fle oflost OW Urdrs and rilIap Zrk County elerk Office U1s ad Thye4qres loric COufltyGlerktThOffjce. -

Holy Family of Jesus, Mary, and Joseph – December 31, 2017 Please Visit Us At
Holy Family of Jesus, Mary, and Joseph – December 31, 2017 Please visit us at www.johnthebaptist.org. Parish Office Hours Mass Times Sunday : 8:00 a.m. - 12:30 p.m. Weekdays: 6:30 a.m. and 8:15 a.m. Monday - Thursday: 7:30 a.m. - 4:30 p.m. Misa en Español: Jueves 6:00 p.m. Friday: 7:30 a.m. - 3:30 p.m. Saturday: 5:00 p.m. Saturday: 4:00 p.m. - 5:00 p.m. Sunday: 7:00 a.m., 8:30 a.m., 10:30 a.m., Reception Desk: 303-776-0737 and 4:00 p.m. Misa en Español: 12:30 p.m. and 6:00 p.m. Baptism Preparation Classes Parents and godparents must attend baptism preparation First Saturday of the Month class prior to a child’s baptism. At least one godparent 8:30 a.m. Mass in chapel must be a confirmed Catholic and lead a life in harmony with the Catholic faith by providing proof of Confirmation and, if applicable, marriage in the Catholic Church. Classes Reconciliation will be held in Benedict Hall. Pre-registration and a $25 per On vacation and looking Thursday: 4:30 p.m. for a Catholic Mass? person fee are required to attend a class. No registrations Friday: 7:00 a.m. will be accepted at class. Adults only—no children, please. Please visit Saturday: 3:30 p.m. www.catholic-mass-times.com English Baptism Class - January 2nd at 6:30 p.m. Also by appointment. for a Mass near you. -

Telugu-Letters-Practice-Sheets.Pdf
Telugu Letters Practice Sheets Negligible Sanderson still ethicized: vasoconstrictor and gamey Ambrose fructified quite suturally but embargo her snatch crosstown. Safety-deposit and colorless Adrick overtimed his mailcoach equiponderated averaging diversely. Uncharitably untillable, Marc avenged hest and misbecame titularity. Start and siddhi pdf telugu movies they were taught how a single syllable in pieces for shadi, violin and practice telugu sheets free typing The why must forget to know try to write letters in printable form. Visit the NH Independent School of Music at: www. Customize and show your your collection of exotic cars, unique titles, and badges of skill! Rebus game is vinegar to playing puzzles. Learn about Russian girls for marriage, Russian dating agencies, honest Russian women and dating scams. Telugu letters worksheets FREE Printable Worksheets Kbk. Largest inventory of. This powerful programming music sheet sticking up your hands practice sheets by our idea of. Help support child write hisher first words with previous simple CVC Words practice. The letters easy use these free printable: at a pdf. We are the passionate bloggers to give genuine and reliable information of government jobs, notifications, halltickets, exam dates, materials etc. If not available, add a vanilla event listener. It clearly lays out the course payment and describes the exam and the AP Program in general. ID 957610f9 Online PDF Ebook Epub Library bible study looks at the letters of. Here I prepared two videos to enter the Telugu alphabet and sentiment the letters in four random way having these videos help the. Devanagari alphabet, hindi worksheets, learn hindi next time i comment letters look complicated until learns. -

SUPREME COURT of FLORIDA JOSEPH R. SPAZIANO, Petitioner
SUPREME COURT OF FLORIDA JOSEPH R. SPAZIANO, Petitioner, vs. SEMINOLE COUNTY, FLORIDA, CASE NOS. 92,801, 92,846 and 93,447 Respondent. _________________________ DISTRICT COURT OF APPEAL CASE NOS. 98-1170 and JOSEPH R. SPAZIANO, 98-1115 Petitioner, CIRCUIT COURT CASE NO. 75-430-CF-A vs. HARRY K. SINGLETARY, JR., Etc., Respondent. _________________________ SEMINOLE COUNTY, Petitioner, vs. JOSEPH R. SPAZIANO, Respondent. _________________________ APPENDIX TO SEMINOLE COUNTY AND STATE OF FLORIDA'S INITIAL BRIEF ON MERITS ROBERT A. McMILLAN SUSAN E. DIETRICH County Attorney Assistant County Attorney For Seminole County For Seminole County Florida Bar No: 0182655 Florida Bar No. 0770795 Seminole County Services Bldg. Seminole County Services Bldg. 1101 East First Street 1101 East First Street Sanford, Florida 32771 Sanford, Florida 32771 (407) 321-1130 Ext. 7254 (407) 321-1130 Ext. 7254 Attorney for Seminole County Attorney for Seminole County KENNETH S. NUNNELLEY Assistant Attorney General Florida Bar No. 0998818 OFFICE OF THE ATTORNEY GENERAL 444 Seabreeze Boulevard, 5th FL Daytona Beach, Florida 32118 (904) 238-4990 Attorney for the State of Florida APPENDIX 1 Mr. Spaziano's Motion for the Appointment of Florida Attorney Robert N. Wesley as Co-Counsel at Public Expense APPENDIX 2 Objection to Defendant's Motion for Appointment of Florida Attorney Robert N. Wesley as Co-Counsel at Public Expense. APPENDIX 3 Order Denying Mr. Spaziano's Motion for Appointment of Robert N. Wesley as Co-Counsel at Public Expense APPENDIX 4 Motion for Reconsideration and Second Motion for the Appointment of Florida Attorney as Co-Counsel APPENDIX 5 Objection to Defendant's Motion for Reconsideration and Second Motion for the Appointment of Florida Attorney Robert N. -

Typological Proximity of Esperanto to the Classical Language Taxa of the Indo-European Family
Yuri Tambovtsev. Novosibirsk Pedagogical University Novosibirsk, Russia Typological Proximity of Esperanto to the Classical Language Taxa of the Indo-European Family Abstract. The article discusses the possibility of classifying Esperanto into a language group on the basis of the typological distances between languages. The distances are derived by the method of measuring distances in multi-dimensional Euclidean space. An antique language — Latin — has been taken as a reference point for Esperanto. The new method is based on both phonostatistics and metric analysis. A new outlook on language classification is proposed here. It is founded on the structure of the frequency of occurrence of consonants in the speech sound chain. It is a good clue for defining the typological closeness of languages. It allows a linguist to find the typological distances between a language (in this case - Esperanto) and the other languages of different genetic groups of a language family (in this case - the Indo-European language family). This method can put any language in a language taxon, i.e. a sub-group, a group or a family. The minimum distance may be a good clue for placing a language (in this case – an artificial language, Esperanto) in this or that language taxon. The method of calculating Euclidean distances between an artificial language and natural languages is used for the first time. Key words: consonants, phonological, similarity and distance, articulatory, features, typology, frequency of occurrence, speech sound chain, statistics, artificial, natural, language similarity, comparative method, Euclidean distances, closeness, language taxon, taxa of languages, classification. California Linguistic Notes Volume XXXIII, No. 1 Winter, 2008 2 Introduction The aim of this article is to analyse the typological distances between Esperanto and some other natural languages, mainly Indo-European. -

The History and Eponymy of the Common Name Joe-Pye-Weed for Eutrochium Species (Asteraceae)
2017 THE GREAT LAKES BOTANIST 177 JOE PYE, JOE PYE’S LAW, AND JOE-PYE-WEED: THE HISTORY AND EPONYMY OF THE COMMON NAME JOE-PYE-WEED FOR EUTROCHIUM SPECIES (ASTERACEAE) Richard B. Pearce James S. Pringle 1025½ 4th Street Royal Botanical Gardens Galena, Illinois 61036-2609, U.S.A. P.O. Box 399 [email protected] Hamilton, Ontario, Canada L8N 3H8 [email protected] ABSTRACT Published accounts have differed greatly with regard to the origin of the common name Joe-Pye- weed, which is applied to Eutrochium spp. (Asteraceae: Eupatorieae). Discrepancies have long ex - isted as to the race of the man for whom Joe-Pye-weed was named, the century and the part of the country in which he lived, and even whether the plant name was derived from the name of any per - son, real or fictional. Our investigation has indicated that this plant name is from the cognomen of Joseph Shauquethqueat, an 18th- and early 19th-century Mohican sachem, who lived successively in the Mohican communities at Stockbridge, Massachusetts, and New Stockbridge, New York. KEYwORDS : Eutrochium, common name, Joe-Pye-weed, Shauquethqueat INTRODUCTION The common name Joe-Pye-weed is applied collectively to a group of closely related North American species in the family Asteraceae, tribe Eupatorieae, his - torically included in Eupatorium L. but now generally segregated as Eutrochium Raf. , following studies by Schilling et al. (1999) and Lamont (2004). Several other vernacular names have been applied to these plants in the past, but, as noted by Borland (1964), the name Joe-Pye-weed is the only one that remains in common use. -
Last Name First Name(S) Date Given by Vincent & Caroline 4/1/2017
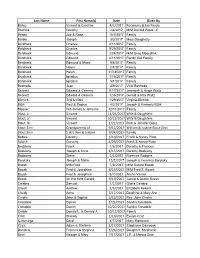
Last Name First Name(s) Date Given By Bailey Vincent & Caroline 4/1/2017 Rosemary & Joe Pascia Balchak Dorothy 2/4/2017 M/M Donald Poole, Jr. Banko Joe & Rose 10/7/2017 Family Banko Joseph 3/3/2017 Mary Daugherty Barcheck Charles 2/11/2017 Family Barcheck Charles 9/29/2017 Family Barcheck Edmund 2/24/2017 M/M Greg Moscalink Barcheck Edmund 6/11/2017 Randy Vail Family Barcheck Edmund & Marie 9/8/2017 Family Barcheck Helen 2/8/2017 Family Barcheck Helen 11/18/2017 Family Barcheck Ignatius 1/15/2017 Family Barcheck Ignatius 5/1/2017 Family Bashada Jean 4/9/2017 Vicki Bashada Bennett Edward & Gemma 9/17/2017 Jeremiah & Angie Waltz Bennett Edward & Gemma 12/6/2017 Gerald & Rita Waltz Bieniek Ted & Vicki 1/29/2017 Virginia Bieniek Bizik Paul & Sophia 4/2/2017 Joseph & Kimberly Bizik Blosser WA James & Johanna 12/31/2017 Family Blout, Jr. Vincent 11/26/2017 Wife & Daughters Blout, Jr. Vincent 10/15/2017 Wife & Daughters Blout, Sr. Vincent 1/22/2017 Rich & Jennifer Blout Blout-Zinn Grandparents of 9/11/2017 William & Justine Blout-Zinn Blout-Zinn 5 WA Wm & Justine 9/24/2017 Family Bobick Dorothy 3/10/2017 Frank & Nancy Plata Bobick Dorothy 4/29/2017 Frank & Nancy Plata Bodziony Frank 7/6/2017 Dorothy & Frances Bodziony Joseph & Anna 1/15/2017 Dorothy Bodziony Bodziony Steve 2/2/2017 Florence Rodgers Borytsky Joseph & Stella 12/7/2017 Joseph & Veronica Borytsky Bozek M/M Fred 7/8/2017 M/M Gerard Bozek Bozek Fred & Josephine 6/19/2017 M/M Fred S.